매핑 데이터 흐름에서의 창 변환
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 흐름은 Azure Data Factory 및 Azure Synapse Pipelines 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 처음 사용하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
창 변환에서는 데이터 스트림에서 열의 창 기반 집계를 정의합니다. 식 작성기에서는 LEAD, LAG, NTILE, CUMEDIST 및 RANK와 같은 데이터 또는 기간(SQL OVER 절)을 기반으로 하는 다른 유형의 집계를 정의할 수 있습니다. 이러한 집계를 포함하는 새 필드가 출력에 생성됩니다. 또한 필드별 선택적 그룹화를 포함할 수 있습니다.
위
창 변환에 대한 열 데이터의 분할을 설정합니다. 해당하는 SQL은 SQL의 Over 절에 있는 Partition By입니다. 분할에 사용할 식을 만들거나 계산을 만들려면 열 이름을 마우스로 가리키고 계산 열을 선택하여 수행할 수 있습니다.
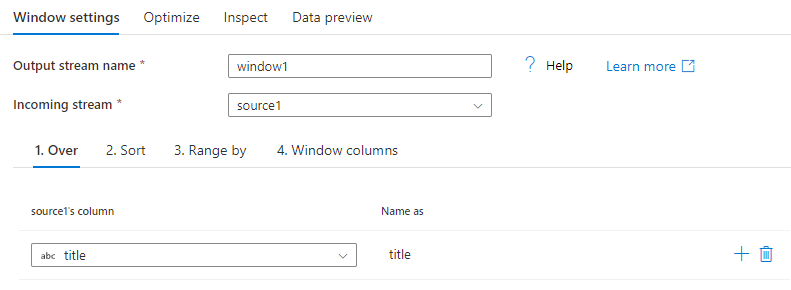
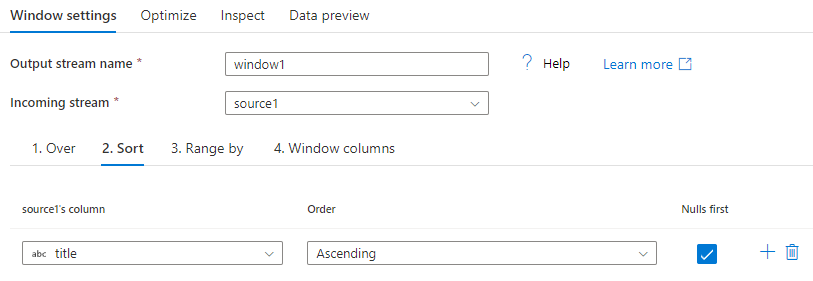
정렬
Over 절의 다른 부분은 Order By를 설정하는 것입니다. 이 절은 데이터 정렬 순서를 설정합니다. 정렬을 위해 이 열 필드에서 계산 값에 대한 식을 만들 수도 있습니다.
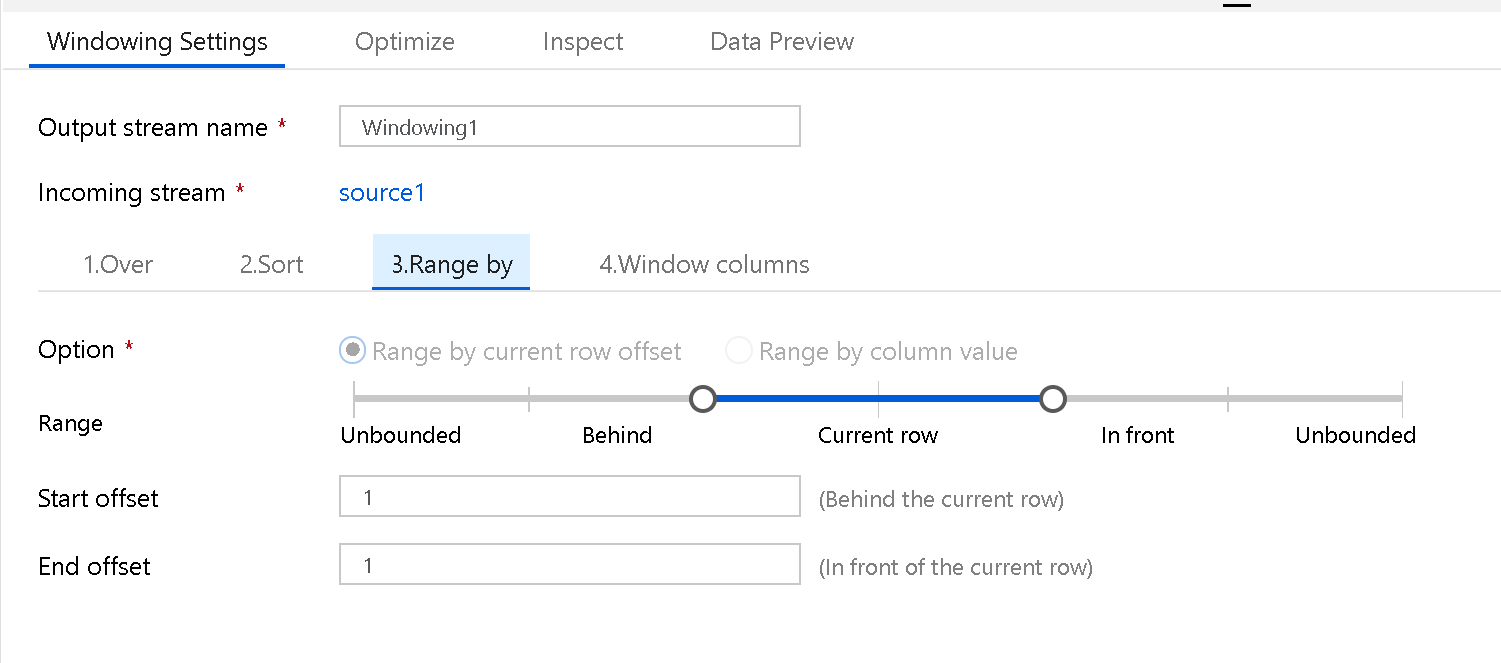
범위 기준
그런 다음, 창 프레임을 Unbounded 또는 Bounded로 설정합니다. 바인딩되지 않은 창 프레임을 설정하려면 슬라이더를 양쪽 끝에서 Unbounded로 설정합니다. Unbounded 및 Current Row 중에서 설정을 선택하는 경우 오프셋 시작 및 끝 값을 설정해야 합니다. 두 값 모두 양의 정수입니다. 데이터의 상대 숫자 또는 값을 사용할 수 있습니다.
창 슬라이더에는 현재 행 이전 값과 현재 행 이후 값이라는 두 개의 값이 설정됩니다. 시작과 끝 사이의 오프셋은 슬라이더의 두 선택기와 일치합니다.
기간 열
마지막으로 식 작성기를 사용하여 RANK, COUNT, MIN, MAX, DENSE RANK, LEAD, LAG 등과 같은 데이터 창과 함께 사용하려는 집계를 정의합니다.
식 작성기를 통해 Data Flow 식 언어에서 사용할 수 있는 집계 및 분석 함수의 전체 목록은 매핑 데이터 흐름의 데이터 변환 식에 나열되어 있습니다.
관련 콘텐츠
간단한 그룹별 집계를 확인하려는 경우, 집계 변환을 사용합니다.