매핑 데이터 흐름의 조회 변환
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 흐름은 Azure Data Factory 및 Azure Synapse Pipelines 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 처음 사용하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
조회 변환을 사용하여 데이터 흐름 스트림의 다른 원본에서 데이터를 참조할 수 있습니다. 조회 변환은 일치하는 데이터의 열을 원본 데이터에 추가합니다.
조회 변환은 왼쪽 우선 외부 조인과 유사합니다. 기본 스트림의 모든 행이 조회 스트림의 추가 열과 함께 출력 스트림에 존재하게 됩니다.
구성
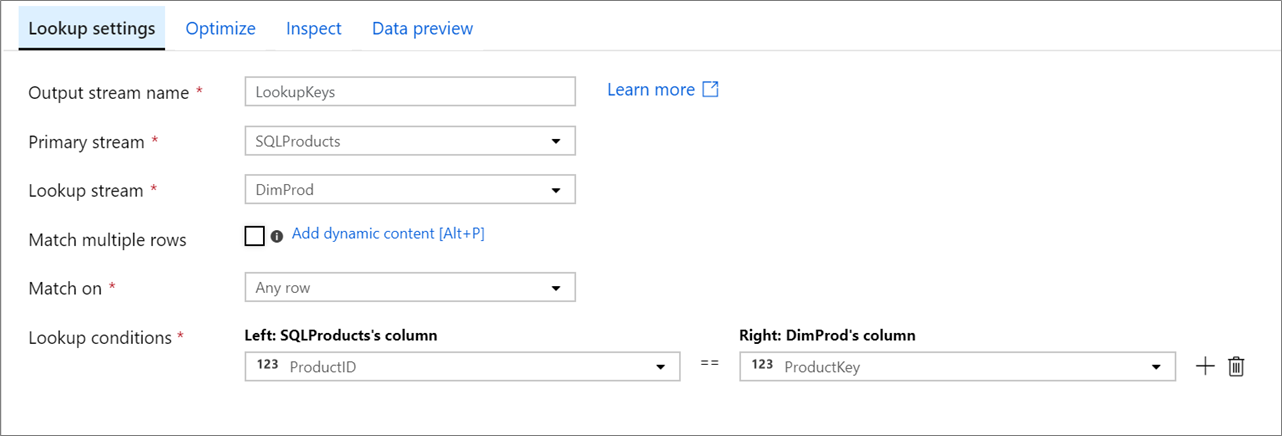
기본 스트림: 수신되는 데이터 스트림입니다. 이 스트림은 조인의 왼쪽에 해당합니다.
조회 스트림: 기본 스트림에 추가되는 데이터입니다. 추가되는 데이터는 조회 조건에 따라 결정됩니다. 이 스트림은 조인의 오른쪽에 해당합니다.
여러 행 일치: 사용하도록 설정하면 기본 스트림에서 여러 일치 항목이 있는 행이 여러 행을 반환합니다. 그러지 않으면 '일치 기준' 조건에 따라 단일 행만 반환됩니다.
일치 기준: ‘여러 행 일치’를 선택하지 않은 경우에만 표시됩니다. 임의 행, 첫 번째 일치 항목 또는 마지막 일치 항목에 일치할지를 선택합니다. 가장 빠르게 실행되는 임의 행이 권장됩니다. 첫 번째 행 또는 마지막 행을 선택한 경우 정렬 조건을 지정해야 합니다.
조회 조건: 일치시킬 열을 선택합니다. 같음 조건이 충족되면 행이 일치하는 것으로 간주됩니다. 데이터 흐름 식 언어를 사용하여 값을 추출하려면 '계산 열'을 가리키고 선택합니다.
두 스트림의 모든 열이 출력 데이터에 포함됩니다. 중복되거나 불필요한 열을 삭제하려면 조회 변환 후 선택 변환을 추가합니다. 싱크 변환에서 열을 삭제하거나 이름을 바꿀 수도 있습니다.
비동등 조인
조회 조건에서 같지 않음(!=) 또는 보다 큼(>)과 같은 조건부 연산자를 사용하려면 두 열 사이의 연산자 드롭다운을 변경합니다. 비동등 조인에서는 최적화 탭에서 고정 브로드캐스팅을 사용하여 두 스트림 중 하나 이상을 브로드캐스트해야 합니다.
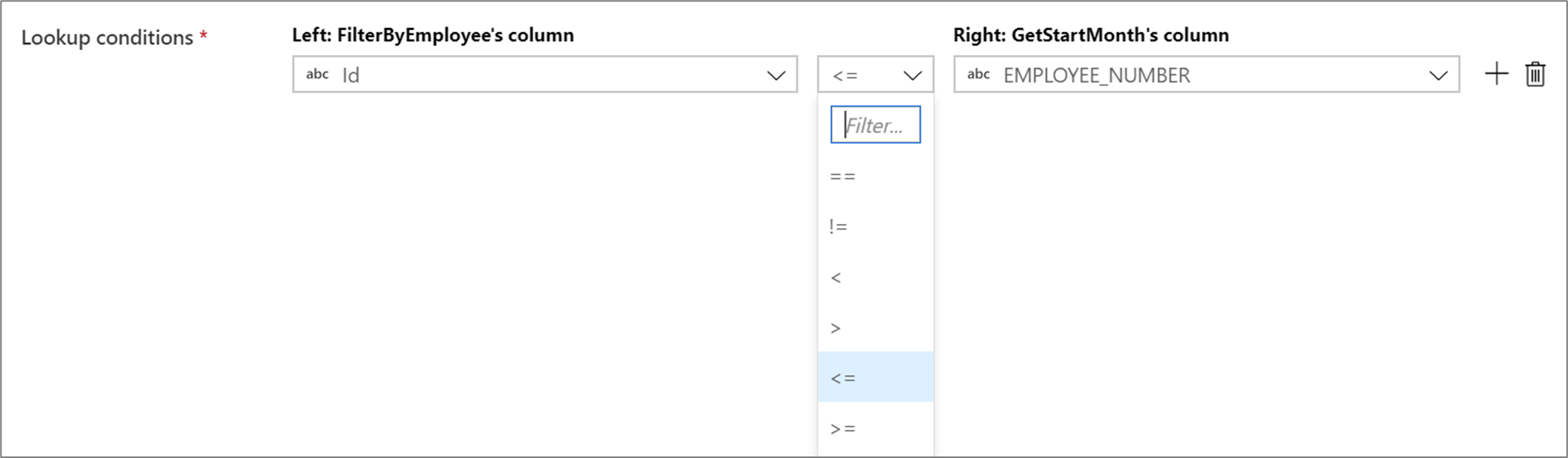
일치하는 행 분석
조회 변환 후 isMatch() 함수를 사용하여 조회가 개별 행과 일치하는지 여부를 확인할 수 있습니다.
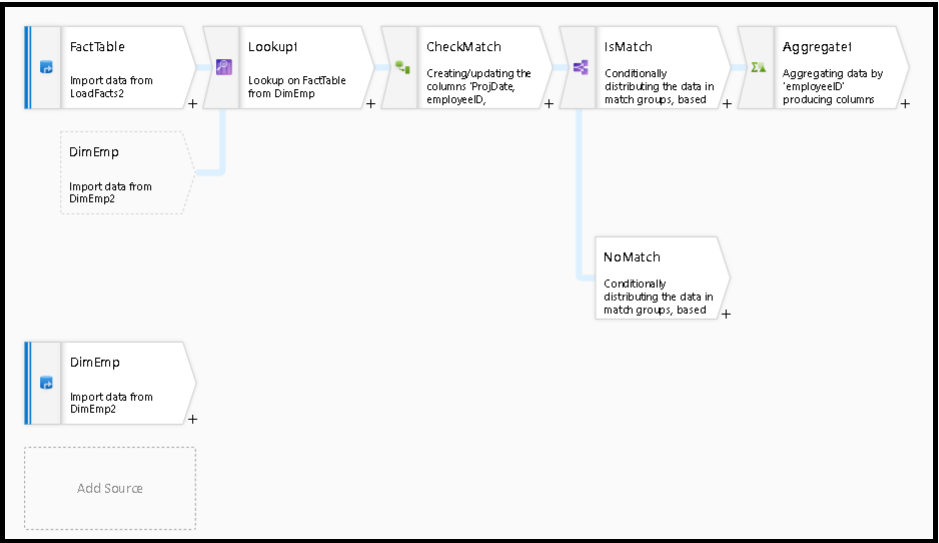
이 패턴의 예는 조건부 분할 변환을 사용하여 isMatch() 함수에서 분할을 수행하는 것입니다. 위의 예제에서는 일치하는 행이 위쪽 스트림을 통과하고 일치하지 않는 행이 NoMatch 스트림을 통해 흐릅니다.
조회 조건 테스트
디버그 모드에서 데이터 미리 보기를 사용하여 조회 변환을 테스트할 때 알려진 소규모 데이터 세트를 사용합니다. 대규모 데이터 세트에서 행을 샘플링하는 경우 테스트를 위해 읽을 행과 키를 예측할 수 없습니다. 따라서 결과가 명확하지 않으므로 조인 조건이 일치하는 항목을 반환하지 않을 수 있습니다.
브로드캐스트 최적화
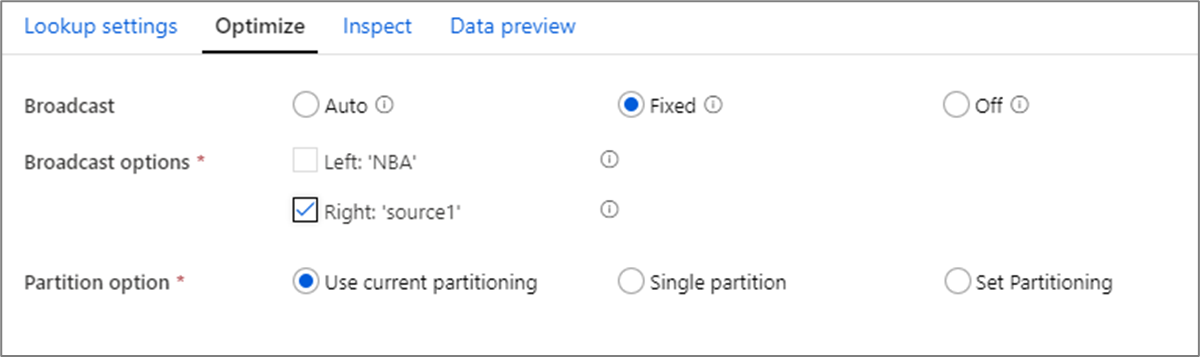
조인, 조회 및 있음 변환에서 하나 또는 두 데이터 스트림이 작업자 노드 메모리에 맞는 경우 브로드캐스팅를 사용하도록 설정하여 성능을 최적화할 수 있습니다. 기본적으로 spark 엔진은 한쪽에서 브로드캐스트할지 여부를 자동으로 결정합니다. 브로드캐스트할 쪽을 수동으로 선택하려면 고정을 선택합니다.
조인이 실행되는 동안 시간 제한 오류가 발생하는 경우에만 해제 옵션을 통해 브로드캐스팅을 사용하지 않도록 설정하는 것이 좋습니다.
캐시된 조회
동일한 원본에서 여러 개의 작은 조회를 수행하는 경우 캐시된 싱크 및 조회가 조회 변환보다 더 나은 사용 사례일 수 있습니다. 캐시 싱크가 더 나은 일반적인 예로는 데이터 저장소에서 최댓값을 조회하고 오류 코드를 오류 메시지 데이터베이스와 일치시키는 것입니다. 자세한 내용은 캐시 싱크 및 캐시된 조회에 대해 알아봅니다.
데이터 흐름 스크립트
구문
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
예시
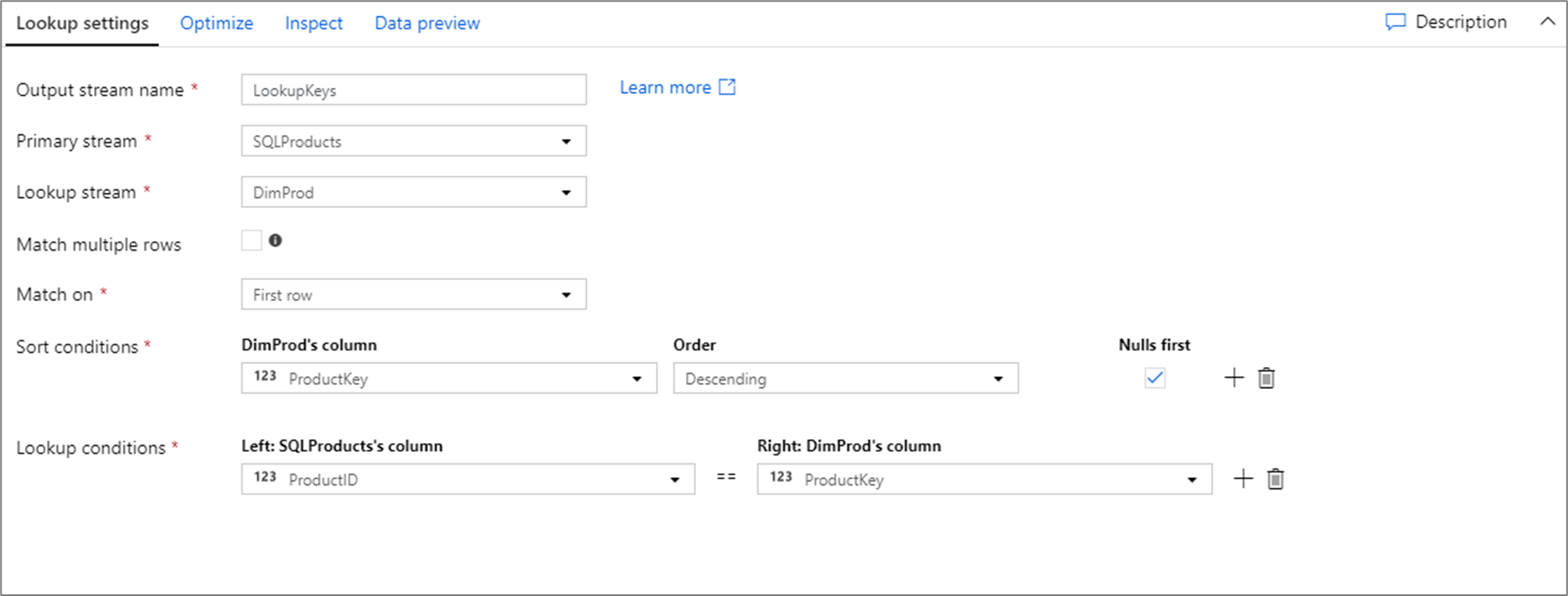
위의 조회 구성에 대한 데이터 흐름 스크립트는 아래 코드 조각에 나와 있습니다.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys