매핑 데이터 흐름에서 변환 어설션
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 흐름은 Azure Data Factory 및 Azure Synapse Pipelines 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 처음 사용하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
Assert 변환을 사용하면 데이터 품질 및 데이터 유효성 검사를 위해 매핑 데이터 흐름 내에서 사용자 지정 규칙을 빌드할 수 있습니다. 값이 예상 값 도메인을 충족하는지 여부를 결정하는 규칙을 작성할 수 있습니다. 또한 행 고유성을 확인하는 규칙을 빌드할 수 있습니다. 어설션 변환은 데이터의 각 행이 조건 집합을 충족하는지 확인하는 데 도움이 됩니다. 어설션 변환을 사용하면 데이터 유효성 검사 규칙이 충족되지 않을 때 사용자 지정 오류 메시지를 설정할 수도 있습니다.
구성
어설션 변환 구성 패널에서 어설션 유형을 선택하고, 어설션에 대한 고유한 이름, 선택적 설명을 제공하고, 식 및 선택적 필터를 정의합니다. 데이터 미리 보기 창은 어설션에 실패한 행을 나타냅니다. 또한 어설션에 실패한 행에 대해 isError() 및 hasError()를 사용하여 각 행 태그 다운스트림을 테스트할 수 있습니다.
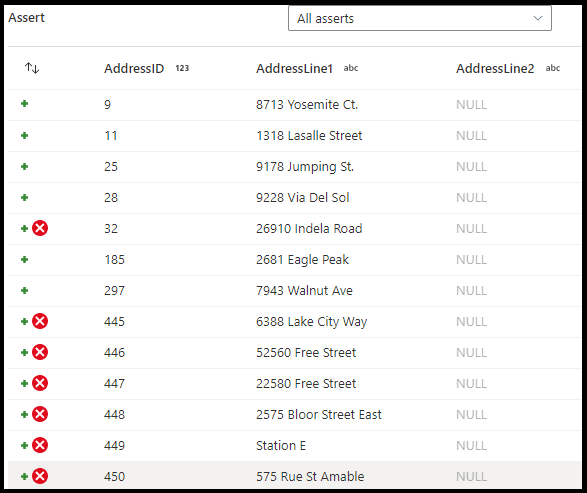
어설션 유형
- true 예상: 식의 결과는 부울 true 결과로 평가되어야 합니다. 이 설정을 사용하여 데이터의 도메인 값 범위의 유효성을 검사합니다.
- 고유성 예상: 열 또는 식을 데이터의 고유성 규칙으로 설정합니다. 이 설정을 사용하여 중복 행에 태그를 지정합니다.
- 예상 내용: 이 옵션은 두 번째 들어오는 스트림을 선택한 경우에만 사용할 수 있습니다. 존재는 두 스트림을 살펴보고 지정한 열 또는 식을 기반으로 두 스트림에 행이 있는지 확인합니다. 존재에 대한 두 번째 스트림을 추가하려면
Additional streams를 선택합니다.
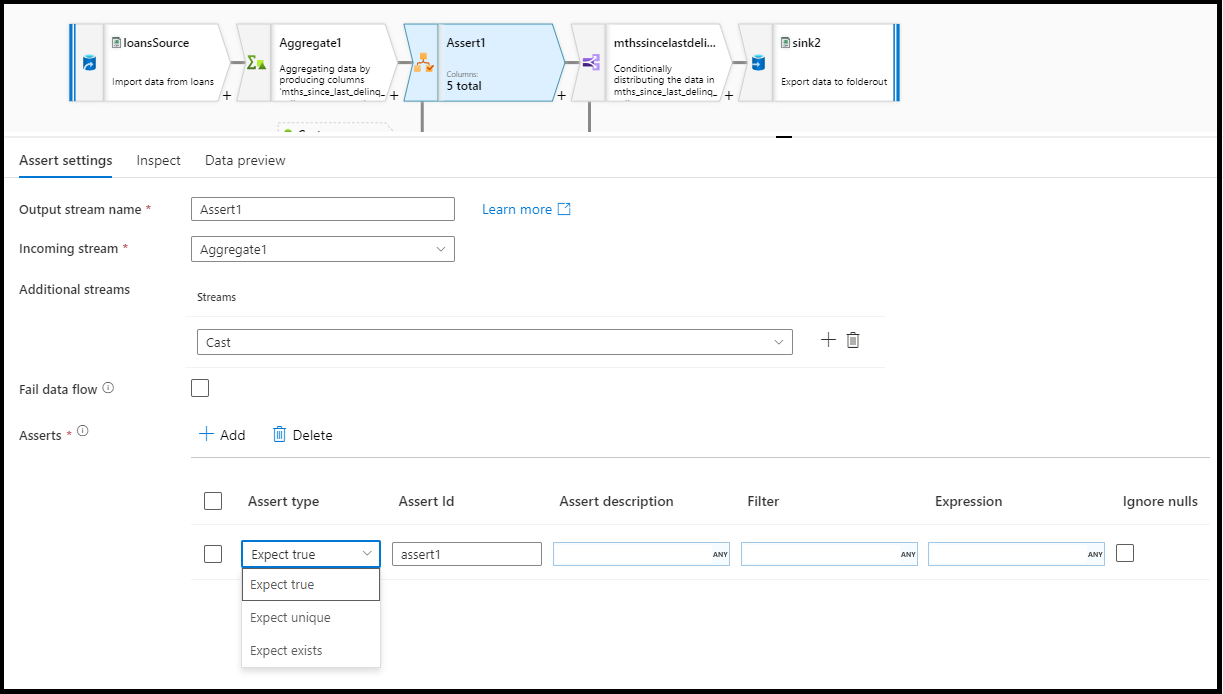
데이터 흐름 실패
어설션 규칙이 실패하는 즉시 데이터 흐름 작업이 실패하도록 하려면 fail data flow를 선택합니다.
어설션 ID
어설션 ID는 어설션의 (문자열) 이름을 입력하는 속성입니다. 어설션 실패 코드를 사용 hasError() 하거나 출력하기 위해 나중에 데이터 흐름에서 식별자를 다운스트림으로 사용할 수 있습니다. 어설션 ID는 각 데이터 흐름 내에서 고유해야 합니다.
어설션 설명
어설션에 대한 문자열 설명을 여기에 입력합니다. 여기에서 식 및 행 컨텍스트 열 값도 사용할 수 있습니다.
필터
필터는 식 값에 따라 행의 하위 집합으로만 어설션을 필터링할 수 있는 선택적 속성입니다.
식
각 어설션에 대한 평가를 위한 식을 입력합니다. 각 어설션 변환에 대해 여러 어설션을 사용할 수 있습니다. 각 어설션 유형에는 ADF가 어설션이 통과했는지 테스트하기 위해 평가해야 하는 식이 필요합니다.
NULL 무시
기본적으로 어설션 변환에는 행 어설션 평가에 NULL이 포함됩니다. 이 속성을 사용하여 NULL을 무시하도록 선택할 수 있습니다.
직접 어설션 행 오류
어설션이 실패하면 싱크 변환의 "오류" 탭을 사용하여 필요에 따라 이러한 오류 행을 Azure의 파일로 보낼 수 있습니다. 또한 오류 행을 무시하여 어설션 오류가 있는 행을 출력하지 않도록 싱크 변환에 대한 옵션도 있습니다.
예제
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
데이터 흐름 스크립트
예제
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1