Azure Data Factory 및 Azure Synapse Analytics의 ForEach 작업
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
ForEach 작업은 Azure Data Factory 또는 Synapse 파이프라인의 반복 제어 흐름을 정의합니다. 이 작업을 사용하여 컬렉션을 반복하고 루프의 지정된 작업을 실행합니다. 이 작업의 루프 구현은 프로그래밍 언어에서 구조를 반복하는 Foreach와 비슷합니다.
UI를 사용하여 ForEach 작업 만들기
파이프라인에서 ForEach 작업을 사용하려면 다음 단계를 완료합니다.
배열 형식 변수 또는 다른 활동의 출력을 ForEach 작업의 입력으로 사용할 수 있습니다. 배열 변수를 만들려면 파이프라인 캔버스의 배경을 선택한 다음, 변수 탭을 선택하여 아래와 같이 배열 형식 변수를 추가합니다.
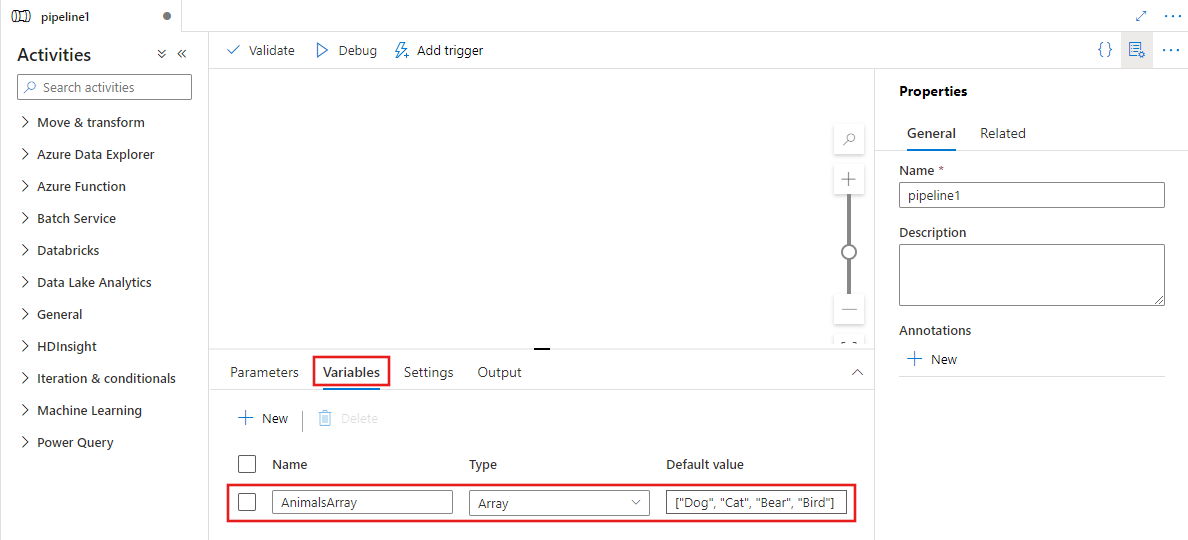
파이프라인 활동 창에서 ForEach를 검색하고 ForEach 작업을 파이프라인 캔버스로 끌어옵니다.
아직 선택하지 않은 경우 캔버스에서 새 ForEach 작업 및 해당 설정 탭을 선택하여 세부 정보를 편집합니다.
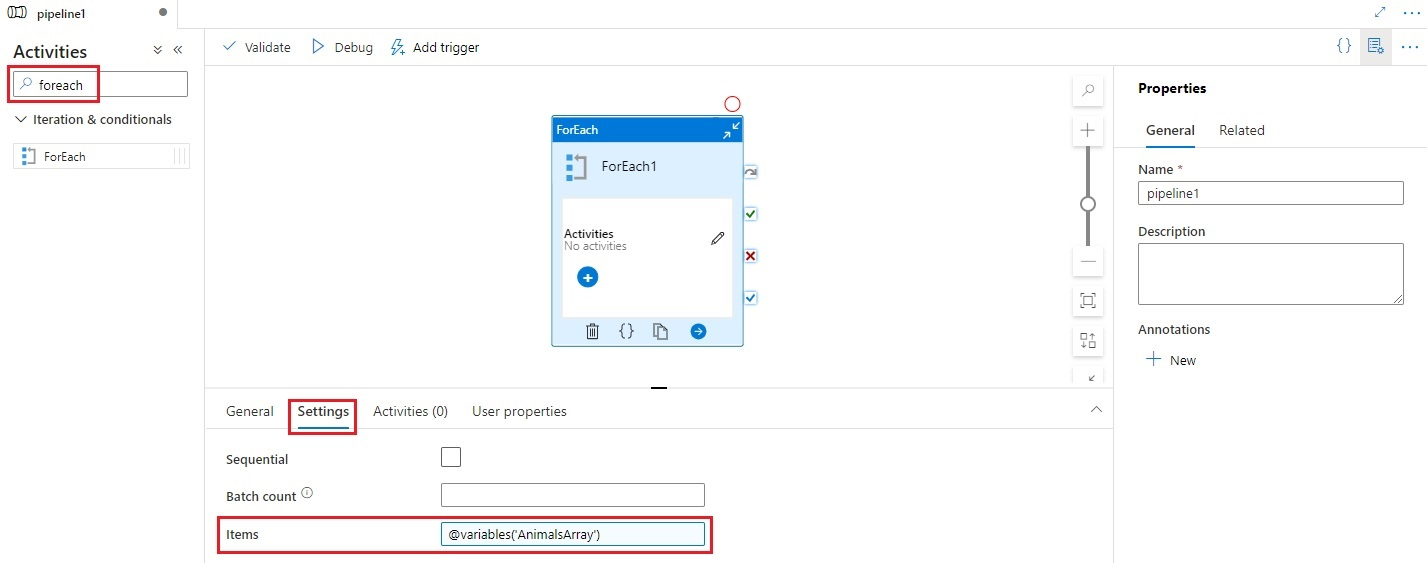
항목 필드를 선택한 다음, 동적 콘텐츠 추가 링크를 선택하여 동적 콘텐츠 편집기 창을 엽니다.
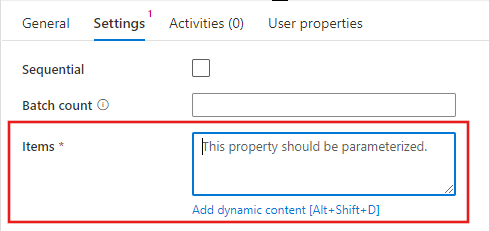
동적 콘텐츠 편집기에서 필터링할 입력 배열을 선택합니다. 이 예제에서는 첫 번째 단계에서 만든 변수를 선택합니다.
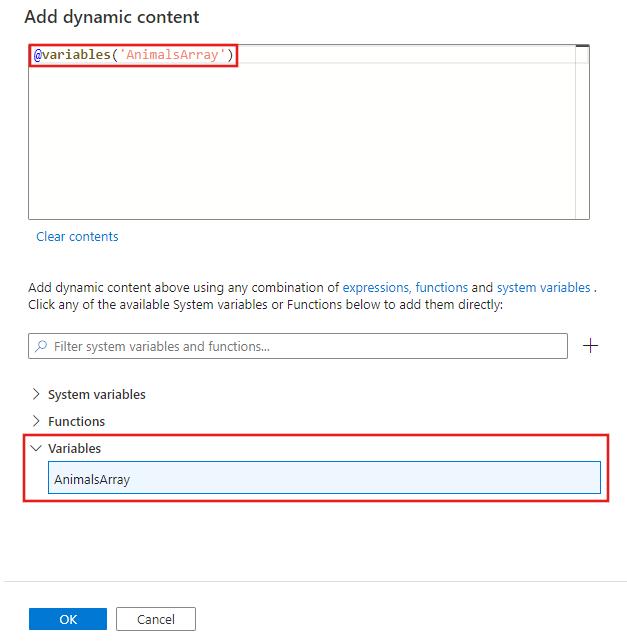
ForEach 작업에서 작업 편집기를 선택하여 입력 항목 배열의 각 항목에 대해 실행할 하나 이상의 작업을 추가합니다.
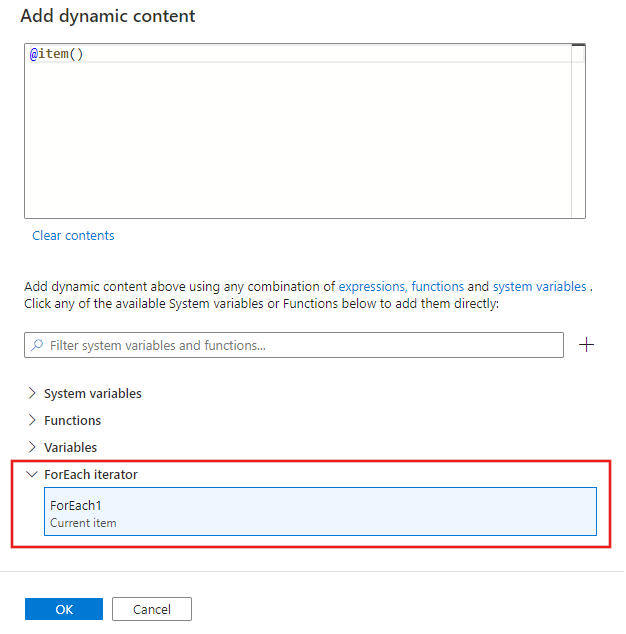
ForEach 작업 내에서 만드는 모든 작업에서 ForEach 작업이 항목 목록에서 반복하는 현재 항목을 참조할 수 있습니다. 동적 식을 사용하여 속성 값을 지정할 수 있는 모든 위치에서 현재 항목을 참조할 수 있습니다. 동적 콘텐츠 편집기에서 ForEach 반복기를 선택하여 현재 항목을 반환합니다.
구문
속성은 이 문서의 뒷부분에서 설명합니다. 항목 속성은 컬렉션이며 컬렉션의 각 항목은 다음 구문에서처럼 @item()를 사용하여 참조합니다.
{
"name":"MyForEachActivityName",
"type":"ForEach",
"typeProperties":{
"isSequential":"true",
"items": {
"value": "@pipeline().parameters.mySinkDatasetFolderPathCollection",
"type": "Expression"
},
"activities":[
{
"name":"MyCopyActivity",
"type":"Copy",
"typeProperties":{
...
},
"inputs":[
{
"referenceName":"MyDataset",
"type":"DatasetReference",
"parameters":{
"MyFolderPath":"@pipeline().parameters.mySourceDatasetFolderPath"
}
}
],
"outputs":[
{
"referenceName":"MyDataset",
"type":"DatasetReference",
"parameters":{
"MyFolderPath":"@item()"
}
}
]
}
]
}
}
형식 속성
| 속성 | 설명 | 허용된 값 | 필수 |
|---|---|---|---|
| name | for-each 작업의 이름입니다. | 문자열 | 예 |
| type | ForEach로 설정되어야 합니다. | 문자열 | 예 |
| isSequential | 순차 또는 병렬로 루프를 실행할지 지정합니다. 한 번에 최대 50개의 루프 반복을 병렬로 실행할 수 있습니다. 예를 들어 isSequential이 False로 설정된 10개의 다른 원본과 싱크 데이터 세트가 있는 복사 작업에 대해 반복되는 ForEach 작업의 경우, 모든 복사가 한 번에 실행됩니다. 기본값은 false입니다. "IsSequential"이 False로 설정된 경우 여러 실행 파일을 실행하기 위해 정확한 구성이 있는지 확인합니다. 그렇지 않으면 쓰기 충돌이 발생하지 않도록 이 속성을 주의하여 사용해야 합니다. 자세한 내용은 병렬 실행 섹션을 참조하세요. |
부울 | 아니요. 기본값은 false입니다. |
| batchCount | 병렬 실행 수를 제어하는 데 사용하는 Batch 수입니다(IsSequential이 false로 설정된 경우). 이는 동시성 상한이지만 for-each 작업이 항상 이 숫자에서 실행되는 것은 아닙니다. | 정수(최대값 50) | 아니요. 기본값은 20입니다. |
| 아이템 | 반복되는 JSON 배열을 반환하는 식 | 식(JSON 배열 반환) | 예 |
| 활동 | 실행할 작업 | 작업 목록 | 예 |
병렬 실행
isSequential이 false로 설정된 경우 최대 50개의 동시 반복에서 병렬로 작업이 반복됩니다. 이 설정은 주의해서 사용해야 합니다. 동시 반복을 동일한 폴더의 다른 파일에 쓰는 것은 괜찮습니다. 동시 반복을 동시에 정확히 동일한 파일에 쓸 경우 오류가 발생할 가능성이 높습니다.
반복 식 언어
ForEach 작업에서 속성 항목에 대해 반복할 배열을 제공합니다. @item()을 사용하여 ForEach 작업의 단일 열거를 반복합니다. 예를 들어 항목이 배열: [1, 2, 3]인 경우 @item()는 첫 번째 반복에서 1, 두 번째 반복에서 2, 세 번째 반복에서 3을 반환합니다. @range(0,10)와 같은 식을 사용하여 0부터 9까지 10회 반복할 수도 있습니다.
단일 활동에 대한 반복
시나리오: Azure Blob에서 동일한 원본 파일을 Azure Blob의 여러 대상 파일에 복사합니다.
파이프라인 정의
{
"name": "<MyForEachPipeline>",
"properties": {
"activities": [
{
"name": "<MyForEachActivity>",
"type": "ForEach",
"typeProperties": {
"isSequential": "true",
"items": {
"value": "@pipeline().parameters.mySinkDatasetFolderPath",
"type": "Expression"
},
"activities": [
{
"name": "MyCopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": "false"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy"
}
},
"inputs": [
{
"referenceName": "<MyDataset>",
"type": "DatasetReference",
"parameters": {
"MyFolderPath": "@pipeline().parameters.mySourceDatasetFolderPath"
}
}
],
"outputs": [
{
"referenceName": "MyDataset",
"type": "DatasetReference",
"parameters": {
"MyFolderPath": "@item()"
}
}
]
}
]
}
}
],
"parameters": {
"mySourceDatasetFolderPath": {
"type": "String"
},
"mySinkDatasetFolderPath": {
"type": "String"
}
}
}
}
Blob 데이터 세트 정의
{
"name":"<MyDataset>",
"properties":{
"type":"AzureBlob",
"typeProperties":{
"folderPath":{
"value":"@dataset().MyFolderPath",
"type":"Expression"
}
},
"linkedServiceName":{
"referenceName":"StorageLinkedService",
"type":"LinkedServiceReference"
},
"parameters":{
"MyFolderPath":{
"type":"String"
}
}
}
}
실행 매개 변수 값
{
"mySourceDatasetFolderPath": "input/",
"mySinkDatasetFolderPath": [ "outputs/file1", "outputs/file2" ]
}
여러 작업에 대해 반복
ForEach 작업에서는 여러 작업(예: 복사 및 웹 작업)에 대해 반복할 수 있습니다. 이 시나리오에서는 별도의 파이프라인으로 여러 활동을 추상화하는 것이 좋습니다. 그런 다음 ForEach 작업으로 파이프라인에서 ExecutePipeline 작업을 사용하여 여러 작업이 있는 별도의 파이프라인을 호출합니다.
구문
{
"name": "masterPipeline",
"properties": {
"activities": [
{
"type": "ForEach",
"name": "<MyForEachMultipleActivities>"
"typeProperties": {
"isSequential": true,
"items": {
...
},
"activities": [
{
"type": "ExecutePipeline",
"name": "<MyInnerPipeline>"
"typeProperties": {
"pipeline": {
"referenceName": "<copyHttpPipeline>",
"type": "PipelineReference"
},
"parameters": {
...
},
"waitOnCompletion": true
}
}
]
}
}
],
"parameters": {
...
}
}
}
예시
시나리오: 실행 파이프라인 작업으로 ForEach 작업 내 InnerPipeline에 대해 반복 내부 파이프라인이 매개 변수화된 스키마 정의로 복사합니다.
마스터 파이프라인 정의
{
"name": "masterPipeline",
"properties": {
"activities": [
{
"type": "ForEach",
"name": "MyForEachActivity",
"typeProperties": {
"isSequential": true,
"items": {
"value": "@pipeline().parameters.inputtables",
"type": "Expression"
},
"activities": [
{
"type": "ExecutePipeline",
"typeProperties": {
"pipeline": {
"referenceName": "InnerCopyPipeline",
"type": "PipelineReference"
},
"parameters": {
"sourceTableName": {
"value": "@item().SourceTable",
"type": "Expression"
},
"sourceTableStructure": {
"value": "@item().SourceTableStructure",
"type": "Expression"
},
"sinkTableName": {
"value": "@item().DestTable",
"type": "Expression"
},
"sinkTableStructure": {
"value": "@item().DestTableStructure",
"type": "Expression"
}
},
"waitOnCompletion": true
},
"name": "ExecuteCopyPipeline"
}
]
}
}
],
"parameters": {
"inputtables": {
"type": "Array"
}
}
}
}
내부 파이프라인 정의
{
"name": "InnerCopyPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "SqlSource",
}
},
"sink": {
"type": "SqlSink"
}
},
"name": "CopyActivity",
"inputs": [
{
"referenceName": "sqlSourceDataset",
"parameters": {
"SqlTableName": {
"value": "@pipeline().parameters.sourceTableName",
"type": "Expression"
},
"SqlTableStructure": {
"value": "@pipeline().parameters.sourceTableStructure",
"type": "Expression"
}
},
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "sqlSinkDataset",
"parameters": {
"SqlTableName": {
"value": "@pipeline().parameters.sinkTableName",
"type": "Expression"
},
"SqlTableStructure": {
"value": "@pipeline().parameters.sinkTableStructure",
"type": "Expression"
}
},
"type": "DatasetReference"
}
]
}
],
"parameters": {
"sourceTableName": {
"type": "String"
},
"sourceTableStructure": {
"type": "String"
},
"sinkTableName": {
"type": "String"
},
"sinkTableStructure": {
"type": "String"
}
}
}
}
원본 데이터 세트 정의
{
"name": "sqlSourceDataset",
"properties": {
"type": "SqlServerTable",
"typeProperties": {
"tableName": {
"value": "@dataset().SqlTableName",
"type": "Expression"
}
},
"structure": {
"value": "@dataset().SqlTableStructure",
"type": "Expression"
},
"linkedServiceName": {
"referenceName": "sqlserverLS",
"type": "LinkedServiceReference"
},
"parameters": {
"SqlTableName": {
"type": "String"
},
"SqlTableStructure": {
"type": "String"
}
}
}
}
싱크 데이터 세트 정의
{
"name": "sqlSinkDataSet",
"properties": {
"type": "AzureSqlTable",
"typeProperties": {
"tableName": {
"value": "@dataset().SqlTableName",
"type": "Expression"
}
},
"structure": {
"value": "@dataset().SqlTableStructure",
"type": "Expression"
},
"linkedServiceName": {
"referenceName": "azureSqlLS",
"type": "LinkedServiceReference"
},
"parameters": {
"SqlTableName": {
"type": "String"
},
"SqlTableStructure": {
"type": "String"
}
}
}
}
마스터 파이프라인 매개 변수
{
"inputtables": [
{
"SourceTable": "department",
"SourceTableStructure": [
{
"name": "departmentid",
"type": "int"
},
{
"name": "departmentname",
"type": "string"
}
],
"DestTable": "department2",
"DestTableStructure": [
{
"name": "departmentid",
"type": "int"
},
{
"name": "departmentname",
"type": "string"
}
]
}
]
}
출력 집계
foreach 작업의 출력을 집계하려면 ‘Variables’ 및 ‘변수 추가’ 작업을 활용하세요.
먼저, 파이프라인에서 array 변수를 선언합니다. 그런 다음, 각 foreach 루프 내에서 변수 추가 작업을 호출합니다. 이후에 배열에서 집계를 검색할 수 있습니다.
제한 사항 및 해결 방법
ForEach 작업 및 제안된 해결 방법의 몇 가지 제한 사항은 다음과 같습니다.
| 제한 사항 | 해결 방법 |
|---|---|
| ForEach 루프를 또 다른 ForEach 루프(또는 Until 루프) 내부에 중첩할 수 없습니다. | 중첩된 루프가 있는 내부 파이프라인을 통해 외부 ForEach 루프가 있는 외부 파이프라인을 반복하는 두 수준의 파이프라인을 설계합니다. |
ForEach 작업에는 병렬 처리를 위한 최대 50개 batchCount 및 최대 100,000개 항목이 있습니다. |
내부 파이프라인을 통해 ForEach 작업이 있는 외부 파이프라인을 반복하는 두 수준의 파이프라인을 설계합니다. |
| 변수가 전체 파이프라인에 대한 전역 변수이고 ForEach 또는 다른 작업으로 범위가 한정되지 않으므로 병렬로 실행 되는 ForEach 작업 내에서 SetVariable을 사용할 수 없습니다. | 순차 ForEach를 사용하거나 ForEach 내에서 Execute 파이프라인을 사용하는 것이 좋습니다(자식 파이프라인에서 처리되는 변수/매개 변수). |
관련 콘텐츠
지원되는 다른 제어 흐름 작업을 참조하세요.