전문 보이스 학습 데이터 세트 추가
애플리케이션에 대한 사용자 지정 텍스트 음성 변환 음성을 만들 준비가 되었다면 첫 번째 단계는 오디오 레코딩 및 관련 스크립트를 수집하여 음성 모델 학습을 시작하는 것입니다. 음성 샘플 녹음에 대한 자세한 내용은 자습서를 참조하세요. Speech Service는 이 데이터를 사용하여 레코딩의 음성에 맞게 튜닝된 고유한 음성을 만듭니다. 음성을 학습시킨 후에는 애플리케이션에서 음성 합성을 시작할 수 있습니다.
업로드하는 모든 데이터는 선택한 데이터 형식에 대한 요구 사항을 충족해야 합니다. 데이터를 업로드하기 전에 데이터 형식을 올바르게 지정해야 합니다. 그러면 Speech Service에에서 데이터를 정확하게 처리할 수 있습니다. 데이터 형식이 올바른지 확인하려면 학습 데이터 형식을 참조하세요.
참고 항목
- 표준 구독(S0) 사용자는 다섯 개의 데이터 파일을 동시에 업로드할 수 있습니다. 업로드 개수가 초과되면 적어도 한 개의 데이터 파일에 대한 가져오기가 완료될 때까지 기다립니다. 그런 다음, 다시 시도하세요.
- 구독당 가져올 수 있는 최대 데이터 파일 수는 표준 구독(S0) 사용자의 경우 500개 .zip 파일입니다. 자세한 내용은 Speech Service 할당량 및 제한을 참조하세요.
데이터 업로드
데이터를 업로드할 준비가 되면 학습 데이터 준비 탭으로 이동하여 첫 번째 학습 세트를 추가하고 데이터를 업로드합니다. 학습 세트는 음성 모델 학습에 사용되는 오디오 발화 및 해당 매핑 스크립트의 세트입니다. 학습 세트를 사용하여 학습 데이터를 구성할 수 있습니다. 서비스는 각 학습 세트별로 데이터 준비 상태를 확인합니다. 여러 데이터를 학습 세트로 가져올 수 있습니다.
학습 데이터를 업로드하려면 다음 단계를 수행합니다.
- Speech Studio에 로그인합니다.
- 사용자 지정 음성> 프로젝트 이름 >학습 데이터 준비>데이터 업로드를 선택합니다.
- 데이터 업로드 마법사에서 데이터 형식을 선택한 후 다음을 선택합니다.
- 컴퓨터에서 로컬 파일을 선택하거나 Azure Blob Storage URL을 입력하여 데이터를 업로드합니다.
- 대상 학습 집합 지정에서 기존 학습 집합을 선택하거나 새 학습 집합을 만듭니다. 새 학습 집합을 만든 경우 계속하기 전에 드롭다운 목록에서 해당 학습 집합이 선택되어 있는지 확인합니다.
- 다음을 선택합니다.
- 데이터의 이름과 설명을 입력하고 다음을 선택합니다.
- 업로드 세부 정보를 검토하고 제출을 선택합니다.
참고 항목
중복 ID는 허용되지 않습니다. ID가 동일한 발화가 제거됩니다.
중복된 오디오 이름은 학습에서 제거됩니다. 선택한 데이터에 한 개 또는 여러 .zip 파일에 동일한 오디오 이름이 포함되지 않도록 해야 합니다. 발화 ID(오디오 또는 스크립트 파일)가 중복되면 거부됩니다.
제출을 선택하면 데이터 파일의 유효성이 자동으로 검사됩니다. 데이터 유효성 검사에는 오디오 파일의 파일 형식, 크기 및 샘플링 레이트를 확인하는 일련의 검사가 포함됩니다. 오류가 있으면 수정하고 다시 제출합니다.
데이터가 업로드되면 학습 세트 세부 정보 보기에서 세부 정보를 확인할 수 있습니다. 세부 정보 페이지에서 각 데이터의 발음 문제와 소음 수준을 추가로 확인할 수 있습니다. 문장 수준의 발음 점수는 0~100 범위입니다. 일반적으로 70점 아래의 점수는 음성 오류 또는 스크립트 불일치를 나타냅니다. 전체 점수가 70보다 낮은 발화는 거부됩니다. 악센트가 강하면 발음 점수를 떨어뜨리고 생성된 디지털 음성에 영향을 줄 수 있습니다.
온라인으로 데이터 문제 해결
업로드한 후 학습 집합의 데이터 세부 정보를 확인할 수 있습니다. 계속해서 음성 모델을 학습시키기 전에 데이터 문제를 해결해야 합니다.
Speech Studio에서 발화 관련 데이터 문제를 식별 및 해결할 수 있습니다.
세부 정보 페이지에서 수락된 데이터 또는 거부된 데이터 페이지로 이동합니다. 변경할 개별 발화를 선택한 다음, 편집을 선택합니다.
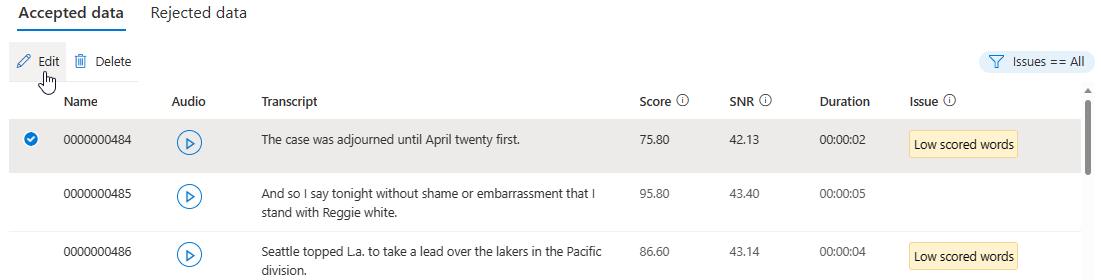
조건에 따라 표시할 데이터 문제를 선택할 수 있습니다.
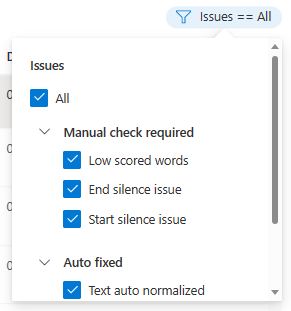
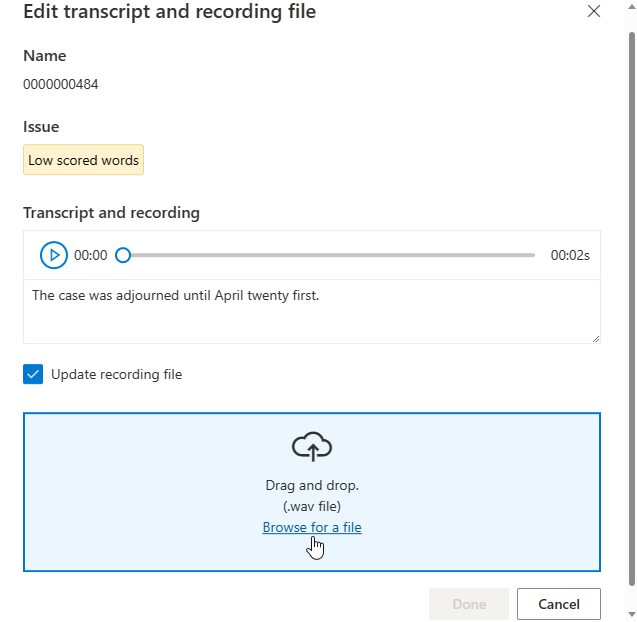
편집 창이 표시됩니다.
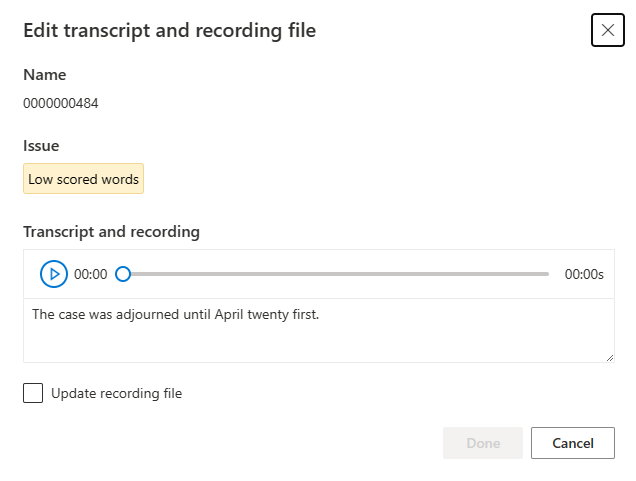
편집 창의 문제 설명에 따라 음성 텍스트 또는 녹음/녹화 파일을 업데이트합니다.
텍스트 상자에서 음성 텍스트를 편집한 다음, 완료를 선택할 수 있습니다
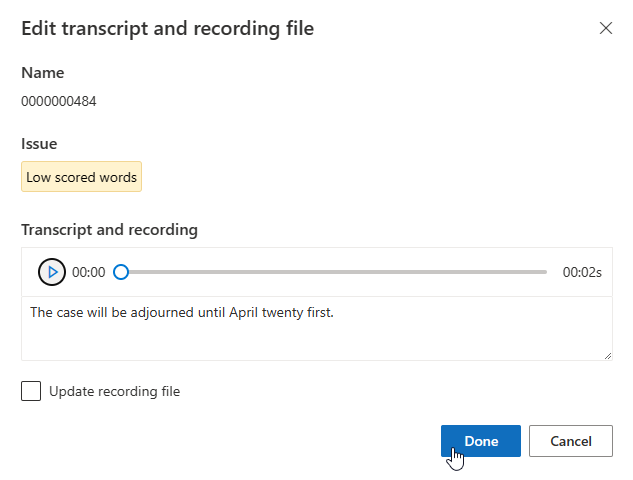
녹음/녹화 파일을 업데이트해야 하는 경우 녹음/녹화 파일 업데이트를 선택한 다음, 수정된 녹음/녹화 파일(.wav)을 업로드합니다.
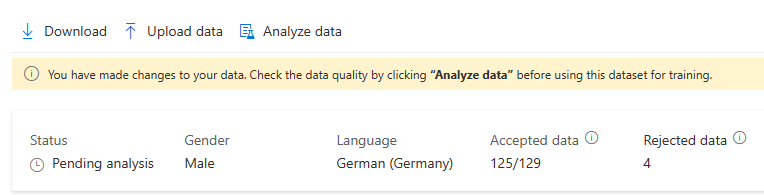
데이터를 변경한 후에는 학습에 이 데이터 세트를 사용하기 전에 데이터 분석을 클릭하여 데이터 품질을 확인해야 합니다.
분석이 완료되기 전에는 학습 모델에 대해 이 학습 세트를 선택할 수 없습니다.
문제가 있는 발화를 선택하고 삭제를 클릭하여 삭제할 수도 있습니다.
일반적인 데이터 문제
문제는 세 가지 유형으로 나뉩니다. 다음 표를 참조하여 각 오류 유형을 확인합니다.
자동 거부됨
이러한 오류가 있는 데이터는 학습에 사용되지 않습니다. 오류가 있는 가져온 데이터는 무시되므로 삭제할 필요가 없습니다. 이러한 데이터 오류를 온라인으로 해결하거나 학습을 위해 수정된 데이터를 다시 업로드할 수 있습니다.
| 범주 | 이름 | 설명 |
|---|---|---|
| 스크립트 | 잘못된 구분 기호 | 발화 ID와 스크립트 내용을 탭 문자로 구분해야 합니다. |
| 스크립트 | 잘못된 스크립트 ID | 스크립트 줄 ID는 숫자여야 합니다. |
| 스크립트 | 복제된 스크립트 | 스크립트 내용의 각 줄은 고유해야 합니다. 줄은 {}와 중복됩니다. |
| 스크립트 | 스크립트가 너무 깁니다. | 이 스크립트는 1,000자 미만이어야 합니다. |
| 스크립트 | 일치하는 오디오가 없습니다. | 각 발화의 ID(스크립트 파일의 각 줄)는 오디오 ID와 일치해야 합니다. |
| 스크립트 | 유효한 스크립트 없음 | 이 데이터 세트에서 유효한 스크립트를 찾을 수 없습니다. 세부 문제 목록에 나타나는 스크립트 줄을 수정합니다. |
| 오디오 | 일치하는 스크립트가 없습니다. | 스크립트 ID와 일치하는 오디오 파일이 없습니다. wav 파일의 이름은 스크립트 파일의 ID와 일치해야 합니다. |
| 오디오 | 잘못된 오디오 형식 | .wav 파일의 오디오 형식이 잘못되었습니다. SoX와 같은 오디오 도구를 사용하여 wav 파일 형식을 확인합니다. |
| 오디오 | 낮은 샘플링 레이트 | .wav 파일의 샘플링 속도는 16KHz보다 낮을 수 없습니다. |
| 오디오 | 너무 긴 오디오 | 오디오 시간이 30초보다 깁니다. 긴 오디오를 여러 파일로 나눕니다. 발화를 15초 미만으로 짧게 만드는 것이 좋습니다. |
| 오디오 | 유효한 오디오 없음 | 이 데이터 세트에서 유효한 오디오를 찾을 수 없습니다. 오디오 데이터를 확인하고 다시 업로드하세요. |
| 불일치 | 점수가 낮은 발화 | 문장 수준의 발음 점수가 70점 미만입니다. 스크립트와 오디오 콘텐츠를 검토하여 일치하는지 확인합니다. |
자동 수정됨
다음 오류는 자동으로 수정되지만 수정 사항이 올바르게 적용되었는지 검토하고 확인해야 합니다.
| 범주 | 이름 | 설명 |
|---|---|---|
| 불일치 | 무음 자동 수정 | 시작 무음은 100ms보다 짧은 것으로 감지되었으며 자동으로 100ms로 확장되었습니다. 정규화된 데이터 세트를 다운로드하고 검토합니다. |
| 불일치 | 무음 자동 수정 | 마지막 무음은 100ms보다 짧은 것으로 감지되었으며 자동으로 100ms로 확장되었습니다. 정규화된 데이터 세트를 다운로드하고 검토합니다. |
| 스크립트 | 텍스트 자동 정규화 | 텍스트는 숫자, 기호 및 약어에 대해 자동으로 정규화됩니다. 스크립트와 오디오를 검토하여 일치하는지 확인합니다. |
수동 확인 필요
다음 표에 나열된 해결되지 않은 오류는 학습 품질에 영향을 주지만, 이러한 오류가 있는 데이터는 학습 중에 제외되지 않습니다. 고품질 학습의 경우 이러한 오류를 수동으로 수정하는 것이 좋습니다.
| 범주 | 이름 | 설명 |
|---|---|---|
| 스크립트 | 정규화되지 않은 텍스트 | 이 스크립트에는 기호가 포함되어 있습니다. 오디오와 일치하도록 기호를 정규화합니다. 예를 들어 /를 슬래시로 정규화합니다. |
| 스크립트 | 질문 발화 부족 | 전체 발화 중 10% 이상의 발화는 질문 문장이어야 합니다. 이는 음성 모델이 질문 톤을 적절하게 표현하는 데 도움이 됩니다. |
| 스크립트 | 감탄문 발화 부족 | 전체 발화 중 10% 이상의 발화는 감탄문이어야 합니다. 이는 음성 모델이 흥분된 톤을 적절하게 표현하는 데 도움이 됩니다. |
| 스크립트 | 유효한 끝 문장 부호 없음 | 마침표(반자 '.' 또는 전자 '。'), 느낌표(반자 '!' 또는 전자 '!') 또는 물음표(반자 '?' 또는 전자 '?') 중 하나를 줄 끝에 추가합니다. |
| 오디오 | 신경망 음성에 대해 샘플링 레이트가 낮음 | 신경망 음성을 만들려면 .wav 파일의 샘플링 속도를 24KHz 이상으로 하는 것이 좋습니다. 더 낮으면 자동으로 24KHz로 높입니다. |
| 볼륨 | 전체 볼륨이 너무 낮음 | 볼륨은 -18dB(최대 볼륨의 10%)보다 낮으면 안 됩니다. 샘플 녹음/녹화 또는 데이터 준비 중에 적절한 범위 내에서 볼륨 평균 수준을 제어합니다. |
| 볼륨 | 볼륨 오버플로 | {}에서 오버플로 볼륨이 감지되었습니다. 피크 값에서 볼륨 오버플로를 방지하기 위해 녹음/녹화 장비를 조정합니다. |
| 볼륨 | 무음 문제 시작 | 처음 100ms의 무음이 깨끗하지 않습니다. 녹음 층간 소음 수준을 줄이고 시작 부분의 처음 100ms를 무음으로 유지합니다. |
| 볼륨 | 무음 문제 종료 | 마지막 100ms의 무음이 깨끗하지 않습니다. 층간 소음 수준을 줄이고 끝 부분의 마지막 100ms를 무음으로 유지합니다. |
| 불일치 | 점수가 낮은 단어 | 스크립트와 오디오 콘텐츠를 검토하여 일치하는지 확인하고 층간 소음 수준을 제어합니다. 긴 무음의 길이를 줄이거나, 오디오가 너무 길면 여러 발화로 분할합니다. |
| 불일치 | 무음 문제 시작 | 첫 단어가 나오기 전에 추가 오디오가 들렸습니다. 스크립트와 오디오 콘텐츠를 검토하여 일치하는지 확인하고, 노이즈 층 수준을 제어하고, 처음 100ms를 무음으로 만듭니다. |
| 불일치 | 무음 문제 종료 | 마지막 단어 뒤에 추가 오디오가 들렸습니다. 스크립트와 오디오 콘텐츠를 검토하여 일치하는지 확인하고 노이즈 층 수준을 제어하며 마지막 100ms를 무음으로 만듭니다. |
| 불일치 | 낮은 신호 대 잡음 비율 | 오디오 SNR 수준이 20dB보다 낮습니다. 최소 35dB가 권장됩니다. |
| 불일치 | 사용 가능한 점수가 없습니다. | 이 오디오의 음성 콘텐츠를 인식하지 못했습니다. 오디오 및 스크립트 내용을 확인하여 오디오가 유효하고 스크립트와 일치하는지 확인합니다. |
다음 단계
전문 보이스를 만들려면 학습 데이터 세트가 필요합니다. 학습 데이터 세트에는 오디오 및 스크립트 파일이 포함됩니다. 오디오 파일은 스크립트 파일을 읽는 성우의 녹음입니다. 스크립트 파일은 오디오 파일의 텍스트입니다.
이 문서에서는 학습 집합을 만들고 해당 리소스 ID를 가져옵니다. 그런 다음, 리소스 ID를 사용하여 오디오 및 스크립트 파일 세트를 업로드할 수 있습니다.
학습 집합 만들기
학습 집합을 만들려면 사용자 지정 음성 API의 TrainingSets_Create 작업을 사용합니다. 다음 지침에 따라 요청 본문을 생성합니다.
- 필수
projectId속성을 설정합니다. 프로젝트 만들기를 참조하세요. - 필수
voiceKind속성을Male또는Female로 설정합니다. 나중에 종류를 변경할 수 없습니다. - 필수
locale속성을 설정합니다. 이는 학습 집합 데이터의 로캘이어야 합니다. 학습 집합의 로캘은 동의서의 로캘과 동일해야 합니다. 로캘은 나중에 변경할 수 없습니다. 여기에서 텍스트 음성 변환 로캘 목록을 찾을 수 있습니다. - 필요에 따라 학습 집합 설명에 대한
description속성을 설정합니다. 학습 집합 설명은 나중에 변경할 수 있습니다.
다음 TrainingSets_Create 예제와 같이 URI를 사용하여 HTTP PUT 요청을 수행합니다.
YourResourceKey를 Speech 리소스 키로 바꿉니다.YourResourceRegion을 음성 리소스 지역으로 바꿉니다.JessicaTrainingSetId를 선택한 학습 집합 ID로 대체합니다. 대/소문자 구분 ID는 학습 집합의 URI에서 사용되며 나중에 변경할 수 없습니다.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
응답 본문은 다음 형식으로 표시되어야 합니다.
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
학습 집합 데이터 업로드
오디오 및 스크립트의 학습 집합을 업로드하려면 사용자 지정 음성 API의 TrainingSets_UploadData 작업을 사용합니다.
이 API를 호출하기 전에 녹음/녹화 및 스크립트 파일을 Azure Blob에 저장하세요. 아래 예제에서 녹음/녹화 파일은 https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav이며, 스크립트 파일은 https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt입니다.
다음 지침에 따라 요청 본문을 생성합니다.
- 필수
kind속성을AudioAndScript로 설정합니다. 종류는 학습 집합의 유형을 결정합니다. - 필수
audios속성을 설정합니다.audios속성 내에서 다음 속성을 설정합니다.- 필수
containerUrl속성을 오디오 파일이 포함된 Azure Blob Storage 컨테이너의 URL로 설정합니다. 읽기 및 목록 권한이 모두 있는 컨테이너에 SAS(공유 액세스 서명)를 사용합니다. - 필수
extensions속성을 오디오 파일의 확장명으로 설정합니다. - 필요에 따라
prefix속성을 설정하여 Blob 이름에 대한 접두사를 설정합니다.
- 필수
- 필수
scripts속성을 설정합니다.scripts속성 내에서 다음 속성을 설정합니다.- 필수
containerUrl속성을 스크립트 파일이 포함된 Azure Blob Storage 컨테이너의 URL로 설정합니다. 읽기 및 목록 권한이 모두 있는 컨테이너에 SAS(공유 액세스 서명)를 사용합니다. - 필수
extensions속성을 스크립트 파일의 확장명으로 설정합니다. - 필요에 따라
prefix속성을 설정하여 Blob 이름에 대한 접두사를 설정합니다.
- 필수
다음 TrainingSets_UploadData 예제와 같이 URI를 사용하여 HTTP POST 요청을 수행합니다.
YourResourceKey를 Speech 리소스 키로 바꿉니다.YourResourceRegion을 음성 리소스 지역으로 바꿉니다.- 이전 단계에서 다른 학습 집합 ID를 지정한 경우
JessicaTrainingSetId로 바꿉니다.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
응답 헤더에는 Operation-Location 속성이 포함되어 있습니다. 이 URI를 사용하여 TrainingSets_UploadData 작업에 대한 세부 정보를 가져옵니다. 응답 헤더의 예는 다음과 같습니다.
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345