Personalizer 학습 루프 구성
Important
2023년 9월 20일부터 새로운 Personalizer 리소스를 만들 수 없습니다. Personalizer 서비스는 2026년 10월 1일에 사용 중지됩니다.
서비스 구성에는 서비스의 보상 처리 방법, 서비스의 탐색 빈도, 모델을 다시 학습하는 빈도 및 저장할 데이터의 양이 포함됩니다.
해당 Personalizer 리소스에 대한 Azure Portal의 구성 페이지에서 학습 루프를 구성합니다.
구성 변경 계획
일부 구성을 변경할 경우 모델이 초기화되므로 구성 변경에 대한 계획을 세워야 합니다.
실습생 모드를 사용하려는 경우에는 Personalizer 구성을 검토한 후에 실습생 모드로 전환해야 합니다.
모델 초기화를 포함하는 설정
다음 작업은 최대 지난 2일 동안 사용 가능한 데이터를 사용하여 모델을 다시 교육합니다.
- 보상
- 탐색
모든 데이터를 지우려면 모델 및 학습 설정 페이지를 사용합니다.
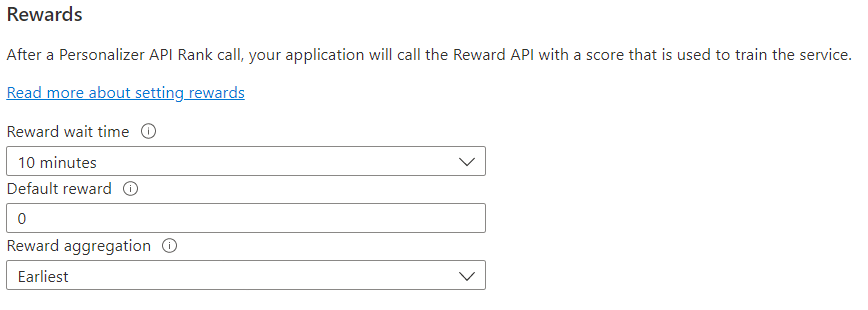
피드백 루프에 대한 보상 구성
학습 루프의 보상 사용에 대해 서비스를 구성합니다. 다음 값을 변경하면 현재 Personalizer 모델이 재설정되고 최근 2일의 데이터로 재학습됩니다.
| 값 | 목적 |
|---|---|
| 보상 대기 시간 | Personalizer가 순위 호출에 대한 보상 값을 수집하는 시간 길이를 설정하며, 순위 호출이 발생하는 순간부터 시작합니다. 이 값은 "Personalizer가 보상 호출을 얼마나 오래 기다려야 하나요?" 이 기간 이후에 도착하는 모든 보상은 기록되지만 학습에 사용되지는 않습니다. |
| 기본 보상 | 순위 호출과 연결된 보상 대기 시간 동안 Personalizer가 보상 호출을 하나도 받지 않은 경우 Personalizer는 기본 보상을 할당합니다. 기본적으로 대부분의 시나리오에서 기본 보상은 0입니다. |
| 보상 집계 | 동일한 순위 API 호출에 대해 여러 보상이 수신되는 경우 집계 메서드 sum 또는 earliest가 사용됩니다. 가장 빠른 집계 메서드는 가장 먼저 받은 점수를 선택하고 나머지 점수를 무시합니다. 가능성이 있는 중복 호출 중에 고유한 보상을 원하는 경우에 유용합니다. |
이 값을 변경한 후에는 꼭 저장을 선택해야 합니다.
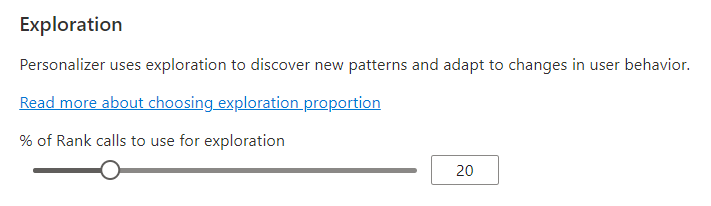
학습 루프가 조정될 수 있도록 탐색 구성
개인 설정은 모델의 학습된 모델의 예측을 사용하지 않고 대안을 탐색하여 새 패턴을 검색하고 사용자 동작 변경에 맞게 조정할 수 있습니다. 탐색 값은 탐색을 통해 답변되는 Rank 호출의 비율을 결정합니다.
이 값을 변경하면 현재 Personalizer 모델이 재설정되고 최근 2일의 데이터로 재학습됩니다.
이 값을 변경한 후에는 꼭 저장을 선택해야 합니다.
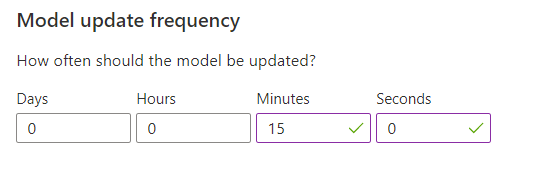
모델 학습을 위한 모델 업데이트 빈도 구성
모델 업데이트 빈도는 모델을 학습하는 빈도를 설정합니다.
| 빈도 설정 | 목적 |
|---|---|
| 1분 | 1분 업데이트 빈도는 Personalizer를 사용하여 애플리케이션의 코드 디버깅, 데모 실행 또는 Machine Learning 측면을 대화형으로 테스트할 때 유용합니다. |
| 15분 | 높은 모델 업데이트 빈도는 사용자 동작에서 변경 사항을 밀접하게 추적하려는 상황에 유용합니다. 라이브 뉴스, 바이럴 콘텐츠 또는 라이브 상품 입찰에서 실행하는 사이트를 예로 들 수 있습니다. 이러한 시나리오에서 15분 빈도를 사용할 수 있습니다. |
| 1시간 | 대부분 사용 사례의 경우 낮은 업데이트 빈도가 효과적입니다. |
이 값을 변경한 후에는 꼭 저장을 선택해야 합니다.
데이터 보존
데이터 보존 기간은 Personalizer가 데이터 로그를 보관하는 기간(일)을 설정합니다. 과거 데이터 로그는 Personalizer의 효율성을 측정하고 학습 정책을 최적화하는 데 사용되는 오프라인 평가를 수행하는 데 필요합니다.
이 값을 변경한 후에는 꼭 저장을 선택해야 합니다.