Azure OpenAI 평가(미리 보기)
큰 언어 모델의 평가는 다양한 작업 및 차원에서 성능을 측정하는 중요한 단계입니다. 이는 학습에서 성능 향상(또는 손실)을 평가하는 것이 중요한 미세 조정된 모델에 특히 중요합니다. 철저한 평가는 다양한 버전의 모델이 애플리케이션 또는 시나리오에 미치는 영향을 이해하는 데 도움이 될 수 있습니다.
개발자는 Azure OpenAI 평가를 통해 예상된 입력/출력 쌍에 대해 테스트하는 평가 실행을 만들고 정확도, 안정성 및 전반적인 성능과 같은 주요 메트릭에서 모델의 성능을 평가할 수 있습니다.
평가 지원
국가별 가용성
- 미국 동부2
- 미국 중북부
- 스웨덴 중부
- 스위스 서부
지원되는 배포 유형
- Standard
- 글로벌 표준
- 데이터 영역 표준
- 프로비전-관리
- 전역 프로비저닝 관리
- 프로비저닝된 관리되는 데이터 영역
평가 파이프라인
테스트 데이터
테스트하려는 근거리 데이터 세트를 어셈블해야 합니다. 데이터 세트 만들기는 일반적으로 시간이 지남에 따라 평가가 시나리오와 계속 관련되도록 하는 반복적인 프로세스입니다. 이 기본 진리 데이터 세트는 일반적으로 수작업으로 작성되며 모델에서 예상되는 동작을 나타냅니다. 데이터 세트에도 레이블이 지정되고 예상 답변이 포함됩니다.
참고 항목
감정 및 유효한 JSON 또는 XML과 같은 일부 평가 테스트에는 기본 진리 데이터가 필요하지 않습니다.
데이터 원본은 JSONL 형식이어야 합니다. 다음은 JSONL 평가 데이터 세트의 두 가지 예입니다.
평가 형식
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
평가 파일을 업로드하고 선택하면 처음 세 줄의 미리 보기가 반환됩니다.


이전에 업로드한 기존 데이터 세트를 선택하거나 새 데이터 세트를 업로드할 수 있습니다.
응답 만들기(선택 사항)
평가에서 사용하는 프롬프트는 프로덕션에서 사용하려는 프롬프트와 일치해야 합니다. 이러한 프롬프트는 모델이 따라야 하는 지침을 제공합니다. 플레이그라운드 환경과 마찬가지로 프롬프트에 몇 가지 예제를 포함하도록 여러 입력을 만들 수 있습니다. 자세한 내용은 프롬프트 디자인 및 프롬프트 엔지니어링의 일부 고급 기술에 대한 자세한 내용은 프롬프트 엔지니어링 기술을 참조하세요.
입력 파일의 열 이름에 해당하는 column_name 형식을 사용하여 {{input.column_name}} 프롬프트 내에서 입력 데이터를 참조할 수 있습니다.
평가 중에 생성된 출력은 형식을 사용하여 {{sample.output_text}} 후속 단계에서 참조됩니다.
참고 항목
데이터를 올바르게 참조하려면 이중 중괄호를 사용해야 합니다.
모델 배포
평가를 만드는 과정의 일환으로 응답을 생성할 때 사용할 모델(선택 사항)과 특정 테스트 조건으로 모델을 채점할 때 사용할 모델을 선택합니다.
Azure OpenAI에서는 평가의 일부로 사용할 특정 모델 배포를 할당합니다. 단일 평가 실행에서 여러 모델 배포를 비교할 수 있습니다.
기본 또는 미세 조정된 모델 배포를 평가할 수 있습니다. 목록에서 사용할 수 있는 배포는 Azure OpenAI 리소스 내에서 만든 배포에 따라 달라집니다. 원하는 배포를 찾을 수 없는 경우 Azure OpenAI 평가 페이지에서 새 배포를 만들 수 있습니다.
테스트 조건
테스트 조건은 대상 모델에서 생성된 각 출력의 효과를 평가하는 데 사용됩니다. 이러한 테스트는 입력 데이터를 출력 데이터와 비교하여 일관성을 보장합니다. 다양한 수준에서 출력의 품질과 관련성을 테스트하고 측정하기 위해 다양한 조건을 유연하게 구성할 수 있습니다.

시작
Azure AI Foundry 포털 내에서 Azure OpenAI 평가(미리 보기)를 선택합니다. 이 보기를 옵션으로 보려면 먼저 지원되는 지역에서 기존 Azure OpenAI 리소스를 선택해야 할 수 있습니다.
새 평가 선택
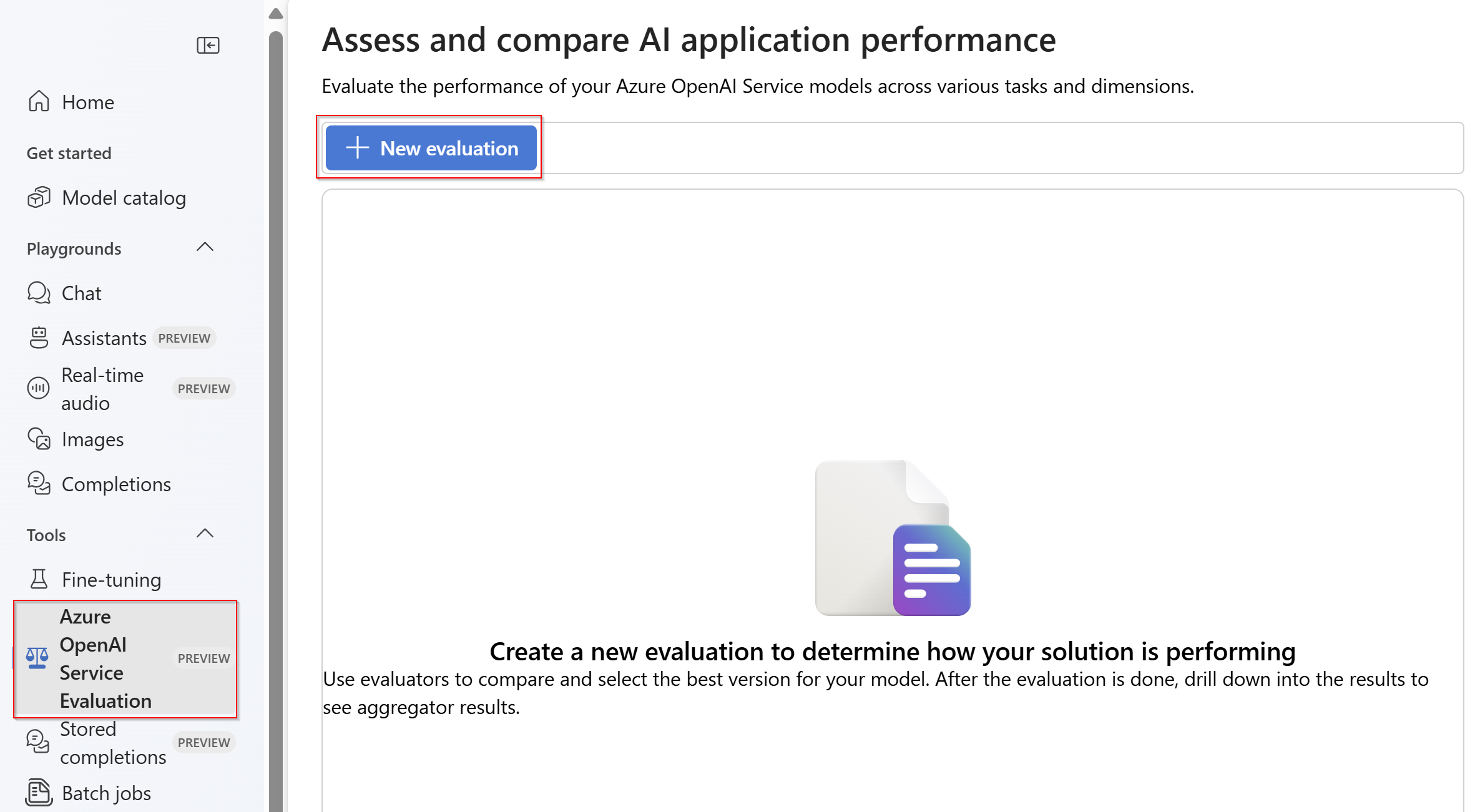
평가의 이름을 입력합니다. 기본적으로 임의 이름은 편집하고 대체하지 않는 한 자동으로 생성됩니다. 새 데이터 세트 업로드를 선택합니다.
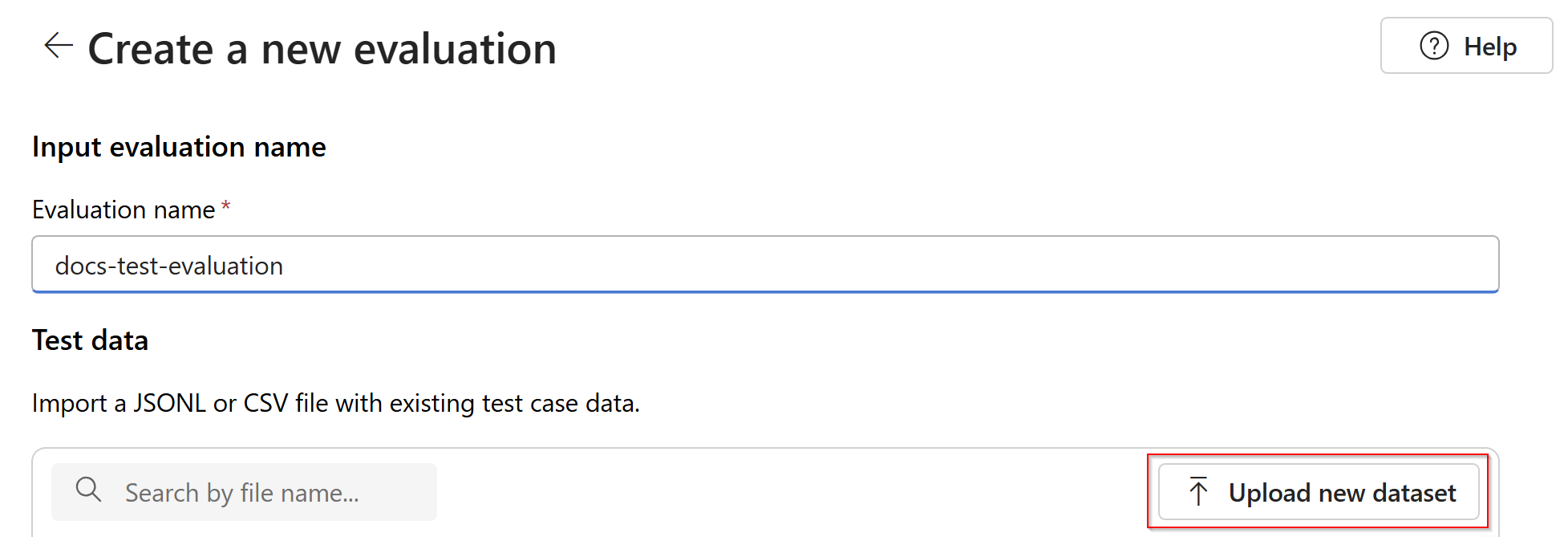
형식이 될
.jsonl평가를 선택합니다. 샘플 테스트 파일이 필요한 경우 다음 10줄을 다음 파일에eval-test.jsonl저장할 수 있습니다.{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}파일의 처음 세 줄은 미리 보기로 표시됩니다.
응답 아래에서 만들기 단추를 선택합니다. 템플릿 드롭다운을 사용하여 만들기에서 선택합니다
{{item.input}}. 그러면 평가 파일의 입력 필드가 평가 데이터 세트와 비교할 수 있는 새 모델 실행에 대한 개별 프롬프트에 삽입됩니다. 모델은 해당 입력을 가져와서 고유한 출력을 생성하며, 이 경우 라는{{sample.output_text}}변수에 저장됩니다. 그런 다음 나중에 테스트 조건의 일부로 해당 샘플 출력 텍스트를 사용합니다. 또는 사용자 고유의 사용자 지정 시스템 메시지와 개별 메시지 예제를 수동으로 제공할 수 있습니다.평가에 따라 응답을 생성할 모델을 선택합니다. 모델이 없는 경우 모델을 만들 수 있습니다. 이 예제에서는 표준 배포
gpt-4o-mini를 사용합니다.
설정/sprocket 기호는 모델에 전달되는 기본 매개 변수를 제어합니다. 현재는 다음 매개 변수만 지원됩니다.




- 온도
- 최대 길이
- 위쪽 P
선택한 모델에 관계없이 최대 길이는 현재 2048로 제한됩니다.
테스트 조건 추가를 선택하고 추가를 선택합니다.
[추가와 함께] 아래에서 [비교]
{{item.output}}아래에서 의미 체계 유사성>을 선택합니다.{{sample.output_text}}이렇게 하면 평가.jsonl파일에서 원래 참조 출력을 가져와서 모델 프롬프트를 기반으로{{item.input}}하여 생성되는 출력과 비교합니다.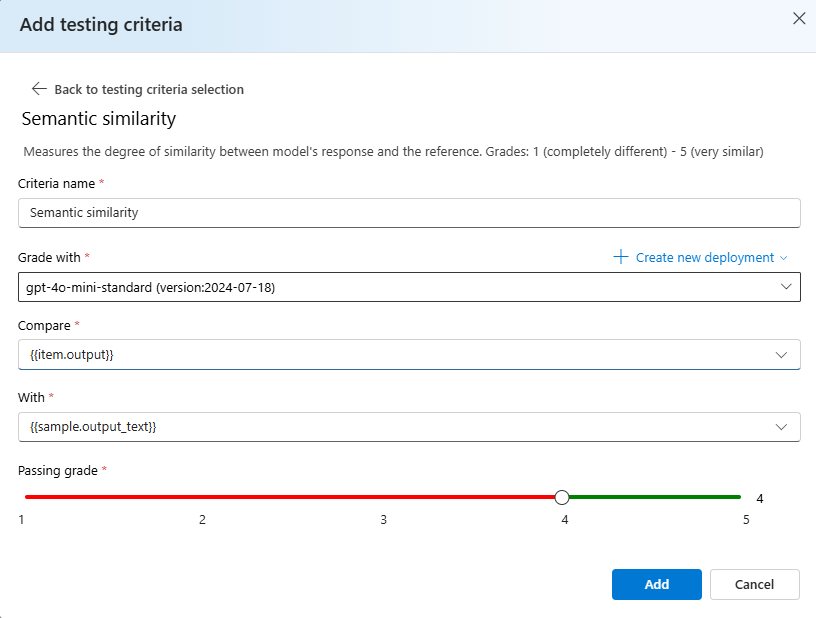
이 시점에서 추가>를 선택하면 테스트 조건을 더 추가하거나 만들기를 선택하여 평가 작업 실행을 시작할 수 있습니다.
만들기를 선택하면 평가 작업의 상태 페이지로 이동합니다.
평가 작업이 만들어지면 작업을 선택하여 작업의 전체 세부 정보를 볼 수 있습니다.
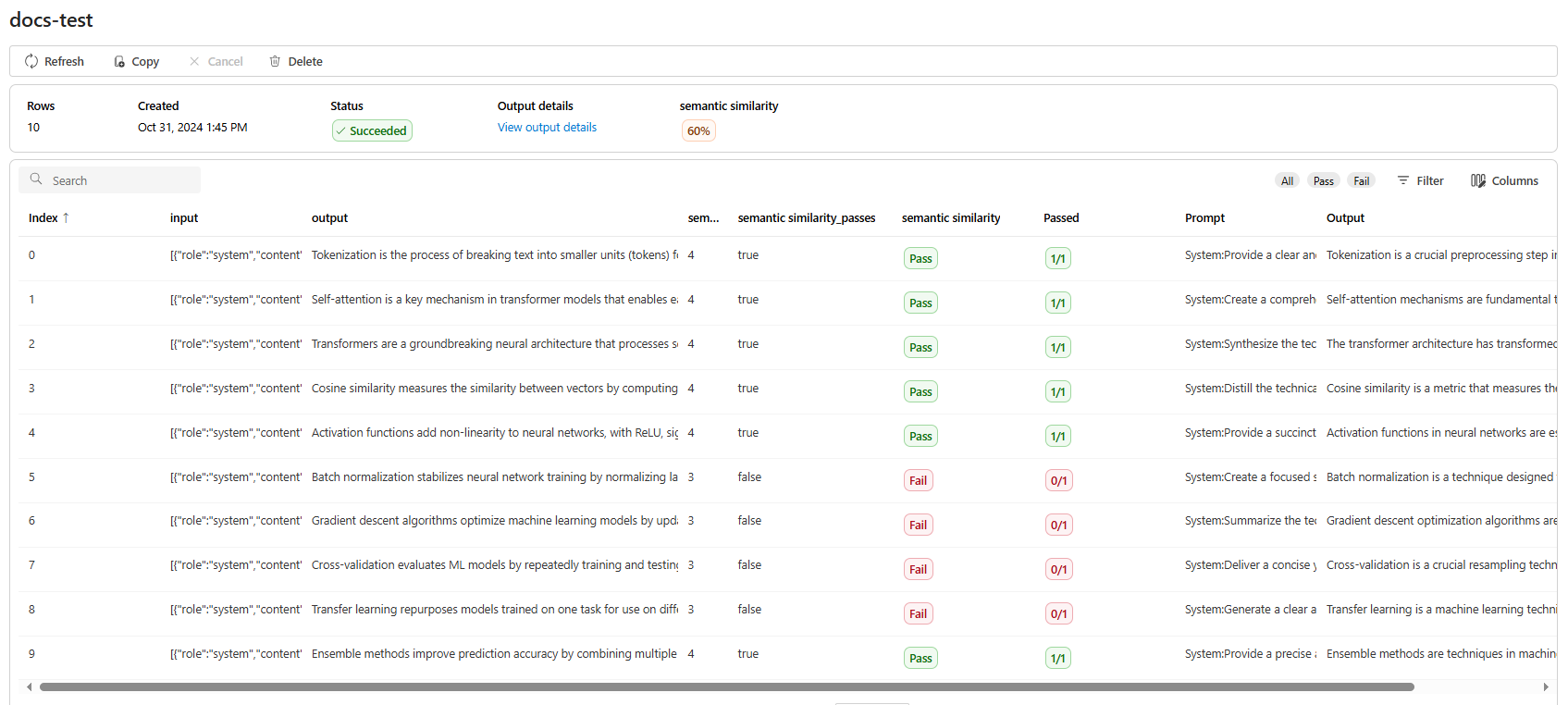
의미 체계 유사성 보기 출력 세부 정보에 는 통과 테스트를 복사/붙여넣을 수 있는 JSON 표현이 포함됩니다.
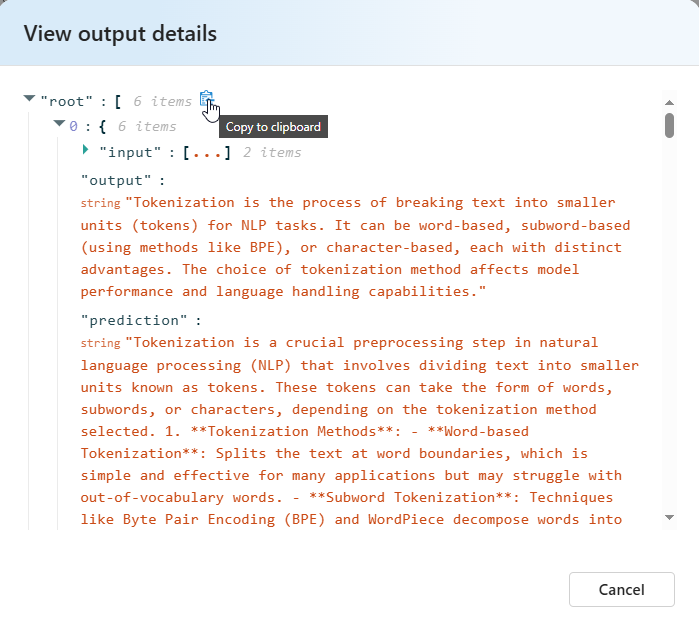




테스트 조건 세부 정보
Azure OpenAI 평가는 여러 테스트 조건 옵션을 제공합니다. 아래 섹션에서는 각 옵션에 대한 추가 세부 정보를 제공합니다.
사실성
제출된 답변의 사실 정확도를 전문가 답변과 비교하여 평가합니다.
사실성은 제출된 답변의 사실 정확도를 전문가의 답변과 비교하여 평가합니다. CoT(상세 생각 체인) 프롬프트를 활용하여, 성적은 제출된 답변이 전문가 답변과 일치하는지, 하위 집합인지, 상위 집합인지 또는 전문가 답변과 충돌하는지를 결정합니다. 스타일, 문법 또는 문장 부호의 차이를 무시하고 사실 콘텐츠에만 초점을 맞춥니다. 사실성은 AI에서 제공하는 답변의 정확도를 보장하는 콘텐츠 확인 및 교육 도구를 포함하지만 제한되지 않는 많은 시나리오에서 유용할 수 있습니다.

프롬프트 옆에 있는 드롭다운을 선택하여 이 테스트 조건의 일부로 사용되는 프롬프트 텍스트를 볼 수 있습니다. 현재 프롬프트 텍스트는 다음과 같습니다.
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
의미 체계 유사성
모델의 응답과 참조 사이의 유사성 정도를 측정합니다.
Grades: 1 (completely different) - 5 (very similar).

관심도
출력의 감성적인 톤을 식별하려고 시도합니다.

프롬프트 옆에 있는 드롭다운을 선택하여 이 테스트 조건의 일부로 사용되는 프롬프트 텍스트를 볼 수 있습니다. 현재 프롬프트 텍스트는 다음과 같습니다.
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
문자열 검사
출력이 예상 문자열과 정확히 일치하는지 확인합니다.

문자열 검사는 다양한 평가 조건을 허용하는 두 문자열 변수에 대해 다양한 이진 작업을 수행합니다. 같음, 포함 및 특정 패턴을 비롯한 다양한 문자열 관계를 확인하는 데 도움이 됩니다. 이 평가기를 사용하면 대/소문자를 구분하거나 대/소문자를 구분하지 않는 비교를 수행할 수 있습니다. 또한 true 또는 false 결과에 대해 지정된 성적을 제공하여 비교 결과에 따라 사용자 지정된 평가 결과를 허용합니다. 지원되는 작업의 유형은 다음과 같습니다.
-
equals: 출력 문자열이 계산 문자열과 정확히 같은지 확인합니다. -
contains: 평가 문자열이 출력 문자열의 부분 문자열인지 확인합니다. -
starts-with: 출력 문자열이 평가 문자열로 시작하는지 확인합니다. -
ends-with: 출력 문자열이 평가 문자열로 끝나는지 확인합니다.
참고 항목
테스트 기준에서 특정 매개 변수를 설정할 때 변수와 템플릿 중에서 선택할 수 있는 옵션이 있습니다. 입력 데이터의 열을 참조하려면 변수를 선택합니다. 고정 문자열을 제공하려는 경우 템플릿을 선택합니다.
유효한 JSON 또는 XML
출력이 유효한 JSON 또는 XML인지 확인합니다.

일치 스키마
출력이 지정된 구조를 따르는지 확인합니다.

조건 일치
모델의 응답이 기준과 일치하는지 평가합니다. 등급: 통과 또는 실패.

프롬프트 옆에 있는 드롭다운을 선택하여 이 테스트 조건의 일부로 사용되는 프롬프트 텍스트를 볼 수 있습니다. 현재 프롬프트 텍스트는 다음과 같습니다.
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
텍스트 품질
참조 텍스트와 비교하여 텍스트 품질을 평가합니다.

요약:
- BLEU 점수: BLEU 점수를 사용하여 하나 이상의 고품질 참조 번역과 비교하여 생성된 텍스트의 품질을 평가합니다.
- ROUGE 점수: ROUGE 점수를 사용하여 참조 요약과 비교하여 생성된 텍스트의 품질을 평가합니다.
- 코사인: 코사인 유사성이라고도 하며 모델 출력 및 참조 텍스트와 같은 두 텍스트 포함이 의미에 맞게 정렬되어 둘 사이의 의미 체계 유사성을 평가하는 데 도움이 됩니다. 이 작업은 벡터 공간에서 거리를 측정하여 수행됩니다.
세부 정보:
BLEU(BiLingual Evaluation Understudy) 점수는 일반적으로 NLP(자연어 처리) 및 기계 번역에 사용됩니다. 텍스트 요약 및 텍스트 생성 사용 사례에 널리 사용됩니다. 생성된 텍스트가 참조 텍스트와 얼마나 일치하는지 평가합니다. BLEU 점수는 0에서 1까지 다양하며, 더 높은 점수는 더 나은 품질을 나타냅니다.
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)는 자동 요약 및 기계 번역을 평가하는 데 사용되는 메트릭 세트입니다. 생성된 텍스트와 참조 요약 간의 중첩을 측정합니다. ROUGE는 생성된 텍스트가 참조 텍스트를 얼마나 잘 다루는지 평가하기 위해 재현율 지향적 측정값에 중점을 둡니다. ROUGE 점수는 다음을 비롯한 다양한 메트릭을 제공합니다. • ROUGE-1: 생성된 텍스트와 참조 텍스트 사이에 유니그램(단일 단어)이 겹칩니다. • ROUGE-2: 생성된 텍스트와 참조 텍스트 사이에 bigrams(연속된 두 단어)가 겹칩니다. • ROUGE-3: 생성된 텍스트와 참조 텍스트 사이의 삼각(연속 단어 3개)이 겹칩니다. • ROUGE-4: 생성된 텍스트와 참조 텍스트 사이에 4그램(연속된 단어 4개)이 겹칩니다. • ROUGE-5: 생성된 텍스트와 참조 텍스트 사이에 5그램(연속된 단어 5개)이 겹칩니다. • ROUGE-L: 생성된 텍스트와 참조 텍스트 사이에 L-gram(L 연속 단어)이 겹칩니다. 텍스트 요약 및 문서 비교는 특히 텍스트 일관성 및 관련성이 중요한 시나리오에서 ROUGE에 대한 최적의 사용 사례 중 하나입니다.
코사인 유사성은 모델 출력 및 참조 텍스트와 같은 두 텍스트 포함이 의미에 얼마나 가깝게 정렬되는지 측정하여 의미 체계 유사성을 평가하는 데 도움이 됩니다. 다른 모델 기반 평가자와 마찬가지로 평가에 사용하는 모델 배포를 제공해야 합니다.
Important
이 평가자에는 포함 모델만 지원됩니다.
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
사용자 지정 프롬프트
모델을 사용하여 출력을 지정된 레이블 집합으로 분류합니다. 이 평가자는 정의해야 하는 사용자 지정 프롬프트를 사용합니다.
