Azure OpenAI 일괄 배포 시작
Azure OpenAI 일괄 처리 API는 대규모 및 대용량 처리 작업을 효율적으로 처리하도록 설계되었습니다. 별도의 할당량으로 비동기 요청 그룹을 처리하고 24시간 대상 처리 시간을 제공하며, 글로벌 표준보다 50% 더 저렴한 비용을 제공합니다. 일괄 처리를 사용하면 한 번에 하나의 요청을 보내는 것이 아니라, 단일 파일에 많은 수의 요청을 보냅니다. 글로벌 일괄 처리 요청에는 별도의 큐 토큰 할당량이 있어 온라인 워크로드가 중단되지 않습니다.
주요 사용 사례는 다음과 같습니다.
대규모 데이터 처리: 방대한 데이터 세트를 병렬로 빠르게 분석합니다.
콘텐츠 생성: 제품 설명이나 문서 등 방대한 양의 텍스트를 만듭니다.
문서 검토 및 요약: 긴 문서의 검토 및 요약을 자동화합니다.
고객 지원 자동화: 더 빠른 응답을 위해 여러 문의를 동시에 처리합니다.
데이터 추출 및 분석: 방대한 양의 구조화되지 않은 데이터에서 정보를 추출하고 분석합니다.
NLP(자연어 처리) 작업: 대규모 데이터 세트에 대한 감정 분석이나 번역과 같은 작업을 수행합니다.
마케팅 및 개인 설정: 대규모로 개인 설정 콘텐츠와 권장 사항을 생성합니다.
Important
24시간 내에 일괄 처리 요청을 처리하는 것을 목표로 하며, 더 오래 걸리는 작업은 만료시키지 않습니다. 언제든지 작업을 취소할 수 있습니다. 작업을 취소하면 남아 있는 작업은 취소되고 이미 완료된 작업은 반환됩니다. 완료된 작업에 대해서는 요금이 부과됩니다.
저장된 데이터는 지정된 Azure 지역에 유지되는 반면, 유추를 위해 데이터는 모든 Azure OpenAI 위치에서 처리될 수 있습니다. 데이터 보존에 대해 자세히 알아보기.
Batch 지원
글로벌 일괄 처리 모델 가용성
| 지역 | o3-mini, 2025-01-31 | gpt-4o, 2024-05-13 | gpt-4o, 2024-08-06 | gpt-4o, 2024-11-20 | gpt-4o-mini, 2024-07-18 | gpt-4, 0613 | gpt-4, turbo-2024-04-09 | gpt-35-turbo, 0613 | gpt-35-turbo, 1106 | gpt-35-turbo, 0125 |
|---|---|---|---|---|---|---|---|---|---|---|
| australiaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| brazilsouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| germanywestcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| japaneast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| koreacentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| polandcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southafricanorth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 스웨덴 중부 | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 스위스 북부 | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
에 액세스 o3-mini하려면 등록이 필요합니다. 자세한 내용은 추론 모델 가이드를 참조하세요.
다음 모델은 글로벌 일괄 처리를 지원합니다.
| 모델 | 버전 | 입력 형식 |
|---|---|---|
o3-mini |
2025-01-31 | text |
gpt-4o |
2024-08-06 | 텍스트 + 이미지 |
gpt-4o-mini |
2024-07-18 | 텍스트 + 이미지 |
gpt-4o |
2024-05-13 | 텍스트 + 이미지 |
gpt-4 |
turbo-2024-04-09 | text |
gpt-4 |
0613 | text |
gpt-35-turbo |
0125 | text |
gpt-35-turbo |
1106 | text |
gpt-35-turbo |
0613 | text |
현재 글로벌 일괄 처리가 지원되는 지역/모델에 대한 최신 정보는 모델 페이지를 참조하세요.
API 지원
| API 버전 | |
|---|---|
| 최신 GA API 릴리스: | 2024-10-21 |
| 최신 미리 보기 API 릴리스: | 2025-01-01-preview |
지원은 다음에서 처음 추가되었습니다. 2024-07-01-preview
기능 지원
현재 지원되지 않는 항목은 다음과 같습니다.
- 도우미 API와 통합.
- Azure OpenAI On Your Data 기능과 통합.
참고 항목
이제 구조적 출력이 전역 Batch에서 지원됩니다.
일괄 처리 배포
참고 항목
Azure AI Foundry 포털에서 일괄 처리 배포 유형이 다음과 같이 Global-BatchData Zone Batch표시됩니다. Azure OpenAI 배포 유형에 대한 자세한 내용은 배포 유형 가이드를 참조하세요.

팁
큐에 추가된 토큰 할당량 부족으로 인한 작업 오류를 방지하려면 모든 전역 일괄 처리 모델 배포에 동적 할당량 을 사용하도록 설정하는 것이 좋습니다. 동적 할당량을 사용하면 추가 용량을 사용할 수 있을 때 배포에서 더 많은 할당량을 기회적으로 활용할 수 있습니다. 동적 할당량이 해제되면 배포는 배포를 만들 때 정의된 큐에 포함된 토큰 제한까지만 요청을 처리할 수 있습니다.
필수 조건
- Azure 구독 – 체험 구독을 만듭니다.
- 배포 유형이
Global-Batch인 Azure OpenAI 리소스가 배포되었습니다. 이 프로세스에 대한 도움말은 리소스 만들기 및 모델 배포 가이드를 참조하세요.
배치 파일 준비
미세 조정과 마찬가지로 글로벌 일괄 처리는 JSON 줄(.jsonl) 형식의 파일을 사용합니다. 다음은 다양한 형식의 지원되는 콘텐츠가 포함된 일부 파일 예입니다.
입력 형식
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id는 지정된 응답에 해당하는 개별 일괄 처리 요청을 식별하는 데 필요합니다. 응답은 .jsonl 배치 파일에 정의된 순서와 동일한 순서로 반환되지 않습니다.
model 특성은 유추 응답을 대상으로 하는 글로벌 일괄 처리 배포의 이름과 일치하도록 설정해야 합니다.
Important
model 특성은 유추 응답을 대상으로 하는 글로벌 일괄 처리 배포의 이름과 일치하도록 설정해야 합니다.
배치 파일의 각 줄에 동일한 글로벌 배치 모델 배포 이름이 있어야 합니다. 다른 배포를 대상으로 하려면 별도의 배치 파일/작업에서 수행해야 합니다.
최상의 성능을 위해 각 파일에 몇 줄만 있는 작은 파일 수가 아니라 일괄 처리를 위해 대용량 파일을 제출하는 것이 좋습니다.
입력 파일 만들기
이 문서에서는 test.jsonl이라는 이름의 파일을 만들고 위의 표준 입력 코드 블록의 콘텐츠를 해당 파일에 복사할 예정입니다. 파일의 각 줄에 글로벌 일괄 처리 배포 이름을 수정하여 추가해야 합니다.
배치 파일 업로드
입력 파일이 준비되면 먼저 파일을 업로드하여 일괄 작업을 시작해야 합니다. 파일 업로드는 프로그래밍 방식으로나 Studio를 통해 이루어질 수 있습니다.
Azure AI Foundry 포털에 로그인합니다.
글로벌 일괄 처리 모델 배포가 가능한 Azure OpenAI 리소스를 선택합니다.
Batch 작업>+일괄 처리 작업 만들기를 선택합니다.
일괄 처리 데이터>파일 업로드> 드롭다운에서 파일 업로드를 선택하고 이전 단계인 >다음에서 만든
test.jsonl파일의 경로를 제공합니다.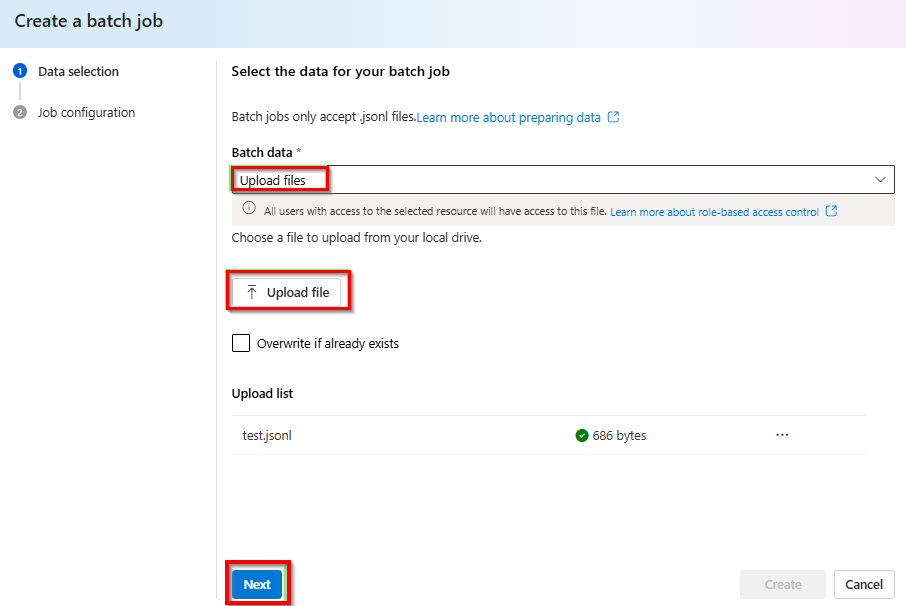


일괄 작업 만들기
만들기를 선택하여 일괄 작업을 시작합니다.

일괄 작업 진행률 추적
작업이 만들어지면 가장 최근에 만들어진 작업의 작업 ID를 선택하여 작업의 진행률을 모니터링할 수 있습니다. 기본적으로 가장 최근에 만든 일괄 작업의 상태 페이지로 이동합니다.

오른쪽 창에서 작업 상태를 추적할 수 있습니다.

일괄 작업 출력 파일 검색
작업이 완료되었거나 터미널 상태에 도달하면 오류 파일과 출력 파일이 생성되며 아래쪽 화살표 아이콘을 선택하면 검토를 위해 다운로드할 수 있습니다.

일괄 처리 취소
진행 중인 일괄 처리를 취소합니다. 일괄 처리는 cancelled로 변경되기 전까지 최대 10분 동안 cancelling 상태를 유지하며, 변경되면 출력 파일에 부분적인 결과(있는 경우)가 제공됩니다.

필수 조건
- Azure 구독 – 체험 구독을 만듭니다.
- Python 3.8 이상 버전
- 다음 Python 라이브러리:
openai - Jupyter 노트북
- 배포 유형이
Global-Batch인 Azure OpenAI 리소스가 배포되었습니다. 이 프로세스에 대한 도움말은 리소스 만들기 및 모델 배포 가이드를 참조하세요.
이 문서의 단계는 Jupyter Notebooks에서 순차적으로 실행되도록 설계되었습니다. 이러한 이유로 예의 시작 부분에서 Azure OpenAI 클라이언트를 한 번만 인스턴스화합니다. 단계를 순서 없이 실행하려면 해당 호출의 일부로 Azure OpenAI 클라이언트를 설정해야 하는 경우가 많습니다.
OpenAI Python 라이브러리가 이미 설치되어 있더라도 설치를 최신 버전으로 업그레이드해야 할 수도 있습니다.
!pip install openai --upgrade
배치 파일 준비
미세 조정과 마찬가지로 글로벌 일괄 처리는 JSON 줄(.jsonl) 형식의 파일을 사용합니다. 다음은 다양한 형식의 지원되는 콘텐츠가 포함된 일부 파일 예입니다.
입력 형식
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id는 지정된 응답에 해당하는 개별 일괄 처리 요청을 식별하는 데 필요합니다. 응답은 .jsonl 배치 파일에 정의된 순서와 동일한 순서로 반환되지 않습니다.
model 특성은 유추 응답을 대상으로 하는 글로벌 일괄 처리 배포의 이름과 일치하도록 설정해야 합니다.
Important
model 특성은 유추 응답을 대상으로 하는 글로벌 일괄 처리 배포의 이름과 일치하도록 설정해야 합니다.
배치 파일의 각 줄에 동일한 글로벌 배치 모델 배포 이름이 있어야 합니다. 다른 배포를 대상으로 하려면 별도의 배치 파일/작업에서 수행해야 합니다.
최상의 성능을 위해 각 파일에 몇 줄만 있는 작은 파일 수가 아니라 일괄 처리를 위해 대용량 파일을 제출하는 것이 좋습니다.
입력 파일 만들기
이 문서에서는 test.jsonl이라는 이름의 파일을 만들고 위의 표준 입력 코드 블록의 콘텐츠를 해당 파일에 복사합니다. 파일의 각 줄에 글로벌 일괄 처리 배포 이름을 수정하여 추가해야 합니다. Jupyter Notebook을 실행하는 것과 동일한 디렉터리에 이 파일을 저장합니다.
배치 파일 업로드
입력 파일이 준비되면 먼저 파일을 업로드하여 일괄 작업을 시작해야 합니다. 파일 업로드는 프로그래밍 방식으로나 Studio를 통해 이루어질 수 있습니다. 이 예에서는 키와 엔드포인트 값 대신 환경 변수를 사용합니다. Python에서 환경 변수를 사용하는 데 익숙하지 않은 경우 빠른 시작 중 하나를 참조하세요. 여기에는 환경 변수를 설정하는 과정이 단계별로 설명되어 있습니다.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch"
)
print(file.model_dump_json(indent=2))
file_id = file.id
출력:
{
"id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"bytes": 815,
"created_at": 1722476551,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": null,
"status_details": null
}
일괄 작업 만들기
파일이 성공적으로 업로드되면 일괄 처리를 위해 파일을 제출할 수 있습니다.
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
참고 항목
현재 완료 창은 24시간으로 설정되어야 합니다. 24시간 이외의 다른 값을 설정하면 작업이 실패합니다. 24시간 이상 걸리는 작업은 취소될 때까지 계속 실행됩니다.
출력:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
일괄 작업 진행률 추적
일괄 작업을 성공적으로 만든 후에는 Studio나 프로그래밍 방식으로 진행률을 모니터링할 수 있습니다. 일괄 작업 진행률을 확인할 때는 각 상태 호출 사이에 최소 60초 동안 기다리는 것이 좋습니다.
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
출력:
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
가능한 상태 값은 다음과 같습니다.
| 상태 | 설명 |
|---|---|
validating |
일괄 처리를 시작하기 전에 입력 파일의 유효성을 검사하고 있습니다. |
failed |
입력 파일의 유효성이 검사 과정에 실패했습니다. |
in_progress |
입력 파일이 성공적으로 유효성 검사되었으며 현재 일괄 처리가 실행 중입니다. |
finalizing |
일괄 처리가 완료되었으며 결과를 준비 중입니다. |
completed |
일괄 처리가 완료되었고 결과가 준비되었습니다. |
expired |
일괄 처리를 24시간 내에 완료할 수 없었습니다. |
cancelling |
일괄 처리가 cancelled 중입니다(적용되기까지 최대 10분이 소요될 수 있습니다.). |
cancelled |
일괄 처리는 cancelled입니다. |
작업 상태 세부 정보를 검사하려면 다음을 실행할 수 있습니다.
print(batch_response.model_dump_json(indent=2))
출력:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
error_file_id와 별도의 output_file_id가 모두 있다는 점에 주목합니다.
error_file_id를 사용하여 일괄 작업에서 발생하는 문제를 디버깅하기 위해 도움을 받으세요.
일괄 작업 출력 파일 검색
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
출력:
간결하게 하기 위해, 출력에서 단 하나의 채팅 완료 응답만 포함했습니다. 이 문서의 단계를 따르면 아래와 비슷한 세 가지 응답이 나올 것입니다.
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
추가 일괄 처리 명령
일괄 처리 취소
진행 중인 일괄 처리를 취소합니다. 일괄 처리는 cancelled로 변경되기 전까지 최대 10분 동안 cancelling 상태를 유지하며, 변경되면 출력 파일에 부분적인 결과(있는 경우)가 제공됩니다.
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
일괄 처리 나열
특정 Azure OpenAI 리소스에 대한 일괄 처리 작업을 나열합니다.
client.batches.list()
Python 라이브러리의 목록 메서드는 페이지를 매깁니다.
모든 작업을 나열하려면 다음을 수행합니다.
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
일괄 처리 나열(미리 보기)
REST API를 사용하여 추가 정렬/필터링 옵션을 사용하여 모든 일괄 처리 작업을 나열합니다.
아래 예제에서는 필터를 generate_time_filter 더 쉽게 생성할 수 있는 함수를 제공합니다. 이 함수를 사용하지 않으려면 필터 문자열의 형식은 다음과 같습니다 created_at gt 1728860560 and status eq 'Completed'.
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2024-10-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
출력:
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
필수 조건
- Azure 구독 – 체험 구독을 만듭니다.
- 배포 유형이
Global-Batch인 Azure OpenAI 리소스가 배포되었습니다. 이 프로세스에 대한 도움말은 리소스 만들기 및 모델 배포 가이드를 참조하세요.
배치 파일 준비
미세 조정과 마찬가지로 글로벌 일괄 처리는 JSON 줄(.jsonl) 형식의 파일을 사용합니다. 다음은 다양한 형식의 지원되는 콘텐츠가 포함된 일부 파일 예입니다.
입력 형식
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id는 지정된 응답에 해당하는 개별 일괄 처리 요청을 식별하는 데 필요합니다. 응답은 .jsonl 배치 파일에 정의된 순서와 동일한 순서로 반환되지 않습니다.
model 특성은 유추 응답을 대상으로 하는 글로벌 일괄 처리 배포의 이름과 일치하도록 설정해야 합니다.
Important
model 특성은 유추 응답을 대상으로 하는 글로벌 일괄 처리 배포의 이름과 일치하도록 설정해야 합니다.
배치 파일의 각 줄에 동일한 글로벌 배치 모델 배포 이름이 있어야 합니다. 다른 배포를 대상으로 하려면 별도의 배치 파일/작업에서 수행해야 합니다.
최상의 성능을 위해 각 파일에 몇 줄만 있는 작은 파일 수가 아니라 일괄 처리를 위해 대용량 파일을 제출하는 것이 좋습니다.
입력 파일 만들기
이 문서에서는 test.jsonl이라는 이름의 파일을 만들고 위의 표준 입력 코드 블록의 콘텐츠를 해당 파일에 복사합니다. 파일의 각 줄에 글로벌 일괄 처리 배포 이름을 수정하여 추가해야 합니다.
배치 파일 업로드
입력 파일이 준비되면 먼저 파일을 업로드하여 일괄 작업을 시작해야 합니다. 파일 업로드는 프로그래밍 방식으로나 Studio를 통해 이루어질 수 있습니다. 이 예에서는 키와 엔드포인트 값 대신 환경 변수를 사용합니다. Python에서 환경 변수를 사용하는 데 익숙하지 않은 경우 빠른 시작 중 하나를 참조하세요. 여기에는 환경 변수를 설정하는 과정이 단계별로 설명되어 있습니다.
Important
주의해서 API 키를 사용합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요. API 키를 사용하는 경우 Azure Key Vault에 안전하게 저장합니다. 앱에서 API 키를 안전하게 사용하는 방법에 대한 자세한 내용은 Azure Key Vault를 사용하여 API 키를 참조하세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2024-10-21 \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json"
위 코드는 test.jsonl 파일에 대해 특정 파일 경로를 가정합니다. 필요에 따라 로컬 시스템에 맞게 이 파일 경로를 조정합니다.
출력:
{
"status": "pending",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
파일 업로드 상태 추적
업로드 파일의 크기에 따라서는 완전히 업로드되어 처리되기까지 시간이 걸릴 수 있습니다. 파일 업로드 상태를 확인하려면 다음을 실행합니다.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
출력:
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
일괄 작업 만들기
파일이 성공적으로 업로드되면 일괄 처리를 위해 파일을 제출할 수 있습니다.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h"
}'
참고 항목
현재 완료 창은 24시간으로 설정되어야 합니다. 24시간 이외의 다른 값을 설정하면 작업이 실패합니다. 24시간 이상 걸리는 작업은 취소될 때까지 계속 실행됩니다.
출력:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
일괄 작업 진행률 추적
일괄 작업을 성공적으로 만든 후에는 Studio나 프로그래밍 방식으로 진행률을 모니터링할 수 있습니다. 일괄 작업 진행률을 확인할 때는 각 상태 호출 사이에 최소 60초 동안 기다리는 것이 좋습니다.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
출력:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
가능한 상태 값은 다음과 같습니다.
| 상태 | 설명 |
|---|---|
validating |
일괄 처리를 시작하기 전에 입력 파일의 유효성을 검사하고 있습니다. |
failed |
입력 파일의 유효성이 검사 과정에 실패했습니다. |
in_progress |
입력 파일이 성공적으로 유효성 검사되었으며 현재 일괄 처리가 실행 중입니다. |
finalizing |
일괄 처리가 완료되었으며 결과를 준비 중입니다. |
completed |
일괄 처리가 완료되었고 결과가 준비되었습니다. |
expired |
일괄 처리를 24시간 내에 완료할 수 없었습니다. |
cancelling |
일괄 처리가 cancelled 중입니다(적용되기까지 최대 10분이 소요될 수 있습니다.). |
cancelled |
일괄 처리는 cancelled입니다. |
일괄 작업 출력 파일 검색
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
추가 일괄 처리 명령
일괄 처리 취소
진행 중인 일괄 처리를 취소합니다. 일괄 처리는 cancelled로 변경되기 전까지 최대 10분 동안 cancelling 상태를 유지하며, 변경되면 출력 파일에 부분적인 결과(있는 경우)가 제공됩니다.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
일괄 처리 나열
지정된 Azure OpenAI 리소스에 대한 기존 일괄 처리 작업을 나열합니다.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
목록 API 호출의 페이지가 매겨집니다. 응답에는 반복할 결과가 더 있을 때를 나타내는 부울 has_more 이 포함됩니다.
일괄 처리 나열(미리 보기)
REST API를 사용하여 추가 정렬/필터링 옵션을 사용하여 모든 일괄 처리 작업을 나열합니다.
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2024-10-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
오류 URL rejected: Malformed input to a URL function 공간을 방지하기 위해 .로 %20바뀝
Batch 제한
| 이름 제한 | 값 제한 |
|---|---|
| 리소스당 최대 파일 | 500 |
| 최대 입력 파일 크기 | 200MB |
| 파일당 최대 요청 수 | 100,000 |
일괄 처리 할당량
이 표는 일괄 처리 할당량 한도를 보여 줍니다. 글로벌 일괄 처리에 대한 할당량 값은 큐에 넣은 토큰으로 표현됩니다. 일괄 처리를 위해 파일을 제출하면 해당 파일에 있는 토큰의 수가 계산됩니다. 일괄 작업이 종료 상태에 도달할 때까지 해당 토큰은 큐에 넣은 총 토큰 한도에서 제외됩니다.
글로벌 일괄 처리
| 모델 | 기업 계약 | 기본값 | 월간 신용 카드 기반 구독 | MSDN 구독 | Azure for Students, 평가판 |
|---|---|---|---|---|---|
gpt-4o |
5 B | 200M | 50M | 90K | 해당 없음 |
gpt-4o-mini |
15 B | 1 B | 50M | 90K | 해당 없음 |
gpt-4-turbo |
300M | 80 M | 40M | 90K | 해당 없음 |
gpt-4 |
150M | 30M | 5M | 100K | 해당 없음 |
gpt-35-turbo |
10B | 1 B | 100M | 2 M | 50K |
o3-mini |
15 B | 1 B | 50M | 90K | 해당 없음 |
B = 10억 | M = 100만 | K = 1천
데이터 영역 일괄 처리
| 모델 | 기업 계약 | 기본값 | 월간 신용 카드 기반 구독 | MSDN 구독 | Azure for Students, 평가판 |
|---|---|---|---|---|---|
gpt-4o |
500M | 30M | 30M | 90K | 해당 없음 |
gpt-4o-mini |
1.5 B | 100M | 50M | 90K | 해당 없음 |
일괄 처리 개체
| 속성 | Type | 정의 |
|---|---|---|
id |
string | |
object |
string | batch |
endpoint |
string | 일괄 처리에 사용되는 API 엔드포인트입니다. |
errors |
개체 | |
input_file_id |
string | 일괄 처리에 대한 입력 파일의 ID입니다. |
completion_window |
string | 일괄 처리를 처리해야 하는 시간 프레임입니다. |
status |
string | 일괄 처리의 현재 상태입니다. 가능한 값: validating, failed, in_progress, finalizing, completed, expired, cancelling, cancelled. |
output_file_id |
string | 성공적으로 실행된 요청의 출력을 포함하는 파일의 ID입니다. |
error_file_id |
string | 오류가 있는 요청의 출력을 포함하는 파일의 ID입니다. |
created_at |
정수 | 이 일괄 처리가 만들어진 타임스탬프(Unix epoch 기준)입니다. |
in_progress_at |
정수 | 이 일괄 처리가 진행되기 시작한 타임스탬프(Unix epoch 기준)입니다. |
expires_at |
정수 | 이 일괄 처리가 만료되는 타임스탬프(Unix epoch 기준)입니다. |
finalizing_at |
정수 | 이 일괄 처리가 마무리되기 시작한 타임스탬프(Unix epoch 기준)입니다. |
completed_at |
정수 | 이 일괄 처리가 마무리되기 시작한 타임스탬프(Unix epoch 기준)입니다. |
failed_at |
정수 | 이 일괄 처리가 실패한 타임스탬프(Unix epoch 기준)입니다. |
expired_at |
정수 | 이 일괄 처리가 만료된 타임스탬프(Unix epoch 기준)입니다. |
cancelling_at |
정수 | 이 일괄 처리가 cancelling되기 시작한 타임스탬프(Unix epochs 기준)입니다. |
cancelled_at |
정수 | 이 일괄 처리가 cancelled된 타임스탬프(Unix epochs 기준)입니다. |
request_counts |
개체 | 개체 구조:total
정수 일괄 처리의 총 요청 수입니다. completed
정수 일괄 처리 중 성공적으로 완료된 요청 수입니다. failed
정수 일괄 처리 중 실패한 요청 수입니다. |
metadata |
map | 일괄 처리에 첨부할 수 있는 키-값 쌍의 집합입니다. 이 속성은 일괄 처리에 대한 추가 정보를 구조화된 형식으로 저장하는 데 유용할 수 있습니다. |
질문과 대답(FAQ)
일괄 처리 API와 함께 이미지를 사용할 수 있나요?
이 기능은 특정 다중 모달 모델에만 국한됩니다. 현재는 GPT-4o만 일괄 처리 요청의 일부로 이미지를 지원합니다. 이미지는 이미지 URL 또는 base64로 인코딩된 이미지 표현을 통해 입력으로 제공될 수 있습니다. 현재 GPT-4 Turbo에서는 일괄 처리용 이미지가 지원되지 않습니다.
미세 조정된 모델에 일괄 처리 API를 사용할 수 있나요?
현재는 지원되지 않습니다.
포함 모델에 일괄 처리 API를 사용할 수 있나요?
현재는 지원되지 않습니다.
콘텐츠 필터링은 글로벌 일괄 처리 배포에서 작동하나요?
예. 다른 배포 유형과 마찬가지로 콘텐츠 필터를 만들고 이를 글로벌 일괄 처리 배포 유형과 연결할 수 있습니다.
추가 할당량을 요청할 수 있나요?
예, Azure AI Foundry 포털의 할당량 페이지에서. 기본 할당량은 할당량 및 한도 문서에서 확인할 수 있습니다.
API가 24시간 내에 내 요청을 완료하지 못하면 어떻게 되나요?
24시간 내에 이러한 요청을 처리하는 것을 목표로 하며, 더 오래 걸리는 작업은 만료시키지 않습니다. 언제든지 작업을 취소할 수 있습니다. 작업을 취소하면 남아 있는 작업은 취소되고 이미 완료된 작업은 반환됩니다. 완료된 작업에 대해서는 요금이 부과됩니다.
일괄 처리를 사용하면 얼마나 많은 요청을 큐에 넣을 수 있나요?
일괄 처리할 수 있는 요청 수에는 고정된 제한이 없지만, 이는 큐에 넣은 토큰 할당량에 따라 달라집니다. 큐에 넣은 토큰 할당량에는 한 번에 큐에 넣을 수 있는 최대 입력 토큰 수가 포함됩니다.
일괄 처리 요청이 완료되면 입력 토큰이 지워지고 일괄 처리 속도 제한이 다시 설정됩니다. 제한은 큐에 있는 글로벌 요청 수에 따라 달라집니다. 일괄 처리 API 큐가 일괄 처리를 빠르게 처리하면 일괄 처리 속도 제한이 더 빨리 다시 설정됩니다.
문제 해결
status가 Completed이면 작업이 성공한 것입니다. 작업이 성공하면 error_file_id가 생성되지만, 0바이트의 빈 파일과 연결됩니다.
작업이 실패하면 errors 속성에서 실패에 대한 세부 정보를 찾을 수 있습니다.
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
“code”: “empty_file”,
“message”: “The input file is empty. Please ensure that the batch contains at least one request.”
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
오류 코드
| 오류 코드 | 정의 |
|---|---|
invalid_json_line |
입력 파일의 한 줄(또는 여러 줄)을 유효한 JSON으로 구문 분석할 수 없습니다. JSON 표준에 따라 오타가 없고, 여는 괄호와 닫는 괄호가 적절하며, 따옴표가 사용되었는지 확인한 후 요청을 다시 제출하세요. |
too_many_tasks |
입력 파일의 요청 수가 허용된 최댓값인 100,000을 초과합니다. 전체 요청 수가 100,000개 이하인지 확인하고 작업을 다시 제출하세요. |
url_mismatch |
입력 파일의 행에 나머지 행과 일치하지 않는 URL이 있거나, 입력 파일에 지정된 URL이 예상 엔드포인트 URL과 일치하지 않습니다. 모든 요청 URL이 동일하고 Azure OpenAI 배포와 연결된 엔드포인트 URL과 일치하는지 확인하세요. |
model_not_found |
입력 파일의 model 속성에 지정된 Azure OpenAI 모델 배포 이름을 찾을 수 없습니다.이 이름이 유효한 Azure OpenAI 모델 배포를 가리키는지 확인하세요. |
duplicate_custom_id |
이 요청의 사용자 지정 ID는 다른 요청의 사용자 지정 ID와 중복됩니다. |
empty_batch |
일괄 처리의 각 요청에 대해 사용자 지정 ID 매개 변수가 고유한지 확인하려면 입력 파일을 확인하세요. |
model_mismatch |
입력 파일에 있는 이 요청의 model 속성에 지정된 Azure OpenAI 모델 배포 이름이 파일의 나머지 부분과 일치하지 않습니다.일괄 처리의 모든 요청이 요청 속성에서 동일한 Azure OpenAI 서비스 모델 배포를 model 가리키는지 확인하세요. |
invalid_request |
입력 줄의 스키마가 잘못되었거나 배포 SKU가 잘못되었습니다. 입력 파일에 있는 요청의 속성이 예상 입력 속성과 일치하는지 확인하고, 일괄 처리 API 요청의 경우 Azure OpenAI 배포 SKU가 globalbatch인지 확인하세요. |
알려진 문제
- Azure CLI를 사용하여 배포된 리소스는 Azure OpenAI 글로벌 일괄 처리와 함께 기본적으로 작동하지 않습니다. 이는 이 방법을 사용하여 배포된 리소스에
https://your-resource-name.openai.azure.com패턴을 따르지 않는 엔드포인트 하위 도메인이 있는 문제로 인해 발생합니다. 이 문제를 해결하려면 배포 프로세스의 일부로 하위 도메인 설정을 올바르게 처리하는 다른 일반적인 배포 방법 중 하나를 사용하여 새 Azure OpenAI 리소스를 배포해야 합니다.