빠른 시작: Azure OpenAI 오디오 생성 사용 시작
gpt-4o-audio-preview 및 gpt-4o-mini-audio-preview 모델은 기존 /chat/completions API에 오디오 형식을 도입합니다. 오디오 모델은 텍스트 및 음성 기반 상호 작용 및 오디오 분석에서 AI 애플리케이션의 잠재력을 확장합니다. 지원되는 gpt-4o-audio-preview 형식 및 gpt-4o-mini-audio-preview 모델에는 텍스트, 오디오 및 텍스트 + 오디오가 포함됩니다.
다음은 예제 사용 사례와 함께 지원되는 형식의 표입니다.
| 형식 입력 | 형식 출력 | 사용 사례 |
|---|---|---|
| Text | 텍스트 + 오디오 | 텍스트 음성 변환, 오디오 북 생성 |
| 오디오 | 텍스트 + 오디오 | 오디오 전사, 오디오 북 생성 |
| 오디오 | Text | 오디오 대화 내용 기록 |
| 텍스트 + 오디오 | 텍스트 + 오디오 | 오디오 북 생성 |
| 텍스트 + 오디오 | Text | 오디오 대화 내용 기록 |
오디오 생성 기능을 사용하여 보다 동적 및 대화형 AI 애플리케이션을 달성할 수 있습니다. 오디오 입력 및 출력을 지원하는 모델을 사용하면 프롬프트에 음성 오디오 응답을 생성하고 오디오 입력을 사용하여 모델을 프롬프트할 수 있습니다.
지원되는 모델
현재만 gpt-4o-audio-preview 버전 gpt-4o-mini-audio-preview : 2024-12-17 오디오 생성을 지원합니다.
지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
현재 오디오 출력에는 Alloy, Echo 및 Shimmer 음성이 지원됩니다.
최대 오디오 파일 크기는 20MB입니다.
참고 항목
실시간 API는 완성 API 와 동일한 기본 GPT-4o 오디오 모델을 사용하지만 대기 시간이 짧은 실시간 오디오 상호 작용에 최적화되어 있습니다.
API 지원
오디오 완성에 대한 지원이 API 버전 2025-01-01-preview에서 처음 추가되었습니다.
오디오 생성을 위한 모델 배포
Azure AI Foundry 포털에서 모델을 배포 gpt-4o-mini-audio-preview 하려면 다음을 수행합니다.
- Azure AI Foundry 포털의 Azure OpenAI 서비스 페이지 로 이동합니다. Azure OpenAI 서비스 리소스 및 배포된 모델이 있는 Azure 구독으로 로그인했는지
gpt-4o-mini-audio-preview확인합니다. - 왼쪽 창의 플레이그라운드 아래에서 채팅 놀이터를 선택합니다.
- 기본 모델에서 + 새 배포>만들기를 선택하여 배포 창을 엽니다.
- 모델을 검색하여 선택한
gpt-4o-mini-audio-preview다음 선택한 리소스에 배포를 선택합니다. - 배포 마법사에서 모델 버전을 선택합니다
2024-12-17. - 마법사에 따라 모델 배포를 완료합니다.
이제 모델을 배포 gpt-4o-mini-audio-preview 했으므로 Azure AI Foundry 포털 채팅 플레이그라운드 또는 채팅 완료 API에서 상호 작용할 수 있습니다.
GPT-4o 오디오 생성 사용
Azure AI Foundry 포털의 채팅 플레이그라운드에서 배포된 gpt-4o-mini-audio-preview 모델과 채팅하려면 다음 단계를 수행합니다.
Azure AI Foundry 포털의 Azure OpenAI 서비스 페이지 로 이동합니다. Azure OpenAI 서비스 리소스 및 배포된 모델이 있는 Azure 구독으로 로그인했는지
gpt-4o-mini-audio-preview확인합니다.왼쪽 창의 리소스 놀이터 아래에서 채팅 놀이터를 선택합니다.
배포 드롭다운에서 배포된
gpt-4o-mini-audio-preview모델을 선택합니다.모델과 채팅을 시작하고 오디오 응답을 듣습니다.
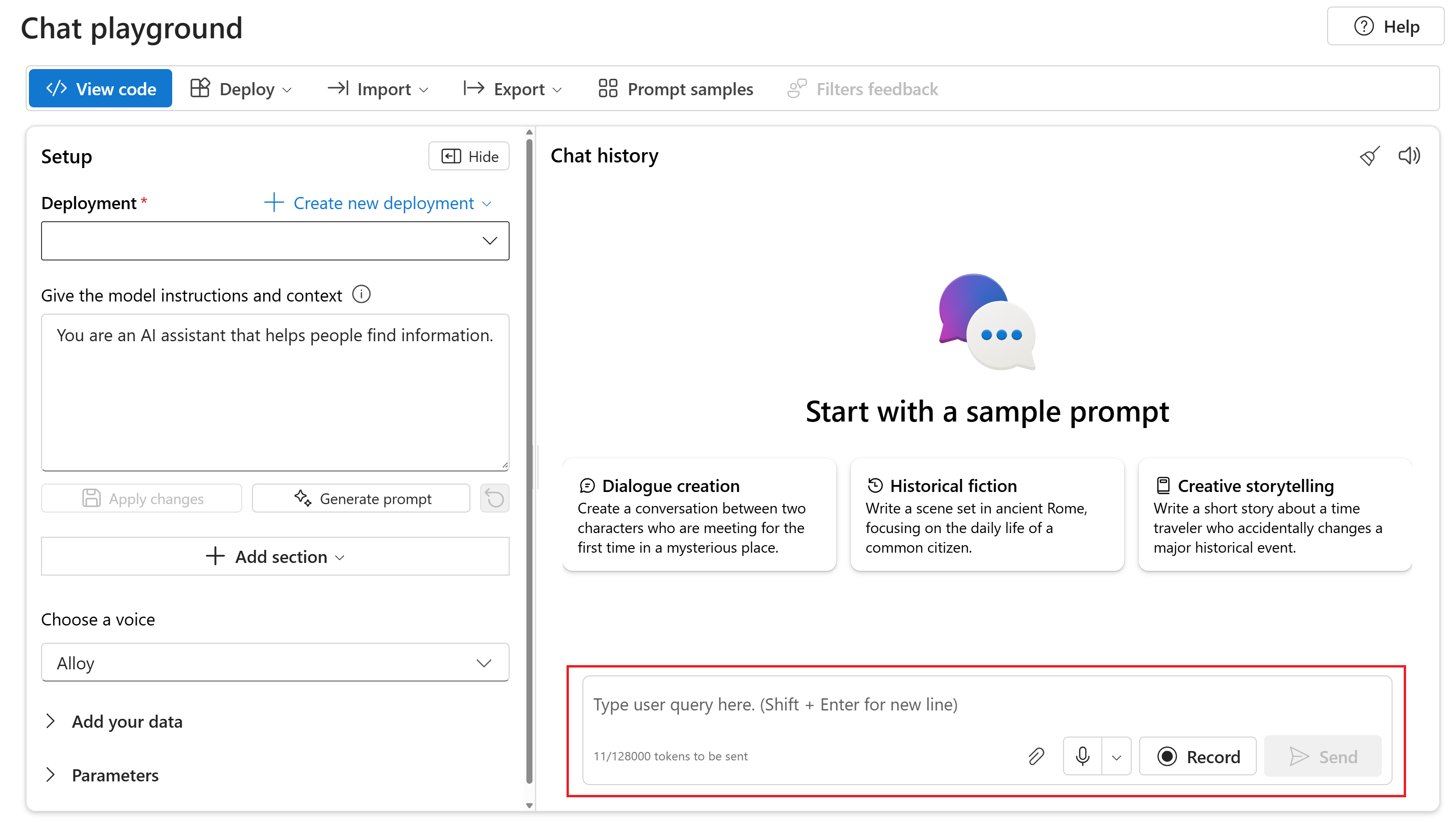
다음이 가능합니다.
- 오디오 프롬프트를 녹음합니다.
- 채팅에 오디오 파일을 첨부합니다.
- 텍스트 프롬프트를 입력합니다.

참조 설명서 | 라이브러리 소스 코드 | 패키지(npm) | 샘플
gpt-4o-audio-preview 및 gpt-4o-mini-audio-preview 모델은 기존 /chat/completions API에 오디오 형식을 도입합니다. 오디오 모델은 텍스트 및 음성 기반 상호 작용 및 오디오 분석에서 AI 애플리케이션의 잠재력을 확장합니다. 지원되는 gpt-4o-audio-preview 형식 및 gpt-4o-mini-audio-preview 모델에는 텍스트, 오디오 및 텍스트 + 오디오가 포함됩니다.
다음은 예제 사용 사례와 함께 지원되는 형식의 표입니다.
| 형식 입력 | 형식 출력 | 사용 사례 |
|---|---|---|
| Text | 텍스트 + 오디오 | 텍스트 음성 변환, 오디오 북 생성 |
| 오디오 | 텍스트 + 오디오 | 오디오 전사, 오디오 북 생성 |
| 오디오 | Text | 오디오 대화 내용 기록 |
| 텍스트 + 오디오 | 텍스트 + 오디오 | 오디오 북 생성 |
| 텍스트 + 오디오 | Text | 오디오 대화 내용 기록 |
오디오 생성 기능을 사용하여 보다 동적 및 대화형 AI 애플리케이션을 달성할 수 있습니다. 오디오 입력 및 출력을 지원하는 모델을 사용하면 프롬프트에 음성 오디오 응답을 생성하고 오디오 입력을 사용하여 모델을 프롬프트할 수 있습니다.
지원되는 모델
현재만 gpt-4o-audio-preview 버전 gpt-4o-mini-audio-preview : 2024-12-17 오디오 생성을 지원합니다.
지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
현재 오디오 출력에는 Alloy, Echo 및 Shimmer 음성이 지원됩니다.
최대 오디오 파일 크기는 20MB입니다.
참고 항목
실시간 API는 완성 API 와 동일한 기본 GPT-4o 오디오 모델을 사용하지만 대기 시간이 짧은 실시간 오디오 상호 작용에 최적화되어 있습니다.
API 지원
오디오 완성에 대한 지원이 API 버전 2025-01-01-preview에서 처음 추가되었습니다.
필수 조건
- Azure 구독 - 체험 구독 만들기
- LTS 또는 ESM 지원을 Node.js.
- 지원되는 지역 중 하나에서 만든 Azure OpenAI 리소스입니다. 지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
- 그런 다음 Azure OpenAI 리소스를 사용하여
gpt-4o-mini-audio-preview모델을 배포해야 합니다. 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)> 역할 할당 추가에서 역할을 할당할 수 있습니다.
설정
애플리케이션을 포함할 새 폴더
audio-completions-quickstart를 만들고 다음 명령을 사용하여 해당 폴더에서 Visual Studio Code를 엽니다.mkdir audio-completions-quickstart && code audio-completions-quickstart다음 명령을 사용하여
package.json만듭니다.npm init -ypackage.json다음 명령을 사용하여 ECMAScript로 업데이트합니다.npm pkg set type=module다음을 사용하여 JavaScript용 OpenAI 클라이언트 라이브러리를 설치합니다.
npm install openaiMicrosoft Entra ID로 권장되는 키 없는 인증의 경우 다음을 사용하여
@azure/identity패키지를 설치합니다.npm install @azure/identity
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다.
| 변수 이름 | 값 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 리소스를 검사할 때 키 및 엔드포인트 섹션에서 찾을 수 있습니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>모델 배포에서 찾을 수 있습니다. |
OPENAI_API_VERSION |
API 버전에 대해 자세히 알아봅니다. |
주의
SDK에서 권장되는 키 없는 인증을 사용하려면 환경 변수가 AZURE_OPENAI_API_KEY 설정되지 않았는지 확인합니다.
텍스트 입력에서 오디오 생성
다음 코드를 사용하여
to-audio.js파일을 만듭니다.require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };다음 명령을 사용하여 Azure에 로그인합니다.
az loginJavaScript 파일을 실행합니다.
node to-audio.js
응답을 얻기 위해 잠시 기다립니다.
텍스트 입력에서 오디오 생성을 위한 출력
스크립트는 스크립트와 동일한 디렉터리에 dog.wav 오디오 파일을 생성합니다. 오디오 파일에는 "골든 리트리버가 좋은 가족 개인가요?" 프롬프트에 대한 음성 응답이 포함되어 있습니다.
오디오 입력에서 오디오 및 텍스트 생성
다음 코드를 사용하여
from-audio.js파일을 만듭니다.require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };다음 명령을 사용하여 Azure에 로그인합니다.
az loginJavaScript 파일을 실행합니다.
node from-audio.js
응답을 얻기 위해 잠시 기다립니다.
오디오 입력에서 오디오 및 텍스트 생성을 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 또한 스크립트와 동일한 디렉터리에 analysis.wav 오디오 파일을 생성합니다. 오디오 파일에는 프롬프트에 대한 음성 응답이 포함됩니다.
오디오 생성 및 다중 턴 채팅 완료 사용
다음 코드를 사용하여
multi-turn.js파일을 만듭니다.require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };다음 명령을 사용하여 Azure에 로그인합니다.
az loginJavaScript 파일을 실행합니다.
node multi-turn.js
응답을 얻기 위해 잠시 기다립니다.
다중 턴 채팅 완료를 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 그런 다음, 다중 턴 채팅 완료를 통해 음성 오디오 입력을 간략하게 요약합니다.
라이브러리 소스 코드 | 패키지 | 샘플
gpt-4o-audio-preview 및 gpt-4o-mini-audio-preview 모델은 기존 /chat/completions API에 오디오 형식을 도입합니다. 오디오 모델은 텍스트 및 음성 기반 상호 작용 및 오디오 분석에서 AI 애플리케이션의 잠재력을 확장합니다. 지원되는 gpt-4o-audio-preview 형식 및 gpt-4o-mini-audio-preview 모델에는 텍스트, 오디오 및 텍스트 + 오디오가 포함됩니다.
다음은 예제 사용 사례와 함께 지원되는 형식의 표입니다.
| 형식 입력 | 형식 출력 | 사용 사례 |
|---|---|---|
| Text | 텍스트 + 오디오 | 텍스트 음성 변환, 오디오 북 생성 |
| 오디오 | 텍스트 + 오디오 | 오디오 전사, 오디오 북 생성 |
| 오디오 | Text | 오디오 대화 내용 기록 |
| 텍스트 + 오디오 | 텍스트 + 오디오 | 오디오 북 생성 |
| 텍스트 + 오디오 | Text | 오디오 대화 내용 기록 |
오디오 생성 기능을 사용하여 보다 동적 및 대화형 AI 애플리케이션을 달성할 수 있습니다. 오디오 입력 및 출력을 지원하는 모델을 사용하면 프롬프트에 음성 오디오 응답을 생성하고 오디오 입력을 사용하여 모델을 프롬프트할 수 있습니다.
지원되는 모델
현재만 gpt-4o-audio-preview 버전 gpt-4o-mini-audio-preview : 2024-12-17 오디오 생성을 지원합니다.
지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
현재 오디오 출력에는 Alloy, Echo 및 Shimmer 음성이 지원됩니다.
최대 오디오 파일 크기는 20MB입니다.
참고 항목
실시간 API는 완성 API 와 동일한 기본 GPT-4o 오디오 모델을 사용하지만 대기 시간이 짧은 실시간 오디오 상호 작용에 최적화되어 있습니다.
API 지원
오디오 완성에 대한 지원이 API 버전 2025-01-01-preview에서 처음 추가되었습니다.
이 가이드를 사용하여 Python용 Azure OpenAI SDK를 사용하여 오디오 생성을 시작합니다.
필수 구성 요소
- Azure 구독 체험 계정 만들기
- Python 3.8 이상 버전 Python 3.10 이상을 사용하는 것이 좋지만 Python 3.8 이상이 필요합니다. 적합한 Python 버전이 설치되어 있지 않은 경우 운영 체제에 Python을 설치하는 가장 쉬운 방법을 알아보려면 VS Code Python 자습서의 지침을 따릅니다.
- 지원되는 지역 중 하나에서 만든 Azure OpenAI 리소스입니다. 지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
- 그런 다음 Azure OpenAI 리소스를 사용하여
gpt-4o-mini-audio-preview모델을 배포해야 합니다. 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)> 역할 할당 추가에서 역할을 할당할 수 있습니다.
설정
애플리케이션을 포함할 새 폴더
audio-completions-quickstart를 만들고 다음 명령을 사용하여 해당 폴더에서 Visual Studio Code를 엽니다.mkdir audio-completions-quickstart && code audio-completions-quickstart가상 환경을 만듭니다. 이미 Python 3.10 이상이 설치되어 있는 경우 다음 명령을 사용하여 가상 환경을 만들 수 있습니다.
Python 환경을 활성화한다는 것은 명령줄에서
python또는pip를 실행할 때 애플리케이션의.venv폴더에 포함된 Python 인터프리터를 사용하게 된다는 의미입니다.deactivate명령을 사용하여 Python 가상 환경을 종료하고 나중에 필요할 때 다시 활성화할 수 있습니다.팁
이 자습서에 필요한 패키지를 설치하는 데 사용할 새 Python 환경을 만들고 활성화하는 것이 좋습니다. 글로벌 Python 설치에 패키지를 설치하지 마세요. Python 패키지를 설치할 때 항상 가상 또는 conda 환경을 사용해야 합니다. 그렇지 않으면 Python의 전역 설치를 중단시킬 수 있습니다.
다음을 사용하여 Python용 OpenAI 클라이언트 라이브러리를 설치합니다.
pip install openaiMicrosoft Entra ID로 권장되는 키 없는 인증의 경우 다음을 사용하여
azure-identity패키지를 설치합니다.pip install azure-identity
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다.
| 변수 이름 | 값 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 리소스를 검사할 때 키 및 엔드포인트 섹션에서 찾을 수 있습니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>모델 배포에서 찾을 수 있습니다. |
OPENAI_API_VERSION |
API 버전에 대해 자세히 알아봅니다. |
텍스트 입력에서 오디오 생성
다음 코드를 사용하여
to-audio.py파일을 만듭니다.import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Python 파일을 실행합니다.
python to-audio.py
응답을 얻기 위해 잠시 기다립니다.
텍스트 입력에서 오디오 생성을 위한 출력
스크립트는 스크립트와 동일한 디렉터리에 dog.wav 오디오 파일을 생성합니다. 오디오 파일에는 "골든 리트리버가 좋은 가족 개인가요?" 프롬프트에 대한 음성 응답이 포함되어 있습니다.
오디오 입력에서 오디오 및 텍스트 생성
다음 코드를 사용하여
from-audio.py파일을 만듭니다.import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Python 파일을 실행합니다.
python from-audio.py
응답을 얻기 위해 잠시 기다립니다.
오디오 입력에서 오디오 및 텍스트 생성을 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 또한 스크립트와 동일한 디렉터리에 analysis.wav 오디오 파일을 생성합니다. 오디오 파일에는 프롬프트에 대한 음성 응답이 포함됩니다.
오디오 생성 및 다중 턴 채팅 완료 사용
다음 코드를 사용하여
multi-turn.py파일을 만듭니다.import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Python 파일을 실행합니다.
python multi-turn.py
응답을 얻기 위해 잠시 기다립니다.
다중 턴 채팅 완료를 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 그런 다음, 다중 턴 채팅 완료를 통해 음성 오디오 입력을 간략하게 요약합니다.
gpt-4o-audio-preview 및 gpt-4o-mini-audio-preview 모델은 기존 /chat/completions API에 오디오 형식을 도입합니다. 오디오 모델은 텍스트 및 음성 기반 상호 작용 및 오디오 분석에서 AI 애플리케이션의 잠재력을 확장합니다. 지원되는 gpt-4o-audio-preview 형식 및 gpt-4o-mini-audio-preview 모델에는 텍스트, 오디오 및 텍스트 + 오디오가 포함됩니다.
다음은 예제 사용 사례와 함께 지원되는 형식의 표입니다.
| 형식 입력 | 형식 출력 | 사용 사례 |
|---|---|---|
| Text | 텍스트 + 오디오 | 텍스트 음성 변환, 오디오 북 생성 |
| 오디오 | 텍스트 + 오디오 | 오디오 전사, 오디오 북 생성 |
| 오디오 | Text | 오디오 대화 내용 기록 |
| 텍스트 + 오디오 | 텍스트 + 오디오 | 오디오 북 생성 |
| 텍스트 + 오디오 | Text | 오디오 대화 내용 기록 |
오디오 생성 기능을 사용하여 보다 동적 및 대화형 AI 애플리케이션을 달성할 수 있습니다. 오디오 입력 및 출력을 지원하는 모델을 사용하면 프롬프트에 음성 오디오 응답을 생성하고 오디오 입력을 사용하여 모델을 프롬프트할 수 있습니다.
지원되는 모델
현재만 gpt-4o-audio-preview 버전 gpt-4o-mini-audio-preview : 2024-12-17 오디오 생성을 지원합니다.
지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
현재 오디오 출력에는 Alloy, Echo 및 Shimmer 음성이 지원됩니다.
최대 오디오 파일 크기는 20MB입니다.
참고 항목
실시간 API는 완성 API 와 동일한 기본 GPT-4o 오디오 모델을 사용하지만 대기 시간이 짧은 실시간 오디오 상호 작용에 최적화되어 있습니다.
API 지원
오디오 완성에 대한 지원이 API 버전 2025-01-01-preview에서 처음 추가되었습니다.
필수 구성 요소
- Azure 구독 체험 계정 만들기
- Python 3.8 이상 버전 Python 3.10 이상을 사용하는 것이 좋지만 Python 3.8 이상이 필요합니다. 적합한 Python 버전이 설치되어 있지 않은 경우 운영 체제에 Python을 설치하는 가장 쉬운 방법을 알아보려면 VS Code Python 자습서의 지침을 따릅니다.
- 지원되는 지역 중 하나에서 만든 Azure OpenAI 리소스입니다. 지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
- 그런 다음 Azure OpenAI 리소스를 사용하여
gpt-4o-mini-audio-preview모델을 배포해야 합니다. 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)> 역할 할당 추가에서 역할을 할당할 수 있습니다.
설정
애플리케이션을 포함할 새 폴더
audio-completions-quickstart를 만들고 다음 명령을 사용하여 해당 폴더에서 Visual Studio Code를 엽니다.mkdir audio-completions-quickstart && code audio-completions-quickstart가상 환경을 만듭니다. 이미 Python 3.10 이상이 설치되어 있는 경우 다음 명령을 사용하여 가상 환경을 만들 수 있습니다.
Python 환경을 활성화한다는 것은 명령줄에서
python또는pip를 실행할 때 애플리케이션의.venv폴더에 포함된 Python 인터프리터를 사용하게 된다는 의미입니다.deactivate명령을 사용하여 Python 가상 환경을 종료하고 나중에 필요할 때 다시 활성화할 수 있습니다.팁
이 자습서에 필요한 패키지를 설치하는 데 사용할 새 Python 환경을 만들고 활성화하는 것이 좋습니다. 글로벌 Python 설치에 패키지를 설치하지 마세요. Python 패키지를 설치할 때 항상 가상 또는 conda 환경을 사용해야 합니다. 그렇지 않으면 Python의 전역 설치를 중단시킬 수 있습니다.
다음을 사용하여 Python용 OpenAI 클라이언트 라이브러리를 설치합니다.
pip install openaiMicrosoft Entra ID로 권장되는 키 없는 인증의 경우 다음을 사용하여
azure-identity패키지를 설치합니다.pip install azure-identity
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다.
| 변수 이름 | 값 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 리소스를 검사할 때 키 및 엔드포인트 섹션에서 찾을 수 있습니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>모델 배포에서 찾을 수 있습니다. |
OPENAI_API_VERSION |
API 버전에 대해 자세히 알아봅니다. |
텍스트 입력에서 오디오 생성
다음 코드를 사용하여
to-audio.py파일을 만듭니다.import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Python 파일을 실행합니다.
python to-audio.py
응답을 얻기 위해 잠시 기다립니다.
텍스트 입력에서 오디오 생성을 위한 출력
스크립트는 스크립트와 동일한 디렉터리에 dog.wav 오디오 파일을 생성합니다. 오디오 파일에는 "골든 리트리버가 좋은 가족 개인가요?" 프롬프트에 대한 음성 응답이 포함되어 있습니다.
오디오 입력에서 오디오 및 텍스트 생성
다음 코드를 사용하여
from-audio.py파일을 만듭니다.import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Python 파일을 실행합니다.
python from-audio.py
응답을 얻기 위해 잠시 기다립니다.
오디오 입력에서 오디오 및 텍스트 생성을 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 또한 스크립트와 동일한 디렉터리에 analysis.wav 오디오 파일을 생성합니다. 오디오 파일에는 프롬프트에 대한 음성 응답이 포함됩니다.
오디오 생성 및 다중 턴 채팅 완료 사용
다음 코드를 사용하여
multi-turn.py파일을 만듭니다.import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-mini-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Python 파일을 실행합니다.
python multi-turn.py
응답을 얻기 위해 잠시 기다립니다.
다중 턴 채팅 완료를 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 그런 다음, 다중 턴 채팅 완료를 통해 음성 오디오 입력을 간략하게 요약합니다.
참조 설명서 | 라이브러리 소스 코드 | 패키지(npm) | 샘플
gpt-4o-audio-preview 및 gpt-4o-mini-audio-preview 모델은 기존 /chat/completions API에 오디오 형식을 도입합니다. 오디오 모델은 텍스트 및 음성 기반 상호 작용 및 오디오 분석에서 AI 애플리케이션의 잠재력을 확장합니다. 지원되는 gpt-4o-audio-preview 형식 및 gpt-4o-mini-audio-preview 모델에는 텍스트, 오디오 및 텍스트 + 오디오가 포함됩니다.
다음은 예제 사용 사례와 함께 지원되는 형식의 표입니다.
| 형식 입력 | 형식 출력 | 사용 사례 |
|---|---|---|
| Text | 텍스트 + 오디오 | 텍스트 음성 변환, 오디오 북 생성 |
| 오디오 | 텍스트 + 오디오 | 오디오 전사, 오디오 북 생성 |
| 오디오 | Text | 오디오 대화 내용 기록 |
| 텍스트 + 오디오 | 텍스트 + 오디오 | 오디오 북 생성 |
| 텍스트 + 오디오 | Text | 오디오 대화 내용 기록 |
오디오 생성 기능을 사용하여 보다 동적 및 대화형 AI 애플리케이션을 달성할 수 있습니다. 오디오 입력 및 출력을 지원하는 모델을 사용하면 프롬프트에 음성 오디오 응답을 생성하고 오디오 입력을 사용하여 모델을 프롬프트할 수 있습니다.
지원되는 모델
현재만 gpt-4o-audio-preview 버전 gpt-4o-mini-audio-preview : 2024-12-17 오디오 생성을 지원합니다.
지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
현재 오디오 출력에는 Alloy, Echo 및 Shimmer 음성이 지원됩니다.
최대 오디오 파일 크기는 20MB입니다.
참고 항목
실시간 API는 완성 API 와 동일한 기본 GPT-4o 오디오 모델을 사용하지만 대기 시간이 짧은 실시간 오디오 상호 작용에 최적화되어 있습니다.
API 지원
오디오 완성에 대한 지원이 API 버전 2025-01-01-preview에서 처음 추가되었습니다.
필수 조건
- Azure 구독 - 체험 구독 만들기
- LTS 또는 ESM 지원을 Node.js.
- TypeScript 가 전역적으로 설치되었습니다.
- 지원되는 지역 중 하나에서 만든 Azure OpenAI 리소스입니다. 지역 가용성에 대한 자세한 내용은 모델 및 버전 설명서를 참조 하세요.
- 그런 다음 Azure OpenAI 리소스를 사용하여
gpt-4o-mini-audio-preview모델을 배포해야 합니다. 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)> 역할 할당 추가에서 역할을 할당할 수 있습니다.
설정
애플리케이션을 포함할 새 폴더
audio-completions-quickstart를 만들고 다음 명령을 사용하여 해당 폴더에서 Visual Studio Code를 엽니다.mkdir audio-completions-quickstart && code audio-completions-quickstart다음 명령을 사용하여
package.json만듭니다.npm init -ypackage.json다음 명령을 사용하여 ECMAScript로 업데이트합니다.npm pkg set type=module다음을 사용하여 JavaScript용 OpenAI 클라이언트 라이브러리를 설치합니다.
npm install openaiMicrosoft Entra ID로 권장되는 키 없는 인증의 경우 다음을 사용하여
@azure/identity패키지를 설치합니다.npm install @azure/identity
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다.
| 변수 이름 | 값 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 리소스를 검사할 때 키 및 엔드포인트 섹션에서 찾을 수 있습니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>모델 배포에서 찾을 수 있습니다. |
OPENAI_API_VERSION |
API 버전에 대해 자세히 알아봅니다. |
주의
SDK에서 권장되는 키 없는 인증을 사용하려면 환경 변수가 AZURE_OPENAI_API_KEY 설정되지 않았는지 확인합니다.
텍스트 입력에서 오디오 생성
다음 코드를 사용하여
to-audio.ts파일을 만듭니다.import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonTypeScript 코드를 변환하고 ECMAScript에 대해 다음 코드를 복사하는 파일을 만듭니다.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }TypeScript에서 JavaScript로 변환합니다.
tsc다음 명령을 사용하여 Azure에 로그인합니다.
az login다음 명령을 사용하여 코드를 실행합니다.
node to-audio.js
응답을 얻기 위해 잠시 기다립니다.
텍스트 입력에서 오디오 생성을 위한 출력
스크립트는 스크립트와 동일한 디렉터리에 dog.wav 오디오 파일을 생성합니다. 오디오 파일에는 "골든 리트리버가 좋은 가족 개인가요?" 프롬프트에 대한 음성 응답이 포함되어 있습니다.
오디오 입력에서 오디오 및 텍스트 생성
다음 코드를 사용하여
from-audio.ts파일을 만듭니다.import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonTypeScript 코드를 변환하고 ECMAScript에 대해 다음 코드를 복사하는 파일을 만듭니다.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }TypeScript에서 JavaScript로 변환합니다.
tsc다음 명령을 사용하여 Azure에 로그인합니다.
az login다음 명령을 사용하여 코드를 실행합니다.
node from-audio.js
응답을 얻기 위해 잠시 기다립니다.
오디오 입력에서 오디오 및 텍스트 생성을 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 또한 스크립트와 동일한 디렉터리에 analysis.wav 오디오 파일을 생성합니다. 오디오 파일에는 프롬프트에 대한 음성 응답이 포함됩니다.
오디오 생성 및 다중 턴 채팅 완료 사용
다음 코드를 사용하여
multi-turn.ts파일을 만듭니다.import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonTypeScript 코드를 변환하고 ECMAScript에 대해 다음 코드를 복사하는 파일을 만듭니다.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }TypeScript에서 JavaScript로 변환합니다.
tsc다음 명령을 사용하여 Azure에 로그인합니다.
az login다음 명령을 사용하여 코드를 실행합니다.
node multi-turn.js
응답을 얻기 위해 잠시 기다립니다.
다중 턴 채팅 완료를 위한 출력
스크립트는 음성 오디오 입력 요약의 대본을 생성합니다. 그런 다음, 다중 턴 채팅 완료를 통해 음성 오디오 입력을 간략하게 요약합니다.
리소스 정리
Azure OpenAI 리소스를 정리하고 제거하려면 해당 리소스를 삭제할 수 있습니다. 리소스를 삭제하기 전에 먼저 배포된 모델을 삭제해야 합니다.
관련 콘텐츠
- Azure OpenAI 배포 유형에 대해 자세히 알아봅니다.
- Azure OpenAI 할당량 및 제한에 대해 자세히 알아봅니다.