Data Science ツールキット - ロジスティック回帰モデル
デジタル広告 Xandr に対するユーザーの応答を予測するクライアントの機能をサポートするために、デシジョン ツリーに基づいてカスタム モデルを提供します。 Bonsai という使いやすいプログラミング言語を開発しました。これにより、ユーザーはデシジョン ツリーを作成して、行項目パラメーターを動的に設定できます。
デシジョン ツリーは、従来のターゲット ベースの予測形式にマップされる単純な離散モデルに適していますが、多くの次元と大規模なカテゴリ特徴のスパース マトリックスに対する量を効果的にモデル化するのに苦労しています。 Bonsai は理解しやすく、使いやすいですが、機能間の関係を効率的に表現できないため、マシンやデータ サイエンティストには必ずしも十分ではありません。 これらのより複雑なニーズに対して、Xandr はロジスティック回帰モデルを使用します。
ロジスティック回帰は、複数のシグナルの組み合わせから二項応答 (クリックまたはクリックしない、購入しない) の確率を予測するための基本的なアプローチです。 ロジスティック回帰データ サイエンティストを利用することで、より正確な予測を生成し、高いスケールで迅速にトレーニングできる、より表現力の高いモデルを実行できます。 カスタマイズされたアルゴリズムを構築することで、高度なデータ サイエンス ツールを使用するクライアントは、Xandr によって提供される組み込みの最適化よりも優れたパフォーマンスを実現でき、複雑なオフライン モデルをリアルタイムで実行できます。
ロジスティック回帰の数式
ロジスティック回帰は分類アルゴリズムです。 これは、一連の独立変数に基づいてバイナリの結果 (クリック、クリックしないなど) を予測するために使用されます。
ロジスティック回帰の数式は次のとおりです。
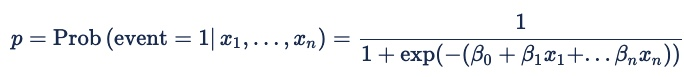
ここで、モデル化される確率 (p) は、二項の結果の確率です。 イベント = 1 またはイベント = 0。 オンライン広告の場合、イベントはクリック、ピクセル火災、または別のオンライン アクションです。 確率は、予測変数 x1 から xn の両方と、入札要求の特徴を表す暗黙的な変数セットの両方で条件付きです。 ベータ係数は、モデルが異なる予測変数に割り当てる重みです。
このイベント発生確率を期待値に変換するには、確率にイベントの値 (クリック予測の eCPC 目標など) を乗算し、推定に加算オフセットを追加し、最小/最大期待値の制限を適用して、誤予測の影響を軽減します。
イベントが発生する確率からインプレッションの期待値を導き出す数式は次のとおりです。
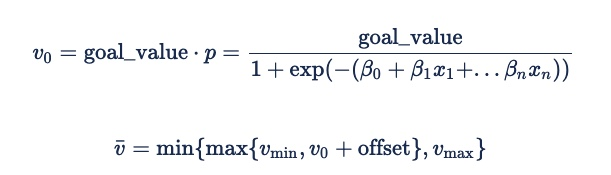
通常、オフセットは 0 になります。 ただし、負の値は、パフォーマンスの低いインベントリの配信を犠牲にしてパフォーマンスを確保するためのセキュリティ要因として役立つ場合があります。 これにより、広告主は、入札が非常に少なく、固定料金が発生する可能性がある代わりに入札しないようにします。
オンライン広告からのカテゴリ機能の使用例
オンライン広告には、多くのカテゴリ機能、つまり、多くの可能な値を持つ機能があります。 たとえば、ブラウザー、ドメイン、曜日などがあります。 これらの機能は通常、"one-hot" エンコード ("ダミー変数" を使用) で表されます。つまり、"browser = safari" の場合は x1、そうでない場合は 0、"browser = firefox" の場合は x2 は 1 になります。
これをロジスティック回帰式に入れると、次のようになります。

ブラウザーはカテゴリ別の特徴であるため、テーブル内の係数を表すことができます。
| ブラウザー | 係数 |
|---|---|
| サファリ | 1.2 |
| firefox | 0.8 |
このテーブルの各行はロジスティック回帰式の用語に変換されるため、"browser = safari" の場合は x1 = 1、"browser = firefox" の場合は safari = 1.2、x2 = 1 β firefox = 0.8 β。 これにより、全体的な数式が作成されます。
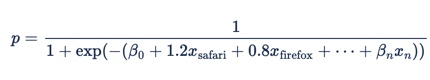
他のカテゴリ特徴もこのように表現できます。 次の値を係数として次のドメインに割り当てたとします。
| ドメイン | 係数 |
|---|---|
| cnn.com | 2.1 |
| nytimes.com | 0.8 |
| yahoo.com | 0.3 |
次に、これらの値は数式の増分項になります ("domain = cnn.com" の場合は x3 が 1、β 3 が 2.1 の場合は、全体の数式になります。

広告インプレッションが配信されると、Xandr はブラウザーを Safari として識別し、ドメインを nytimes.com として識別します。 ブラウザー = Safari および domain = nytimes.com の対応する変数は 1 に設定され、他の変数は 0 に設定され、次の式が得られます。
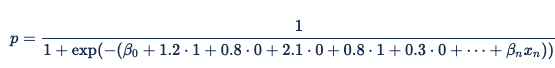
高次予測器
Xandr では、高次の予測変数 (特徴の組み合わせ) がサポートされており、カスタム モデルで予測器間の複雑な相互作用を処理できます。 前の例では、ドメインとブラウザーのカテゴリ値に基づいて値を計算します。 ここで、ドメインとブラウザーが独立していないため、それらの間の関係をモデル化する必要があるとします。 これを行うには、次の表に示す値を使用して、特徴のペアごとに係数を持つ双方向カテゴリ特徴を作成できます。
| ブラウザー | ドメイン | 係数 |
|---|---|---|
| Safari | cnn.com | 1.1 |
| Safari | nytimes.com | 1.3 |
| Safari | yahoo.com | 1.2 |
| Firefox | cnn.com | 3.3 |
| Firefox | nytimes.com | 0.7 |
| Firefox | yahoo.com | 0.1 |
これらのペアの各予測変数は、ロジスティック回帰式の項になります。
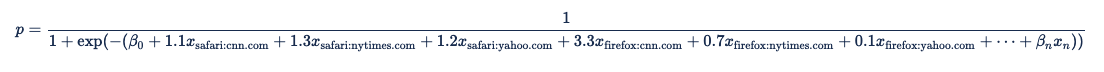
ハッシュ化された予測変数
複数のカテゴリ予測器を組み合わせると、リアルタイム システムのメモリに簡単にマップできない非常に大きなテーブルが作成されます。 このようなテーブルから値をプルする代わりに、特徴の組み合わせをハッシュして競合を作成できます。実際には、リアルタイムでメモリにマップする必要がある組み合わせの数を減らすことができます。
ハッシュ予測変数の例
簡単な例として、2 ビット ハッシュ関数を使用して、前の例のブラウザーとドメインの組み合わせをハッシュできます。
| ブラウザー | ドメイン | 係数 |
|---|---|---|
| Safari | cnn.com | 0 |
| Safari | nytimes.com | 1 |
| Safari | yahoo.com | 3 |
| Firefox | cnn.com | 2 |
| Firefox | nytimes.com | 0 |
| Firefox | yahoo.com | 1 |
次に、各ハッシュ値の係数を計算します。 前の例よりも少ない機能があることに注意してください。多くのメモリを必要とせずに、機能間の相互作用の一部をキャプチャする可能性があります。
| Browser-Domain ハッシュ | 係数 |
|---|---|
| 0 | 1.3 |
| 1 | 0.7 |
| 2 | 1.5 |
| 3 | 0.9 |
変数をこれらの値に置き換えると、ロジスティック回帰式は次のようになります。
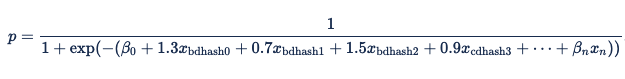
特定の印象に対する応答を予測するために、Xandr は検出された特徴をハッシュします (モデルのトレーニングとオンライン推論の両方に特徴エンジニアリング時に適用されるのと同じハッシュ関数を使用します)。 一部の機能では、ハッシュ関数を使用して、生の特徴値を上記の数式で使用されたものにハッシュし、予測を実行します。 ブラウザーが Safari で、ドメインが nytimes.com (または同じ値にハッシュする他のブラウザー ドメイン ペア) である場合は、これらをハッシュして値 1 を見つけ、ロジスティック回帰式に置き換えます。
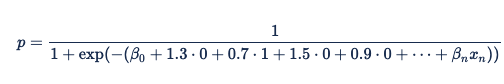
ワンホット エンコードおよび重みベクトルからテーブルへの変換
カテゴリ特徴のエンコードにより、カテゴリ特徴ごとに、最大で 1 つの変数が値 1 を受け取り、それ以外のすべてが 0 の値を受け取ります。 ブラウザー機能の重みとブラウザー変数のドット積は、入札要求でブラウザーの事前に設定された重みをアクティブ化するためのラウンドアバウトな方法です。 Digital Platform API では、標準の Sigmoid 関数である次の式が使用されます。
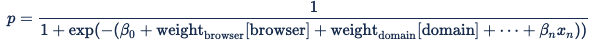
次の広告リクエストがあった場合:
ブラウザーの種類が Firefox の場合、ワンホット エンコード x_firefox は 1 に設定され、 x_safari は 0 に設定されます。 Firefox 型のアクティブ化された重みは、所定の重み 0.8 にエンコードされた値 1 を掛けたものになります。 したがって 、x_firefox は 0.8 になります。 Safari の種類のアクティブ化された重みは 0 で、これは事前に定義された重みであり、1.2 に x_safari 設定の 0 を乗算します。
次の重み付けを使用して数式を取得します。

カテゴリ特徴から重みへのマッピングを定義するために、Xandr は API 呼び出しを使用してルックアップ テーブルを作成および更新します。 ロジスティック回帰モデル自体は、1 ホットでエンコードされた変数のベクトルではなく、これらのテーブルを参照します。 また、モデルは、広告主、クリエイティブ、または広告申込情報のセグメント年齢、セグメント値、頻度または再ジェンシー情報など、カーディナル値または実際の値を直接参照することもできます。
サンプル プロセスの概要
上記の情報を使用して、サンプル ワークフローを作成しましょう。
小規模な予算でトレーニング データを収集する探索的キャンペーンを設定したとします。 クリックあたりのコストを最小限に抑えるために、特定のリターゲット広告申込情報を最適化する必要があります。 各インプレッションの [ ログ レベル データ フィード ] に行が生成され、 is_click 列が falseに設定されます。 クリックが最終的に生成されると、データ フィードに同じ行が生成され、 is_click 列が trueに設定されます。 トレーニング セット、検証セット、テスト セット間でデータをパーティション分割するには、最後の数ビットの user_id_64を確認します。
user_id_64は、データを割り当てる部分を決定します。 最終的に、キー変数は次のようになります。
- ユーザーのブラウザー (カテゴリ)
- ユーザーの国/地域と曜日 (上位カテゴリ)
- 発行元とユーザーの国/地域の組み合わせ (上位カテゴリ)
- その広告主の広告がそのユーザーに最後に表示されてからの時間 (広告主のリジェンシー、カーディナル値)
それほど多くのブラウザーがないため、トレーニング セット内のブラウザーごとに 1 つの重みを持つことが妥当です。 製品間と国/地域、曜日もかなり小さいです。 ただし、発行元と国/地域の組み合わせはカーディナリティが高いため、4096 エントリのハッシュ テーブルを使用して任意にトレーニングすることにします。 最後に、行項目の毎日の頻度はカーディナル値です。
LLD の各行について、最初にトレーニング キャンペーンに含まれていない行を除外します。 目的のイベントを定義したら、変数を抽出できます。
- ブラウザー ID
- 国/地域 ID
- ユーザーの曜日 (インプレッションのタイムスタンプにタイムゾーンオフセットを追加し、7 日間の週にマッピングする)
- パブリッシャー ID
- 広告主のリジェンシー (最大 1 時間) (このユーザーに表示する最初の広告の場合、レジェンシーの既定値は 1 時間)
1 つの機能 ID を再暗号化用に予約し、ハッシュ (publisher:country/region) 用に 4096 ID を予約し、各ブラウザーと (国/地域:曜日) ペアの機能 ID を動的に生成します。 ハッシュ機能にはもう 1 つの追加の手順が必要です。2 つの ID (パブリッシャーと国/地域) を取得し、8 32 ビット整数の小さなエンディアン ベクターに書き出し、MurmurHash3_x86_32 (vector, 32, 0xC0FFEE) % 4096 (0xC0FFEE は任意のシード) を持つ バケット を見つけます。 これにより、各行の特徴値の (スパース) ベクトルが得られます。そのため、そのようなベクトルごとにインプレッション数とクリック数をカウントできます。
ゆっくりとインプレッションを購入した 1 日の後、LLD でトレーニングしたロジスティック回帰モデル (のサブセット) を試します。 特徴値のスパース ベクターは、特徴空間の 1 ホット エンコードです。 このエンコードから、カテゴリ値から重み (参照テーブル) へのより多くの論理関数に戻す必要があります。 これを行うには、特徴のテーブルを特徴 ID に結合し、重みのベクトルを結合して、次を取得します。
| 機能 | インデックス | 太さ |
|---|---|---|
| 広告主のリジェンシー | 0 | -0.2 |
| publisher:country/region-bucket 0 | 1 | 1.4 |
| publisher:country/region-bucket 1 | 2 | -2.1 |
| ... | ... | ... |
| publisher:country/region-bucket 4095 | 4096 | -0.5 |
| browser=safari | 4097 | 5.2 |
| country/region:day-of-week=US:monday | 4098 | 0.7 |
| ... | ... | ... |
各機能の重みを決定します。
- 広告主のリジェンシー: トレーニング済みのモデルから直接重みを読み取る。
- ハッシュテーブル: 4096 機能の重みを読み取り、配列に配置します。
- ブラウザー: 機能から ID への動的マップ、特徴はキーと値の ID、ブラウザー ID からゼロ以外の重み (既定値は 0) へのルックアップ テーブルを作成して、ブラウザーから重み付けマッピングの一覧を作成します。
- 国/地域:曜日: フィーチャから ID への動的マップをウォークし、ブラウザー ID から 0 以外の重み (既定値としてゼロ) にルックアップ テーブルを作成して、ブラウザーから重み付けマッピングの一覧を作成します。
これは、AppNexus API を呼び出すために必要なすべてのデータです。
オークションの時間プロセスの概要
広告申込情報がターゲティングに合格すると、Xandr はそのロジスティック回帰モデルを使用して入札価格を決定します。
- 説明の各ルックアップ テーブルについて、Xandr は入札要求からフィールドの (またはフィールドの) 値を抽出し、テーブル内のエントリを検索します。 エントリがある場合、その値はロジスティック関数の線形引数に追加されます。 それ以外の場合、テーブルの既定値 (通常は 0) が使用されます。
- ハッシュテーブルでも同じことが行われますが、Xandr は値をハッシュしてバケットを見つけ、ハッシュされたテーブルのバケットの一覧でそのバケットを探> 値マッピングを探します。 ここでも、指定した値がテーブルに表示されない場合は、既定値が使用されます。
- 最後に、Xandr は Bonsai 機能を探します。 各特徴のルックアップを実行し、重みを乗算し、最小/最大制限を適用します。
- Xandr は次に、コンポーネントと Beta0 を合計し、それをロジスティック関数に渡して、クリックの推定確率を計算します。 推定確率に目標値を乗算して期待値を取得し、1 から 100 CPM の間でクランプして、非現実的に高い評価を抑制します。
- 次に、Xandr は、予想される値と、入札の計算に使用できる在庫の量を使用します。 正確な計算は、行項目の設定によって異なりますが、その結果、Xandr は、毎日の終わりに 1 日の予算を費やすほど入札額が高くなるまで、期待値を自動的にスケールダウンします。 このスケーリングの詳細については、ドキュメントの 「アダプティブ ペーシング (ログインが必要)」を参照してください。