インク分析の概要
InkAnalysis API は、タブレット PC 開発者に、プログラムでインク入力を調べる強力なツールを提供します。 API は、インクを単語、線、段落、図面などの意味のあるカテゴリに分類します。
各分類は、手書きの認識結果の改善など、さまざまな方法で使用できます。
インク分析の基本
このセクションでは、タブレット PC プラットフォーム のインク分析テクノロジについて説明し、それを使用するタイミングと方法について説明します。
InkAnalysis API は、手書き認識とレイアウト分類という 2 つの異なる無料のテクノロジを効果的に組み合わせています。 これら2つの技術を組み合わせることで、単独で撮影した部品よりも確実に大きな結果が得られます。
手書き認識は、特定の言語で文字ベースの解釈を返す手書きのデジタル インクの計算分析です。 つまり、手書き認識とは、コンピューターが人の手書きを "読み取る" 方法です。
インク分析は、インク分類とレイアウト分析にさらに分けることができます。 インク分類は、インクを段落、線、単語、図面などの意味的に意味のある単位に分割する計算です。 レイアウト分析は、インク入力の計算検査であり、インクサーフェス上のインクの位置と、ストロークが空間的および意味的にどのように相互に関連しているかを決定します。 たとえば、レイアウト分析では、特定のインクが注釈または呼び出しであることを示すことができます。
認識
InkAnalysis API での認識とインク分析の組み合わせが開発者にどのように役立つかの 1 つの例は、認識結果の改善です。 タブレット PC の手書き認識エンジンは、主に 1 本の水平線のインクを認識するように設計されています。 しかし、ノートを取るときに複数の行を書く傾向があり、それらの行はページに関連して水平であるとは限りません。 InkAnalysis API を使用すると、インクは認識エンジンに送信される前にインク アナライザーによって前処理されます。 分析されたインクは認識される前に水平方向に変換され、認識結果が向上します。
認識のその他の利点は、認識エンジンにインクを送信する前に、インク アナライザーで正しくないストローク順序情報を正しくすることで得られます。 さらに、認識結果は選択的な方法で利用できるようになりました。 つまり、開発者は、1 回の呼び出しで 1 つの単語、行、または段落の認識結果をすばやく取得できます。
インク分類
もちろん、インク データをテキストにすぐに変換するのではなく、そのまま維持するシナリオはさまざまです。 インク分析にも利点があります。 具体的には、InkAnalysis API は、書き込み中か図面かに応じてインク ストロークを分割する機能を提供します。 書き込みとして分類されるインク ストロークは、単語または文字を構成するストロークです。 その他のストロークはすべて図面です。 これにより、インク データにアクセスするための新しい方法が提供され、新しいユーザー シナリオが可能になります。 たとえば、選択を実装して、ユーザーがタップするストロークの種類によって異なるようにすることができます。ユーザーが書き込みストロークをタップすると、アプリケーションは単語を構成するストロークのセット全体を選択します。ユーザーが描画ストークをタップすると、アプリケーションはそのストロークのみを選択します。
レイアウト分析
便利なレイアウト分析は、実際には、インクの比較的単純なブレークダウンから書き込みおよび描画コンポーネントへの分割をはるかに超えています。
インク分析には、書き込みストロークと描画ストロークの詳細な内訳も含まれています。 非常に簡単な例として、次の図に示すように、インクの BLOB を使用します。

プラットフォームは、これらのストロークを分析した後、次の図に示すように、これらのストロークのツリー表現を返します。 この単純なケースでは、ツリーには段落、行、および単語の情報のみが含まれますが、インク ドキュメントの複雑さが増すにつれて、このツリーのリッチさが増します。
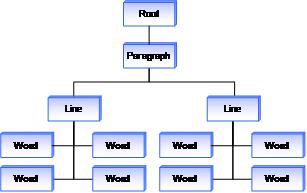
この情報は管理可能な単位に分かれているため、より強力な機能を作成できるようになりました。 たとえば、アプリケーションでは、ユーザーがタップして単語を選択する機能を拡張して、ユーザーが単語を 1 回タップして単語を選択し、2 回タップして行全体を選択し、3 回タップして段落全体を選択します。 分析操作によって返されるツリー構造を利用することで、タップされた領域をツリー内のストロークに関連付けることができます。 アプリケーションがストロークを見つけたら、ツリーを上に歩いて、選択する隣接するストロークの方法と方法を決定できます。
行全体を選択することは、インク分析の利点の単純な例ですが、インク アナライザーが検出できるさまざまな種類の階層構造を考慮すると、可能性は大きくなる可能性があります。
- 順序付きリストと順序なしリスト
- 図形
- テキストと共にインラインで記述された異尺度対応コメント
機能の種類はアプリケーションによって異なり、要件と使用可能なインク分析および認識エンジンに基づいています。
インク分析の主な機能
InkAnalysis API の主な機能には、次の機能があります。
- 増分分析
- 永続化
- データ プロキシ
- 和解
- 機能拡張
増分分析
エンド ユーザーがインクを操作する場合、通常は手書きのように扱われます。 インクには、新しいインクの追加、既存のインクの削除、インク プロパティの変更などの編集操作が継続的に適用され、すべて手書きが継続的に編集されるのと同じ方法で行われます。 これらの編集操作は、分析結果に影響します。 編集が行われると、通常、特定の時点でドキュメントのセクションに分離できます。 たとえば、ユーザーが 5 行のインクを書き込んだとします。 アプリケーションでインクを分析する標準的な方法は、ユーザーが 5 行すべてのインク (たとえば段落) の書き込みを完了するまで待ってから、結果を同期的または非同期的に分析することです。
これらの 5 行の分析に費やされた全体的な時間を最適化するには、書き込み中に分析される領域を分離し、変更された結果の部分のみを再分析します。 最初の行が分析された後、エンド ユーザーによって変更されない限り、再び認識されることはありません。 2 行目の認識は、独立した認識操作として扱われます。
この増分アプローチは、認識操作の行レベルでは適切に機能しますが、インク分析操作ではより高いレベルで動作する必要があります。 インク アナライザーは、これら 5 行のインクに対して異なる上位レベルの分類を検出できるため (たとえば、標準の段落またはリスト内の 5 つの項目でもかまいません)、インク アナライザーの増分アプローチでは、これらの上位の構造を分析する必要があります。 つまり、インク アナライザーがインクの最初の行を 1 行として分類した後、2 行目を分類するときに、まだ 1 行であることを再確認します。 ただし、インク アナライザーは、このダブルチェックを段落に分離し、2 番目の段落を分析するときに最初の段落を無視し、2 番目の段落を独立したインク アナライザー操作として扱います。 この増分分析アプローチにより、アプリケーションに大量のインクが既に存在する場合の処理時間が大幅に節約されます。
永続化
増分分析は、 InkAnalyzer オブジェクトの特定のセッションまたはインスタンス内で適切に機能します。 ただし、第 1 世代のタブレット PC プラットフォーム API では、インクがディスクに永続化された後に増分分析を実行することはできません。 InkAnalysis API を使用すると、分析結果の永続化された形式と共に、インクをディスクに保存できます。 分析結果は、インクが読み込まれるときに読み込まれ、 InkAnalyzer の新しいインスタンスに挿入できます。 その後、 InkAnalyzer オブジェクトの新しいインスタンスは、以前と同じ結果状態になり、すべての変更を再度分析するのではなく、既存の状態への増分変更として受け入れることができるようになりました。
データ プロキシ
多くのアプリケーションは、既にアプリケーションに何らかの既存のドキュメント構造を持っています。たとえば、グラフやデータベースなどです。 InkAnalyzer は、ContextNode オブジェクトのツリーに構造化された形式で結果を表示します。 InkAnalyzer 構造体とアプリケーションの既存の構造体は、2 つの方向で相互運用する必要があります。結果は InkAnalyzer からアプリケーションにプルされ、状態はアプリケーションから InkAnalyzer にプッシュされます。
InkAnalyzer からアプリケーションの構造に結果をプルするだけで済む場合は、比較的簡単です。 アプリケーションでは、結果ツリーを反復処理し、必要なすべての結果を既存のデータ構造にコピー (統合) します。 ただし、多くの水平方向のアプリケーションではディスクへの増分分析と永続化が必要であるため、問題は双方向になります。 状態 (過去の結果) は、アプリケーションの構造からプルし、 InkAnalyzer にプッシュする必要があります。
この要件を満たすために、 InkAnalyzer には、分析操作中に適切なタイミングで発生する一連のイベントが含まれています。これにより、アプリケーションはデータの要求を既存の構造体にプロキシバックできます。 これらのイベントは、増分操作で必要な ContextNode オブジェクトに対してのみ発生します。
和解
ほとんどのアプリケーションでは、ユーザー インターフェイスの中断を最小限に抑えるために、バックグラウンドでインクを分析する必要があります。 バックグラウンドでインクを分析すると問題が発生しますが、ユーザーが分析対象のインク (または隣接するインク) を変更した場合は問題が発生します。 たとえば、ユーザーがバックグラウンド操作中にインクを削除した場合、結果の構造体には、完了時ではなく、バックグラウンド操作の開始時のドキュメントの状態が反映されます。
アプリケーションを支援するために、 InkAnalyzer は分析操作の開始と終了の間のドキュメント状態の違いを調整します。 分析がバックグラウンドで実行されている間にユーザーまたはアプリケーションによって行われた変更は、常にバックグラウンドで計算された結果をオーバーライドします。 調整後、ドキュメントの変更と競合しない結果構造の部分のみが報告され、競合するストロークは将来の分析用にタグ付けされます。 次にバックグラウンド分析操作を実行すると、新しい状態に基づいて結果が再計算されます。
このプロセスを次の図に示します。 時間は、図の上から下に直線的に表されます。
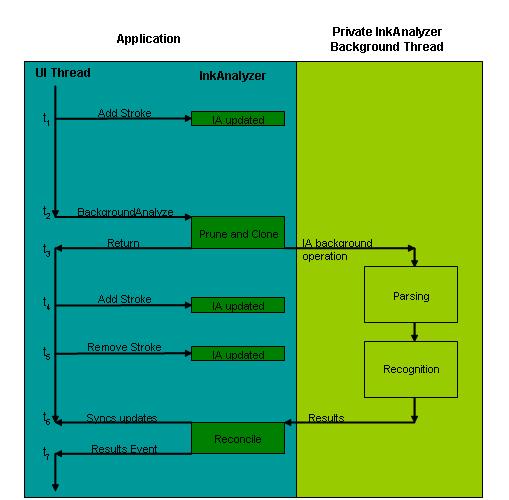
- 時刻 1 (t1) では、アプリケーションは、追加、削除、変更などの任意の種類のインク修正を含む、エンドユーザーからインクを収集しています。
- t2 では、アプリケーションによってバックグラウンド分析操作が呼び出されます。 InkAnalyzer は、結果がないインクと、ダブルチェックする必要があるインクを決定します。 必要なインク データをコピーして、バックグラウンド スレッドを個別に実行できるようにします。
- t3 では、 InkAnalyzer は ユーザー インターフェイス スレッドの実行をアプリケーションに返します。 InkAnalyzer は、2 番目のスレッド、バックグラウンド分析スレッド、およびインク分析および認識エンジンによって、コピーされたインク データを分析します。
- 分析操作が 2 番目のバックグラウンド スレッドで行われている間、エンド ユーザーは引き続きドキュメントを編集し、ストローク データを追加および削除します (t4 と t5)。 これらの編集は、バックグラウンドで処理されている作業と競合する可能性があります。
- t6 では、バックグラウンド スレッドによって分析操作が完了し、結果の準備が整いました。 InkAnalyzer は、結果をアプリケーションに通信する前に、調整アルゴリズムを実行して、分析操作の計算中にユーザーが編集した (t4 と t5) が結果と競合しているかどうかを判断します。 衝突が検出されると、衝突するストロークに再分析のフラグが設定されます。これは、アプリケーションが次にバックグラウンド分析操作を呼び出す際に発生します。
- 最後に、t7 で、すべての競合が検出されると、 InkAnalyzer によって結果がアプリケーションに表示されます。
機能拡張
InkAnalysis API を使用すると、アプリケーションで調整、データ プロキシ、永続化、増分分析など、InkAnalysis API のすべての利点を書き換える必要がないように、新しい種類の分析エンジンをアプリケーションで使用できます。
関連トピック