PyTorch を使用してデータ分析モデルをトレーニングする
このチュートリアルの前の段階で、PyTorch を使用してデータ分析モデルをトレーニングするために使用するデータセットを取得しました。 今度は、そのデータを使用する番です。
PyTorch を使用してデータ分析モデルをトレーニングするには、次の手順を完了する必要があります。
- データを読み込みます。 このチュートリアルの前の手順を完了している場合は、既にこれに対応しています。
- ニューラル ネットワークを定義します。
- loss 関数を定義します。
- トレーニング データに対してモデルをトレーニングします。
- テスト データに対してネットワークをテストします。
ニューラル ネットワークを定義する
このチュートリアルでは、3 つの線形レイヤーを使用する基本的なニューラル ネットワーク モデルを構築します。 このモデルの構造は、次のとおりです。
Linear -> ReLU -> Linear -> ReLU -> Linear
線形レイヤーでは、受信データに線形変換が適用されます。 入力の特徴量の数と出力の特徴量の数を指定する必要があります。これらは、クラスの数に対応している必要があります。
ReLU レイヤーは、受信するすべての特徴量を 0 以上に定義するアクティブ化関数です。 したがって、ReLU レイヤーが適用されると、0 未満の数値は 0 に変更され、それ以外の数値はそのまま維持されます。 ここでは、2 つの隠れレイヤーにアクティブ化レイヤーを適用し、最後の線形レイヤーにはアクティブ化を適用しません。
モデル パラメーター
モデル パラメーターは、目標とトレーニング データによって異なります。 入力サイズは、モデルにフィードする特徴量の数 (この場合は 4) によって異なります。 使用可能なアヤメの種類は 3 つであるため、出力サイズは 3 です。
3 つの線形レイヤー ((4,24) -> (24,24) -> (24,3)) があるため、ネットワークの重みは 744 (96 + 576 + 72) です。
学習率 (lr) には、損失の勾配に対してネットワークの重みをどの程度調整するかが設定されます。 これを低くするほど、トレーニング速度は遅くなります。 このチュートリアルでは、lr を 0.01 に設定します。
ネットワークのしくみ
ここでは、フィード転送ネットワークを構築しています。 トレーニング プロセス中に、ネットワークによって入力がすべての層で処理され、画像の予測ラベルが正しいものからどれだけ離れているかを理解するために損失が計算され、勾配がネットワークに伝播され、層の重みが更新されます。 ネットワークにより、入力の膨大なデータセットを反復処理することで、最良の結果が得られるように重みを設定することが "学習" されます。
forward 関数を使用して loss 関数の値を計算し、backward 関数を使用して学習可能なパラメーターの勾配を計算します。 PyTorch を使用してニューラル ネットワークを作成する際に必要なのは、forward 関数を定義することだけです。 backward 関数は自動的に定義されます。
- Visual Studio で、次のコードを
DataClassifier.pyファイルにコピーして、モデル パラメーターとニューラル ネットワークを定義します。
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
また、お使いの PC で使用可能なデバイスに基づいて実行デバイスを定義する必要があります。 PyTorch には GPU 専用のライブラリはありませんが、実行デバイスを手動で定義できます。 デバイスは、マシンに存在する場合は Nvidia GPU になり、存在しない場合は CPU になります。
- 次のコードをコピーして、実行デバイスを定義します。
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- 最後の手順として、モデルを保存する関数を定義します。
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Note
PyTorch を使用したニューラル ネットワークの詳細については関心がある場合は PyTorch のドキュメントを参照してください。
loss 関数を定義する
loss 関数により、出力が目標からどれだけ離れているかを推定する値が計算されます。 この主な目的は、ニューラル ネットワークで逆伝搬法によって重みのベクトル値を変更することで、loss 関数の値を小さくすることです。
loss 値はモデルの正確性とは異なります。 loss 関数は、トレーニング セットで最適化を繰り返すたびにモデルがどの程度適切に動作するかを表します。 モデルの精度はテスト データに対して計算され、正しい予測の割合を示します。
PyTorch のニューラル ネットワーク パッケージには、ディープ ニューラル ネットワークの構成要素となるさまざまな loss 関数が含まれています。 これらの関数の詳細については、まず、上記の注を参照してください。 ここでは、このような分類用に最適化された既存の関数を使用し、Classification Cross-Entropy (分類交差エントロピー) loss 関数と Adam オプティマイザーを使用します。 オプティマイザーでは、学習率 (lr) に、損失の勾配に対してネットワークの重みをどの程度調整するかが設定されます。 ここでは、これを 0.001 として設定します。これを低くするほど、トレーニング速度は遅くなります。
- Visual Studio で次のコードを
DataClassifier.pyファイルにコピーし、loss 関数とオプティマイザーを定義します。
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
トレーニング データに対してモデルをトレーニングします。
モデルをトレーニングするには、データ反復子をループさせ、ネットワークに入力をフィードし、最適化する必要があります。 結果を検証するには、トレーニング エポックごとに、予測されたラベルを検証データセット内の実際のラベルと比較するだけです。
プログラムでは、すべてのエポックまたはトレーニング セット全体のすべての完全な反復について、トレーニング損失、検証損失、モデルの精度を表示します。 最も高い精度のモデルが保存され、10 エポック後、プログラムによって最終的な精度が表示されます。
- 次のコードを
DataClassifier.pyファイルに追加します
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
テスト データに対してモデルをテストします。
モデルをトレーニングしたので、テスト データセットを使用してモデルをテストできます。
2 つのテスト関数を追加します。 最初の関数では、前のパートで保存したモデルをテストします。 モデルは、45 個の項目を含むテスト データ セットを使用してテストされ、モデルの精度が出力されます。 2 番目の関数はオプションの関数であり、3 つのアヤメの種のそれぞれを予測する際のモデルの信頼度をテストします。信頼度は、それぞれの種の分類が成功する確率で表されます。
- 次のコードを
DataClassifier.pyファイルに追加します。
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
最後に、メイン コードを追加します。 これで、モデルのトレーニングが開始され、モデルが保存され、結果が画面に表示されます。 ここではトレーニング セットに対して [num_epochs = 25] という 2 回の反復処理を実行するだけなので、トレーニング プロセスにはそれほど時間はかかりません。
- 次のコードを
DataClassifier.pyファイルに追加します。
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
テストを実行しましょう。 上部のツール バーのドロップダウン メニューが Debug に設定されていることを確認します。 デバイスが 64 ビットの場合は Solution Platform を x64 に、32 ビットの場合は x86 に変更して、ローカル マシン上でプロジェクトを実行します。
- プロジェクトを実行するには、ツール バーの
Start Debuggingボタンをクリックするか、F5キーを押します。
コンソール ウィンドウがポップアップ表示され、トレーニングのプロセスを確認できます。 定義したとおり、エポックごとに損失値が出力されます。 損失値はループごとに減少することが予想されます。
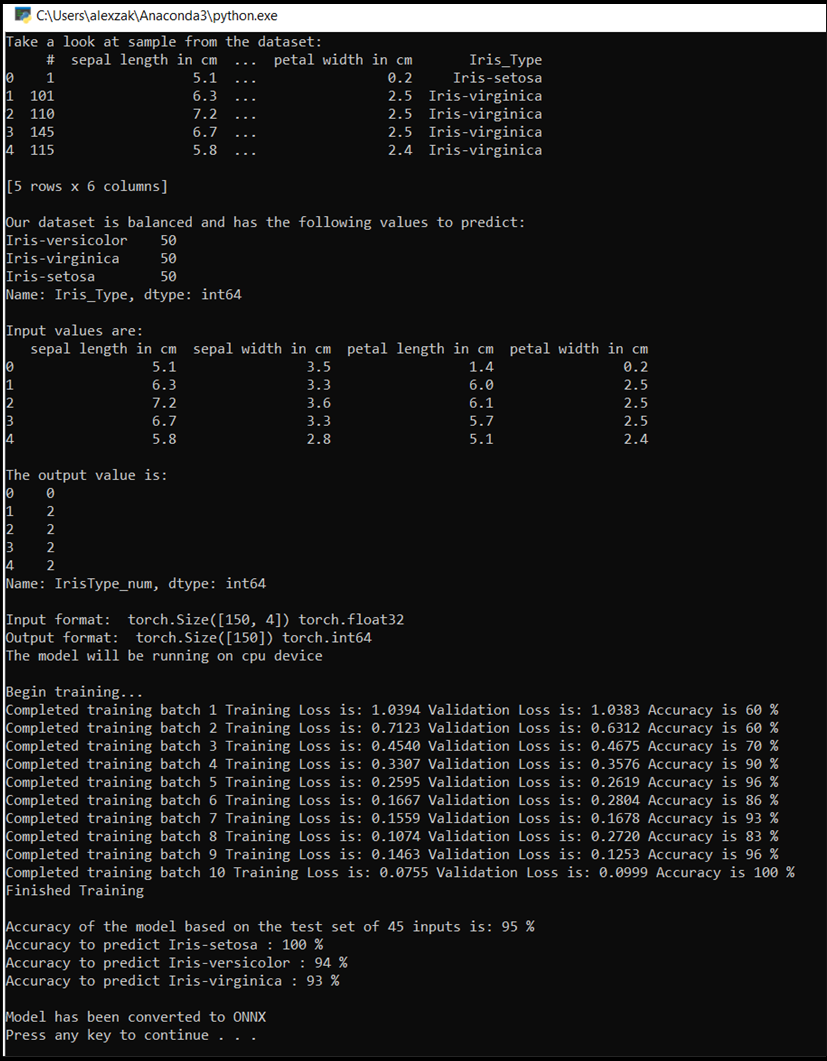
トレーニングが完了すると、次のような出力が表示されます。 トレーニングはさまざまな要因に左右されるため、常に同じ結果が得られるわけではないので、実際に表示される数字はまったく同じではありませんが、似たような結果が得られるはずです。
次のステップ
分類モデルが完成したので、次の手順では、モデルを ONNX 形式に変換します。