この記事では、Active Directory Domain Services (AD DS) のキャパシティ プランニングに関する推奨事項を示します。
キャパシティ プランニングの目標
キャパシティ プランニングは、パフォーマンス インシデントのトラブルシューティングと同じではありません。 キャパシティ プランニングの目標は次のとおりです。
- 環境を適切に実装して運用する。
- パフォーマンスの問題のトラブルシューティングに費やす時間を最小限に抑える。
組織のキャパシティ プランニングでは、クライアントのパフォーマンス要件を満たし、データセンターのハードウェアをアップグレードするための十分な時間を確保することを目的として、たとえばピーク時のプロセッサ使用率を 40% というベースライン目標に設定することができます。 一方、パフォーマンスの問題に対する監視アラートのしきい値を 5 分間隔で 90% に設定することもできます。
キャパシティ管理のしきい値を継続的に超えている場合は、プロセッサの数を増やすか高速なプロセッサを追加してキャパシティを引き上げること、あるいは複数のサーバーにわたってサービスを拡張することが解決策になります。 パフォーマンス アラートのしきい値を設定すると、パフォーマンスの問題がクライアントのエクスペリエンスにマイナスの影響を及ぼす場合に、直ちに対処する必要があれば通知を受けることができます。 これに対し、トラブルシューティング ソリューションでは、1 回限りのイベントに対処することに重点を置きます。
キャパシティ管理は、自動車で言えば、安全運転やブレーキの適切な作動確認など、事故を避けるために講じる予防措置のようなものです。 パフォーマンスのトラブルシューティングは、警察、消防、救急医療の専門家による事故対応と似ています。
過去数年間で、スケールアップ システムのキャパシティ プランニングのガイダンスは大幅に変更されています。 システム アーキテクチャに生じている次のような変化は、サービスの設計とスケーリングに関する基本的な前提に疑問を投げかけるものです。
- 64 ビット サーバー プラットフォーム
- 仮想化
- 消費電力への関心の高まり
- SSD ストレージ
- クラウド シナリオ
キャパシティ プランニングへのアプローチも、サーバー ベースの計画作業からサービス ベースの計画作業へと移行しています。 Active Directory Domain Services (AD DS) は、多くの Microsoft 製品やサードパーティ製品でバックエンドとして使用されている成熟した分散サービスであり、今では、他のアプリケーションの実行に必要なキャパシティを確保するうえで最も重要な製品の 1 つとなっています。
プランニングを開始する前に考慮を要する重要な情報
この記事を最大限に活用するには、次のことを行う必要があります。
- Windows Server 2012 R2 の パフォーマンス チューニング ガイドラインを読んで理解すること。
- Windows Server プラットフォームが x64 ベースのアーキテクチャである点を理解すること。 また、Active Directory 環境が Windows Server 2003 x86 (現在はサポート ライフサイクルが終了済み) にインストールされていて、ディレクトリ情報ツリー (DIT) が 1.5 GB 未満でメモリへの格納が容易である場合でも、この記事のガイドラインが適用されることを理解する必要があります。
- キャパシティ プランニングは継続的なプロセスである点を理解し、構築した環境がどの程度要望に対応しているかを定期的に確認すること。
- 最適化は、ハードウェア コストの変化に伴い、複数のハードウェア ライフサイクルで行われるという点を理解すること。 たとえば、メモリが安くなると、コアあたりのコストが減少したり、さまざまなストレージ オプションの価格が変化することがあります。
- 毎日のピーク時に合わせて計画を立てること。 30 分または 1 時間の間隔に基づいて計画を立てることをお勧めします。 1 時間を超える間隔では、サービスのキャパシティが実際にピークに達しでも、それがわからなくなる可能性があります。また、30 分未満の間隔では、一時的な増加が実際よりも重要に見え、正確な情報が得られなくなる可能性があります。
- 企業のハードウェア ライフサイクル全体にわたる成長を計画します。 この計画には、段階的にハードウェアをアップグレードまたは追加するための戦略や、3 ~ 5 年ごとに行う完全な見直しを含めることができます。 各拡張計画では、Active Directory の負荷がどれだけ大きくなるかを見積もる必要があります。 より正確な評価を行うには、履歴データが役立つことがあります。
- フォールト トレランスを計画します。 推定値 N が導き出されたら、N – 1、N – 2、N - x を含むシナリオを計画します。
1 台以上のサーバーが失われてもシステムが推定の最大ピーク キャパシティを超えないように、成長計画に基づき、組織のニーズに応じてサーバーを追加します。
また、成長とフォールト トレランスの計画を統合する必要があることを覚えておいてください。 たとえば、現在の展開で負荷をサポートするために必要なドメイン コントローラー (DC) は 1 台で、推定では今後 1 年間で負荷が 2 倍になり、2 台の DC が必要になるとわかっている場合、このシステムにはフォールト トレランスをサポートするための十分なキャパシティがありません。 このキャパシティ不足を防ぐには、3 台の DC から始めることを計画する必要があります。 予算で 3 台の DC が許可されない場合は、2 台の DC から始めて、3 か月または 6 か月後に 3 台目の DC を追加する計画を立てることもできます。
Note
Active Directory 対応アプリケーションを追加すると、DC の負荷に大きな影響を与える可能性があります。その負荷がアプリケーション サーバーまたはクライアントから発生したかどうかには関係ありません。
3 部構成のキャパシティ プランニング サイクル
プランニング サイクルを開始する前に、組織に必要なサービスの品質を決定する必要があります。 この記事のすべての推奨事項とガイダンスは、最適なパフォーマンス環境を目的としています。 ただし、最適化の必要がない場合は、部分的に緩和することもできます。 たとえば、組織で高いレベルのコンカレンシーと一貫性のあるユーザー エクスペリエンスが必要な場合は、データセンターのセットアップを検討する必要があります。 データセンターを使用すると、冗長性に注意を払い、システムとインフラストラクチャのボトルネックを最小限に抑えることができます。 一方、ユーザー数が少ないサテライト オフィスへの展開を計画している場合は、ハードウェアとインフラストラクチャの最適化についてそれほど心配する必要がないため、低コストのオプションを選択できます。
次に、仮想マシンと物理マシンのどちらを使用するかを決定する必要があります。 キャパシティ プランニングの観点からは、どちらが正解ということはありません。 ただし、シナリオによって扱う可変要素が異なることに留意する必要があります。
仮想化のシナリオには、次の 2 つのオプションがあります。
- ホストとゲストが 1 対 1 である直接マッピング。
- ホストごとに複数のゲストが存在する共有ホスト シナリオ。
直接マッピング シナリオは、物理ホストの場合と同じように扱うことができます。 共有ホスト シナリオを選択した場合は、この後のセクションで説明する、他の可変要素についても考慮する必要があります。 共有ホストの場合は、Active Directory Domain Services (AD DS) とのリソース競合も生じるため、システム パフォーマンスやユーザー エクスペリエンスに影響する可能性があります。
これらの点を念頭に置いて、キャパシティ プランニングのサイクルを見てみましょう。 キャパシティ プランニングの各サイクルは、次の 3 つのプロセスで構成されます。
- 既存の環境を測定し、システムのボトルネックが現在発生している場所を特定して、展開に必要なキャパシティを計画するために必要となる環境の基本情報を取得する。
- キャパシティの要件に基づいて、必要なハードウェアを決定する。
- セットアップしたインフラストラクチャが仕様の範囲内で動作しているかどうかを監視および検証する。 このステップで収集するデータは、キャパシティ プランニングの次のサイクルでのベースラインになります。
プロセスを適用する
パフォーマンスを最適化するには、以下の主要なコンポーネントが正しく選択され、アプリケーションの負荷に合わせて調整されていることを確認します。
- メモリ
- ネットワーク
- ストレージ
- プロセッサ
- Netlogon
10,000 ~ 20,000 人のユーザーが存在する環境では、AD DS の基本的なストレージ要件と互換性のあるクライアント ソフトウェアの一般的な動作によって、物理ハードウェアのキャパシティ プランニングを無視できます。これは、最新のサーバー クラス システムのほとんどが既にその規模の負荷を処理できるためです。 ただし、データ コレクションの概要テーブルには、既存の環境を評価して適切なハードウェアを選択する方法が示されていいます。 その後のセクションでは、AD DS 管理者がインフラストラクチャを評価するために役立つ、ハードウェアに関するベースライン推奨事項と環境固有の原則について詳しく説明しています。
その他、プランニング時には次のような情報も念頭に置く必要があります。
- 現在のデータに基づくサイズ設定が正しいのは、現在の環境に対してのみです。
- 見積もりを行う際には、ハードウェア ライフサイクルの推移と共に需要が増加することも考慮します。
- 将来的な成長に対応するために、今すぐ環境を大きめに拡張するか、ライフサイクルの推移に伴い徐々にキャパシティを追加するかを決定します。
- 物理的な展開に適用するキャパシティ プランニングの原則と方法論はすべて、仮想化を取り入れた展開にも適用されます。 ただし、仮想化環境を計画する場合は、ドメイン関連の計画や見積もりに仮想化のオーバーヘッドを追加することを忘れないようにする必要があります。
- キャパシティ プランニングは予測であり、完全に正しい値ではないため、完全に正確であるとは考えないでください。 必要に応じてキャパシティを常に調整し、意図したとおりに環境が動作しているかどうかについても繰り返し検証するようにしてください。
データ コレクションの概要テーブル
次の表は、ハードウェアの見積もりを決定するための条件を示しています。
基本環境
| コンポーネント | 見積もり |
|---|---|
| ストレージまたはデータベースのサイズ | ユーザーごとに 40 KB - 60 KB |
| RAM | データベース サイズ 基本オペレーティング システムの推奨事項 サードパーティ アプリケーション |
| ネットワーク | 1 GB |
| CPU | コアごとに 1000 人の同時ユーザー |
高レベルの評価基準
| コンポーネント | 評価基準 | 計画に関する考慮事項 |
|---|---|---|
| ストレージまたはデータベースのサイズ | オフライン最適化 | |
| ストレージ/データベースのパフォーマンス |
|
|
| RAM |
|
|
| ネットワーク |
|
|
| CPU |
|
|
| NetLogon |
|
|
計画
長い間、AD DS のサイズ設定については、データベース サイズと同じ量の RAM を配置することが推奨されていました。 AD DS 環境とそれを利用するエコシステムが大幅に拡大したため、状況は変わりました。 コンピューティング能力の向上と x86 アーキテクチャから x64 への切り替えにより、パフォーマンスのためのサイズ設定に関する些細な問題は物理マシン上で AD DS を実行しているお客様には重要ではなくなりましたが、仮想化におけるチューニングの方がはるかに大きな懸念事項になりました。
これらの懸念に対処するために、以下の各セクションでは、サービスとしての Active Directory の需要を決定して計画する方法について説明します。 これらのガイドラインは、環境が物理環境、仮想化環境、混在環境のいずれであっても、任意の環境に適用できます。 パフォーマンスを最大化するには、AD DS 環境が可能な限りプロセッサ バウンドになることを目標にする必要があります。
RAM
RAM にキャッシュできるストレージ容量が大きくなるほど、ディスクにアクセスする必要が少なくなります。 サーバーのスケーラビリティを最大化するには、使用する RAM の最小容量を、現在のデータベース サイズ、システム値の合計サイズ、オペレーティング システムの推奨サイズ、各種エージェント (ウイルス対策プログラム、監視、バックアップなど) のベンダー推奨サイズの合計と等しくする必要があります。 また、サーバーの有効期間の将来的な拡大に対応するために、追加の RAM も含める必要があります。 この見積りは、データベースの拡大と環境の変化に応じて変わります。
サテライト拠点の場合や Directory Information Tree (DIT) が大きすぎる場合など、RAM 容量の最大化が優れたコスト効率につながらない環境や実現不可能な環境では、「ストレージ」セクションを参照して、ストレージのサイズが適切に設定されていることを確認してください。
メモリのサイズを変更する際に考慮すべきもう 1 つの重要な点は、ページ ファイルのサイズ設定です。 ディスクのサイズ設定では、メモリに関連するその他のすべての作業と同様、ディスクの使用量を最小限に抑えることが目標です。 特に、ページングを最小限に抑えるには、どれくらいの RAM が必要になるでしょうか。 次のいくつかのセクションでは、この点を明らかにするために必要な情報を確認します。 AD DS のパフォーマンスに必ずしも影響しないページ サイズに関するその他の考慮事項としては、オペレーティング システム (OS) の推奨事項と、メモリ ダンプ用のシステムの構成があります。
ドメイン コントローラー (DC) に必要な RAM 容量を判断することは、多くの複雑な要因により容易でない場合があります。
- メモリ不足の状況下では、Local Security Authority Subsystem Service (LSSAS) によって RAM のトリミングや人為的な要件縮小が行われるため、既存のシステムは必ずしも RAM 要件の信頼できる指標ではありません。
- 個々の DC は、クライアントが必要とするデータのみをキャッシュする必要があります。 つまり、さまざまな環境でキャッシュされるデータは、含まれるクライアントの種類によって変わります。 たとえば、Exchange Server を使用する環境の DC では、ユーザー認証を行うだけの DC とは異なるデータが収集されます。
- ケースバイケースで各 DC の RAM を評価するために必要な労力は、多くの場合、過剰であり、環境の変化に応じて変化します。
推奨事項の背後にある基準は、より多くの情報に基づいた意思決定を行うために役立ちます。
- RAM にキャッシュする容量が大きくなるほど、ディスクにアクセスする必要が少なくなります。
- ストレージは、コンピューターで最も低速なコンポーネントです。 スピンドル ベースおよび SSD ストレージ メディアでのデータ アクセスは、RAM のデータ アクセスよりも 100 万倍遅くなります。
RAM の仮想化に関する考慮事項
RAM を最適化する目的は、ディスクへのアクセスに費やす時間を最小限に抑えることです。 また、ホストでのメモリのオーバーコミットも避ける必要があります。 仮想化のシナリオでは、メモリのオーバーコミットとは、システムが物理マシン自体に存在する RAM よりも多くの RAM をゲストに割り当てることです。 オーバーコミット自体は問題ではありませんが、すべてのゲストが使用するメモリの合計がホストの RAM の容量を超えると、ホストでページングが発生します。 DC がデータを取得するために NTDS.nit またはページ ファイルにアクセスする場合、またはホストが RAM データにアクセスするためにディスクにアクセスする場合、ページングによってパフォーマンスがディスクバウンドになります。 その結果、このプロセスにより、パフォーマンスと全体的なユーザー エクスペリエンスが大幅に低下します。
計算の概要の例
| コンポーネント | 推定メモリ (例) |
|---|---|
| 基本オペレーティング システムの推奨 RAM (Windows Server 2008) | 2 GB |
| LSASS 内部タスク | 200 MB |
| 監視エージェント | 100 MB |
| ウイルス対策 | 100 MB |
| データベース (グローバル カタログ) | 8.5 GB |
| 管理者が影響を受けずにログオンするための、バックアップを実行するためのクッション | 1 GB |
| 合計 | 12 GB |
推奨: 16 GB
経時的には、データベースにデータが追加されていき、サーバーの平均寿命は約 3 ~ 5 年になります。 333% の成長予測に基づくと、物理サーバーに搭載する RAM の適切な量は 16 GB です。
ネットワーク
このセクションでは、クライアント クエリ、グループ ポリシー設定などを含め、展開に必要な合計帯域幅とネットワーク キャパシティの評価について説明します。 見積もりを行うためのデータは、パフォーマンス カウンター Network Interface(*)\Bytes Received/sec および Network Interface(*)\Bytes Sent/sec を使用して収集できます。 Network Interface カウンターのサンプル間隔は、15 分、30 分、または 60 分に設定する必要があります。 設定値がこれより短いと、変動が大きくなりすぎて測定精度が低下し、設定値がこれより長いと、日々のピークが過度に平滑化されます。
Note
一般に、DC でのネットワーク トラフィックの大半は、DC がクライアント クエリに応答するときに送信されます。 このため、このセクションでは主に送信トラフィックに重点を置いています。 ただし、受信トラフィックについても各環境を評価することをお勧めします。 この記事のガイドラインを使用すると、ネットワークの受信トラフィックに関する要件も評価できます。 詳細については、「929851: Windows Vista および Windows Server 2008 では TCP/IP の既定の動的ポート範囲が変更されている」を参照してください。
帯域幅のニーズ
ネットワークのスケーラビリティの計画には、トラフィックの量と、ネットワーク トラフィックからの CPU 負荷という 2 つの異なるカテゴリがあります。
トラフィック サポート用にキャパシティ プランニングを行う際には、考慮を要する点が 2 つあります。 1 つ目は、DC 間での Active Directory レプリケーション トラフィックの量を把握する必要があるという点です。 2 つ目は、サイト内のクライアントからサーバーへのトラフィックを評価する必要があるという点です。 サイト内トラフィックでは主に、クライアントに返送される大量のデータに比べると、クライアントから受信する要求の量は少なくなります。 サーバーあたり最大 5,000 ユーザーの環境では、通常は 100 MB で十分です。 5,000 ユーザーを超えるの環境では、1 GB のネットワーク アダプターと Receive Side Scaling (RSS) のサポートを使用することをお勧めします。
サイト内トラフィックのキャパシティを評価するには、特にサーバー統合シナリオの場合、サイト内のすべての DC の Network Interface(*)\Bytes/sec パフォーマンス カウンターを確認し、それらを合計して、その合計を DC のターゲット数で割る必要があります。 この数値を計算する簡単な方法は、Windows 信頼性およびパフォーマンス モニターを開き、積み上げ面グラフ ビューを確認することです。 すべてのカウンターの尺度が同じであることを確認してください。
この一般的な規則が特定の環境に適用されるかどうかを検証するために、より複雑な方法の例を見てみましょう。 この例では、次のことを前提としています。
- 目標は、サーバーの設置面積をできる限り削減することです。 理想は、1 台のサーバーで負荷を処理し、冗長性のために追加のサーバーを展開することです (n + 1 シナリオ)。
- このシナリオでは、現在のネットワーク アダプターは 100 MB のみをサポートし、切り替えられた環境にあります。
- n シナリオ (1 台の DC がない場合) では、ターゲット ネットワーク帯域幅の最大使用率は 60% です。
- 各サーバーには、約 10,000 のクライアントが接続されています。
では、このシナリオ例について、Network Interface(*)\Bytes Sent/sec カウンターのグラフでどのようなことがわかるかを見てみましょう。
- 営業日は午前 5 時 30 分頃に始まり、午後 7 時頃に終わります。
- 最も負荷の高いピーク時間帯は午前 8 時から午前 8 時 15 分までで、最も負荷の高い DC では 1 秒あたり 25 バイトを超えるデータが送信されます。
Note
すべてのパフォーマンス データは履歴データであり、午前 8:15 のピーク データ ポイントは午前 8 時から午前 8 時 15 分までの負荷を示します。
- 午前 4 時前にスパイクが発生し、最も負荷の高い DC で 1 秒あたり 20 バイト以上が送信されます。これは、異なるタイム ゾーンからの負荷や、バックアップなどバックグラウンド インフラストラクチャのアクティビティを示している可能性があります。 午前 8 時のピークはこのアクティビティを超えているため、関連性はありません。
- サイト内には 5 台の DC があります。
- 最大負荷は DC あたり約 5.5 MBps で、これは 100 MB 接続 の44% に相当します。 このデータを使用すると、午前 8 時から午前 8 時 15 分までの時間帯に必要な合計帯域幅は 28 MBps であると見積もることができます。
Note
ネットワーク インターフェイスの送受信カウンターはバイト単位ですが、ネットワーク帯域幅はビット単位で測定されます。 したがって、合計帯域幅を知るには、100 MB ÷ 8 = 12.5 MB、1 GB ÷ 8 = 128 MB を計算する必要があります。
データを確認したら、そこからどのような結論を導き出せるでしょうか。
- 現在の環境は、60% の目標使用率で n + 1 レベルのフォールト トレランスを満たしています。 1 つのシステムをオフラインにすると、サーバーあたりの帯域幅が約 5.5 MBps (44%) から約 7 MBps (56%) に変化します。
- 1 台のサーバーに統合するという前述の目標に基づくと、この変更では、100 MB の接続の最大目標使用率と可能な使用率を超過しています。
- 1 GB の接続の場合、この値は合計キャパシティの 22% に相当します。
- n + 1 シナリオでの通常の運用条件下では、クライアントの負荷は、サーバーあたり約 14 MBps または合計キャパシティの 11% と、比較的均等に分散されます。
- 1 台の DC が使用できない場合の十分なキャパシティを確保するには、サーバーあたりの通常の動作目標は、ネットワーク使用率約 30% またはサーバーあたり 38 MBps になります。 フェイルオーバーの目標は、ネットワーク使用率 60% またはサーバーあたり 72 MBps になります。
最終的なシステム展開には、1 GB のネットワーク アダプターと、その負荷をサポートするネットワーク インフラストラクチャへの接続が必要です。 ネットワーク トラフィックの量が原因で、ネットワーク通信からの CPU 負荷によって AD DS の最大スケーラビリティが制限される可能性があります。 これと同じプロセスを使用して、DC への受信通信を見積もることができます。 ただし、ほとんどのシナリオでは、受信トラフィックは送信トラフィックよりも小さいため、受信トラフィックを計算する必要はありません。
サーバーあたり 5,000 ユーザー数を超える環境では、ハードウェアで RSS がサポートされていることを確認することが重要です。 ネットワーク トラフィック量が多いシナリオでは、割り込み負荷の分散処理がボトルネックになることがあります。 Processor(*)\% Interrupt Time カウンターを調べて、割り込み時間が CPU 間で不均等に分散されていないか確認することで、潜在的なボトルネックを検出できます。 RSS 対応のネットワーク インターフェイス コントローラー (NIC) を使用すると、これらの制限を軽減し、スケーラビリティを向上させることができます。
Note
同様のアプローチを使用して、データセンターを統合する場合やサテライト ロケーションの DC を廃止する場合に、さらにキャパシティが必要かどうかを見積もることができます。 必要なキャパシティを見積もるには、クライアントへの送信トラフィックと受信トラフィックのデータを確認します。 その結果、ワイド エリア ネットワーク (WAN) リンクに存在する OD トラフィックの量が得られます。
場合によっては、証明書のチェックが WAN での厳しいタイムアウトに対応できない場合など、トラフィックが遅いために、予想よりも多くのトラフィックが発生する可能性があります。 このため、WAN のサイズ設定と使用率は反復的で継続的なプロセスである必要があります。
ネットワーク帯域幅に関する仮想化に関する考慮事項
物理サーバーについての一般的な推奨は、5,000 人を超えるユーザーをサポートするサーバーで 1 GB です。 複数のゲストが基盤となる仮想スイッチ インフラストラクチャの共有を開始した後は、システム内のすべてのゲストをサポートするためにホストが十分なネットワーク帯域幅を持っているかどうかに特に注意する必要があります。 ネットワークに、ホスト上で VM として実行されている DC が含まれていて、ネットワーク トラフィックが仮想スイッチを経由するか、物理スイッチに直接接続されているかに関係なく、帯域幅を考慮する必要があります。 仮想スイッチは、アップリンクが接続が送信するデータ量をサポートする必要があるコンポーネントです。つまり、スイッチにリンクされている物理ホスト ネットワーク アダプターは、DC 負荷と、物理ネットワーク アダプターに接続されている仮想スイッチを共有する他のすべてのゲストをサポートできる必要があります。
ネットワーク計算の概要例
次の表は、ネットワーク キャパシティの計算に使用できるシナリオ例の値を示します。
| システム | 最大帯域幅 |
|---|---|
| DC 1 | 6.5 MBps |
| DC 2 | 6.25 MBps |
| DC 3 | 6.25 MBps |
| DC 4 | 5.75 MBps |
| DC 5 | 4.75 MBps |
| トータル | 28.5 MBps |
この表に基づくと、推奨される帯域幅は 72 MBps (28.5 MBps ÷ 40%) になります。
| ターゲット システム数 | 合計帯域幅 (上記から) |
|---|---|
| 2 | 28.5 MBps |
| 結果として得られる通常の動作 | 28.5 ÷ 2 = 14.25 MBps |
ここでも、クライアントの負荷は時間の経過とともに増加すると想定する必要があるため、この増加に対してできるだけ早い段階で計画を立てる必要があります。 少なくとも 50% のネットワーク トラフィックの増加を見込んで計画を立てることをお勧めします。
Storage
ストレージのキャパシティ プランニングでは、次の 2 つの点を考慮する必要があります。
- 容量 (ストレージのサイズ)
- パフォーマンス
容量は重要ですが、パフォーマンスを無視しないことが重要です。 現在のハードウェア コストを考えると、ほとんどの環境では、どちらの要素も大きな懸念材料になるほど深刻ではありません。 このため、通常はデータベース サイズと同じ量の RAM を配置することが推奨されます。 ただし、大規模な環境のサテライト拠点では、この推奨内容が過剰である可能性もあります。
サイズ変更
ストレージの評価
Active Directory が初めて登場した当時は 4 GB と 9 GB のドライブが最も一般的なドライブ サイズでしたが、その頃と比べて現在では、最大規模の環境を除くほとんどの環境で、Active Directory のサイズ設定は考慮されなくなりました。 180 GBの範囲で使用可能な最小のハード ドライブ サイズを使用して、オペレーティング システム全体、SYSVOL、NTDS.dit を 1 つのドライブに簡単に収めることができます。 そのため、この分野への過剰な投資は避けることをお勧めします。
ストレージのデフラグを実行できるように、使用可能な容量として NTS.dit サイズの 110% を確保することをお勧めします。 それ以外に、将来の成長に対応するには通常の考慮事項も検討する必要があります。
ストレージを評価する場合は、まず NTDS.dit と SYSVOL に要するサイズを評価する必要があります。 これらの値は、固定ディスクと RAM の割り当てサイズを決定するために役立ちます。 これらのコンポーネントのコストが比較的低いため、計算を行う際にそれほど正確である必要はありません。 ストレージ評価の詳細については、「ストレージの制限」および「Active Directory ユーザーと組織単位の増加予測」を参照してください。
Note
前の段落でリンクされている記事は、Windows 2000 での Active Directory のリリース時に行われたデータ サイズの推定に基づいています。 独自の見積もりを作成する場合は、環境内のオブジェクトの実際のサイズを反映したオブジェクト サイズを使用してください。
複数のドメインが含まれる既存の環境を確認すると、データベース サイズにばらつきがあることに気付くことがあります。 このようなバリエーションを見つけた場合は、グローバル カタログ (GC) と非 GC の最小サイズを使用します。
データベースのサイズは、OS のバージョンによって異なる場合があります。 Windows Server 2003 などの以前のバージョンの OS を実行している DC では、Windows Server 2008 R2 などの新しいバージョンを実行する場合よりもデータベース サイズが小さくなります。 DC で Active Directory REcycle Bin や Credential Roaming などの機能が有効になっている場合は、データベース サイズにも影響する可能性があります。
Note
- 新しい環境では、同じドメイン内の 100,000 人のユーザーで約 450 MB の領域を消費することを覚えておいてください。 属性の設定で、消費される領域の合計量に大きな影響を与える可能性があります。 属性は、Microsoft Exchange Server や Lync など、サードパーティ製品と Microsoft 製品の両方の多数のオブジェクトによって設定されます。 このため、環境の製品ポートフォリオに基づいて評価することをお勧めします。 ただし、最大規模の環境以外では、正確な見積もりを作成するための計算やテストに、多大な時間や労力をかける価値がない可能性があることにも注意する必要があります。
- オフライン デフラグを有効にするには、使用可能な空き領域として NTDS.dit サイズの 110% を確保できることを確認してください。 この空き領域により、サーバーの 3 ~ 5 年のハードウェア寿命にわたり、成長に対応するための計画を立てることもできます。 そのためのストレージがある場合、成長とデフラグに対応するための安全な方法は、ストレージ用に DIT の 300% に相当する十分な空き領域を割り当てることです。
ストレージの仮想化に関する考慮事項
複数の仮想ハード ディスク (VHD) ファイルを 1 つのボリュームに割り当てるシナリオでは、ニーズに合わせて十分な領域を確保できるように、少なくとも DIT の 210% (DIT の 100% + 空き領域として 110%) のサイズの固定状態ディスクを使用する必要があります。
ストレージ計算の概要例
次の表に、架空のストレージ シナリオの領域要件を見積もるために使用する値を示します。
| 評価フェーズから収集されたデータ | サイズ |
|---|---|
| NTDS.dit のサイズ | 35 GB |
| オフラインでのデフラグを許可する修飾子 | 2.1 GB |
| 必要なストレージの合計 | 73.5 GB |
Note
ストレージの見積もりには、SYSVOL、OS、ページ ファイル、一時ファイル、ローカル キャッシュ データ (インストーラー ファイル、アプリケーションなど) に必要なストレージの量も含める必要があります。
Storage performance (ストレージのパフォーマンス)
ストレージはどのコンピューターでも最も低速なコンポーネントであるため、クライアント エクスペリエンスに最も大きい悪影響を及ぼす可能性があります。 大規模な環境で、この記事に記載されている RAM サイズに関する推奨事項を適用できない場合、ストレージのキャパシティ プランニングを軽視した結果、システム パフォーマンスに壊滅的な影響が及ぶ可能性があります。 利用可能なストレージ テクノロジの複雑さと多様性によってリスクがさらに増大します。OS、ログ、データベースを別々の物理ディスクに配置するという一般的な推奨事項は、すべてのシナリオに普遍的に当てはまるわけではないためです。
ディスクに関する以前の推奨事項では、ディスクは I/O の分離を可能にする専用のスピンドルであることが前提になっていました。 この前提は、以下のストレージ タイプの導入により当てはまらなくなりました。
- RAID
- 新しいストレージの種類と仮想化および共有ストレージのシナリオ
- 記憶域ネットワーク (SAN) 上の共有スピンドル
- SAN またはネットワークに接続されたストレージ上の VHD ファイル
- ソリッド ステート ドライブ (SSDs)
- 階層型ストレージ アーキテクチャ (SSD ストレージ階層キャッシング、より大きなスピンドルベースのストレージなど)
RAID、SAN、NAS、JBOD、記憶域スペース、VHD などの共有ストレージは、バックエンド ストレージに配置された他のワークロードによって過負荷になる可能性があります。 これらの種類のストレージには、物理ディスクと AD アプリケーション間の SAN、ネットワーク、またはドライバーの問題により、調整や遅延が発生する可能性があるという追加の課題もあります。 わかりやすく言えば、これらは悪い構成ではありませんが、より複雑なため、すべてのコンポーネントが意図したとおりに動作していることを確認するために特別な注意を払う必要があります。 詳細な説明については、この記事の付録 C および付録 D を参照してください。 また、SSD では I/O を 1 回ずつしか処理できないハード ドライブによる制限はありませんが、それでも過負荷になる可能性のある I/O 制限があります。
要約すると、ストレージ アーキテクチャに関係なく、すべてのストレージ パフォーマンス プランニングの目標は、必要な数の I/O が常に利用可能であり、許容可能な時間枠内で実行されるようにすることです。 ローカル接続されたストレージを使用するシナリオについては、付録 C で設計と計画の詳細を参照してください。 付録に記載されている原則は、より複雑なストレージ シナリオや、バックエンド ストレージ ソリューションをサポートするベンダーとの打ち合わせに適用できます。
現在利用可能なストレージ オプションが多数あるため、AD DS 展開のニーズを満たすソリューションを計画する際には、ハードウェア サポート チームまたはベンダーに相談することをお勧めします。 検討時に、特にデータベースが RAM に対して大きすぎる場合は、次のパフォーマンス カウンターが役立つ場合があります。
LogicalDisk(*)\Avg Disk sec/Read(たとえば、NTDS.dit がドライブ D に格納されている場合、完全パスはLogicalDisk(D:)\Avg Disk sec/Readになります)LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
データを提供するときは、現在の環境を可能な限り正確に把握できるように、サンプリング間隔が 15 分、30 分、または 60 分であることを確認する必要があります。
結果を評価する
通常、最も要求の厳しいコンポーネントはデータベースであるため、このセクションではデータベースからの読み取りに焦点を当てます。 <NTDS Log>)\Avg Disk sec/Write と LogicalDisk(<NTDS Log>)\Writes/sec) を置き換えることで、ログ ファイルへの書き込みに同じロジックを適用できます。
LogicalDisk(<NTDS>)\Avg Disk sec/Read カウンターは、現在のストレージのサイズが適切かどうかを示します。 その値が、ディスクの種類に対して予想されるディスク アクセス時間とほぼ等しい場合、LogicalDisk(<NTDS>)\Reads/sec カウンターは有効な測定値です。 その結果が、ディスクの種類に対するディスク アクセス時間とほぼ等しい場合、LogicalDisk(<NTDS>)\Reads/sec カウンターは有効な測定値です。 これはバックエンド ストレージの製造元の仕様によって変わる可能性がありますが、LogicalDisk(<NTDS>)\Avg Disk sec/Read の適切な範囲は、おおよそ次のようになります。
- 7200 rpm: 9 ~ 12.5 ミリ秒 (ms)
- 10,000 rpm: 6 ~ 10 ms
- 15,000 rpm: 4 ~ 6 ms
- SSD – 1 から 3 ms
ストレージのパフォーマンスは 15 ミリ秒から 20 ミリ秒で低下するという声もあります。 このような値と上の一覧に示されている値の違いは、一覧の値が通常の動作範囲を示していることです。 他方の値はトラブルシューティングを目的としており、クライアント エクスペリエンスがいつ低下して顕著になったのかを特定するために役立ちます。 詳細については、付録 C を参照してください。
LogicalDisk(<NTDS>)\Reads/secは、システムが現在実行している I/O の量です。LogicalDisk(<NTDS>)\Avg Disk sec/Readの値がバックエンド ストレージの最適な範囲内であれば、LogicalDisk(<NTDS>)\Reads/secを直接使用してストレージのサイズを決定できます。LogicalDisk(<NTDS>)\Avg Disk sec/Readの値がバックエンド ストレージの最適な範囲内でない場合は、次の式に従って追加の I/O が必要になります:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ Physical Media Disk Access Time ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
これらの計算を行うときは、次の点を考慮する必要があります。
- サーバーの RAM サイズが最適ではない場合は、結果の値が高くなりすぎて、計画に役立つ正確さが得られません。 ただし、そのような値を使用して最悪のシナリオを予測することはできます。
- RAM を追加または最適化すると、読み取り I/O の
LogicalDisk(<NTDS>)\Reads/Secも減少します。 この減少により、ストレージ ソリューションが、元の計算で推測したほど堅牢ではなくなる可能性があります。 計算は個々の環境、特にクライアントの負荷によって大きく異なるため、この意味を詳細に説明することはできません。 ただし、RAM を最適化した後は、ストレージのサイズを調整することをお勧めします。
パフォーマンスに関する仮想化に関する考慮事項
前のセクションと同様に、ここでの目標は、共有インフラストラクチャがすべてのコンシューマーの合計負荷をサポートできるようにすることです。 以下のシナリオを計画するときは、この目標を念頭に置く必要があります。
- SAN、NAS、または iSCSI インフラストラクチャ上で他のサーバーまたはアプリケーションと同じメディアを共有する物理 CD。
- メディアを共有する SAN、NAS、または iSCSI インフラストラクチャへのパススルー アクセスを使用するユーザー。
- 共有メディア上のローカル VHD ファイル、または SAN、NAS、iSCSI インフラストラクチャを使用しているユーザー。
ゲスト ユーザーの観点では、ホストを経由してストレージにアクセスする必要がある場合、ユーザーはアクセスするために追加のコード パスをたどる必要があるため、パフォーマンスに影響します。 パフォーマンス テストでは、ホスト システムがプロセッサをどの程度使用するかに応じて、仮想化がスループットに影響を与えることが示されています。 プロセッサ使用率は、ゲスト ユーザーがホストに要求するリソースの量からも影響を受けます。 仮想化シナリオでの処理ニーズに応じた、処理の仮想化に関する検討では、この要求を考慮する必要があります。 詳細については、付録 A を参照してください。
さらに問題を複雑にしているのは、現在使用できるストレージ オプションの数と、それぞれのパフォーマンスへの影響が大きく異なることです。 これらのオプションには、パススルー ストレージ、SCSI アダプター、IDE が含まれます。 物理環境から仮想環境に移行する場合は、乗数 1.10 を使用して、仮想化されたゲスト ユーザーのさまざまなストレージ オプションを調整する必要があります。 ただし、異なるストレージ シナリオ間で転送する場合は、ストレージがローカル、SAN、NAS、または iSCSI のいずれであるかの方が重要であるため、調整を考慮する必要はありません。
仮想化の計算例
通常の動作状態で正常なシステムに必要な I/O の量を決定する場合:
- LogicalDisk(
<NTDS Database Drive>) ÷ 15 分間のピーク時間における 1 秒あたりの転送数 - 基盤となるストレージの容量を超えるストレージに必要な I/O の量を決定する場合:
必要な IOPS = (LogicalDisk(
<NTDS Database Drive>)) ÷ Avg Disk Read/sec ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Read/sec
| カウンタ | 値 |
|---|---|
Actual LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
.02 秒 (20 ミリ秒) |
Target LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
.01 秒 |
| 利用可能な I/O の変更に使用する乗数 | 0.02 ÷ 0.01 = 2 |
| 値の名前 | 値 |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transfers/sec |
400 |
| 利用可能な I/O の変更に使用する乗数 | 2 |
| ピーク時に必要な合計 IOPS | 800 |
キャッシュの適切なウォームアップ速度を決定するには:
- キャッシュのウォームアップに使用できる許容可能な最長時間を決定します。 一般的なシナリオで許容される時間は、ディスクからデータベース全体を読み込むのにかかる時間です。 RAM がデータベース全体を読み込めないシナリオでは、RAM 全体を埋めるのにかかる時間を使用します。
- 使用する予定のない領域を除いて、データベースのサイズを決定します。 詳細については、「ストレージの評価」を参照してください。
- データベースのサイズを 8 KB で割ると、データベースを読み込むために必要な I/O の合計数がわかります。
- 合計 I/O 数を、定義された時間枠内の秒数で割ります。
計算した数値はほぼ正確ですが、ESE (Extensible Storage Engine) を固定キャッシュ サイズに構成していないため正確ではない可能性があります。AD DS では、既定で可変キャッシュ サイズが使用されるため、以前に読み込まれていたページが削除されます。
| 収集するデータ ポイント | 値 |
|---|---|
| ウォームアップの最大許容時間 | 10 分 (600 秒) |
| データベース サイズ | 2 GB |
| 計算ステップ | Formula | 結果 |
|---|---|---|
| ページ内のデータベースのサイズを計算する | (2 GB × 1024 × 1024) = データベースのサイズ (KB 単位) | 2,097,152 KB |
| データベース内のページ数を計算する | 2,097,152 KB ÷ 8 KB = ページ数 | 262,144 ページ |
| キャッシュを完全にウォームアップするために必要な IOPS を計算する | 262,144 ページ ÷ 600 秒 = 必要な IOPS | 437 IOPS |
処理
Active Directory のプロセッサ使用率の評価
ほとんどの環境で、最も注意を払う必要がある要素は処理能力の管理です。 展開に必要な CPU キャパシティを評価するときは、次の 2 点を考慮する必要があります。
- 環境内のアプリケーションが共有サービス インフラストラクチャ内で、「コストがかかり非効率的な検索の追跡」に概説されている基準に基づき、意図したとおりに動作するかどうか。 大規模な環境では、アプリケーションのコーディングが適切でないと、CPU 負荷が不安定になり、他のアプリケーションを犠牲にして CPU 時間が過度に消費され、キャパシティ ニーズが高まり、DC に対する負荷が不均等に分散される可能性があります。
- AD DS は分散環境であり、処理ニーズが大きく異なる可能性のあるクライアントが多数あります。 各クライアントの推定コストは、使用パターンと、AD DS を使用しているアプリケーションの数によって異なる場合があります。 「ネットワーク」で説明したように、各クライアントを 1 つずつ確認するのではなく、環境内で必要な総キャパシティを評価するという形で見積もりを行う必要があります。
プロセッサ負荷に関する有効なデータがなければ正確な推測を行うことができないため、この見積もりは、ストレージの見積もりを完了してから行う必要があります。 また、プロセッサのトラブルシューティングを行う前に、ストレージによってボトルネックが発生していないことを確認することも重要です。 プロセッサの待機状態を削除すると、データを待機する必要がなくなるため、CPU 使用率が増加します。 このため、最も注意が必要なパフォーマンス カウンターは、Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read と Process(lsass)\ Processor Time です。 Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read カウンターが 10 ミリ秒または 15 ミリ秒を超える場合、Process(lsass)\ Processor Time 内のデータは不自然に低く、問題はストレージ パフォーマンスに関連しています。 可能な限り正確なデータを取得するには、サンプル間隔を 15 分、30 分、または 60 分に設定することをお勧めします。
処理の概要
ドメイン コントローラーのキャパシティ プランニングを計画するたには、処理能力に最も注意を払って理解する必要があります。 最大のパフォーマンスを確保できるようにシステムのサイズを決定する場合、ボトルネックとなるコンポーネントが常に存在します。適切なサイズのドメイン コントローラーでは、このコンポーネントはプロセッサです。
環境の需要がサイトごとに見直されるネットワーク セクションと同様に、要求されるコンピューティング容量についても同じことを行う必要があります。 利用可能なネットワーク テクノロジが通常の需要をはるかに超えるネットワーク セクションとは異なり、CPU 容量のサイズ設定にさらに注意を払ってください。 中規模の環境でも同様です。同時ユーザーが数千人を超えると、CPU に大きな負荷をかける可能性があります。
残念ながら、AD を利用するクライアント アプリケーションには大きなばらつきがあるため、CPU あたりのユーザーの一般的な見積もりを、すべての環境に適用することは到底できません。 具体的には、コンピューティング需要は、ユーザーの行動とアプリケーション プロファイルの影響を受けます。 そのため、環境ごとに個別にサイズを設定する必要があります。
ターゲット サイトの動作プロファイル
サイト全体のキャパシティ プランニングを行う場合、N + 1 というキャパシティ設計を目標にする必要があります。 この設計では、ピーク期間中に 1 つのシステムが失敗した場合でも、許容できるレベルの品質でサービスを続行できます。 N のシナリオでは、ピーク期間中にすべてのボックスの負荷が 80% ~ 100% 未満である必要があります。
また、サイトのアプリケーションとクライアントは、DC を検索するために推奨される DsGetDcName 関数のメソッドを使用します。DC は、わずかな一時的なスパイクのみで既に均等に分散されている必要があります。
ここで、目標どおりの環境と目標どおりでない環境の例を見てみましょう。 まず、意図したとおりに機能し、キャパシティ プランニングの目標枠を超過しない環境の例を見てみましょう。
最初の例では、次のように想定します。
- サイト内の 5 つの DC に、それぞれ 4 つの CPU があるものとします。
- 業務時間内の目標合計 CPU 使用率は、通常の動作条件 (N + 1) では 40%、それ以外の場合 (N) は 60% です。 業務時間外は、バックアップ ソフトウェアやその他のメンテナンス プロセスによって、利用可能なすべてのリソースが消費されることが予想されるため、目標 CPU 使用率は 80% です。
次に、下の画像で各 DC の (Processor Information(_Total)\% Processor Utility) グラフを見てみましょう。
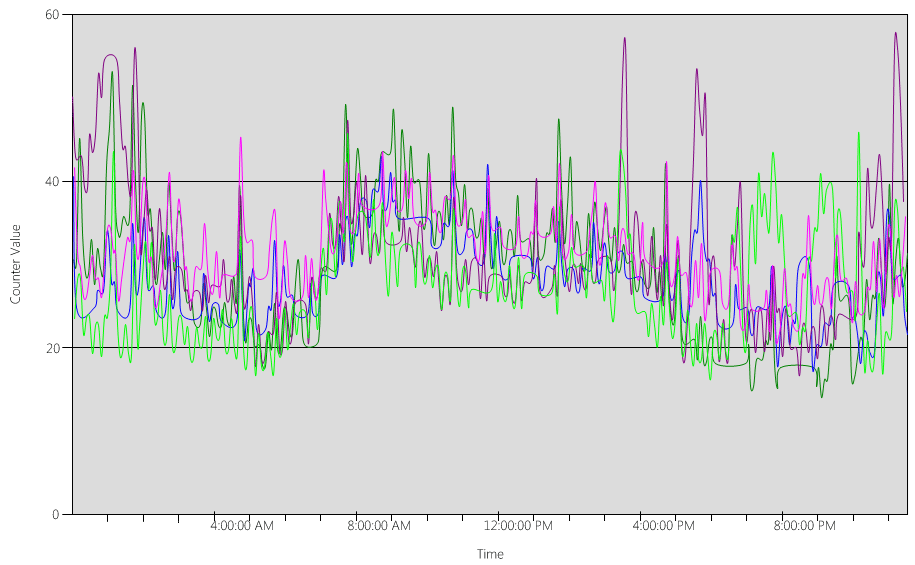
負荷は比較的均等に分散されています。これはクライアントが DC ロケーターと、適切に記述された検索を使用する場合に予想される状態です。
5 分間隔で数回、10% のスパイクがあり、時には 20% の場合もあります。 ただし、スパイクによって CPU 使用率がキャパシティ プランの目標を超える場合を除き、それらを調査する必要はありません。
すべてのシステムのピーク期間は、午前 8 時 から午前 9 時 15 分までです。 平均的な営業日は午前 5 時から午後 5 時までです。 したがって、午後 5 時から午前 4 時の間に発生する CPU 使用率のランダムなスパイクは業務時間外であるため、キャパシティ プランニングの考慮事項に含める必要はありません。
Note
適切に管理されたシステムでは、オフピーク期間中に発生するスパイクは通常、バックアップ ソフトウェア、システム全体のウイルス対策スキャン、ハードウェアまたはソフトウェアのインベントリ、ソフトウェアまたはパッチの展開などによって発生します。 これらのスパイクは業務時間外に発生するため、キャパシティ プランニングの目標に対して超過の加算対象にはなりません。
各システムは約 40% で、すべて同じ数の CPU を持っているため、そのうちの 1 つがオフラインになると、残りのシステムは推定 53% で実行されます。 システム D に対する 40% の負荷が均等に分割されて、システム A と C の既存の 40% の負荷に追加されます。 このような線形仮定は完全に正確ではありませんが、判断のための精度としては十分です。
次に、CPU 使用率が思わしくなく、キャパシティ プランニングの目標を超えている環境の例を見てみましょう。
この例では、2 つの DC が 40% で実行されています。 1 台のドメイン コントローラーがオフラインになり、他の DC で推定 CPU 使用率が 80% に達します。 このレベルの CPU 使用率は、キャパシティ プランのしきい値を大幅に超えており、負荷プロファイルで見られる 10% から 20% のヘッドルームの量も制限され始めます。 これによって N のシナリオでは、スパイクによって DC が 90% から 100% になり、応答性が低下する可能性があります。
CPU 要求の計算
Process\% Processor Time パフォーマンス カウンターは、アプリケーションのすべてのスレッドが CPU に費やした時間を合計し、経過したシステム時間の合計で除算したものです。 これにより、マルチ CPU システム上のマルチスレッド アプリケーションが 100% の CPU 時間を超える可能性があり、Processor Information\% Processor Utility カウンターとはまったく異なる解釈になります。 実際には、Process(lsass)\% Processor Time カウンターでは、プロセスの要求をサポートするためにシステムが必要とする 100% で実行されている CPU の数を追跡しています。 たとえば、カウンターの値が 200% の場合、AD DS の全負荷をサポートするには、2 つの CPU がそれぞれ 100% で実行される必要があることを意味します。 CPU が 100% のキャパシティで実行されていれば、CPU に費やされるコストと電力およびエネルギー消費の点で最も優れたコスト効率になりますが、付録 A で説明されている理由により、システムが 100% で実行されていない場合には、マルチスレッド システムの方が応答性が高くなります。
クライアント負荷の一時的なスパイクに対応するには、目標として、ピーク時の CPU をシステム キャパシティの 40% ~ 60% にすることをお勧めします。 たとえば、「ターゲット サイトの動作プロファイル」の最初の例では、AD DS の負荷をサポートするには、3.33 個の CPU (目標の 60%) から 5 個の CPU (目標の 40%) が必要になります。 OS やその他の必要なエージェント (ウイルス対策、バックアップ、監視など) の要求に応じて、キャパシティを追加する必要があります。 CPU エージェントに対するエージェントの影響は環境ごとに評価する必要がありますが、通常は、1 つの CPU 上のエージェント プロセスに対して 5% ~ 10% の範囲で割り当てることができます。 この例でピーク時の負荷をサポートするには、3.43 個 (目標の 60%) から 5.1 個 (目標の 40%) の CPU が必要です。
次に、特定のプロセスの計算例を見てみましょう。 ここでは、LSASS プロセスについて説明します。
LSASS プロセスでの CPU 使用率の計算
この例では、システムは N + 1 のシナリオであり、1 台のサーバーが AD DS の負荷を処理し、冗長性のために追加のサーバーが存在します。
次のグラフは、このシナリオ例のすべてのプロセッサにおける LSASS プロセスのプロセッサ時間を示しています。 このデータは、Process(lsass)\% Processor Time パフォーマンス カウンターから収集されたものです。
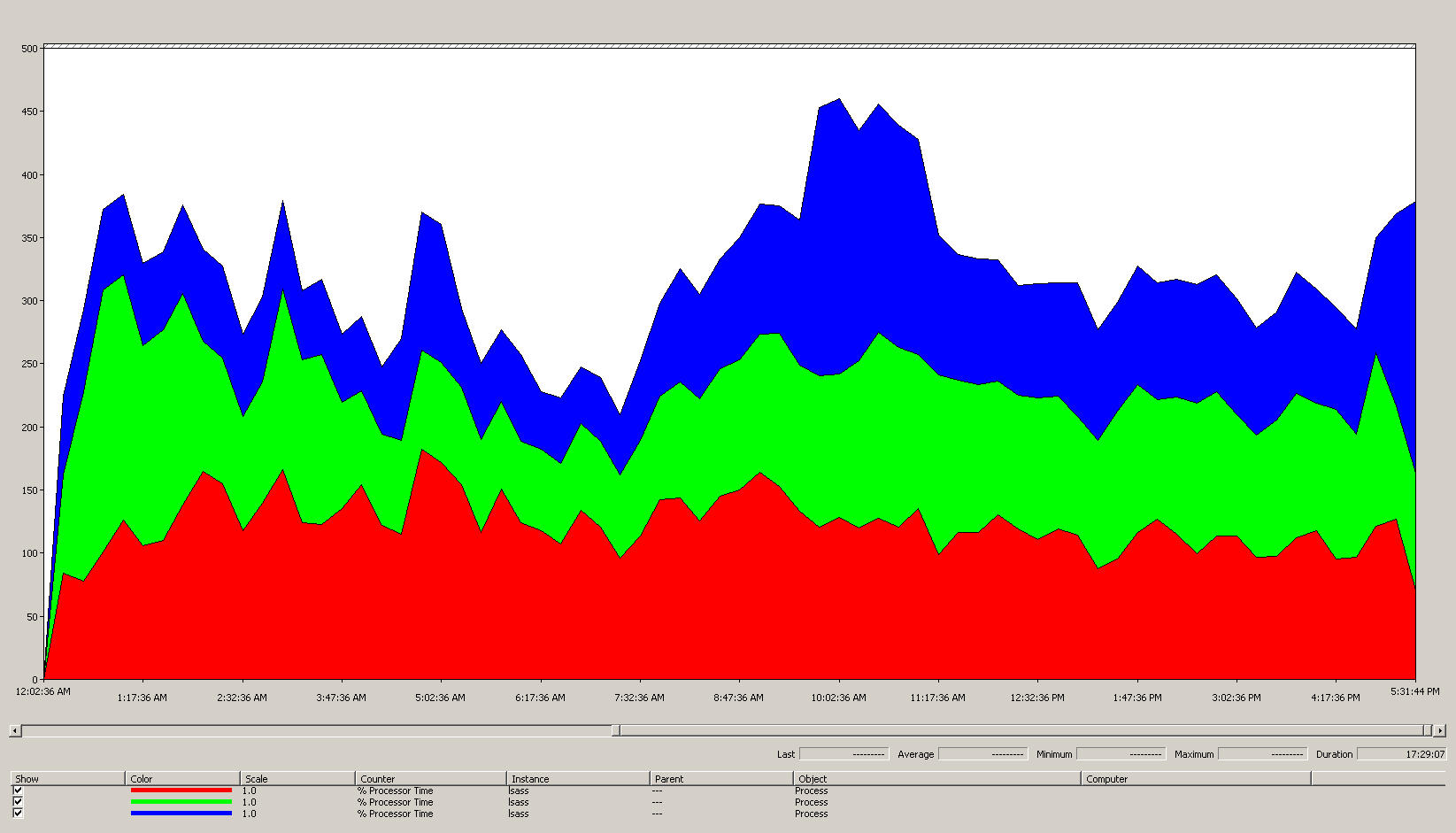
シナリオ環境について、このグラフからわかることは次のとおりです。
- サイトには 3 つのドメイン コントローラーがあります。
- 営業日は午前 7 時頃に始まり、午後 5 時頃に終わります。
- 一日で最も忙しい時間帯は午前 9 時 30 分から午前 11 時までです。
Note
すべてのパフォーマンス データは履歴です。 午前 9 時 15 分のピーク データ ポイントは、午前 9 時から午前 9 時 15 分までの負荷を示しています。
- 午前 7 時より前にスパイクがあります。これは、異なるタイム ゾーンからの負荷や、バックアップなどバックグラウンド インフラストラクチャ アクティビティによる追加の負荷を示している可能性があります。 ただし、このスパイクは午前 9 時 30 分のピーク アクティビティよりも小さいため、問題の原因にはなりません。
最大負荷では、lsass によって、100% で実行されている 4.85 個分の CPU が消費されます。これは、1 つの CPU では 485% になります。 つまり、シナリオのサイトで AD DS を処理するには、約 12.25 個の CPU が必要であるということです。 バックグラウンド プロセス用に、推奨される 5% ~ 10% のキャパシティを追加した場合、サーバーが同じの負荷をサポートするには 12.30 ~ 12.25 個の CPU が必要になります。 将来的な成長を予ふまえた見積もりでは、この数値がさらに大きくなります。
LDAP の重みをチューニングするタイミング
シナリオによっては、LdapSrvWeight のチューニングを検討する必要があります。 キャパシティ プランニングにおいては、アプリケーションまたはユーザーの負荷や、基盤となるシステムの機能が均等に分散されていない場合に、これを行います。
次のセクションでは、Lightweight Directory Access Protocol (LDAP) の重みを調整する必要がある 2 つのシナリオ例について説明します。
例 1: PDC エミュレータ環境
プライマリ ドメイン コントローラー (PDC) エミュレータを使用している場合、ユーザーまたはアプリケーションの動作が均等に分散されていないと、一度に複数の環境に影響を及ぼす可能性があります。 グループ ポリシー管理ツール、2 回目の認証の試行、信頼の確立など、複数のツールやアクションが PDC エミュレータをターゲットとしていることで、PDC エミュレータの CPU リソースは、多くの場合、展開内の他の場所よりも要求が大きくなります。
- PDC エミュレータは、CPU 使用率に顕著な違いがある場合にのみ調整する必要があります。 チューニングでは、PDC エミュレータの負荷を軽減し、他の DC の負荷を増やして、より均等な負荷分散を可能にする必要があります。
- このような場合は、PDC エミュレータの
LDAPSrvWeightの値を 50 ~ 75 の範囲に設定します。
| System | 既定値での CPU 使用率 | 新しい LdapSrvWeight | 新しい CPU 使用率の推定値 |
|---|---|---|---|
| DC 1 (PDC エミュレーター) | 53% | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
ここでの問題点は、PDC エミュレータ ロールが、(特にサイト内の別のドメイン コントローラーに) 転送または強制移行された場合、新しい PDC エミュレータで CPU 使用率が劇的に増加することです。
この例のシナリオでは、「ターゲット サイトの動作プロファイル」に基づいて、このサイトの 3 台のドメイン コントローラーすべてに 4 個の CPU があることを想定しています。 ドメイン コントローラーの 1 台に 8 個の CPU が搭載されている場合、通常の状況ではどうなるでしょうか。 使用率が 40% のドメイン コントローラーが 2 台と、使用率が 20% のドメイン コントローラーが 1 台あることになります。 この構成は必ずしも悪いわけではありませんが、LDAP の重み調整を使用すると、負荷分散のバランスを改善できます。
例 2: CPU 数が異なる環境
同じサイト内に CPU 数や速度が異なるサーバーがある場合は、それらが均等に分散されていることを確認する必要があります。 たとえば、サイトに 8 コア サーバーが 2 台と 4 コア サーバーが 1 台ある場合、4 コア サーバーの処理能力は他の 2 台のサーバーの半分です。 クライアントの負荷が均等に分散されている場合、CPU 負荷を処理するために、4 コア サーバーでは 2 台の 8 コア サーバーの 2 倍奮闘する必要があります。 さらに、8 コア サーバーのいずれかがオフラインになると、4 コア サーバーでは過負荷になります。
| システム | Processor Information\ % Processor Utility(_Total) 既定値での CPU 使用率 |
新しい LdapSrvWeight | 新しい CPU 使用率の推定値 |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30% |
| 4-CPU DC 2 | 40 | 100 | 30% |
| 8-CPU DC 3 | 20 | 200 | 30% |
"N + 1" シナリオでのプランニングは非常に重要です。 1 つの DC がオフラインになることによる影響は、シナリオごとに計算する必要があります。 負荷分散が均等な 1 つ前のシナリオでは、"N" シナリオで 60% の負荷を確保するために、すべてのサーバー間で負荷が均等に分散されるため、比率が一定に保たれ、問題なく分散が行われます。 PDC エミュレータのチューニング シナリオや、ユーザーまたはアプリケーションの負荷が均等でないな一般的なシナリオを見ると、効果は大きく異なります。
| システム | 調整された使用率 | 新しい LdapSrvWeight | 推定される新規使用率 |
|---|---|---|---|
| DC 1 (PDC エミュレーター) | 40% | 85 | 47% |
| DC 2 | 40% | 100 | 53% |
| DC 3 | 40% | 100 | 53% |
処理のための仮想化に関する考慮事項
仮想化環境のキャパシティ プランニングを行う場合は、ホスト レベルとゲスト レベルの 2 レベルを考慮する必要があります。 ホスト レベルでは、ビジネス サイクルのピーク期間を特定する必要があります。 仮想マシンの CPU 上でゲスト スレッドをスケジュールするには、物理マシンの CPU 上での AD DS スレッドの取得と似た処理が必要になるため、基盤となるホストの 40% ~ 60% を使用することをお勧めします。 ゲスト レベルでも、基礎となるスレッド スケジューリングの原則は変わらないため、CPU 使用率を 40% ~ 60% の範囲内に維持することをお勧めします。
ホストとゲストが 1 対 1 で直接マップされたシナリオで見積もりを行うには、これまでのセクションで行ったすべてのキャパシティ プランニングの見積もりを取り入れる必要があります。 共有ホスト シナリオでは、基になるプロセッサの効率に約 10% の影響があります。つまり、サイトで 40% を目標として 10 個の CPU が必要な場合、N 個のゲスト全体に割り当てる仮想 CPU の推奨数は 11 になります。 物理サーバーと仮想サーバーが混在するサイトでは、この変更は仮想マシン (VM) にのみ適用されます。 たとえば、N + 1 のシナリオでは、10 個の CPU を備えた 1 台の物理サーバーまたは直接マップされたサーバーは、DC 用にさらに 11 個の CPU が予約されているホスト上の 11 個の CPU を備えた 1 台のゲストとほぼ同等になります。
AD DS 負荷をサポートするために必要な CPU の数を分析および計算する際には、物理ハードウェアを購入する予定がある場合、市場で入手可能なハードウェアの種類が見積もりと正確に一致しない場合があることに注意してください。 ただし、仮想化を使用すると、その問題は発生しません。 VM を使用すると、必要な仕様の CPU を VM にいくつでも追加できるため、サイトにコンピューティング キャパシティを追加するために必要な労力を削減できます。 ただし、仮想化を使用する場合も、ゲストがより多くの CPU を必要とするときに基盤となるハードウェアが利用可能であることを保証するためのコンピューティング能力は、正確に評価する必要があります。 この場合も、将来的な拡大に備えて事前に計画を立てておく必要があります。
仮想化の計算の概要例
| システム | ピーク CPU |
|---|---|
| DC 1 | 120% |
| DC 2 | 147% |
| DC 3 | 218% |
| CPU 使用率の合計 | 485% |
| ターゲット システム数 | 合計帯域幅 (上記から) |
|---|---|
| 40% のターゲットで必要な CPU | 4.85 ÷ .4 = 12.25 |
このシナリオで拡大に備えて計画する場合、今後 3 年間で需要が 50% 増加すると想定すると、それまでに 18.375 個の CPU (12.25 × 1.5) を確保する必要があります。 あるいは、最初の 1 年が経過した後に需要を確認し、その結果に基づいて追加のキャパシティを追加することもできます。
NTLM の相互信頼クライアント認証の負荷
NTLM の相互信頼クライアント認証の負荷を評価する
多くの環境では、1 つ以上のドメインが信頼によって接続されている場合があります。 Kerberos 認証を使用しない別のドメインの ID に対する認証要求では、セキュリティで保護されたチャネルを 2 つのドメイン コントローラー間で使用して信頼を走査する必要があります。 ユーザーがサイト内でアクセスしようとしているドメイン コントローラーは、宛先ドメイン内か、宛先ドメインに至るパスより上位にある、別のドメイン コントローラーに接続します。 DC が信頼されたドメイン内の他の DC に対して実行できる呼び出しの数は、*MaxConcurrentAPI 設定で制御されます。 DC 間で相互に通信するために必要な負荷量をセキュリティで保護されたチャネルが処理できるようにするには、MaxConcurrentAPI を調整するか、フォレスト内であればショートカット信頼を作成します。 信頼間のトラフィック量を決定する方法の詳細については、MaxConcurrentApi 設定を使用して NTLM 認証のパフォーマンス チューニングを行う方法の記事を参照してください。
これまでのシナリオと同様、データを活用するには、一日のピーク時間帯にデータを収集する必要があります。
Note
フォレスト内およびフォレスト間のシナリオでは、複数の信頼を走査して認証が行われる可能性があるため、プロセスの各段階で調整する必要があります。
仮想化のプランニング
仮想化のキャパシティ プランニングを行うときは、次の点に注意する必要があります。
- 多くのアプリケーションでは、既定または特定の構成で Network Level Trust Manager (NTLM) 認証が使用されています。
- アクティブなクライアントの数が増えるにつれて、アプリケーション サーバーのキャパシティも増やす必要があります。
- クライアントは、セッションを開いておく時間を制限し、その代わり電子メールのプル同期などのサービスのために、定期的に再接続することがあります。
- インターネット アクセスに認証が必要な Web プロキシ サーバーでは、NTLM の負荷が高くなる可能性があります。
そのような用途では、NTLM 認証の負荷が大きくなる可能性があり、特にユーザーとリソースが異なるドメインにある場合は、DC に大きな負担がかかります。
信頼境界を越える負荷を管理するにはさまざまなアプローチがあり、多くの場合、それらを同時に使用できます。
- 信頼境界を越えたクライアント認証を削減するには、ユーザーが使用するサービスをユーザーと同じドメイン内に配置します。
- セキュリティで保護された使用可能なチャネルの数を増やします。 これらのチャネルはショートカット信頼と呼ばれ、フォレスト内およびフォレスト間のトラフィックに関連しています。
- MaxConcurrentAPI の既定の設定をチューニングします。
既存のサーバーで MaxConcurrentAPI を調整するには、次の式を使用します。
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
詳細については、「サポート技術情報の記事 2688798: MaxConcurrentApi の設定を使用して NTLM 認証のパフォーマンスを調整する方法」を参照してください。
仮想化に関する考慮事項
仮想化はオペレーティング システムのチューニング設定であるため、特別な考慮事項はありません。
仮想化調整の計算例
| データの種類 | 値 |
|---|---|
| セマフォ取得 (最小) | 6,161 |
| セマフォ取得 (最大) | 6,762 |
| セマフォ タイムアウト | 0 |
| セマフォの平均保持時間 | 0.012 |
| 収集期間 (秒) | 1:11 分 (71 秒) |
| 式 (KB 2688798 から) | ((6762 - 6161) + 0) × 0.012 / |
| MaxConcurrentAPI の最小値 | ((6762 - 6161) + 0) × 0.012 ÷ 71 = .101 |
この期間、このシステムでは既定値が許容されます。
キャパシティ プランニング目標の準拠を監視する
この記事では、プランニングとスケーリングが使用率目標にどのように役立つかについて説明しました。 次の表は、システムが意図したとおりに動作しているか確認するために監視する必要がある、推奨のしきい値をまとめたものです。 これらはパフォーマンスのしきい値ではなく、あくまでもキャパシティ プランニングでのしきい値であることに注意してください。 サーバーはこれらのしきい値を超えても引き続き動作しますが、ユーザーの需要の増加に伴ってパフォーマンスの問題が発生し始める前に、アプリケーションが意図したとおりに動作していることを検証する必要があります。 アプリケーションに問題がなければ、ハードウェアのアップグレードやその他の構成変更の評価を開始する必要があります。
| カテゴリ | パフォーマンス カウンター | 間隔/サンプリング | 移行先 | 警告 |
|---|---|---|---|---|
| プロセッサ | Processor Information(_Total)\% Processor Utility |
60 分 | 40% | 60% |
| RAM (Windows Server 2008 R2 以前) | Memory\Available MB | < 100 MB | 該当なし | < 100 MB |
| RAM (Windows Server 2012) | Memory\Long-Term Average Standby Cache Lifetime(s) | 30 分 | テストが必要 | テストが必要 |
| ネットワーク | Network Interface(*)\Bytes Sent/sec Network Interface(*)\Bytes Received/sec |
30 分 | 40% | 60% |
| Storage | LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/ReadLogicalDisk(( |
60 分 | 10 ms | 15 ms |
| AD サービス | Netlogon(*)\Average Semaphore Hold Time | 60 分 | 0 | 1 秒 |
付録 A: CPU のサイズ設定の条件
この付録では、環境の CPU サイズ設定ニーズを見積もるために役立つ用語と概念について説明します。
定義: CPU のサイズ設定
プロセッサ (マイクロプロセッサ) は、プログラムの命令を読み取って実行するコンポーネントです。
マルチコア プロセッサでは、同じ集積回路上に複数の CPU コアが搭載されています。
マルチ CPU システムには、同じ集積回路上にない複数の CPU があります。
論理プロセッサとは、オペレーティング システムの観点では、論理コンピューティング エンジンが 1 つだけあるプロセッサを指します。
これらの定義には、ハイパースレッド、マルチコア プロセッサ上の 1 コア、シングル コア プロセッサなどが含まれます。
今日のサーバー システムには複数のプロセッサ、複数のマルチコア プロセッサ、およびハイパースレッディングが搭載されているため、これらの定義は両方のシナリオに対応できるように一般化されています。 論理プロセッサという用語を使用するのは、利用可能なコンピューティング エンジンの OS とアプリケーションの観点を表すためです。
スレッドレベルの並列処理
各スレッドには独自のスタックと命令があるため、各スレッドは独立したタスクです。 AD DS はマルチスレッドであり、「Ntdsutil.exe を使用して Active Directory で LDAP ポリシーを表示および設定する方法」の指示に従って、使用可能なスレッドの数を調整できます。また、複数の論理プロセッサ間で適切にスケーリングできます。
データレベルの並列処理
データ レベルの並列処理とは、サービスが同じプロセスの複数のスレッド間でデータを共有し、複数のプロセス間で多数のスレッドを共有する場合です。 AD DS プロセスのみであっても、単一のプロセスの複数のスレッド間でデータを共有するサービスとしてカウントされます。 データへの変更は、キャッシュのすべてのレベル、すべてのコア、および共有メモリへの更新で実行中のすべてのスレッドに反映されます。 書き込み操作中は、命令処理を続行する前にすべてのメモリ位置が変更に合わせて調整されるため、パフォーマンスが低下する可能性があります。
CPU 速度とマルチコアに関する考慮事項
一般的に、論理プロセッサが高速になると、一連の命令を処理するために必要な時間が短縮されます。 論理プロセッサの数が多くなると、同時に実行できるタスクの数も増えます。 ただし、これらの規則は、共有メモリからのデータの取得、データ レベルの並列処理の待機、複数スレッドの同時管理によるオーバーヘッドなど、より複雑なシナリオには適用されません。 これらにより、マルチコア システムでのスケーラビリティは線形ではありません。
このような変化が起こる理由を理解するには、これらのシナリオを高速道路のように考えるとわかりやすくなります。 各スレッドを個々の車であり、各車線をコアであり、速度制限をクロック速度として考えます。
高速道路では、車が 1 台しかなければ、車線が 2 車線であろうと 12 車線であろうと関係ありません。 その車は制限速度の範囲内で走るだけです。
スレッドに必要なデータがすぐに利用できない場合、スレッドはメモリから関連データを取得するまで命令を処理できません。 これは高速道路の一部が通行止めになっているようなものです。 たとえ高速道路に車が 1 台しかなかったとしても、道路が再開されるまではどこにも行けないため、制限速度はその車の走行能力に影響しません。
車の台数が増加すると、高速道路が車の台数を管理するために必要となるオーバーヘッドも増加します。 道路がほとんど空いている深夜とは対照的に、ラッシュアワーの交通状況で高速道路を運転する場合は、運転手はより一層の集中力が必要です。 また、2 車線の高速道路では他の 1 車線だけを気にすればよいので、6 車線の高速道路で他の 5 車線の交通に注意を払いながら運転する場合よりも、集中力は少なくて済みます。
つまり、プロセッサの数を増やすべきか高速なプロセッサを追加すべきかという質問に対する答は非常に主観的なものとなり、ケースバイケースで検討する必要があります。 特に AD DS の場合、処理のニーズは環境要因に依存し、単一環境内のサーバーごとに異なる場合があります。 そのため、この記事の前半では、正確さを追求した計算を行うことに重点を置きませんでした。 予算に基づいて購入を決定する場合は、まずプロセッサの使用率を 40% (または対象の環境で必要な数値) に最適化することをお勧めします。 システムが最適化されていなければ、追加のプロセッサを購入してもそれほどメリットはありません。
システムアクティビティレベルによるパフォーマンスへの影響と応答時間
待ち行列理論は、待ち行列またはキューの数学的研究です。 コンピューティングの待ち行列理論では、利用法則が t 方程式で表されます。
U k = B ÷ T
ここで、U k は使用率、B はビジー状態で費やされた時間、T はシステムの監視に費やされた合計時間です。 Microsoft のコンテキストでは、これは、実行状態にある 100 ナノ秒 (ns) 間隔のスレッドの数を、指定された時間間隔で使用可能だった 100 ns 間隔の数で割った値を意味します。 この式は、「プロセッサ オブジェクト」および「PERF_100NSEC_TIMER_INV」に示されているプロセッサ使用率のパーセンテージを計算する式と同じです。
待ち行列理論では、使用率に基づいて待機中の項目の数を推定するための式 N = U k ÷ (1 - U k) も提供されています (N はキューの長さ)。 この式をすべての使用率間隔にわたってグラフ化すると、特定の CPU 負荷でプロセッサにキューが到達するまでの長さが次のように推定されます。
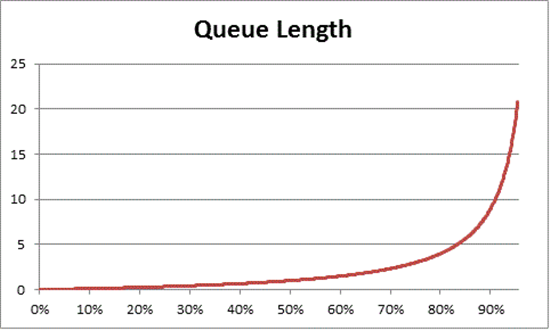
この推定に基づくと、CPU 負荷が 50% を超えると、平均的な待機では通常、キュー内に別の項目が 1 つ含まれ、CPU 使用率が急速に 70% に増加することがわかります。
待ち行れる理論が AD DS 展開にどのように適用されるかを理解するために、「CPU 速度とマルチコアに関する考慮事項」で使用した高速道路の例えに戻りましょう。
午後中頃の忙しい時間帯は、キャパシティが 40% ~ 70% の範囲になります。 交通量は十分あるため、運転する車線を選択する能力はそれほど制限されません。 別のドライバーがに割り込まれる可能性は高いですが、ラッシュアワーのときのように、車線内で他の車の間に安全な隙間を見つけるために必要なレベルの労力は必要ありません。
ラッシュアワーが近づくと、道路網のキャパシティは 100% に近くなります。 ラッシュアワーに車線を変更するのは非常に困難になります。車同士が接近しすぎていて、車線変更時に使える余地があまりないからです。
このため、キャパシティの長期平均を 40% と見積もると、実行に時間がかかる不適切なコード記述のクエリなど、一時的なスパイクであっても、休業日である週末の翌朝にアクティビティが急増するなど、一般的な負荷の異常なバーストであっても、負荷の異常なスパイクに対して余裕が生まれます。
前の記述では、プロセッサ時間のパーセンテージの計算は使用率法則の式と同じであるとみなしています。 この簡略化されたバージョンは、新しいユーザーにこの概念を紹介することを目的としています。 ただし、より高度な計算については、次のリファレンスをガイドとして使用できます。
- PERF_100NSEC_TIMER_INV を変換する
- B = アイドル スレッドが論理プロセッサで費やす 100 ナノ秒間隔の数。 PERF_100NSEC_TIMER_INV 計算における X 変数の変化
- T = 指定された時間範囲内の 100 ns 間隔の総数。 PERF_100NSEC_TIMER_INV 計算における Y 変数の変化。
- U k = Idle Thread または % Idle Time による論理プロセッサの使用率。
- 数学の計算:
- U k = 1 – %Processor Time
- %Processor Time = 1 – U k
- %Processor Time = 1 – B / T
- %Processor Time = 1 – X1 – X0 / Y1 – Y0
これらの概念をキャパシティ プランニングに適用する
前のセクションの計算を見ると、システムに必要な論理プロセッサの数を決定するのが非常に複雑に思えるかもしれません。 このため、システムのサイズを設定するアプローチでは、現在の負荷に基づいて最大ターゲット使用率を決定し、そのターゲットに到達するために必要な論理プロセッサの数を計算することに重点を置く必要があります。 これに加え、見積もりは完全に正確に行う必要はありません。 論理プロセッサの速度は同期に大きな影響を与えますが、パフォーマンスは他の領域によっても影響を受ける可能性があります。
- キャッシュの効率性
- メモリ コヒーレンスの要件
- スレッドのスケジューリングと同期
- 不完全なバランスのクライアント負荷
コンピューティング能力のコストは比較的低いため、必要な CPU の数を正確に計算するために時間をかける価値はありません。
この場合、40% の推奨は必須要件ではないことにも注意することが重要です。 この数値は、計算を行ううえでの妥当な開始点として使用します。 AD ユーザーの種類によって、必要な応答性のレベルは異なります。 プロセッサ アクセスの待機時間の増加によってクライアントのパフォーマンスに顕著な影響を与えることなく、平均 80% または 90% の使用率で環境を継続的に稼働させるシナリオもあり得ます。
システムには、RAM アクセス、ディスク アクセス、ネットワーク経由の応答の送信など、論理プロセッサよりもはるかに低速な他の領域もあり、これらも調整する必要があります。 次に例を示します。
ディスクバウンドで 90% の使用率で稼働しているシステムにプロセッサを追加しても、パフォーマンスが大幅に向上することは期待できません。 システムを詳しく調べると、I/O 操作の完了を待っているためにプロセッサにアクセスできないスレッドが多数あります。
ディスクバウンドの問題を解決すると、待機状態のままになっていたスレッドが停止しなくなり、CPU 時間の競合が増える可能性があります。 その結果、90% の使用率が 100% になります。 使用率を引き下げて管理可能なレベルに戻すには、両方のコンポーネントを調整する必要があります。
Note
Processor Information(*)\% Processor Utilityカウンターは、ターボ モードのあるシステムでは 100% を超えることがあります。 ターボ モードでは、CPU が短時間、定格プロセッサ速度を超えることがあります。 詳細については、CPU 製造元のドキュメントとカウンターの説明を参照してください。
システム全体の使用率に関する考慮事項を議論する際には、仮想化ゲストとしてのドメイン コントローラーも考慮する必要があります。 応答時間とシステム アクティビティ レベルがパフォーマンスに与える影響は、仮想化シナリオのホストとゲストの両方に適用されます。 ゲストが 1 台だけのホストでは、DC またはシステムのパフォーマンスは物理ハードウェアの場合とほぼ同じです。 ホストにゲストを追加すると、基盤となるホストの使用率が増加し、プロセッサにアクセスするための待機時間も長くなります。 このため、論理プロセッサの使用率は、ホスト レベルとゲスト レベルの両方で管理する必要があります。
これまでのセクションで使用した高速道路の例えについて、もう一度考えてみましょう。ただし、今回はゲスト VM を高速バスとして想像します。 高速バスは、公共交通機関やスクール バスとは異なり、停車せずに乗客の目的地まで直行します。
では、4 つのシナリオを想像してみましょう。
- システムのオフピーク時間帯は、深夜に高速バスに乗っているようなものです。 乗車すると、他の乗客はほとんどおらず、道路もほぼ空です。 バスが対処しなければならない交通渋滞がないため、乗車はゆったりとしており、乗客が自分の車で目的地まで運転するのと同じくらい速いです。 ただし、所要時間は、地域の速度制限によっても制限されます。
- オフピークの時間帯にシステムの CPU 使用率が高すぎる状況は、高速道路のほとんどの車線が閉鎖されている深夜の乗車に似ています。 バス自体はほとんど空いていますが、通行車線が制限される中、その時間にも走行している車両で道路は依然として混雑しています。 乗客は好きな席所に座ることができますが、実際の移動時間は車外の交通状況によって決まります。
- ピーク時の CPU 使用率が高いシステムは、ラッシュ時に混雑しているバスのようなものです。 移動に時間がかかるだけでなく、車内は乗客でいっぱいなので、乗り降りも難しくなります。 待ち時間を短縮しようとゲスト システムに論理プロセッサを追加することは、バスを追加して渋滞の問題を解決しようとするようなものです。 問題はバスの数ではなく、移動にかかる時間です。
- オフピークの時間帯に CPU 使用率が高いシステムは、夜間にほとんど空の道路を混雑したバスが走っている状況に似ています。 乗客は座席を見つけたりバスに乗り降りしたりするのに苦労するかもしれませんが、バスにすべての乗客が乗り込んだ後、移動はかなりスムーズになります。 このシナリオは、バスを追加することでパフォーマンスが向上する唯一のケースです。
これまでの例から、0% ~ 100% の使用率の間には、パフォーマンスにさまざまな度合いの影響を与えるシナリオが多数あることがわかります。 また、論理プロセッサを追加しても、非常に具体的なシナリオ以外では、必ずしもパフォーマンスが向上するとは限りません。 これらの原則を、ホストとゲストに推奨される 40% の CPU 使用率目標に適用することは難しくないはずです。
付録 B: プロセッサ速度の違いに関する考慮事項
「処理」では、データの収集中にプロセッサが 100% のクロック速度で実行されていて、交換システムの処理速度も同じであると想定しました。 これらの前提条件は正確ではありませんが (特に Windows Server 2008 R2 以降では既定の電源プランがバランスになっているため)、控えめに見積もる場合はこれらの前提条件を使用できます。 潜在的なエラーが多くなる可能性はありますが、プロセッサの速度が上がるにつれて安全マージンが増加するのみです。
- たとえば、11.25 個の CPU を必要とするシナリオで、データ収集時にプロセッサが半分の速度で動作していた場合、その需要のより正確な推定値は 5.125 ÷ 2 になります。
- ただしクロック速度を 2 倍にしても、記録中の期間内に発生する処理量が 2 倍になることを保証することは不可能です。 プロセッサが RAM またはその他のコンポーネントを待機するための時間は、ほぼ変わりません。 したがって、より高速なプロセッサでは、システムがデータを取得するのを待機している間、アイドル状態の時間の割合が大きくなる可能性があります。 最小公分母を使い、見積もりを控えめにしておき、不正確な結果につながるプロセッサ速度間の線形比較は想定しないことをお勧めします。
交換用ハードウェアのプロセッサ速度が現在のハードウェアより低い場合は、必要なプロセッサ数の推定値を比例的に増やす必要があります。 たとえば、サイトの負荷を支えるために 10 個のプロセッサが必要であると計算したシナリオについて考えてみましょう。 現在のプロセッサは 3.3 GHz で動作し、交換予定のプロセッサは 2.6 GHz で動作します。 元のプロセッサを 10 個交換しただけでは、速度が 21% 低下します。 速度を上げるには、10 個ではなく少なくとも 12 個のプロセッサが必要になります。
ただし、このような変更があってもキャパシティ管理プロセッサの使用率目標は変わりません。 プロセッサのクロック速度は負荷需要に基づいて動的に調整されるため、高負荷でシステムを実行すると、CPU が高クロック速度状態になっている時間が長くなります。 最終的な目標は、業務時間中のピーク時に、100% のクロック速度状態で CPU の使用率を 40% にすることです。 これより低い場合は、オフピーク時に CPU 速度を調整することで電力を節約できます。
Note
データ収集中にプロセッサの電源管理をオフにするには、電源プランを [ハイ パフォーマンス] に設定します。 電源管理をオフにすると、対象サーバーの CPU 消費量をより正確に測定できます。
さまざまなプロセッサの見積もりを調整するには、Standard Performance Evaluation Corporation のSPECint_rate2006 ベンチマークを使用することをお勧めします。 このベンチマークを使用するには:
Standard Performance Evaluation Corporation (SPEC) の Web サイトにアクセスします。
結果を選択します。
「CPU2006」と入力し、[Search] を選択します。
[Available Configurations] ドロップダウン メニューで、[All SPEC CPU2006] を選択します。
[Search Form Request] フィールドで [Simple] を選択し、[Go!] を選択します。
[Simple Request]で、対象のプロセッサを検索する条件を入力します。 たとえば、ES-2630 プロセッサを検索する場合は、ドロップダウン メニューで [Processor] を選択し、検索フィールドにプロセッサ名を入力します。 完了したら、[Execute Simple Fetch] を選択します。
検索結果から、サーバーとプロセッサの構成を探します。 検索エンジンから正確に一致する結果が返されない場合は、できるだけ近いものを探します。
[Result] 列と [# Cores] 列の値を記録します。
次の数式を使用して係数を決定します。
(("ターゲット プラットフォームのコアあたりのスコア値") × ("ベースライン プラットフォームのコアあたりの MHz")) ÷ (("ベースラインのコア ごとのスコア値") × ("ターゲット プラットフォームのコアあたりの MHz"))
たとえば、ES-2630 プロセッサの場合の変更は次のようになります。
(35.83 × 2000) ÷ (33.75 × 2300) = 0.92
必要なプロセッサ数と推定される数にこの係数を掛けます。
ES-2630 プロセッサの例では、プロセッサ数は 0.92 × 10.3 = 10.35 になります。
付録 C: オペレーティング システムとストレージの対話方法
「システムアクティビティレベルによるパフォーマンスへの影響と応答時間」で説明した待ち行列理論の概念は、ストレージにも適用されます。 これらの概念を効果的に適用するには、OS で I/O がどのように処理されるかを理解している必要があります。 Windows OS の場合、OS は各物理ディスクに対する I/O 要求を保持するためのキューを作成します。 ただし、物理ディスクは必ずしも単一のディスクであるとは限りません。 OS が、アレイ コントローラーまたは SAN 上のスピンドルの集合を 1 つの物理ディスクとして登録することもあり得ます。 アレイ コントローラーと SAN は、複数のディスクを 1 つのアレイ セットに集約し、それを複数のパーティションに分割して、各パーティションを物理ディスクとして使用することもできます (次の図を参照)。
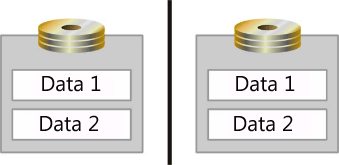
この図では、2 つのスピンドルがミラーリングされており、データ ストレージ用の論理領域に分割され、データ 1 とデータ 2 というラベルが付いています。 OS は、これらの論理領域をそれぞれ別々の物理ディスクとして登録します。
物理ディスクの定義が明確になったところで、この付録の情報をより深く理解するために役立つ、以下の用語についても理解しておきましょう。
- A spindle は、サーバーに物理的に取り付けられているデバイスです。 スピンドルは、サーバーに物理的に取り付けられているデバイスです。
- アレイはスピンドルの集合であり、コントローラーによって統合されます。
- アレイ パーティションは、統合されたアレイのパーティションです。
- 論理ユニット番号 (LUN) は、コンピューターに接続された SCSI デバイスのアレイに使用されます。 この記事では、SAN に関する説明で、これらの用語を使用します。
- ディスクには、OS によって単一の物理ディスクとして登録されるスピンドルまたはパーティションが含まれます。
- パーティションは、OS によって物理ディスクとして登録されるディスクの論理パーティションです。
オペレーティング システムのアーキテクチャに関する考慮事項
OS は、登録するディスクごとに先入れ先出し (FIFO: First In, First Out) で I/O キューを作成します。 ディスクには、スピンドル、アレイ、またはアレイ パーティションがあります。 OS が I/O を処理する方法に関しては、アクティブなキューが多いほど良好な状態です。 OS が FIFO キューをシリアル化する際には、ストレージ サブシステムに発行されたすべての FIFO I/O 要求を到着順に処理する必要があります。 OS が各ディスクをスピンドルまたはアレイと関連付ける際には、一意のディスク セットごとに I/O キューを管理することで、限られた I/O リソースに対するディスク間の競合を排除し、I/O 要求を単一のディスクに分離します。 ただし、Windows Server 2008 では、I/O 優先度設定という形の例外が導入されました。 低優先度の I/O を使用するように設計されたアプリケーションは、OS がいつ受け取ったかに関係なく、キューの最後尾に移動されます。 特に低優先度設定を使用するようにコーディングされていないアプリケーションは、既定で通常の優先度に設定されます。
シンプルなストレージ サブシステムの概要
このセクションでは、単純なストレージ サブシステムについて説明します。 まず、例として、コンピューター内の 1 つのハード ドライブを見てみましょう。 このシステムを主要なストレージ サブシステム コンポーネントに分解すると、次のようになります。
- 10,000 RPM の Ultra Fast SCSI HD × 1 (Ultra Fast SCSI の転送速度は 20 MBps)
- SCSI バス 1 × 1 (ケーブル)
- Ultra Fast SCSI アダプター × 1
- 32 ビット 33 MHz PCI バス × 1
Note
この例では、システムが通常 1 シリンダのデータを保持するディスク キャッシュが反映されていません。 この場合、最初の I/O には 10 ミリ秒かかり、ディスクはシリンダ全体を読み取ります。 その他のすべてのシーケンシャル I/O はキャッシュによって処理できます。 その結果、ディスク内キャッシュによってシーケンシャル I/O パフォーマンスが向上する可能性があります。
コンポーネントを特定したら、システムで転送できるデータ量と処理できる I/O 量がわかってきます。 I/O の量とシステムを通過できるデータの量は互いに関連していますが、同じ値ではありません。 この相関関係は、ブロック サイズと、ディスク I/O がランダムかシーケンシャルかによって異なります。 システムはすべてのデータをブロックとしてディスクに書き込みますが、アプリケーションによってブロック サイズが異なる場合があります。
次に、これらの項目をコンポーネントごとに分析してみましょう。
ハード ドライブのアクセス時間
平均的な 10,000 RPM ハード ドライブのシーク時間は 7 ミリ秒、アクセス時間は 3 ミリ秒です。 シーク時間とは、読み取りまたは書き込みヘッドがプラッター上の特定の位置に移動するまでにかかる平均時間です。 アクセス時間とは、ヘッドが正しい位置に移動してから、ディスクにデータを読み書きするためにかかる平均時間です。 したがって、10,000 RPM HD で一意のデータ ブロックを読み取る場合にかかる平均時間には、シーク時間とアクセス時間の両方が含まれ、データ ブロックあたり合計で約 10 ミリ秒 (0.010 秒) になります。
すべてのディスク アクセスでヘッドをディスク上の新しい位置に移動する必要がある場合、読み取りまたは書き込みの動作はランダムと呼ばれます。 すべての I/O がランダムである場合、10,000 RPM の HD では 1 秒あたり約 100 回の I/O (IOPS) を処理できます。
すべての I/O をハード ドライブ上の隣接セクターで行う場合、これをシーケンシャル I/O と呼びます。 シーケンシャル I/O にはシーク時間がありません。これは、最初の I/O が終了した後、読み取りまたは書き込みヘッドがハード ドライブが次のデータ ブロックを保存している場所の先頭にあるためです。 たとえば、10,000 RPM の HD では、次の式に基づいて、1 秒あたり約 333 回の I/O を処理できます。
1 秒あたり 1000 ミリ秒 ÷ I/O あたり 3 ミリ秒
ここまでの説明で、ハード ドライブの転送速度は、この例には関係ありません。 ハード ドライブのサイズに関係なく、10,000 RPM HD で処理できる IOPS の実際の量は、常に約 100 回のランダムまたは 300 シーケンシャル I/O です。 ドライブに書き込みを行うアプリケーションによってブロック サイズが異なるため、I/O ごとに取得されるデータの量も変わります。 たとえば、ブロック サイズが 8 KB の場合、100 の I/O 操作がハード ドライブに対して読み取りまたは書き込みを行い、合計 800 KB になります。 ただし、ブロック サイズが 32 KB の場合、100 回の I/O で処理されるハード ドライブに対する読み書きは 3,200 KB (3.2 MB) になります。 転送されるデータの総量を SCSI 転送速度が上回る場合、転送速度を上げても変化はありません。 詳細については、次の表を参照してください。
| 説明 | 7200 RPM、シーク時間 9 ミリ秒、アクセス時間 4 ミリ秒 | 10,000 RPM、シーク時間 7 ミリ秒、アクセス時間 3 ミリ秒 | 15,000 RPM、シーク時間 4 ミリ秒、アクセス時間 2 ミリ秒 |
|---|---|---|---|
| ランダム I/O | 80 | 100 | 150 |
| シーケンシャル I/O | 250 | 300 | 500 |
| 10,000 RPM ドライブ | 8 KB のブロック サイズ (Active Directory Jet) |
|---|---|
| ランダム I/O | 800 KB/秒 |
| シーケンシャル I/O | 2400 KB/秒 |
SCSI バックプレーン
SCSI バックプレーン (この例ではリボン ケーブル) がストレージ サブシステムのスループットに与える影響は、ブロック サイズによって異なります。 I/O が 8 KB ブロックの場合、バスではどのくらいの I/O を処理できるのでしょうか。 このシナリオでは、SCSI バスは 20 MBps、つまり 20480 KB/秒です。 20480 KB/秒を 8 KB ブロックで割ると、SCSI バスでサポートされる最大約 2,500 IOPS が得られます。
Note
次の表の数値はシナリオ例を表しています。 ほとんどの接続ストレージ デバイスでは現在、はるかに高いスループットを提供する PCI Express が使用されています。
| SCSI バスでサポートされるブロック サイズあたりの I/O | 2 KB ブロック サイズ | 8 KB ブロック サイズ (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 MBps | 10,000 | 2,500 |
| 40 MBps | 20,000 | 5,000 |
| 128 MBps | 65,536 | 16,384 |
| 320 MBps | 160,000 | 40,000 |
上の表に示されているように、この例のシナリオでは、スピンドルの最大値が 100 回の I/O であり、一覧に示されているどのしきい値を大幅に下回るため、バスがボトルネックになることはありません。
Note
このシナリオでは、SCSI バスの効率が 100% であることを前提としています。
SCSI アダプター
システムで処理できる I/O の量を判断するには、製造元の仕様を確認する必要があります。 I/O 要求を適切なデバイスに送信するには処理能力が必要であるため、システムで処理できる I/O の量は SCSI アダプタまたはアレイ コントローラ プロセッサによって異なります。
この例のシナリオでは、システムが 1,000 回の I/O を処理できることが前提になっています。
PCI バス
PCI バスは見落とされがちなコンポーネントです。 この例のシナリオでは、PCI バスはボトルネックではありません。 ただし、システムが拡張されると、将来的にボトルネックになる可能性があります。
この例のシナリオで PCI バスが転送できるデータ量は、次の式を使用して確認できます。
32 ビット ÷ 8 ビット/バイト × 33 MHz = 133 MBps
したがって、33 MHz で動作する 32 ビット PCI バスでは、133 MBps のデータを転送できると想定できます。
Note
この式の結果は、転送されるデータの理論上の上限を表しています。 実際には、ほとんどのシステムで到達するデータ量は上限の 50% 程度です。 特定のバースト シナリオでは、短時間で上限の 75% に達することもあります。
66 MHz の 64 ビット PCI バスでは理論上、次の式に基づいて最大 528 MBps をサポートできます。
64 ビット ÷ 8 ビット/バイト × 66 Mhz = 528 MBps
ネットワーク アダプターや 2 台目の SCSI コントローラーなど、他のデバイスを追加すると、すべてのデバイスが帯域幅を共有し、限られた処理リソースに対する競合が生じるため、システムで使用できる帯域幅が減少します。
ストレージ サブシステムを分析してボトルネックを特定する
このシナリオでスピンドルは、要求できる I/O の量を制限する要因になっています。 結果として、システムが送信できるデータ量もこのボトルネックにより制限されます。 この例は AD DS のシナリオであるため、送信可能なデータの量は 8 KB 単位で 1 秒あたり 100 回のランダム I/O で、Jet データベースにアクセスすると合計 800 KB/秒になります。 一方、ログ ファイルのみに割り当てるように構成したスピンドルの最大スループットは、8 KB 単位で 1 秒あたり 300 回のシーケンシャル I/O に制限され、合計 2,400 KB (1 秒あたり 2.4 MB) になります。
構成例のコンポーネントを分析できたところで、ストレージ サブシステムのコンポーネントを追加および変更するときにボトルネックが発生する可能性がある箇所を下の表を見てみましょう。
| メモ | ボトルネック分析 | ディスク | Bus | アダプター | PCI バス |
|---|---|---|---|---|---|
| これは、2 つ目のディスクを追加した後のドメイン コントローラーの構成です。 このディスク構成では、800 KB/秒のボトルネックが示されています。 | ディスクを 1 つ追加 (合計 = 2) I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD |
合計 200 I/O 合計 800 KB/秒。 |
|||
| 7 つのディスクを追加した後も、ディスク構成で 3200 KB/秒のボトルネックが示されています。 | ディスクを 7 つ追加 (合計 = 8) I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD |
合計 800 I/O。 合計 3200 KB/秒 |
|||
| I/O をシーケンシャルに変更すると、ネットワーク アダプターの IOPS が 1000 回に制限されるため、ボトルネックになります。 | ディスクを 7 つ追加 (合計 = 8) I/O はシーケンシャル 4 KB ブロック サイズ 10,000 RPM HD |
2400 I/O 秒はディスクに読み取り/書き込み可能、コントローラーは 1000 IOPS に制限 | |||
| ネットワーク アダプターを 10,000 IOPS をサポートする SCSI アダプターに置き換えると、ボトルネックはディスク構成に戻ります。 | ディスクを 7 つ追加 (合計 = 8) I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD SCSI アダプターのアップグレード (10,000 I/O のサポートが可能) |
合計 800 I/O。 合計 3,200 KB/秒 |
|||
| バスではサポートの上限が 20 MBps であるため、ブロック サイズを 32 KB に増やした場合はボトルネックになります。 | ディスクを 7 つ追加 (合計 = 8) I/O はランダム 32 KB ブロック サイズ 10,000 RPM HD |
合計 800 I/O。 25,600 KB/秒 (25 MBps) の速度でディスクの読み書きが可能です。 バスでのサポートの上限が 20 MBps です |
|||
| バスをアップグレードし、ディスクを追加した後も、ディスクはボトルネックのままです。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD 320 MBps の SCSI バスへのアップグレード |
2800 I/O 11,200 KB/秒 (10.9 MBps) |
|||
| I/O をシーケンシャルに変更した後も、ディスクはボトルネックのままです。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はシーケンシャル 4 KB ブロック サイズ 10,000 RPM HD 320 MBps の SCSI バスへのアップグレード |
8,400 I/O 33,600 KB/秒 (32.8 MB/秒) |
|||
| より高速なハード ドライブを追加した後も、ディスクはボトルネックのままです。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はシーケンシャル 4 KB ブロック サイズ 15,000 RPM HD 320 MBps の SCSI バスへのアップグレード |
14,000 I/O 56,000 KB/秒 (54.7 MBps) |
|||
| ブロック サイズを 32 KB に増やすと、PCI バスがボトルネックになります。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はシーケンシャル 32 KB ブロック サイズ 15,000 RPM HD 320 MBps の SCSI バスへのアップグレード |
14,000 I/O 448,000 KB/秒 スピンドルの読み取り/書き込みの上限は (437 MBps) です。 PCI バスは、理論上の最大速度 133 MBps (最高効率 75%) をサポートします。 |
RAID の概要
アレイ コントローラーをストレージ サブシステムに導入しても、その性質が劇的に変わるわけではありません。 計算の際に SCSI アダプタがアレイ コントローラーに置き換わるのみです。 ただし、使用するアレイ レベルが異なると、ディスクへのデータの読み取りと書き込みのコストが変わります。
RAID 0 では、データを書き込むと、RAID セット内のすべてのディスクにデータがストライプ化されます。 読み取りまたは書き込みの操作中、システムは各ディスクからのデータのプルや、各ディスクへのプッシュを行うため、この期間中にはシステムが送信できるデータ量が増加します。 したがって、10,000 RPM のドライブを使用しているこの例では、RAID 0 を使用すると 100 回の I/O 操作を実行できます。 システムがサポートする I/O の合計量は、スピンドル数 (N) に、スピンドルあたり 1 秒に 100 回の I/O を掛けた値、つまり N 個のスピンドル × 1 秒あたり 100 回の I/O/秒 (スピンドルあたり) です。

RAID 1 では、冗長性を確保するために、システムは 1 組のスピンドル間でデータをミラーリング (複製) します。 システムが読み取り I/O 操作を実行する際には、セット内の両方のスピンドルからデータを読み取ることができます。 このミラーリングにより、読み取り操作中に両方のディスクの I/O キャパシティが使用可能になります。 ただし、書き込まれたデータも 1 組のスピンドルでミラーリングする必要があるため、RAID 1 での書き込み操作にパフォーマンス上の利点はありません。 ミラーリングによって書き込み操作にかかる時間が長くなることはありませんが、システムが同時に複数の読み取り操作を行うことはできなくなります。 このため、個々の書き込み I/O 操作ごとに、2 回の読み取り I/O 操作のコストがかかります。
このシナリオで発生する I/O 操作の数を計算するには、次の式を使用できます。
"読み取り I/O" + 2 ×"書き込み I/O" = "消費された使用可能なディスク I/O の合計"
読み取りと書き込みの比率と展開内のスピンドル数がわかれば、アレイでサポートされる I/O の量を次の式で計算できます。
スピンドルあたりの最大 IOPS × 2 スピンドル × [(読み取り % + 書き込み %) ÷ (読み取り % + 2 × 書き込み %)] = 合計 IOPS
RAID 1 と RAID 0 の両方を使用するシナリオでは、読み取りおよび書き込み操作のコストは RAID 1 とまったく同じようにかかります。 ただし、I/O はミラー化されたセットごとにストライピングされるようになりました。 つまり、式は次のように変わります。
スピンドルあたりの最大 IOPS × 2 スピンドル × [(読み取り % + 書き込み %) ÷ (読み取り % + 2 × 書き込み %)] = 合計 I/O
RAID 1 セットで、N 個の RAID 1 セットをストライプ化すると、アレイが処理できる合計 I/O は N × RAID 1 セットあたりの I/O になります。
N × {スピンドルあたりの最大 IOPS × 2 スピンドル × [(読み取り % + 書き込み %) ÷ (読み取り % + 2 × 書き込み %)]} = 合計 IOPS
RAID 5 は、システムが N 個のスピンドルにデータをストライプ化し、+ 1 個のスピンドルにパリティ情報を書き込むため、N + 1 RAID と呼ばれることもあります。 ただし、RAID 5 では、書き込み I/O の実行時に、RAID 1 や RAID 1 + 0 よりも多くのリソースが使用されます。 RAID 5 では、オペレーティング システムがアレイに書き込み I/O を送信するたびに、以下のプロセスが実行されます。
- 古いデータの読み取り。
- 古いパリティの読み取り。
- 新しいデータの書き込み。
- 新しいパリティの書き込み。
OS がアレイ コントローラに送信するすべての書き込み I/O 要求に対し、完了するまでに 4 回の I/O 操作が必要になります。 したがって、N + 1 RAID の書き込み要求では、完了するまでに読み取り I/O の 4 倍の時間がかかります。 つまり、OS からの I/O 要求の数を、スピンドルが受け取る要求の数に変換するには、次の式を使用できます。
"読み取りI/O" + 4 ×"書き込み I/O" = "合計 I/O"
同様に、RAID 1 セットで読み取り/書き込みの比率とスピンドルの数がわかっている場合は、アレイがサポートできる I/O の量を次の式で特定できます。
スピンドルあたりの IOPS × (スピンドル – 1) × [(読み取り % + 書き込み %) ÷ (読み取り % + 4 × 書き込み %)] = 合計 IOPS
Note
上の式の結果には、パリティに属していないドライブは含まれません。
SAN の概要
ストレージ エリア ネットワーク (SAN) を環境に導入しても、ここまでのセクションで説明した計画の原則には影響しません。 ただし、SAN によって、接続されているすべてのシステムの I/O 動作が変わる可能性があることを考慮する必要があります。 SAN を使用する主な利点の 1 つは、内部または外部に接続されたストレージよりも冗長性が高くなることですが、キャパシティ プランニングではフォールト トレランスのニーズも考慮する必要があります。 また、システムに導入するコンポーネントが増えた場合は、そのような新しい部分も計算に組み込む必要があります。
それでは、SAN をコンポーネントに分解してみましょう。
- SCSI またはファイバー チャネル ハード ドライブ
- ストレージ ユニット チャネル バックプレーン
- ストレージ ユニットの本体
- ストレージ コントローラー モジュール
- 1 つ以上の SAN スイッチ
- 1 つ以上のホスト バス アダプター (HBA)
- 周辺機器相互接続 (PCI) バス
冗長性を考慮してシステムを設計する場合は、元のコンポーネントの 1 つ以上が動作しなくなる危機的な状況においてもシステムが動作し続けるように、追加のコンポーネントを含める必要があります。 ただし、キャパシティ プランニングを行う場合は、システムのベースライン キャパシティを正確に見積もるために、使用可能なリソースから冗長コンポーネントを除外する必要があります。これらのコンポーネントは通常、緊急事態が発生しない限りオンラインにならないためです。 たとえば、SAN に 2 つのコントローラー モジュールがある場合、元のモジュールが動作を停止しない限り、もう 1 つのモジュールが稼働状態にならないため、使用可能な合計 I/O スループットを計算するときは 1 つのモジュールのみを使用する必要があります。 冗長 SAN スイッチ、ストレージ ユニット、またはスピンドルも I/O の計算に含めないでください。
また、キャパシティ プランニングではピーク時の使用量のみが考慮されるため、使用可能なリソースとして冗長コンポーネントをカウントしないでください。 バーストやその他の異常なシステム動作に対応するには、ピーク使用率をシステムの飽和状態の 80% を超えないようにします。
SCSI またはファイバー チャネル ハード ドライブの動作を分析する場合は、これまでのセクションで説明した原則に従って分析する必要があります。 各プロトコルにはそれぞれ長所と短所がありますが、ディスク単位でのパフォーマンスを制限する主な要因は、ハード ドライブの機械的な制限です。
ストレージ ユニットのチャネルを分析する場合は、SCSI バスで使用可能なリソースの数を計算する場合と同じアプローチで、帯域幅をブロック サイズで割ります。 たとえば、ストレージ ユニットに 6 つのチャネルがあり、各チャネルが最大 20 MBps の転送速度をサポートしている場合、使用可能な I/O とデータ転送の合計量は 100 MBps になります。 合計が 120 MBps ではなく 100 MBps である理由は、チャネルの 1 つが突然停止し、稼働しているチャネルが 5 つだけになった場合に、ストレージ チャネルの合計スループットが、使用するスループットの量を超えないようにするためです。 もちろん、この例では、すべてのチャネルに負荷とフォールト トレランスが均等に分散されていることも前提になっています。
前の例を I/O プロファイルに変換できるかどうかは、アプリケーションの動作によって異なります。 Active Directory の Jet I/O の場合、最大値は 1 秒あたり約 12,500 回の I/O、つまり 100 MBps ÷ 8) KB (I/O あたり) になります。
コントローラー モジュールでサポートされるスループットを知るには、製造元の仕様も確認する必要があります。 この例では、SAN にはそれぞれ 7,500 I/O をサポートする 2 つのコントローラー モジュールがあります。 冗長構成を使用していない場合、システム全体のスループットは 15,000 IOPS になります。 ただし、冗長構成が必要なシナリオでは、1 台のみのコントローラーの上限 (7,500 IOPS) に基づいて最大スループットを計算します。 ブロック サイズが 4 KB であると仮定すると、このしきい値はストレージ チャネルがサポートできる最大値 12,500 IOPS を大幅に下回るため、この分析でのボトルネックになります。 ただし、プランニングの目的では、計画する必要がある最大 I/O は 10,400 回の I/O です。
データがコントローラー モジュールから送信されると、1 GBps (128 MBps) のファイバー チャネル接続が送信されます。 この量は、すべてのストレージ ユニット チャネルの合計帯域幅 100 MBps を超えるため、システムのボトルネックにはなりません。 また、冗長構成により、この送信は 2 つのファイバー チャネルの一方のみで行われるため、1 つのファイバー チャネル接続が機能しなくなった場合でも、残りの接続にはデータ転送の需要を処理するために十分なキャパシティが残っています。
その後、データは SAN スイッチを経由してサーバーに送信されます。 スイッチは、着信要求を処理して適切なポートに転送する必要があるため、処理できる I/O の量を制限します。 ただし、スイッチに関する制限は、製造元の仕様を確認しないとわかりません。 たとえば、システムに 2 つのスイッチがあり、各スイッチが 10,000 IOPS を処理できる場合、合計スループットは 20,000 IOPS になります。 フォールト トレランスの規則に基づき、1 つのスイッチが動作を停止した場合は、システムの合計スループットが 10,000 IOPS になります。 このため、通常の状況では、80% の使用率 (8,000 I/O) を超えて使用しないでください。
最後に、サーバーに設置した HBA によっても、処理できる I/O の量が制限されます。 通常、冗長性のために 2 つ目の HBA をインストールしますが、SAN スイッチの場合と同様、システムが処理できる I/O の量を計算すると、合計スループットは N - 1 HBA になります。
キャッシュに関する考慮事項
キャッシュは、ストレージ システム内のあらゆる箇所で全体的なパフォーマンスに大きな影響を与えるコンポーネントの 1 つです。 ただし、この記事では、キャッシュ アルゴリズムの詳細な分析についての説明を控えます。 その代わり、ディスク サブシステムのキャッシュについて知っておくべき事項について簡単に説明します。
- キャッシュを使用すると多数の小さな書き込み操作が大きな I/O ブロックにバッファリングされるため、持続的なシーケンシャル書き込み I/O が向上します。 また、多数の小さなブロックではなく、少数の大きなブロック単位で、操作をストレージにデステージします。 この最適化により、ランダム I/O 操作とシーケンシャル I/O 操作の合計回数が減り、他の I/O 操作に使用できるリソースが増えます。
- キャッシングでは、スピンドルがデータをコミットできる状態になるまで書き込みをバッファリングしておくだけなので、ストレージ サブシステムで書き込み I/O スループットが継続的に向上することはありません。 スピンドルからのすべての利用可能な I/O がデータによって長時間飽和状態になると、キャッシュは最終的にいっぱいになります。 キャッシュを空にするには、追加のスピンドルを提供するか、遅れを取り戻せるようにバースト間に十分な時間を確保することで、キャッシュが自然にクリアされるように十分な I/O を提供する必要があります。
- キャッシュが大きいほど、バッファリングできるデータ量が増えるため、より長い期間の飽和状態をキャッシュが処理できるようになります。
- 一般的なストレージ サブシステムでは、システムはデータをキャッシュに書き込むだけでよいため、OS の書き込みパフォーマンスはキャッシュによってが向上します。 ただし、基盤となるメディアが I/O 操作で飽和状態になると、キャッシュがいっぱいになり、書き込みパフォーマンスは通常のディスク速度に戻ります。
- 読み取り I/O をキャッシュする場合、キャッシュを最大限に役立てるには、キャッシュで先読みできるように、データをデスク上に順番に保存します。 先読みとは、次に要求されるデータが次のセクターに含まれていると想定し、キャッシュをすぐに次のセクターに移動できることです。
- 読み取り I/O がランダムである場合、ドライブ コントローラーでキャッシングを使用しても、ディスクで読み取り可能なデータ量は増加しません。 OS またはアプリケーション ベースのキャッシュ サイズがハードウェア ベースのキャッシュ サイズよりも大きい場合、ディスクの読み取り速度を向上させようとしても何も変わりません。
- Active Directory では、キャッシュはシステムに搭載されている RAM の量によってのみ制限されます。
SSD に関する考慮事項
ソリッド ステート ドライブ (SSD) は、スピンドル ベースのハード ディスクとは根本的に異なります。 SSD の方が短い待ち時間で大量の I/O を処理できます。 SSD はギガバイトあたりのコストで見ると高価ですが、I/O あたりのコストで見ると非常に安価です。 ただし、SSD のキャパシティ プランニングでも、スピンドルの場合と同じ点を明らかにする必要があります。つまり、SSD で処理できる IOPS の数と、IOPS の待ち時間はどの程度かという点です。
SSD を計画する際に考慮すべき点を次に示します。
- IOPS と待機時間はどちらも、製造元の設計に依存します。 場合によっては、特定の SSD 設計の方が、スピンドルベースのテクノロジよりもパフォーマンスが低いこともあります。 SSD とスピンドルのどちらを使用するかを決定する場合は、すべてのテクノロジが特定の方法で動作すると想定するのではなく、ドライブごとの製造元の仕様を確認して検証する必要があります。
- IOPS の種類によって、読み取りか書き込みかで値が異なる場合もあります。 AD DS サービスは主に読み取りベースであるため、他のアプリケーション シナリオと比較して、使用する書き込みテクノロジの影響は小さくなります。
- 書き込み耐久性は、SSD セルの寿命が限られており、頻繁に使用すると最終的に摩耗するという前提に基づいています。 データベース ドライブの場合、主に読み取りの I/O プロファイルによってセルの書き込み耐久性が拡張され、書き込み耐久性についてそれほど心配する必要がなくなります。
まとめ
ストレージは、家にある屋内配管のようなものだと想像してみてください。 データを格納するメディアの IOPS は、家の主排水管のようなものです。 主排水管が詰まったり、サイズが制限されたり、パイプが破損したりすると、排水管が逆流し、家庭で大量の水を使用したときに正常に機能しなくなります。 このシナリオは、共有環境に、同じ基盤メディアを持つ同じ SAN、NAS、または iSCSI 上の共有ストレージを使用するシステムが 1 つ以上ある場合と似ています。 ユーザーの需要がシステムの対応能力を超えると、パフォーマンスが低下します。
同様に、この架空の配管のシナリオでは、詰まりやその他のパフォーマンスの問題を解決するためにさまざまなアプローチを取ることができます。
- 排水管が破損していたり、排水口が小さすぎたりする場合は、パイプを正常に機能する適切なサイズのものに交換する必要があります。 共有ストレージで言えば、新しいハードウェアを追加したり、インフラストラクチャ全体の共有システムの使用を再配分したりするようなものです。
- 排水管の詰まりを解消するには、根本的な問題とその場所を特定し、適切な道具を使って詰まりを取り除く必要があります。 たとえば、キッチン シンクの排水管の比較的単純な詰まりは、プランジャーまたは排水管クリーナーで取り除くだけで済みますが、物が詰まっている複雑な詰まりには、専用のツールが必要になる場合があります。 同様に、共有ストレージ システムでも、パフォーマンスの問題の原因を特定することにより、システム レベルのバックアップを作成する必要があるか、すべてのサーバー間でウイルス対策スキャンを同期する必要があるか、ピーク時に実行するデフラグ ソフトウェアを同期する必要があるかを判断できます。
ほとんどの配管設計では、複数の排水管から接続している主排水管に排水されます。 排水口が詰まると、詰まりが発生した箇所の背後の部分のみに水が溜まります。 接合部が詰まると、その接合部の背後にあるすべての排水口から水が流れなくなります。 ストレージのシナリオでは、接合部が詰まる状況は、スイッチの過負荷、ドライバーの互換性の問題、またはソフトウェア タスクの同期が取れていない状態と似ています。 IOPS と I/O サイズを測定して、ストレージ システムが負荷を処理できるかどうかを判断し、必要に応じてシステムを調整する必要があります。
付録 D: RAM を追加できない環境でのストレージのトラブルシューティング
仮想化ストレージ以前には、ストレージ推奨事項の多くは、次の 2 つの目的に沿っていました。
- I/O を分離して、OS スピンドルのパフォーマンスの問題がデータベースと I/O プロファイルのパフォーマンスに影響しないようにする。
- AD DS ログ ファイルのシーケンシャル I/O と組み合わせることで、スピンドル ベースのハード ドライブとキャッシュにより、システムのパフォーマンスを向上させる。 シーケンシャル I/O を別の物理ドライブに分離すると、スループットも向上します。
新しいストレージ オプションでは、以前のストレージ推奨事項の背後にある多くの基本的な前提が当てはまらなくなりました。 iSCSI、SAN、NAS、仮想ディスク イメージ ファイルなどの仮想化ストレージ シナリオでは、多くの場合、基になる記憶域メディアが複数のホスト間で共有されます。 この違いにより、I/O を分離してシーケンシャル I/O を最適化する必要があるという前提が否定されます。 他のホストが共有メディアにアクセスする場合は、ドメイン コントローラーへの応答性が低下する可能性があります。
ストレージ パフォーマンスのキャパシティ プランを作成する際には、以下の 3 点を考慮する必要があります。
- コールド キャッシュ状態
- ウォーム キャッシュ状態
- バックアップと復元
コールド キャッシュ状態は、ドメイン コントローラーを最初に再起動するか、Active Directory サービスを再起動したときの状態であり、このとき RAM には Active Directory データが存在しません。 ウォーム キャッシュ状態は、ドメイン コントローラーが安定した状態で動作し、データベースをキャッシュしている状態です。 パフォーマンス設計の観点では、コールド キャッシュのウォーミングは短距離走に似ていますが、完全にウォーミングされたキャッシュでのサーバー稼働はマラソンのようなものです。 これらの状態と、それらがもたらすさまざまなパフォーマンス プロファイルを定義することは重要です。キャパシティを見積もる際には、これらをどちらも考慮する必要があるためです。 たとえば、ウォーム キャッシュ状態中にデータベース全体をキャッシュするために十分な RAM があっても、コールド キャッシュ状態中のパフォーマンスを最適化するのに役立つわけではありません。
どちらのキャッシュ シナリオでも、最も重要なのは、ストレージがディスクからメモリにデータをどれだけ速く移動できるかです。 キャッシュをウォームアップすると、クエリによってデータが再利用され、キャッシュ ヒット率が上がり、ディスクにアクセスしてデータを取得する頻度が減少するため、経時的にはパフォーマンスが向上します。 その結果、ディスクへのアクセスによる、パフォーマンスへのマイナス影響も緩和されます。 パフォーマンスの低下は一時的なもので、キャッシュがウォーム状態になり、システムで許容される最大サイズに達すると通常は解消されます。
Active Directory で使用可能な IOPS を測定すると、システムがディスクからデータを取得できる速度を測定できます。 使用可能な IOPS の値は、基盤となるストレージで使用可能な IOPS の値よっても左右されます。 プランニングの観点からは、キャッシュのウォーミングやバックアップ/復元状態は通常、ピーク時間外に発生する例外的なイベントであり、DC 負荷の影響を受けるため、一般的な推奨事項を提供することはできません。ただしこれらの状態に入るのは、オフピーク時のみに限定してください。
ほとんどのシナリオでは、AD DS では読み取り I/O が主であり、読み取りが 90%、書き込みが 10% の比率になります。 読み取り I/O はユーザー エクスペリエンスの一般的なボトルネックであり、書き込み I/O は書き込みパフォーマンスを低下させるボトルネックです。 NTDS.dit ファイルの I/O 操作は主にランダムであるため、キャッシュを使用しても、読み取り I/O でのメリットはほとんどありません。 このため、読み取り I/O プロファイル ストレージを正しく構成することが最優先事項になります。
通常の運用条件下におけるストレージ プランニングの目標は、システムがAD DSからディスクに要求を返すまでの待ち時間を最小限に抑えることです。 未処理および保留中の I/O 操作の数は、ディスク内のパスの数以下にする必要があります。 パフォーマンス監視のシナリオでは通常、LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read カウンターを 20 ミリ秒未満にすることをお勧めします。 動作しきい値は、ストレージの種類に応じて 2 ~ 6 ミリ秒の範囲内で、できるだけストレージの速度に近く低い値に設定する必要があります。
下の折れ線グラフは、ストレージ システム内のディスク待機時間の測定を示しています。
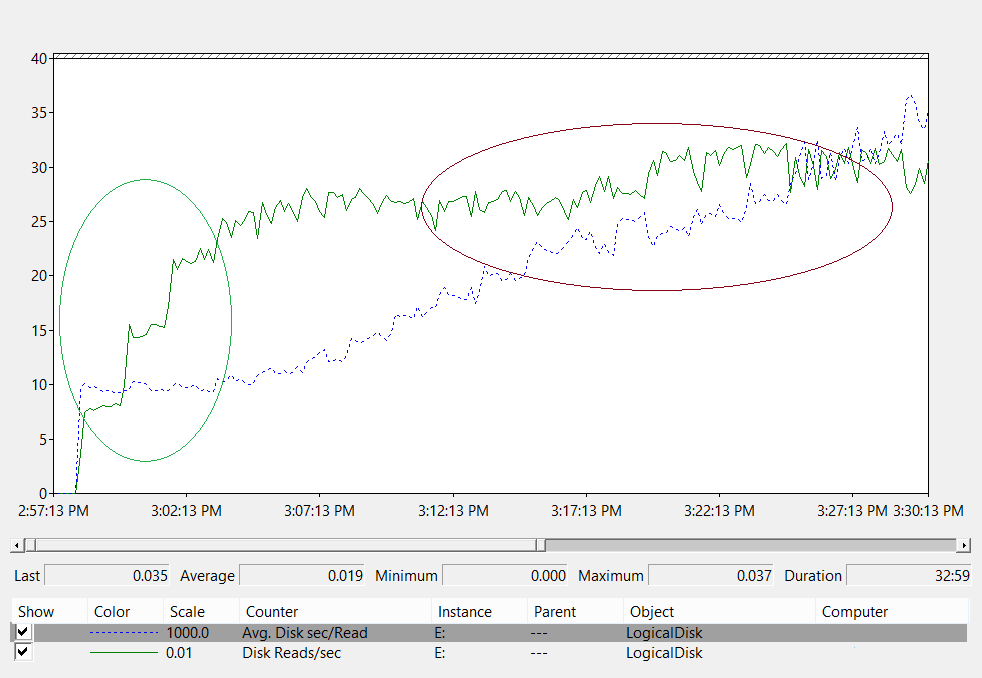
この折れ線グラフを分析してみましょう。
- グラフの左側にある緑色の円で囲まれた領域は、負荷が 800 IOPS から 2,400 IOPS に増加しても、待機時間が 10 ミリ秒で一定であることを示しています。 この領域は、基になるストレージが I/O 要求を処理できる速度のベースラインです。 ただし、このベースラインは、使用するストレージ ソリューションの種類によって影響を受けます。
- グラフの右側にある茶色で囲まれた領域は、ベースラインとデータ収集の終了との間のシステム スループットを示しています。 スループット自体は変わりませんが、待機時間が長くなります。 この領域は、要求ボリュームが基になるストレージの物理的な制限を超えると、要求がストレージ サブシステムに送信されるのをキューで待機する時間が長くなることを示しています。
では、このデータから何がわかるか考えてみましょう。
まず、ユーザーによる大規模なグループのメンバーシップ照会により、システムがディスクから 1 MB のデータを読み取る必要があるとします。 次の値を使用して、必要な I/O の量と操作にかかる時間を評価できます。
- 各 Active Directory データベース ページのサイズは 8 KB です。
- システムが読み取る必要のあるページの最小数は 128 です。
- したがって、図のベースライン領域では、システムがディスクからデータを読み込んでクライアントに返すには、少なくとも 1.28 秒かかります。 スループットが推奨最大値を大幅に上回る 20 ミリ秒の時点では、プロセスに 2.5 秒かかります。
これらの数値に基づき、次の式を使用して、キャッシュのウォームアップ速度を計算できます。
2,400 IOPS × 8 KB (I/O あたり)
この計算を実行すると、このシナリオでのキャッシュ ウォームアップ レートは 20 MBps であることがわかります。 つまり、システムは 53 秒ごとに約 1 GB のデータベースを RAM に読み込んでいるということです。
Note
コンポーネントがディスクの読み取りや書き込みを積極的に行っている間、待機時間が一時的に増加するのは正常です。 たとえば、システムでのバックアップや AD DS によるガベージ コレクションの実行中は、待機時間が長くなります。 元の使用量の見積もりに加えて、これらの定期的なイベント用に余裕を持たせる必要があります。 目標は、全体的な機能に影響を与えずに、これらのスパイクに対応できる十分なスループットを提供することです。
ストレージ システムの設計方法により、キャッシュのウォームアップ速度には物理的な制限があります。 基になるストレージが対応できる速度までキャッシュをウォームアップできるのは、受信クライアント要求だけです。 ピーク時にキャッシュを事前にウォームアップするスクリプトを実行すると、実際のクライアント要求と競合して全体的な負荷が増加し、クライアント要求に関係のないデータが読み込まれて、パフォーマンスが低下します。 キャッシュのウォームアップには、人為的な手段を使用しないことをお勧めします。