CPU の分析
このガイドでは、評価メトリックに影響を与える中央処理ユニット (CPU) 関連の問題を調査するために使用できる詳細な手法について説明します。
評価固有の分析ガイドの個々のメトリックまたは問題のセクションでは、調査に関する一般的な問題を特定します。 このガイドでは、これらの問題を調査するために使用できる手法とツールを提供します。
このガイドの手法では、パフォーマンス Windows パフォーマンス アナライザー (WPT) のWindows (WPA) Toolkit使用します。 WPTはWindows Assessment and Deployment Kit (Windows ADK)の一部であり、Windows Insider Programからダウンロードすることができます。 詳細については、「Windows Performance Toolkit テクニカル リファレンス」を参照してください。
このガイドは、次の3つのセクションで構成されています。
このセクションでは、Windows 10 での CPU リソースの管理方法について説明します。 |
|
このセクションでは、Windows ADK Toolkit で CPU 情報を表示し、解釈する方法について説明します。 |
|
ここでは、CPU のパフォーマンスに関連する一般的な問題を調査して解決するために使用できる数々の手法について説明します。 |
背景
ここでは、簡単な説明と、CPU パフォーマンスに関する基本的な説明を示します。 このトピックの包括的な調査については、Windows 内部の5番目のエディションをお勧めします。
最新のコンピューターには、複数のCPUが別々のソケットに搭載されていることがあります。 各 CPU は、1つまたは2つの個別の命令ストリームを同時に処理できる、複数の物理プロセッサコアをホストできます。 これらの個々の命令ストリームプロセッサは、Windows オペレーティングシステムによって論理プロセッサとして管理されます。
このガイドでは、プロセッサと CPU の両方が、プログラムの命令を実行するためにオペレーティングシステムが使用できる論理プロセッサ (つまり、ハードウェアデバイス) を参照します。
Windows 10 は、電力消費とパフォーマンスのバランスを取る電源管理、およびプログラムとドライバーの処理要件のバランスを取るCPU 別 CPU 使用率(正確)という、主に2つの方法でプロセッサのハードウェアをアクティブに管理します。
プロセッサの電源管理
プロセッサは、常に動作状態にあるわけではありません。 命令を実行する準備ができていない場合、Windows は、Windows 電源マネージャーによって決定されたように、プロセッサをターゲットアイドル状態 (または C 状態) にします。 CPU 使用率パターンに基づいて、プロセッサのターゲット C 状態は時間の経過と共に調整されます。
アイドル状態とは、C0(アクティブ;アイドルではない)から、徐々に消費電力の低い状態へと番号がついた状態です。 これらの状態には、C1 (停止しているがクロックが有効になっている)、C2 (停止してクロックが無効) などが含まれます。 アイドル状態の実装は、プロセッサに依存します。 ただし、すべてのプロセッサの状態番号が高いほど、消費電力は低くなりますが、プロセッサが命令処理に戻るまでの待機時間も長くなります。 アイドル状態で費やされた時間は、エネルギーの使用とバッテリの寿命に大きく影響します。
プロセッサの中には、アクティブに命令を処理しているときでも、パフォーマンス(P)とスロットル(T)の状態で動作できるものがあります。 P-状態は、プロセッサがサポートするクロック周波数と電圧レベルを定義します。 T-状態はクロック周波数を直接変化させませんが、クロックティック数の何割かで処理活動をスキップすることで、実効的なクロック速度を低下させることができます。 現在のP と T の状態によって、プロセッサの実効動作周波数が決まります。 低周波数は、パフォーマンスの低下と消費電力の低下に対応します。
Windows 電源マネージャーは、CPUの使用状況パターンとシステム電源ポリシーに基づいて、各プロセッサに対して適切な P と T の状態を決定します。 高パフォーマンス状態や低パフォーマンス状態で費やされた時間は、エネルギー使用量とバッテリ寿命に大きく影響します。
プロセッサ使用の管理
Windows は、3つの主要な抽象化を使用してプロセッサの使用状況を管理します。
処理
スレッド
遅延プロシージャ呼び出し (DPC) と割り込みサービスルーチン (ISR)
プロセスとスレッド
Windows のすべてのユーザーモードプログラムは、プロセスのコンテキストで実行されます。 プロセスには、次の属性とコンポーネントが含まれます。
仮想アドレス空間
優先度クラス:
読み込まれたプログラムモジュール
環境と構成に関する情報
少なくとも1つのスレッド
プロセスにはプログラムモジュール、コンテキスト、および環境が含まれていますが、プロセッサ上で実行するように直接スケジュールされていません。 代わりに、プロセスによって所有されているスレッドは、プロセッサ上で実行されるようにスケジュールされます。
スレッドは、実行コンテキスト情報を保持します。 ほとんどすべての計算は、スレッドの一部として管理されます。 スレッドアクティビティは、根本的に測定とシステムのパフォーマンスに影響を及ぼします。
システムのプロセッサ数が制限されているため、すべてのスレッドを同時に実行することはできません。 Windows はプロセッサのタイムシェアリングを実装します。これにより、プロセッサが別のスレッドに切り替える前に一定期間、スレッドを実行できます。 スレッド間の切り替えの動作はコンテキストスイッチと呼ばれ、ディスパッチャーと呼ばれるWindowsコンポーネントによって実行されます。 ディスパッチャーは、 優先度、 最適なプロセッサとアフィニティ、 クォンタム、および 状態に基づいて、スレッドのスケジューリングの決定を行います。
優先順位
優先度は、ディスパッチャーが実行するスレッドをいかに選択するかを決める重要な要素です。 スレッドの優先度は 0 から 31 までの整数です。 スレッドが実行可能で、現在実行中のスレッドよりも高い優先度を持つ場合、低い優先度のスレッドは直ちに割り込まれ、高い優先度のスレッドのコンテキストが切り替わります。
スレッドが実行中または実行可能な状態であるとき、両方のスレッドを同時に実行できるだけのプロセッサがあるか、または優先度の高いスレッドが利用可能なプロセッサのサブセットのみで実行されるように制限されている場合を除き、優先度の低いスレッドを実行することはできません。 スレッドには基本的な優先度があり、例えば、プロセスがフォアグラウンドウィンドウを所有するときや、I/O が完了したときなど、特定のタイミングで一時的に高い優先度に昇格させることができます。
理想的なプロセッサとアフィニティ
スレッドの理想的なプロセッサとアフィニティは、与えられたスレッドが実行されるようにスケジュールされるプロセッサを決定します。 各スレッドには、プログラムまたはWindowsによって自動的に設定される理想的なプロセッサがあります。 Windowsは ラウンドロビン方式を使用しており、各プロセスのほぼ同数のスレッドが各プロセッサに割り当てられます。 可能な限り、Windowsは スレッドをその理想的なプロセッサ上で実行するようにスケジュールしますが、スレッドが他のプロセッサ上で実行されることもあります。
スレッドのプロセッサアフィニティは、スレッドが実行されるプロセッサを制限します。 これは、スレッドの理想的なプロセッサの属性よりも強く制限します。 プログラムは SetThreadAffinityMask を使用してアフィニティを設定します。 アフィニティは、スレッドが特定のプロセッサ上で実行されることを防ぐことができます。
Quantum
コンテキストの切り替えは負荷の高い操作です。 Windows は一般的に、各スレッドが他のスレッドに切り替わる前に quantum と呼ばれる期間実行することを許可します。 Quantum 持続時間はシステムの応答性を維持するように設計されています。 コンテキストスイッチのオーバーヘッドを最小にすることで、スループットを最大化します。 Quantum 持続時間は、クライアントとサーバーの間で異なる場合があります。 サーバーでは、応答性を犠牲にしてスループットを最大化するため、通常、Quantum 持続時間は長くなります。 クライアントコンピューターでは、Windows は全体的に短い Quantum 値を割り当てますが、現在のフォアグラウンドウィンドウに関連するスレッドに長い Quantum 値を提供します。
都道府県
各スレッドは、特定の時点で特定の実行状態に存在します。 Windowsでは、パフォーマンスに関連するRunning、Ready、Waitingの3つの状態を使用します。
現在実行中のスレッドはRunning状態になっています。 実行可能でも、現在実行されていないスレッドは、Ready状態です。 特定のイベントを待っているために実行できないスレッドは、Waiting 状態です。
状態から状態への遷移を図1スレッド状態遷移に示します。
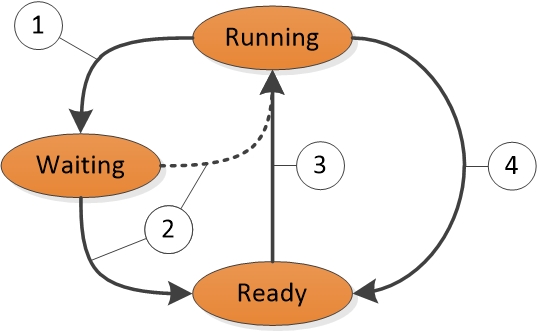
図1 スレッド状態の遷移
図 1 スレッド状態の遷移を以下に説明します。
Running 状態のスレッドは WaitForSingleObject や Sleep(> 0) などの待機関数を呼び出して Waiting 状態への遷移を開始します。
実行中のスレッドやカーネル操作がWaiting状態のスレッドを準備する(例えば、SetEventやタイマーの満了など)。 プロセッサがアイドル中の場合、または準備を完了したスレッドが現在実行中のスレッドよりも高い優先度を持っている場合、準備を完了したスレッドは実行状態に直接切り替えることができます。 そうでない場合は、Ready (準備完了) 状態になります。
Ready (準備完了) 状態のスレッドは、実行中のスレッドが待機するか、(Sleep(0)) をイールドするか、またはそのクォンタムの終わりに達すると、ディスパッチャーによって処理するためにスケジュールされます。
実行状態のスレッドは、より高い優先度のスレッドによって割り込まれたとき、(Sleep(0)) になったとき、またはそのQuantum が終了したとき、ディスパッチャーによって Ready 状態に切り替わります。
Waiting 状態にあるスレッドは、必ずしもパフォーマンス上の問題を示しているわけではありません。 ほとんどのスレッドは待機状態でかなりの時間を費やし、プロセッサはアイドル状態に入り、エネルギーを節約できます。 スレッドの状態は、ユーザーがスレッドが操作を完了するのを待機している場合にのみ、パフォーマンスの重要な要因になります。
DPC と ISR
プロセッサは、スレッドの処理に加えて、ネットワークカードやタイマーなどのハードウェアデバイスからの通知に応答します。 ハードウェアデバイスでプロセッサの注意が必要な場合は、 割り込みが生成されます。 Windows は現在実行中のスレッドを一時停止し、割り込みに関連する ISR を実行することで、ハードウェア割り込みに応答します。
ISRを実行している間、プロセッサは他の割り込みを含む他のアクティビティを処理することを妨げられる可能性があります。 このため、ISR は迅速に完了しなければならず、そうしないとシステム性能が低下します。 実行時間を短縮するために、ISR は、割り込みに応答して実行する必要がある処理を実行するように DPC を設定するのが一般的です。 論理プロセッサごとに、Windowsは スケジュールされた DPC の待ち行列を維持します。 DPC は、どのような優先度のレベルでもスレッドより優先されます。 プロセッサがスレッドの処理に戻る前に、そのキューにあるすべての DPC を実行します。
プロセッサが DPC とISR を実行している間、そのプロセッサ上でスレッドを実行することはできません。 この特性は、オーディオやビデオを再生するスレッドなど、一定のスループットや正確なタイミングで作業を実行しなければならないスレッドに問題を起こす可能性があります。 Dpc と Isr の実行に使用されるプロセッサ時間によって、これらのスレッドが十分な処理時間を受信できない場合、スレッドは必要なスループットを達成できないか、または作業項目を時間どおりに完了できない可能性があります。
Windows ADK ツール
Windows ADK は、ハードウェア情報と評価を評価結果ファイルに書き込みます。 WPA は CPU 使用率の詳細な情報を様々なグラフで提供します。 ここでは、Windows ADKとWPAを使用して、CPU のパフォーマンスデータを収集、表示、分析する方法を説明します。
ADK 評価結果ファイルの Windows
Windows は対称型マルチプロセッシングシステムのみをサポートしているため、このセクションの情報はすべて、インストールされているすべての CPU とコアに適用されます。
CPU ハードウェアの詳細情報は、 EcoSysInfo ノードの評価結果ファイルのセクションにあり <Processor><Instance id=”0”> ます。
次に例を示します。
<Processor>
<Instance id="0">
<ProcessorName>The name of the first CPU</ProcessorName>
<TSCFrequency>The maximum frequency of the first CPU</TSCFrequency>
<NumProcs>The total number of processors</NumProcs>
<NumCores>The total number of cores</NumCores>
<NumCPUs>The total number of logical processors</NumCPUs>
...and so on...
WPAグラフ
WPA にトレースを読み込むと、WPA UI の [トレース]、[システムの構成]、 [全般 ]、[ トレース/システムの構成 ]、[PnP] の各セクションで、プロセッサのハードウェア情報を確認できます。
ノート このガイドのすべての手順は、WPA で発生します。
CPU アイドル状態グラフ
アイドル状態の情報がトレースに収集されると、[ 電力/CPU アイドル状態 ] グラフが WPA UI に表示されます。 このグラフには、各プロセッサのTargetアイドル状態に関するデータが常に含まれています。 この状態がプロセッサによってサポートされている場合、グラフには各プロセッサの 実際 のアイドル状態に関する情報も含まれます。
以下の表の各行には、プロセッサの Target または Actual 状態のいずれかのアイドル状態の変化が記述されています。 グラフの各行には、以下のカラムが用意されています。
| 列 | 詳細 |
|---|---|
CPU |
状態変更の影響を受けるプロセッサ。 |
エントリ時刻 |
プロセッサがアイドル状態になった時刻。 |
終了時刻 |
プロセッサがアイドル状態になった時刻。 |
最長期間 (ミリ秒) |
アイドル状態 (既定の集計: 最大) で費やされた時間。 |
最小期間 (ミリ秒) |
アイドル状態 (既定の集計: 最大) で費やされた時間。 |
次の状態 |
現在の状態の後にプロセッサが遷移した状態。 |
前の状態 |
現在の状態の前にプロセッサが遷移した状態です。 |
都道府県 |
現在のアイドル状態。 |
状態 (数値) |
数値としての現在のアイドル状態 (たとえば、C0 の場合は 0)。 |
Sum:継続時間(ms) |
アイドル状態にある時間 (既定の集計:sum)。 |
テーブル |
未使用 |
Type |
Target(電源マネージャーが選択したプロセッサのターゲット状態)またはActual(プロセッサの実際のアイドル状態)のいずれかを指定します。 |
デフォルトのWPAプロフィールでは、このグラフに2つのプリセットが用意されています。タイプ別状態、CPUおよびタイプ別状態、CPUです。
種類別の状態、CPU
State by Type, CPUのグラフでは、各CPUのTargetとActualの状態がY軸の状態番号と共にグラフ化されます。 図2 CPU Idle States State by Type, CPU は、Active と Target のアイドル状態の間を行き来する CPU の Actual 状態を表しています。
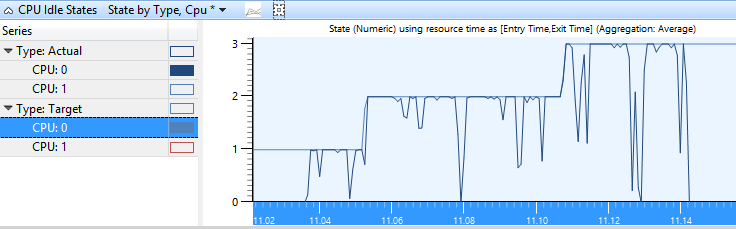
図2 種類別の CPU アイドル状態の状態、CPU
種類別の状態図、CPU
このグラフでは、各 CPU のターゲット状態と実際の状態がタイムライン形式で示されます。 各状態には、タイムラインに個別の行があります。 図3種類別の CPU アイドル状態の状態ダイアグラムでは、タイムラインビューの cpu アイドル状態の種類別の cpu アイドル状態の状態と同じデータが CPU に表示されます。
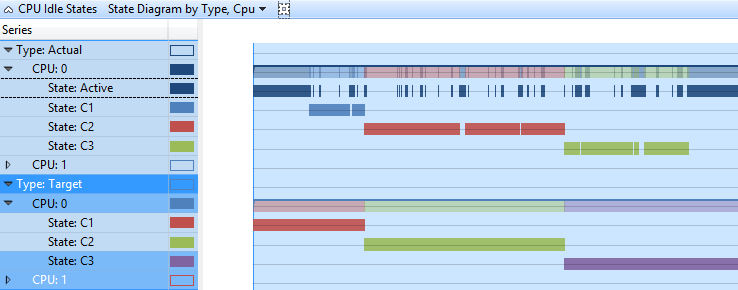
図 3 CPU アイドル状態の種類別状態図、CPU
CPU周波数グラフ
複数の P または T 状態をサポートするシステムで CPU 周波数データが収集された場合、 CPU 周波数 グラフは WPA UI で使用できるようになります。 次の表の各行は、プロセッサの特定の頻度レベルでの時刻を表しています。 周波数(MHz) 列には、プロセッサがサポートする P ステートと T ステートに対応する限られた数の周波数が含まれています。 グラフの各行には、以下のカラムが用意されています。
| 列 | 詳細 |
|---|---|
% 持続時間 |
持続時間は、現在表示されている期間の総 CPU 時間に対する割合で表示されます。 |
カウント |
頻度が変化する回数 (個々の行に対して常に 1)。 |
CPU |
周波数の変化の影響を受ける CPU。 |
エントリ時刻 |
CPU が P 状態になった時刻。 |
終了時刻 |
CPU が P 状態を終了した時刻。 |
周波数 (MHz) |
P 状態にある時間内の CPU の頻度です。 |
最長期間 (ミリ秒) |
P 状態 (既定の集計: 最大) で費やされた時間。 |
最小期間 (ミリ秒) |
P 状態 (既定の集計: 最小) で費やされた時間。 |
Sum:継続時間(ms) |
P 状態 (既定の集計: sum) で費やされた時間。 |
テーブル |
未使用 |
Type |
P 状態のその他の情報 |
デフォルトのプロフィールでは、このグラフのFrequency by CPUプリセットを定義しています。 図 4 CPU による CPU 周波数は、次の3つの状態間の遷移時に CPU を示します。

図4 CPU別CPU周波数
CPU 使用率(サンプリング)グラフ
CPU 使用率(サンプリング) グラフに表示されるデータは、定期的なサンプリング間隔で取得される CPU アクティビティのサンプルです。 ほとんどのトレースでは、これは1ミリ秒 (1 ミリ秒) です。 テーブルの各行は 1 つのサンプルを表します。
このサンプルの重みは、他のサンプルと比較して、そのサンプルの有意性を表します。 重みは、現在のサンプルのタイムスタンプから前のサンプルのタイムスタンプに等しくなります。 システムの状態やアクティビティの変動により、重みは必ずしもサンプリング間隔と同じではありません。
図 5 CPU サンプリングは、データの収集方法を表します。
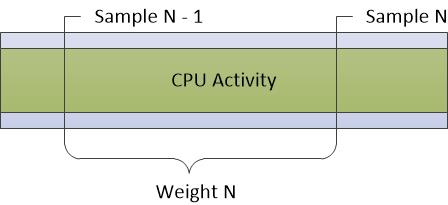
図 5 CPU サンプリング。
このサンプリング方法では、サンプル間に発生した CPU のアクティビティは記録されません。 そのため、DPC や ISR などの非常に短い期間のアクティビティは、CPU サンプリンググラフではあまり表現されません。
グラフの各行には、以下のカラムが用意されています。
| 列 | 詳細 |
|---|---|
% 重み |
重みは、現在表示されている時間範囲に対して費やされた総 CPU 時間に対する割合として表されます。 |
番地 |
スタックの一番上にある関数のメモリアドレス。 |
全カウント |
1行で表現されるサンプルの数。 この数には、プロセッサがアイドルのときに取得されたサンプルも含まれます。 個々の行の場合、この列は常に1です。 |
カウント |
プロセッサがアイドル状態のときに取得されたサンプルを除く、行で表されるサンプルの数です。 個々の行については、この列は常に 1 (CPU が低電力状態であった場合は 0) になります。 |
CPU |
このサンプルが取得された CPU の0から始まるインデックス。 |
表示名 |
アクティブなプロセスの表示名。 |
DPC/ISR |
このサンプルでは、通常の CPU 使用率、DPC/ISR、低電力状態のいずれを測定したか。 |
機能 |
スタックの一番上にある関数。 |
モジュール |
スタックの一番上にある関数を含むモジュール。 |
優先順位 |
実行中のスレッドの優先度。 |
プロセス |
実行中のコードを所有するプロセスのイメージ名。 |
プロセス名 |
実行中のコードを所有するプロセスのフルネーム(プロセスIDを含む)。 |
Stack |
実行中のスレッドのスタック。 |
スレッド ID |
実行中のスレッドのID。 |
スレッド開始関数 |
実行中のスレッドが開始された関数。 |
スレッド開始モジュール |
スレッドの開始関数を含むモジュール。 |
タイムスタンプ |
サンプルが撮影された時間。 |
体重 |
サンプルで表現される時間(ミリ秒単位)(つまり、最後のサンプルからの時間)。 |
デフォルトのプロフィールでは、このグラフに以下のプリセットが用意されています。
CPU 別の使用率
優先度別使用率
プロセス別使用率
Utilization by Process and Thread (プロセスとスレッド別の使用率)
CPU 別の使用率
CPU 別 CPU 使用率のグラフは、プロセッサ間でどのように仕事が分配されるかを示しています。 図 6 CPU 別 CPU 使用率グラフはこの分布を 2CPU 分布で示したものです。
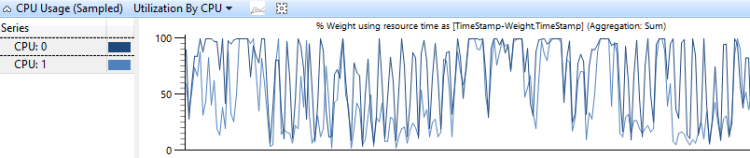
図 6 CPU 別 CPU 使用率
優先度別使用率
CPU 使用率はスレッドの優先順位によってグループ化され、優先順位の高いスレッドが優先順位の低いスレッドにどのような影響を与えるかを示します。 図 7 CPU使用率(サンプリング) 優先度別使用率では、このようなグラフが表示されます。
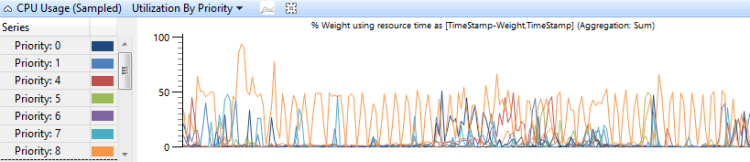
図 7 CPU 使用率(サンプリング) 優先度別使用率
プロセス別使用率
CPU 使用率はプロセス別にグループ化されており、プロセスの相対的な使用状況を示します。 図 8 CPU 使用率(サンプリング)プロセス別使用率は、このプリセットを示します。 このサンプルグラフでは、1つのプロセスが、他のプロセスよりも多くの CPU 時間を消費していることが示されています。
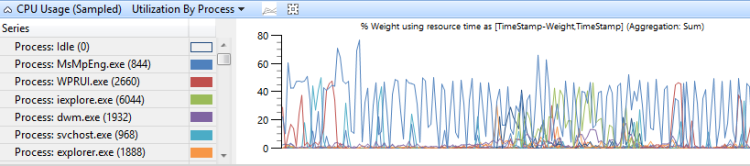
図 8 CPU 使用率(サンプリング)プロセス別使用率
Utilization by Process and Thread (プロセスとスレッド別の使用率)
CPU 使用率はプロセスごとにグループ化され、さらにスレッドごとにグループ化されたもので、プロセスと各プロセスのスレッドの相対的な使用率を示します。 図 9 CPU 使用率(サンプル) プロセスおよびスレッド別使用率は、このプリセットを示します。 このグラフでは、1つのプロセスのスレッドが選択されています。
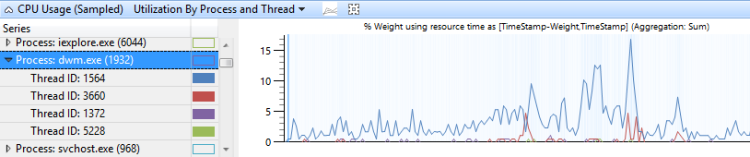
図 9 CPU 使用率(サンプル) プロセスおよびスレッド別使用率
CPU 使用率(正確)グラフ
CPU 使用率(正確) グラフは、コンテキストスイッチのイベントに関連する情報が記録されます。 各行は、1 回のコンテキスト スイッチに関連するデータ セットを表します。 データは、以下のイベントシーケンスについて収集されます。
新しいスレッドが切り替わります。
新しいスレッドは、準備中のスレッドによって実行可能な状態にされます。
新しいスレッドが投入され、それによって古いスレッドが切り替わります。
新しいスレッドが再び切り替わります。
図 10 CPU 使用率の正確な図では、時間フローは左から右です。 図のラベルはCPU 使用率(正確) グラフの列名と対応しています。 Timestampカラムのラベルは図の上部に表示され、Interval Durationカラムのラベルは図の下部に表示されます。
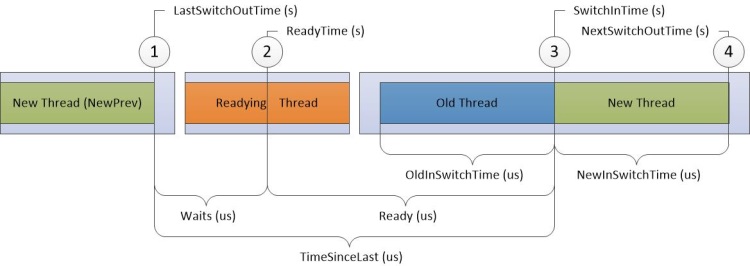
図 10 CPU 使用率の正確な図
図 10 CPU 使用率の正確な図のタイムラインでの中断は、タイムラインを異なる Cpu で同時に発生する可能性があるリージョンに分割します。 これらのタイムラインは、番号付けされたイベントの順序が変更されない限り、重なり合うことができます。 たとえば、準備中のスレッドは、プロセッサ-2上で新しいスレッドが切り替わり、プロセッサ-1上に戻ってくるのと同時に実行することができます)。
情報は、タイムライン上の以下の4つの対象について記録されます。
New thread (新しいスレッド)は、入れ替わったスレッドです。 これは、グラフのこの行の主な焦点です。
NewPrev thread:新しいスレッドが切り替わった前回の時刻を指します。
準備スレッド: 新しいスレッドが処理されるように準備したスレッドです。
古いスレッド: 新しいスレッドが投入された時に切り替わったスレッドです。
次の表のデータは、各ターゲットスレッドに関連しています。
| 列 | 詳細 |
|---|---|
% CPU Usage |
切り替えられた後の新しいスレッドの CPU 使用率。 この値は、現在表示されている期間の総 CPU 時間に対する割合で表示されます。 |
カウント |
行で表されるコンテキスト スイッチの数。 これは、個々の行に対して常に 1 です。 |
回数:待ち時間 |
行で表現される待ちの数。 スレッドがアイドル状態に移行した場合を除き、個々の行では常に 1 になります。 |
CPU |
コンテキストスイッチが発生した CPU。 |
CPU Usage (ms) |
コンテキストの切り替え後の新しいスレッドの CPU 使用率。 これはNewInSwitchTimeと同じですが、ミリ秒単位で表示されます。 |
理想的な CPU |
新しいスレッドに対してスケジューラによって選択された理想的な CPU。 |
最後のスイッチアウト時間(秒) |
新しいスレッドが切り替わった前回の時間。 |
NewInPri |
スイッチングされた新しいスレッドの優先度。 |
NewInSwitchTime(s) |
NextSwitchOutTime(s) minus SwitchInTime(s) |
NewOutPri |
新しいスレッドがスイッチアウトするときの優先度。 |
NewPrevOutPri |
新しいスレッドが以前スイッチアウトしたときの優先度。 |
NewPrevState |
新しいスレッドが以前にスイッチアウトした後の状態。 |
NewPrevWaitMode |
新しいスレッドが以前スイッチアウトされたときの待機モード。 |
NewPrevWaitReason |
新しいスレッドが切り替わった理由。 |
NewPriDecr |
スレッドに影響を与える優先度ブースト。 |
NewProcess |
新しいスレッドのプロセス。 |
新しいプロセスの名前 |
新しいスレッドのプロセス名(PIDを含む)。 |
NewQnt |
未使用。 |
NewState |
新しいスレッドが切り替わった後の状態。 |
NewThreadId |
新しいスレッドのスレッド ID。 |
NewThreadStack |
新しいスレッドに切り替わったときのスタック。 |
NewThreadStartFunction |
新しいスレッドの開始関数。 |
NewThreadStartModule |
新しいスレッドの開始モジュール。 |
NewWaitMode |
新しいスレッドの待機モード。 |
NewWaitReason |
新しいスレッドが切り替わった理由。 |
NextSwitchOutTime(s) |
新しいスレッドが次に切り替わった時間。 |
OldInSwitchTime(s) |
古いスレッドが切り替わる前に入れ替わった時間。 |
OldOutPri |
切り替えられたときの古いスレッドの優先度。 |
OldProcess |
古いスレッドを所有するプロセス。 |
OldProcess 名 |
古いスレッドを所有するプロセスの名前(PID を含む)。 |
OldQnt |
未使用。 |
OldState |
古いスレッドが切り替わった後の状態。 |
OldThreadId |
古いスレッドのスレッド ID。 |
OldThreadStartFunction |
古いスレッドの開始関数。 |
OldThreadStartModule |
古いスレッドの開始モジュール。 |
OldWaitMode |
古いスレッドの待機モード。 |
OldWaitReason |
古いスレッドが切り替わった理由。 |
PrevCState |
プロセッサの以前の CState。 これが0(アクティブ)でない場合、新しいスレッドがコンテキストスイッチされる前にプロセッサがアイドル状態であったことを示します。 |
Ready(s) |
SwitchInTime(s) minusReadyTime |
Readying ThreadId |
準備スレッドのスレッド ID。 |
ThreadStartFunction の準備 |
準備スレッドの開始関数。 |
Readying ThreadStartModule の準備 |
準備スレッドの開始モジュール。 |
ReadyingProcess |
準備スレッドを所有するプロセス。 |
ReadyingProcess 名 |
準備スレッドを所有するプロセスの名前(PIDを含む)。 |
ReadyThreadStack |
準備スレッドのスタック。 |
ReadyTime (s) |
新しいスレッドがレディされた時刻。 |
SwitchInTime(s) |
新しいスレッドがスイッチインされた時間。 |
TimeSinceLast |
SwitchInTime から LastSwitchOutTime を引いた値 |
Waits (s) |
ReadyTime - LastSwitchOutTime |
デフォルトのプロフィールでは、このグラフに以下のプリセットが使用されます。
CPU 別タイムライン
プロセス、スレッド別タイムライン
Usage by Priority at Context Switch Begin (コンテキスト切り替え開始時点の優先度別の使用率)
CPU 別の使用率
プロセス、スレッド別使用率
CPU 別タイムライン
CPU 使用率は CPU 毎のタイムラインで、プロセッサ間の作業分担を示します。 図 11 CPU 別 CPU 使用率(正確)タイムラインは 8 プロセッサシステムでのタイムラインを表示します。
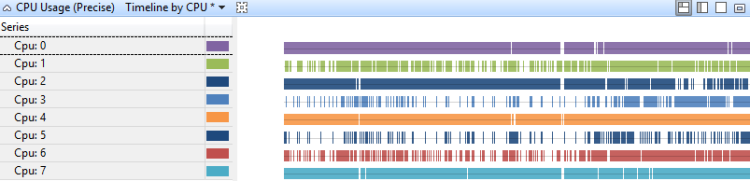
図 11 CPU 別 CPU 使用率(正確)タイムライン
プロセス、スレッド別タイムライン
プロセスごとの スレッドごとのタイムラインでの CPU 使用率は、特定の時点でスレッドが実行されているプロセスを示します。 図 12 プロセス、スレッドごとの使用率(精密)タイムラインは、このタイムラインを複数のプロセスにわけて表示したものです。
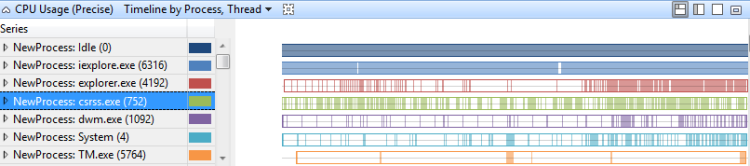
図 12 プロセス別使用量(正確)タイムライン、スレッド
Usage by Priority at Context Switch Begin (コンテキスト切り替え開始時点の優先度別の使用率)
このグラフは、各優先度において、優先度の高いスレッドのバースト的な活動を特定するものです。 図 13 CPU 別 CPU 使用率(正確) コンテキスト切り替え開始時の優先度別使用率は、優先順の分布を示します。
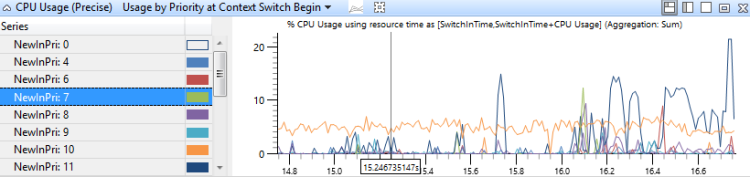
図 13 CPU 別 CPU 使用率(正確) コンテキスト切り替え開始時の優先度別使用率
CPU 別の使用率
このグラフは、CPU の使用率を CPU ごとにまとめてグラフ化し、プロセッサ間の仕事の配分を表したものです。 図 14 CPU 別 CPU 使用率(正確) CPU 使用率は、8 個のプロセッサを搭載したシステムのこのグラフを示しています。
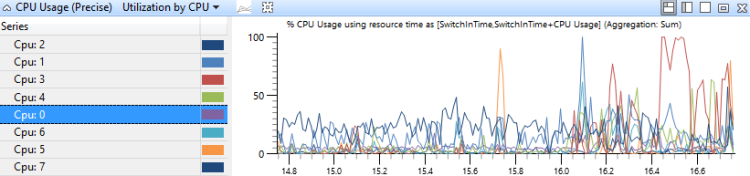
図 14 CPU 使用率(正確) CPU 別使用率
プロセス、スレッド別使用率
このグラフでは、CPU 使用率は最初にプロセス別にグループ化され、次にスレッド別にグループ化されます。 プロセスと各プロセスのスレッドの相対的な使用状況を示します。図 15 プロセス別の CPU 使用率 (正確な) 使用率、スレッドは複数のプロセス間でのこの分布を示しています。
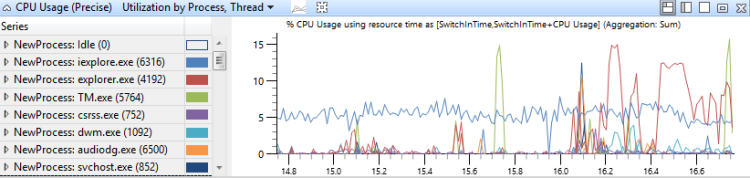
図 15 プロセス別 CPU 使用率(正確)、スレッド別使用率
DPC/ISR グラフ
DPC/ISRグラフは、WPAにおけるDPC/ISR情報の主要なソースです。 グラフ内の各行はフラグメントを表します。これは、DPC または ISR が中断されない期間です。 データはフラグメントの開始時と終了時に収集されます。 DPC/ISRが完了すると、追加のデータが収集されます。 図 16 DPC/ISR 図は、この動作を示しています。
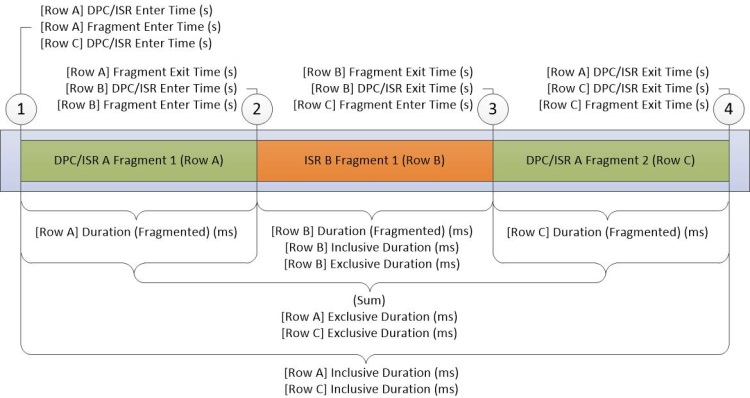
図 16 DPC/ISR ダイアグラム
図 16 DPC/ISR 図は、次のアクティビティ中に収集されたデータを示しています。
DPC/ISR-Aが実行開始されます。
DPC/ISR-Aよりも高い割込みレベルのデバイス割込みにより、ISR-BがDPC/ISR Aを割込み、それによりDPC/ISR-Aの最初のフラグメントを終了させます。
ISR-Bが完了し、それによってISR-Bのフラグメントが終了します。 DPC/ISR-Aは2番目のフラグメントで実行を再開します。
DPC/ISR-Aが終了し、DPC/ISR-Aの2番目のフラグメントが終了します。
データテーブルには、各フラグメントの行が表示されます。 DPC/ISR-Aのフラグメントは、フラグメントでない列と同一の情報を共有します。
DPC/ISR グラフのカラムは、フラグメントレベルの情報、つまり DPC/ISR レベルのカラムを記述します。 各フラグメントは、フラグメント レベルの列内の異なるデータと、DPC/ISR 列の同一のデータです。
| 列 | 詳細 |
|---|---|
% Duration (Fragmented) |
現在表示されている期間における CPU 時間の合計に対する割合で表される期間 (断片化)。 |
% 排他継続時間 |
現在表示されている期間における CPU 時間の合計に対する割合で表される排他期間。 |
% 包括継続時間 |
現在表示されている期間における CPU 時間の合計に対する割合で表される包括継続時間。 |
番地 |
DPC または ISR 関数のメモリ アドレス。 |
Count (DPC/ISRs) |
この行で表現されるDPC/ISRの数。 DPC/ISR の最終フラグメントを表す行では、このカウントは常に1であり、それ以外の場合、このカウントは0になります。 |
Count (Fragments) |
その行で表現されるフラグメントの数。 これは、個々の行に対して常に 1 です。 |
CPU |
DPC または ISR が実行された論理プロセッサのインデックス。 |
DPC の種類 |
DPC の場合、DPC の種類 (Regular または Timer)。 ISRの場合、この値は空白です。 |
DPC/ISR Enter Time (s) |
DPC/ISR が開始されたトレース内の時間。 |
DPC/ISR Exit Time (s) |
トレース開始からDPC/ISRが終了するまでの時間。 |
Duration (Fragmented) (ms) |
Fragment Exit Time (s) から Fragment Enter Time (s) をミリ秒単位で引いた値。 |
排他継続時間 (ミリ秒) |
この DPC/ISR のすべてのフラグメントの断片化された期間の合計 (ミリ秒)。 |
Fragment |
この行のDPC/ISRが複数のフラグメントを持っていた場合、この値はTrueとなり、そうでない場合はFalseとなります。 |
Fragment |
このDPC/ISR の唯一のフラグメントでない場合、この値はTrue、それ以外はFalseになります。 |
Fragment Enter Time (s) |
フラグメントの実行が開始された時刻。 |
Fragment Exit Time (s) |
フラグメントの実行が停止した時刻。 |
機能 |
実行された DPC または ISR 関数。 |
包括継続時間 (ミリ秒) |
DPC/ISR 終了時刻 (s) から DPC/ISR Enter Time (秒) (ミリ秒) を差し引いた値。 |
MessageIndex |
メッセージシグナル割り込みの割り込みインデックス。 |
モジュール |
DPC または ISR 関数を含むモジュール。 |
戻り値 |
DPC/ISR の戻り値 |
Type |
イベントの種類。これは、DPC または割り込み (ISR) のいずれかです。 |
ベクター |
デバイス上の割り込みベクトルの値。 |
デフォルトのプロフィールでは、このグラフに以下のプリセットが使用されます。
[DPC,ISR,DPC/ISR] CPU 別の期間
[DPC,ISR,DPC/ISR]モジュール、機能別継続時間
[DPC,ISR,DPC/ISR] モジュール、関数別タイムライン
[DPC,ISR,DPC/ISR] CPU 別の期間
DPC/ISR イベントは、実行された CPU によって集計され、期間で並べ替えされます。 このグラフは、CPU 間での DPC アクティビティの割り当てを示しています。 図 17 CPU 別の DPC/ISR 期間は、8 つのプロセッサを搭載したシステムのこのグラフを示しています。
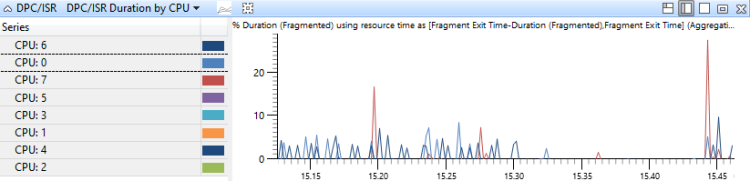
図 17 CPU 別 DPC/ISR 継続時間 (単位:秒)
[DPC,ISR,DPC/ISR]モジュール、機能別継続時間
このグラフでは、DPC/ISRイベントをDPC/ISRルーチンのモジュールと機能別に集計し、継続時間でソートしています。 これは、どのDPC/ISRルーチンが最も時間を消費したかを示しています。 図18 DPC/ISR Duration by Module, Functionは、2つのモジュールでDPC/ISRアクティビティを発生させる期間を示しています。
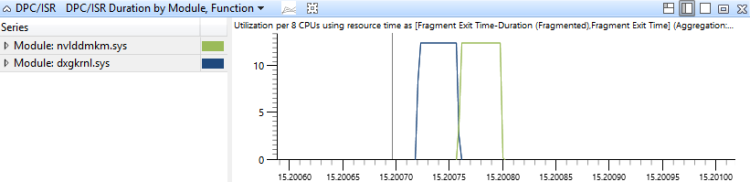
Figure 18 DPC/ISR Duration by Module, Function
[DPC,ISR,DPC/ISR] モジュール、関数別タイムライン
このグラフでは、DPC/ISRイベントをDPC/ISRルーチンのモジュールと関数別に集計し、継続時間でソートしています。 これらは、タイムラインとしてグラフ化されます。 このグラフは、 DPC/ISRが実行された期間の詳細なビューを提供します。 このグラフでは、単一の DPC/ISR をどのように断片化できるかを示すこともできます。 図 19 DPC/ISR タイムライン (モジュール別): 関数は、アクティビティのタイムラインを3つのモジュールで示しています。

[DPC,ISR,DPC/ISR] モジュール、関数別タイムライン
スタックツリー
スタックツリーは、 CPU 使用率 (サンプリング)、CPU 使用率 (正確)、WPA の DPC/ISR テーブル、および評価レポートで報告される問題に表示されます。 スタックツリーは、一定期間内の複数のイベントに関連するコールスタックを示します。 ツリー内の各ノードは、イベントのサブセットによって共有されているスタックセグメントを表します。 ツリーは個々のスタックから構築され、図20の3つのイベントのスタックに示されています。

図 20 3 つのイベントのスタック
図21 特定された一般的なセグメントは、このグラフで共通のシーケンスを識別する方法を示しています。

図21 識別される共通セグメント
図22スタックから構築されたツリーは、共通のセグメントを結合してツリーのノードを形成する方法を示しています。
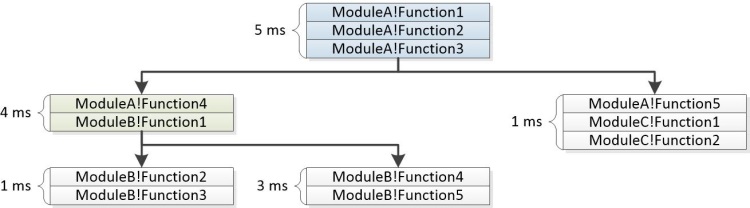
図 22 スタックから構築されるツリー。
WPA UIのStacks列には、非リーフノードごとにエキスパンダーが含まれています。 評価報告された課題では、ツリーは集約された重みとともに表示されます。 一部の枝は、その重みが指定された閾値を満たさない場合、グラフから削除されることがあります。 以下のサンプルスタックは、上記のイベントが評価報告課題の一部としてどのように表示されるかを示しています。
5ms ModuleA!Function1
5ms ModuleA!Function2
5ms ModuleA!Function3
|
4ms |-ModuleA!Function4
4ms | ModuleB!Function1
| |
1ms | |-ModuleB-Function2
1ms | | ModuleB-Function3
| |
3ms | |-ModuleB!Function3
3ms | ModuleB!Function4
|
1ms |-ModuleA!Function5
1ms ModuleC!Function1
1ms ModuleC!Function2
スタック内の<itself>ノードは、関数自体がスタックの最上位にある時間を表します。 <itself>ノードには、親関数から呼び出される関数に費やされる時間は含まれません。 その時間は、関数に費やされた排他的時間と呼ばれます。
例えば、Function1 は Function2 を呼び出します。 Function2 は、CPU を集中的に使用するループで2ミリ秒を使用し、4ミリ秒間実行された別の関数を呼び出しました。 これは次のようなスタックで表すことができます。
6ms ModuleA!Function1
|
2ms |-<itself>
4ms |-ModuleA!Function2
4ms ModuleB!Function3
4ms ModuleB-Function4
テクニック
このセクションでは、パフォーマンス解析の標準的なアプローチについて説明します。 CPU 関連の一般的なパフォーマンス上の問題を調査するために使用できるテクニックを提供します。
パフォーマンス解析は4つのステップで構成されています。
シナリオと問題を定義します。
関係するコンポーネントと関連する時間範囲を特定します。
起こるはずだったことのモデルを作成します。
このモデルを使用して、問題を特定し、根本原因を調査します。
シナリオと問題を定義する
性能解析の最初のステップは、シナリオと問題を明確に定義することです。 多くのパフォーマンス上の問題は、評価指標で測定されるシナリオに影響します。 次に例を示します。
シナリオ11: 物理リソースが完全に利用されていない。 例えば、サーバーがパケットを十分に速く暗号化できないため、ネットワーク接続を十分に利用できない。
シナリオ2:ある物理リソースが必要以上に利用されています。 たとえば、バッテリ電源を使用するアイドル期間中にシステムが大量の CPU リソースを使用しているとします。
シナリオ3: アクティビティが必要な速度で完了しない。 例えば、ビデオの再生中にフレームがドロップするのは、フレームが十分に速くデコードされないからです。
シナリオ4:アクティビティが遅延しています。 たとえば、ユーザーが Internet Explorer を起動しましたが、タブを開くのに予想以上に時間がかかっていました。
CPU リソースに関連するシナリオ3と4は、このガイドで説明されています。 シナリオ1および2は範囲外であり、カバーされていません。 これらの問題を分析するには、「遅い」といった曖昧な観察から始めて、シナリオと正確な問題を特定するために追加の質問をすることができます。
コンポーネントと期間を特定する
シナリオと問題が特定されたら、関係するコンポーネントと対象期間を特定することができます。 構成要素には、ハードウェアリソース、プロセス、スレッドなどがあります。
多くの場合、分析ガイドの関連するアクティビティを特定することで、関心のある時間範囲を見つけることができます。 アクティビティとは、WPAで、選択およびズームインできる開始イベントと停止イベントの間のインターバルのことです。 アクティビティが定義されていない場合は、シナリオに関連する特定の一般的なイベントを探すか、シナリオの開始と終了を示す可能性のあるリソース使用率の変化を探すことによって、時間範囲を見つけることができます。 たとえば、CPU が 2 秒間アイドルであった後、4 秒間フルに使用され、その後再び 2 秒間アイドルになった場合、ビデオ再生をキャプチャするトレースでは、4 秒間のフル使用率が関心のある領域となる可能性があります。
Create a Model (モデルの作成)
問題の根本的な原因を理解するためには、どのようになるべきだったかを示すモデルが必要です。 モデルは、問題またはメトリックの関連する目標から始まります。例えば、「この操作は5秒以内に完了するべきである」のようになります。
より完全なモデルには、コンポーネントがどのように実行されるべきかについての情報が含まれます。 例えば、コンポーネント間でどのような通信が期待されるか? 典型的なリソースの利用はどの程度か? 通常、操作にはどれくらいの時間がかかるのか?
モデルの情報は、多くの場合、評価分析ガイドに記載されています。 そのようなリソースがない場合は、パフォーマンスの問題が発生していない類似のハードウェアとソフトウェアからトレースを作成してモデルを作成することができます。
モデルを使用して問題を特定し、根本的な原因を調査する
モデルを作成したら、トレースとモデルを比較して問題を特定することができます。 例えば、Suspend Devicesという特定のアクティビティのモデルは、Suspend <DeviceName>というサブアクティビティの各インスタンスが100ms以上かからないようにしながら、全体のアクティビティを3秒で完了させることが推奨される場合があります。 Suspend<DeviceName>というサブアクティビティの2つのインスタンスがそれぞれ 800ms かかる場合、そのインスタンスを調査する必要があります。
モデルからの各乖離を分析し、根本原因を見つけることができます。 関与するスレッドの状態を調べ、共通の根本原因を探す必要があります。 要求された速度で完了しない、あるいは遅延するアクティビティについて、CPU に関連するいくつかの主要な根本原因をここで説明します。
ダイレクト CPU 使用率: 適切なスレッドが完全な CPU リソースを受け取りましたが、必要なプログラムが短時間で実行されませんでした。 これは、プログラムの誤動作や遅いハードウェアによって引き起こされる可能性があります。
スレッドの干渉。あるスレッドが十分な実行時間を得られず、代わりに他のスレッドが実行された。 この場合、そのスレッドはスターブ状態であるか、または割り込まれているとみなされます。
DPC/ISR の干渉: Cpu が Dpc または Isr の処理中にビジーだったため、スレッドは十分な実行時間を得られませんでした。
多くの場合、これらの根本原因の1つはスレッドに顕著な影響を与えず、スレッドは待機状態でほとんどの時間を費やします。 この場合、スレッドが待機しているイベントを特定し、調査する必要があります。 この再帰的なタイプの調査は待機分析と呼ばれ、クリティカルパスを特定することから始まります。
高度な技法: 待機分析とクリティカルパス
アクティビティとは、ある開始イベントからある終了イベントまで、順次または並行して行われる操作のネットワークのことです。 トレース内の開始イベントと終了イベントのペアは、アクティビティと見なすことができます。 この操作のネットワークで最も長い経路は、クリティカルパスと呼ばれます。 クリティカルパス上のいずれかの操作の期間を短縮すると、アクティビティ全体の期間が直接短縮されますが、クリティカルパスを変更することもできます。
図 23 アクティビティ操作は、3つのスレッドのアクティビティを示しています。 Thread-1はアクティビティ開始イベントを送信し、Thread-2とThread-3がタスクを完了するのを待ちます。 Thread-2が先にタスクを完了し、Thread-3がそれに続く。 両方のスレッドがタスクを完了すると、Thread-1が準備され、アクティビティイベントを完了します。
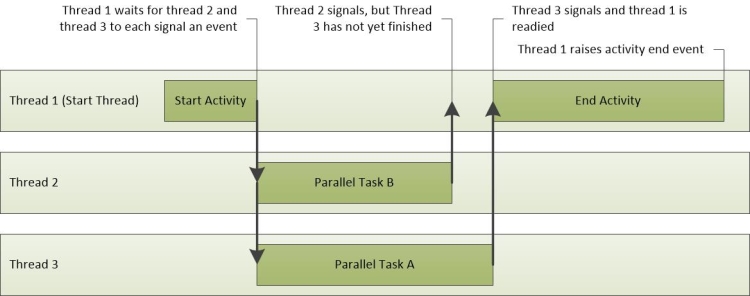
図 23 アクティビティ操作.
このシナリオでは、クリティカルパスには Thread-3と Thread-1 の部分が含まれています。 これらをトレースしたものが図 24 のクリティカルパスです。 スレッド-2はクリティカルパス上にないため、そのタスクの完了にかかる時間は、アクティビティ全体の時間に影響を与えません。
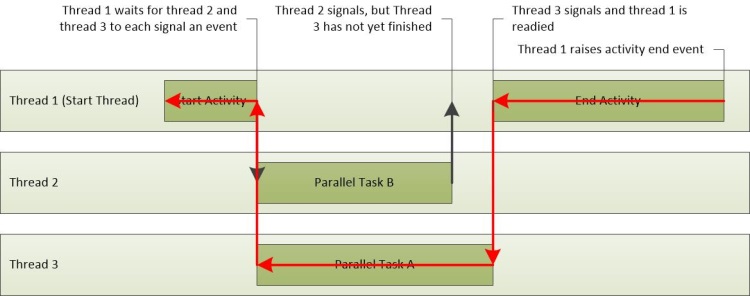
図 24 クリティカルパス.
クリティカルパスとは、あるアクティビティの実行になぜそれだけの時間がかかったのかという疑問に対する、低レベルの文字通りの答えです。 クリティカルパスの主要なセグメントがわかったら、それらを分析して、全体の遅れの原因となっている問題を見つけることができます。
クリティカルパス探索の一般的なアプローチ
クリティカルパスを見つけるための最初のステップは、シナリオモデルを確認し、アクティビティの目的と実施方法を理解することです。
アクティビティを理解することで、クリティカルパス上にある可能性のある特定の操作、プロセス、スレッドを特定することができます。 例えば、Fast Startup Resume Explorer Initアクティビティの遅延は、RunOnceアプリケーションとエクスプローラ初期化プロセスによって引き起こされる可能性があり、これらは両方ともかなりの量のI/Oを必要とします。
シナリオモデルを確認した後、影響を受けるアクティビティについて、評価で問題が報告されたかどうかを確認します。 多くの場合、アセスメントで報告された遅延の問題には、クリティカルパスの近似値が含まれています。 クリティカルパスは、待機と準備のアクションのシーケンスとして表示されます。 これは、クリティカルパスの主要な遅延セグメントをリストの真ん中に置き、イベントのシーケンスとして最初から最後まで読むことができます。 リストの最後のエントリは、アクティビティを完了したスレッドを準備したアクションです。
クリティカルパスを手動で探す必要がある場合は、アクティビティを完了したプロセスとスレッドを特定し、アクティビティが完了した瞬間から逆算することをお勧めします。 アクティビティを開始したプロセスとスレッド、およびアクティビティを完了したプロセスとスレッドは、WPAのActivitiesグラフで特定することができます。
Activitiesグラフは、評価結果XMLファイルからトレースが読み込まれたときに表示されます。 特定のアクティビティに関連するプロセスおよびスレッドを特定するには、グラフを対象のアクティビティに展開し、表示をGraph+Tableに切り替えます。 グラフモードをTableに設定します。 開始プロセス、開始スレッド ID、終了プロセス、終了スレッド ID列がテーブル内の各アクティビティについて表示されます。
開始工程、終了工程、スレッド、アクティビティの実装が分かれば、クリティカルパスを逆にたどることができます。 アクティビティを完了したスレッドを分析することから始め、そのスレッドがその時間のほとんどを実行、準備、または待機など、どのように過ごしたかを判断します。
重大な実行時間は、直接の CPU 使用率がクリティカル パスの期間に影響を与える可能性を示します。 レディモードで過ごした時間は、他のスレッドがクリティカルパス上のスレッドの実行を妨げて、クリティカルパスの持続時間に寄与していることを示します。 待機中で費やした時間は、I/O、タイマーなど、クリティカル パス上の他のスレッドやプロセスを現在のスレッドが待機していたことを示します。
現在のスレッドを待機させた各スレッドは、おそらくクリティカルパスの別のリンクであり、クリティカルパスの期間が説明されるまで分析することもできます。
手順 WPAにおけるクリティカルパスの発見。
以下の手順は、アクティビティグラフでクリティカルパスを求めるアクティビティを特定した場合を想定しています。
アクティビティグラフでアクティビティにカーソルを合わせると、そのアクティビティを完了したプロセスを特定できます。
CPU 使用率 (正確)グラフを追加します。 影響を受けるアクティビティにズームし、プロセス別使用率、スレッドプリセットを適用します。
列ヘッダーを右クリックし 、ReadyThreadStack 列と CPU 使用率 (ミリ秒) 列を 表示します。 Ready (us) [Max] 列と Waits (us) [Max] 列を削除します。
対象プロセスを展開し、CPU 使用率 (ms)、Ready (us) [Sum]、Waits (us) [Sum]でそれぞれソートします。
Running、Ready、または Waiting 状態で費やされた時間が最も長いプロセス内の NewThreadIds を検索します。
実行中または準備完了状態でかなりの時間を費やすスレッドは、クリティカル パスでの直接 CPU 使用率を表している可能性があります。 待機中の状態でかなりの時間を費やすスレッドは、I/O、タイマー、またはクリティカル パス内の別のスレッドで待機している可能性があります。
スレッドが何を待っているかを調べるには、NewThreadId グループを展開して、ReadyThreadStack を表示します。
[Root]を展開します。
KiDispatchInterruptで始まるスタックは、他のスレッドに関連するものではありません。 これらのスタックでスレッドが何を待っていたかを確認するには KiDispatchInterrupt を展開し、子スタック上の関数を表示します。 IopfCompleteRequest は、すぐに使用できるスレッドが I/O を待機している状態を示します。 KiTimerExpiration は 、すぐに使用できるスレッドがタイマーを待機している状態を示します。
KiDispatchInterruptで始まらないスタックをReadyingProcessとReadyingThreadが表示されるまで展開します。 プロセスが既に展開されている場合は、ReadyingThreadに対応するNewThreadIdを展開します。 実行中、準備完了、別の理由で待機中、または別のプロセスで待機中のスレッドを見つけるまで、この手順を繰り返します。 スレッドが別のプロセスで待機している場合は、そのプロセスを使用してこの手順を繰り返します。
例
この例では、Fast Startup Resume Explorer Initアクティビティでの遅延を紹介します。 [問題] ウィンドウの検索では 、このアクティビティに対して 7 つの遅延の種類の問題が報告されます。 これらの問題のそれぞれは、クリティカルパスのセグメントとしてレビューすることができます。 次の主要なセグメントが識別されます。
プロセス TestBootStrapper.exe (3024) のスレッド3872は、2.1秒間、割り込まれています。
プロセスTestBootStrapper.exe (3024)のスレッド3872 は、1秒間の CPU 時間を使用しています。
プロセスTestBootStrapper.exe (3024)のスレッド3872 は、レジストリハイブを 544 ミリ秒フラッシュします。
プロセスTestBootStrapper.exe (3024)のスレッド3872は、513 ミリ秒間スリープします。
スレッド 4052 と 4036 がExplorer.exeディスクから読み取り、461 ミリ秒の遅延が発生します。
プロセスTestBootStrapper.exe (3024)のスレッド3872は、187 ミリ秒間スターブします。
プロセスTestBootStrapper.exeのスレッド3872は、ディスクに3.5MBを書き込み、178ミリ秒の遅延を発生させました。
問題を見ると、このアクティビティは5.2秒の遅延が発生しています。 これらの遅延は、アクティビティ全体の 6.3 秒の期間の大部分を占めます。 TestBootStrapper.exe アプリケーションは、主に他の処理タスクを先取りしていたため、この遅延の原因となっています。
クリティカル パスの問題を調査する
影響を受けるリージョンにズームし 、ReadyThreadStack 列と CPU 使用率 (ミリ秒) 列を追加 します。
この場合、Explorer.exe はアクティビティを完了させるプロセスです。 エクスプローラ.exeプロセスを展開し、次の図のようにCPU Usage (ms), Ready (us) [Sum], Waits (us) [Sum] でそれぞれソートします。

図 25 CPU 使用率 (ms) 別のアクティビティ

図 26 準備完了によるアクティビティ

図 27 待機時間別アクティビティ (us)。
CPU 使用率 (ms) 列で並べ替えると、一番上の子行が 299 ミリ秒になります。 Ready(us)[Sum]列で並べ替えると、46msの最上位の子の行が表示されます。 待機(us) [Sum]}列による並べ替えでは、5749 ミリ秒の上の子行と 4902 ミリ秒の 2 行目が表示されます。 これらの行は遅延に大きく影響を与えるので、さらに調査する必要があります。
次の図に示すように、スタックを展開して、準備完了のスレッドを表示します。
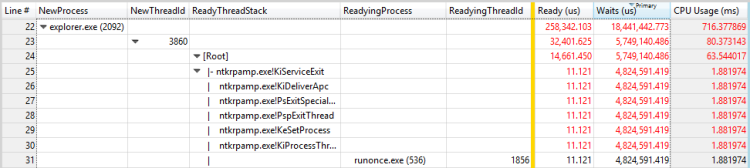
図 29 別のスレッドに対するプロセスの準備とスレッドの準備
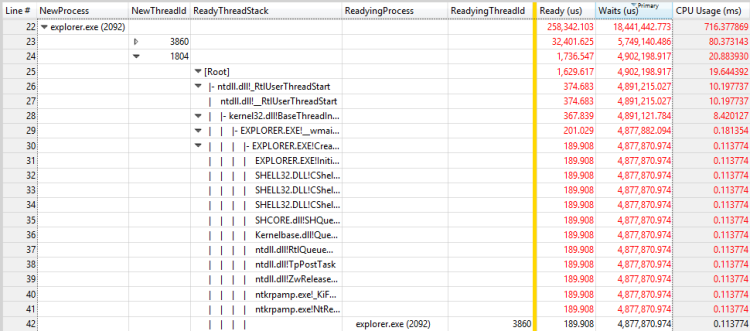
図 29 別のスレッドに対するプロセスの準備とスレッドの準備
この例では、最初のスレッドは、プロセスが終了する前にほとんどのRunOnce.exe時間を費やします。 プロセスの完了にRunOnce.exe時間がかかっている理由を調べる必要があります。 2 番目のスレッドは最初のスレッドで待機しています。同じ待機チェーン内の重要ではないリンクである可能性があります。
RunOnce.exeは、この手順を繰り返します。 主要なコントリビューター列は Waits (us)で、4 つのコントリビューターが可能です。
各共同作成者を展開して、最初の 3 人の共同作成者がそれぞれ 4 番目の共同作成者を待機しているのを確認します。 この状況により、最初の 3 人の共同作成者は待機チェーンに対して重要ではありません。 4 番目の共同作成者は、別のプロセス (TestBootStrapper.exe) を待機しています。
このシナリオは、図 30 のスレッドの準備プロセスと準備中のスレッドに関するページRunOnce.exe。
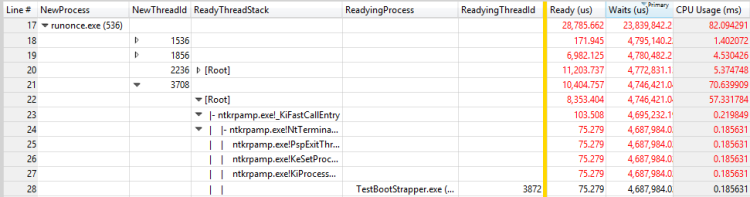
図 30 RunOnce.exe のスレッドに対するプロセスの準備とスレッドの準備。
TestBootStrapper.exeに対して、この手順を繰り返してください。 結果を次の 3 つの図に示します。

図 31 CPU 使用率別スレッド数 (ミリ秒)

図 32 準備完了によるスレッド(us)

図 33 待機時間別スレッド数 (us)。
スレッド 3872 は、約 1 秒の実行、2 秒の準備完了、および 1.3 秒の待機に費やしました。 このスレッドはスレッド 3872 の準備完了スレッドで、実行時間と準備時間が遅延の一部である可能性があります。 評価では、遅延に一致する次の問題が報告されます。
プロセスTestBootStrapper.exe (3024)のスレッド3872は、2.1秒間割り込まれています。
プロセスTestBootStrapper.exe (3024)のスレッド3872は、187 ミリ秒間スターブします。
プロセスTestBootStrapper.exe (3024)のスレッド3872 は、1秒間の CPU 時間を使用しています。
その他の問題を見つけるには、スレッド 3872 が待機しているイベントを表示します。 ReadyThreadStackを展開し、Figure 34 Contributors to Wait Timeに示すように、1.3秒の待ち時間の原因を表示します。

図 34 待機時間の共同作成者
KiRetireDpcList は通常、I/O に関連し 、KiTimerExpiration は タイマーです。 ReadyThreadStack を削除し、NewThreadStackを表示することで、I/Os とタイマーがどのように開始されたのか確認できます。 このビューには、図 35 の I/Os と NewThreadStack のタイマーに示すように、次の 3 つの関連する関数が表示されます。

図 35 NewThreadStack の I/Os とタイマー
このビューでは、以下の詳細が開示されています。
プロセスTestBootStrapper.exe (3024)のスレッド3872 は、レジストリハイブを 544 ミリ秒フラッシュします。
プロセスTestBootStrapper.exe (3024)のスレッド3872は、513 ミリ秒間スリープします。
プロセス のスレッド 3872 はTestBootStrapper.exe 3.5 MB をディスクに書き込むので、178 ミリ秒の遅延が発生します。
クリティカル パスの調査を開始すると、Explorer.exe で最も重要な待機原因を分析し、その待機原因の後に発生したクリティカル パスの一部を無視しました。 クリティカル パスの以前に無視されたこのセクションをキャプチャするには、タイムラインを確認する必要があります。 CPU 使用率 (正確) を追加し、Timeline by Process, Thread プリセットを適用します。
クリティカル パスの一部として識別されたプロセスのみを含めるようにフィルタリングします。 結果のグラフを図 36 のクリティカル パス タイムラインに示します。

図 36 クリティカル パスのタイムライン
図 36 クリティカル パスのタイムラインは、Explorer.exe待機を停止した後、より多くの作業を実行RunOnce.exe。 以前に分析された待機チェーンの後の期間にズームし、別の分析を実行します。 この場合、分析では、クリティカル パスを介して明確なトレースを実行Explorer.exe内部にある多数のスレッドが明らかになります。 この場合、さらなる分析によって、アクション可能な分析情報が得られる可能性は低い可能性があります。
直接 CPU 使用率
クリティカル パス上のスレッドで CPU 時間が大幅に使用されるので、アクティビティが遅延する場合がよく発生します。 スレッド状態モデルを使用すると、この問題は、実行中状態で非常に長い時間を費やすクリティカル パス上のスレッドによって特徴付けされるのを確認できます。 一部のハードウェアでは、この高い CPU 使用率によって遅延が発生する可能性があります。
問題の特定
多くの評価では、ヒューリスティックを使用して、CPU 使用率に関連する直接的な問題を特定します。 クリティカルパス上の著しいCPU使用率は、以下のような形で問題として報告されます。
プロセスPによるCPU使用は、影響を受けるアクティビティAをx秒間遅延させます。
ここで、Pは実行中のプロセス、Aはアクティビティ、xは時間(秒)です。
遅延が発生するアクティビティに対してこれらの問題が報告された場合、直接的なCPU使用率が原因である可能性があります。
直接 CPU 使用率を調査する
CPU 使用率 (サンプル)グラフで 100% の CPU 使用率を発生させる個々の CPU を探すことで、手動で問題を特定することができます。
グラフ内の関心領域にズームし、[プロセスとスレッド別の使用率] プリセットを選択 します。
既定では、テーブルには、CPU 使用率の集計が最も高い行が上部に表示されます。 これらのスレッドは、CPU 使用率 (サンプリング) グラフの 上部にも表示 されます。
ノート 複数のプロセッサを持つシステムでは、1 つのプロセッサの 100% を使用するスレッドは、100/(論理プロセッサの数) を消費している可能性があります。 この種のシステムでは、仮想アイドル 状態のスレッド (PID 0、TID 0) だけが、100/(論理プロセッサの数) よりも大きいプロセッサ使用率を示す可能性があります。 最も多くの CPU を消費するプロセスとスレッドがクリティカル パス内のスレッドに対応している場合は、直接 CPU 使用率がおそらく要因になります。
直接 CPU 使用率Assessment-Reported問題の例
TestUM.exeプロセス(4024)によるCPU使用は、影響を受けるアクティビティである高速スタートアップ・シャットダウンプロセスTestIM.exeを2.1秒遅延させます。 この例は、図 37 のスレッド 3208 に示されています。
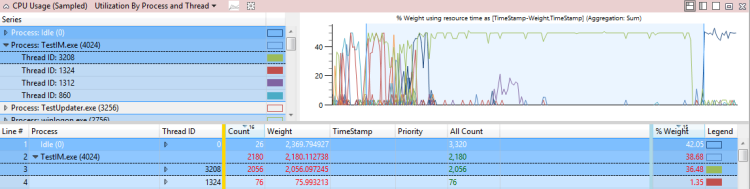
図 37 スレッド 3208
調査
直接 CPU 使用率がクリティカル パスの遅延の原因である場合は、遅延の原因である特定のモジュールと関数を特定する必要があります。
手法: 直接 CPU 使用率Assessment-Reportedの問題を確認する
評価で報告された直接 CPU 使用率の問題を拡張して、直接 CPU 使用率の影響を受け取るクリティカル パスを表示できます。 CPU 使用率に関連付けられているノードを展開すると、CPU 使用率と関連付けられているモジュールに関連付けられているスタックが表示されます。 このビューは、図 38 拡張 CPU 使用率セグメントに示されています。
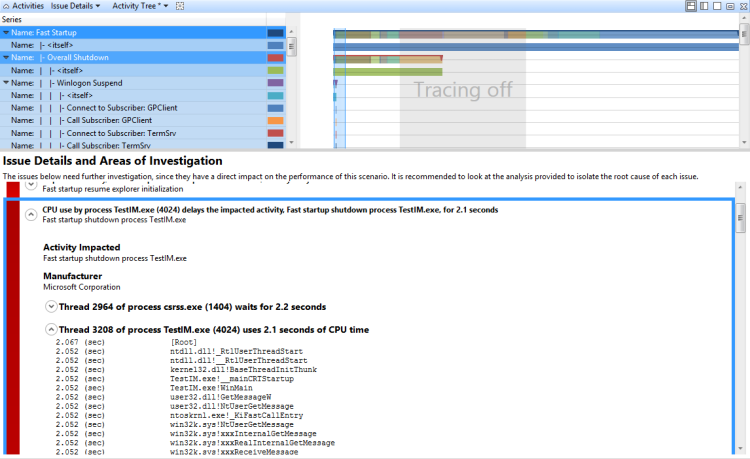
図 38 拡張 CPU 使用率セグメント.
手法: CPU 使用率の問題のスタックを直接手動で調査する
評価で問題が報告されていない場合、または追加の検証が必要な場合は、CPU 使用率 (サンプリング) グラフを使用して、CPU 使用率の問題に関連するモジュールと関数に関する情報を手動で収集できます。 これを行うには、関心領域にズームし、CPU 使用率で並べ替えたスタックを表示する必要があります。
CPU 使用率の問題のスタックを直接手動で調査する
[トレース] メニューの [シンボルの読み込み] をクリックします。
タイムラインをズームして、CPU の問題の影響を受けるクリティカル パスの部分のみを表示します。
[プロセスと スレッド別の使用率] プリセットを適用 します。
Stack列を表示に追加し、この列をThread IDの右側(バーの左側)にドラッグします。
プロセスとスレッドを展開してスタック ツリーを表示します。
スタック内の行は、CPU 使用率 の % 重み で降順に並べ替えされます。 これにより、最も興味深いスタックが上位に表示されます。 スタックを展開するとき、% 重み 列を見て、最も高い使用率を持つ行にフォーカスがあることを確認します。
スタックのコピーを抽出するには、全ての行を選択して右クリックし、選択部分のコピー をクリックします。
解決方法
構成レベルとコンポーネント レベルの両方で対処法を適用して、高い CPU 使用率を解決できます。
直接 CPU 使用率は、下位プロセッサを搭載したコンピューターに大きな影響を与えます。 このような場合、コンピューターに処理能力を追加することができます。 または、問題のモジュールをクリティカルパスまたはシステムから削除できるかもしれません。 コンポーネントを変更できる場合は、以下のいずれかの結果を得るための再設計作業を検討します。
CPU に負荷のかかるコードをクリティカルパスから削除します。
CPU 効率の高いアルゴリズムを使用する
作業を延期またはキャッシュする
スレッドの干渉
クリティカルパス上にないスレッド(アクティビティとは無関係かもしれない)がCPUを使用すると、クリティカルパス上にあるスレッドが遅延する可能性があります。 スレッド状態モデルは、この問題が、クリティカルパス上のスレッドが異常な時間を Ready (準備完了) 状態で過ごすことによって特徴付けられることを示しています。
問題の特定
多くの評価では、干渉に関連する問題を特定するためにヒューリスティックを使用しています。 これらは、次の2つのうちどちらかの形式で報告されます。
プロセスPがスターブ状態にあります。 このスターブにより、影響を受けるアクティビティAにxmsの遅延が発生します。
プロセスPは割り込まれています。 割り込みは、xmsの影響を受けるアクティビティAへの遅延を引き起こします。
ここで、Pはプロセス、Aはアクティビティ、xはミリ秒単位の時間です。
最初のフォームは、クリティカル パス上のスレッドと同じ優先度レベルのスレッドからの干渉を反映します。 2 番目の形式は、クリティカル パス上のスレッドよりも優先度の高いスレッドからの干渉を反映しています。
遅延アクティビティでこれらのタイプの問題が報告された場合、スレッドの干渉が原因である可能性があります。 CPU 使用率 (正確) グラフを使用して 、問題を手動で特定できます。
スレッド干渉の問題を特定する。
間隔を拡大し、[CPU 別の使用率] プリセットを適用 します。 すべての CPU で利用率が 100% の場合、干渉の問題があることを示します。
Utilization by Process, Thread プリセットを適用し、最初の Ready (us) 列でソートします。 (これはSum集計を含む列です)。
影響を受けるアクティビティのプロセスを展開し、クリティカルパス上のスレッドの準備完了時間を見ます。 この値は、スレッドのInterference問題を解決することによって、遅延を減らすことができる最大時間です。 調査中の遅延に対して大きな大きさを持つ値は、スレッド干渉の問題が存在することを示します。
図 39 CPU 使用率が 100% 近く、図 40 スレッド干渉の問題は次のシナリオを表しています。

図 39 CPU 使用率が 100% に近い
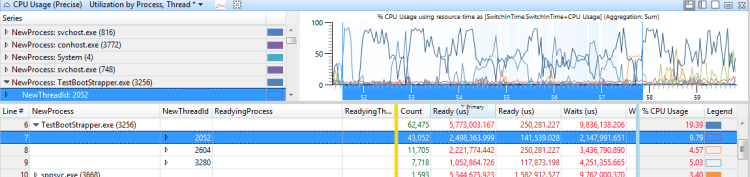
図 40 スレッド干渉の問題
調査
問題を特定した後、影響を受けたスレッドがなぜReady (準備完了) 状態で長い時間を過ごしたのかを特定する必要があります。
テクニック スレッドが Ready (準備完了) 状態で時間を費やした理由を特定する。
CPU 使用率 (精度)グラフを使用して、スレッドが Ready (準備完了) 状態で時間を費やした理由を特定することができます。 まず、スレッドが特定のプロセッサに制限されているかどうかを判断する必要があります。 この情報を直接取得することはできませんが、CPU 使用率が高い期間中のスレッドの CPU 使用率履歴を調べることができます。 これは、スレッドがプロセッサ間を頻繁に切り替える傾向にある期間です。
スレッドのプロセッサの制限を決定する。
対象地域にズームインします。
CPU 使用率 (正確)グラフを追加し、プロセス別、スレッド別使用率プリセットを適用します。
詳細設定 ダイアログを使用して、NewThreadId の右側に Unique Count 集計モードを持つ CPU 列を追加します。
グラフをフィルタリングして、関心のあるスレッドのみを表示します。
CPU列の値は、現在の時間間隔中にスレッドが実行されたプロセッサの数を反映しています。 CPU 使用率が 100% の期間中、この数は、このスレッドの実行が許可されているプロセッサの数を概算します。 値が使用可能なプロセッサの数より小さい場合、スレッドは特定の CPU に制限される可能性があります。
図 41 制限付きスレッドは、このグラフの例を示しています。
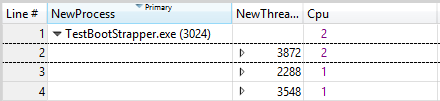
図 41 制限付きスレッド
スレッドのプロセッサ制約がわかったら、何がそのスレッドの割り込みやスターブを発生させたかを判断できます。 これを行うには、スレッドが Ready (準備完了) 状態態で過ごした間隔を特定し、その間に他のスレッドやプロセスがどのように実行されていたかを調べる必要があります。
スレッドの割り込みまたはスターブの原因を特定します
スレッドがいつ Ready (準備完了) 状態になったかを示すグラフを作成し、Utilization by Process, Threadのプリセットを適用します。
ビューエディタを開き、詳細設定をクリックし、グラフ設定タブを選択します。
図 42 の準備完了時刻列に示すように、[開始時刻] をReadyTime に設定し、[期間] を [準備完了] (us)に設定します。 OK をクリックします。

図 43 準備完了グラフ
ビューエディタでCPU 使用率 (%) 列をReady (us) [Sum] 列と置き換えます。
図 43 準備完了時刻のようなグラフを作成するために、関心のあるスレッドを選択します。

図 43 準備完了グラフ
この場合、スレッドはReady(準備完了) 状態でかなりの時間を費やしています。 その標準的な優先度を決定するには、Average 集計を NewInPri カラムに追加します。
この場合、スレッドの平均優先度はちょうど8です。 この数値は、おそらくバックグラウンドスレッドであり、優先度の昇格を受け取ることがないことを示しています。
平均優先度がわかったら、スレッドの実行が許可されているCPUのCPUアクティビティを見ます。
この場合、スレッドは CPU 1 のみにアフィニティを持っていると判断されました。
別のCPU 使用率(正確)グラフを追加し、CPU による使用率プリセットを適用します。 該当する CPU を選択します。
Advancedビューを開き、先ほど見つけた優先度のフィルタを追加して、そのスレッドをフィルタリングします。 このシナリオを図 44 スレッド フィルターに示します。
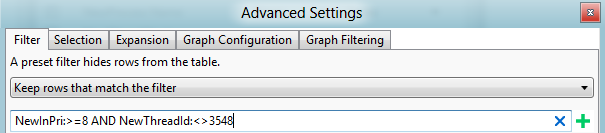
図 44 スレッド フィルター
図45 CPU使用率、レディタイム、その他のスレッドアクティビティにおいて、上のグラフはスレッド3548のCPU使用率を示しています。 真ん中のグラフはスレッドが準備できた時間、下のグラフはスレッドの実行が許可されているCPU(この場合はCpu1)のアクティビティを示しています。
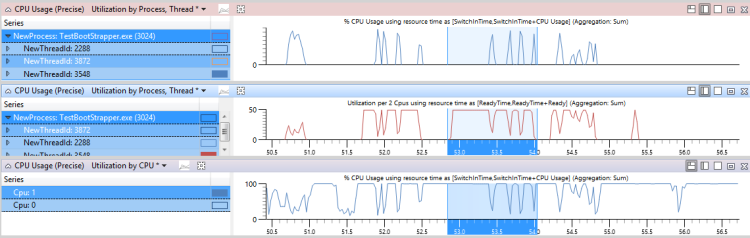
図 45 CPU 使用率、準備完了時間、その他のスレッドアクティビティ
その区間のほとんどの時間、スレッドの準備はできているが、実行されていない領域にズームインします。
CPU 使用率グラフで、NewInPriをバーの左に追加して、結果を調べます。
ターゲットスレッドの優先度と同じ優先度を持つスレッドまたはプロセスは、スレッドがスターブ餓状態にあった時間を示しています。 対象スレッドの優先度より高い優先度を持つスレッドまたはプロセスは、そのスレッドが割り込みされた時間を示します。 割り込まれたすべてのスレッドとアクションの時間を追加することで、スレッドが割り込まれた合計時間を計算できます。
図 46 Usage by Priority When Target Thread was Readyでは、スレッド時間の730msが割り込まれ、スレッド時間の300msがスターブされたことを示しています。 (この図は 1192ms 間隔にズームされます)。
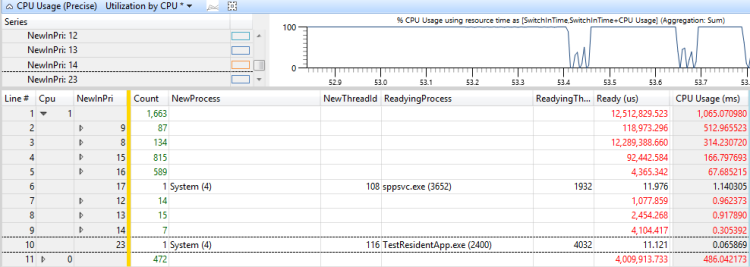
図 46 ターゲット スレッドの準備が完了した時の優先度別使用率
このスレッドの割り込みとスターブの原因がどのスレッドであるかを判断するには、NewProcess列をNewInPri列の右に追加し、プロセスが実行されていた優先度レベルを確認します。 この場合、割り込みとスターブは、主に同じプロセス内の別のスレッドと TestResidentApp.exe によって引き起こされています。 これらのプロセスは、基本的優先度よりも高い優先度を定期的に受け取っていると考えることができます。
解決方法
割り込みやスターブの問題は、設定やコンポーネントを変更することで解決することができます。 以下の対処法を検討してください。
問題のあるプロセスをシステムから削除します。
問題のあるプロセスの基本的優先度を調整する...
問題のあるプロセスの実行時間を変更します。例えば、コンピューターが再起動したときに開始するように時間を遅らせます。
問題のあるコンポーネントを変更できる場合は、CPUへの負荷が少ない、または低い優先順位で実行されるように再設計します。
DPC/ISRの干渉
DPCやISRの実行によりプロセッサの時間が過剰に消費されると、スレッドを実行するのに十分なCPU時間が残らない場合があります。 この状況は、スレッドの干渉と同様の遅延を引き起こす可能性があります。 ビデオ再生やアニメーションのように、スレッドが定期的に高い頻度で処理を完了する必要がある場合、DPCとISRによる干渉が動作上の問題を引き起こす可能性があります。
問題の特定
多くの評価では、DPC/ISR 関連の問題を特定するためにヒューリスティックを使用します。 DPC/ISRのアクティビティは、以下のような形で問題として報告された場合、疑わしいものとして識別されます。
DPC Dがmミリ秒の閾値をx回Pの間に超えています。このDPCのn個のインスタンスは、合計tミリ秒のために実行されます。
ここで、D は DPC、m は閾値を設定するミリ秒数、x は DPC が閾値を超えた回数、P は現在のプロセス、n は DPC が実行したインスタンスの数、t は DPC が閾値を超えたミリ秒の合計時間で実行されたことを表します。
例えば、次のような問題が評価で報告されています。
DPC sdbus.sys!SdbusWorkerDpc がメディアエンジンのライフタイム中に 153 回 3.0 ミリ秒の目標を超えました。 このDPCの153のインスタンスは、合計で864ミリ秒実行されます。
問題のあるイベントや遅延を示すアクティビティに対してこの問題が報告された場合、DPC/ISRアクティビティが原因である可能性があります。
DPC/ISRの干渉を手動で特定する
DPC/ISR 干渉を手動で特定するには、WPA でトレースを開き、関心のある問題イベントを特定します。 これらは Microsoft-Windows-Dwm-Core:SCHEDULE_GLITCH や Microsoft-Windows-MediaEngine:DroppedFrame などの評価固有の一般的なイベントです。
イベントのグラフの横に CPU 別の DPC/ISR 期間グラフを追加 します。 DPC/ISR Duration by CPUグラフのピークが問題イベントと一緒に表示されている場合は、DPC/ISR が問題の原因となる可能性があります。
追加データとして、いくつかの問題イベントが表示される100ms前に発生する時間帯にズームインします。 問題イベントが発生する100ms前の領域で、1つまたは複数のプロセッサに重要なDPC/ISRアクティビティが表示された場合、問題イベントはDPC/IRSアクティビティが原因であると結論付けることができます。
DPC/ISRの干渉が原因で遅延が発生しているかどうかを判断するには、実行中のスレッドが表示されている領域にズームします。 このスレッドが実行されている CPU または CPU をメモします。
DPC/ISR グラフで、DPC/ISR Duration by CPU プリセットを適用し、その時間範囲内の関連 CPU の DPC/ISR アクティビティを表示します。
図47 問題のあるイベントとDPC/ISRアクティビティは、iexplore.exeのスレッド864が影響を受けるアクティビティに関連していることを示しています。 スレッド 864 は CPU2 の実行中状態で、ビューの時間範囲の 10.65% を占めます。 ただし、DPC/ISR グラフは、CPU2 が、その時間の 10% の DPC/ISR の実行でビジー状態だったと示しています。
ノート ほとんどのDPC/ISRは、この例で示されたほど高い影響を与えません。
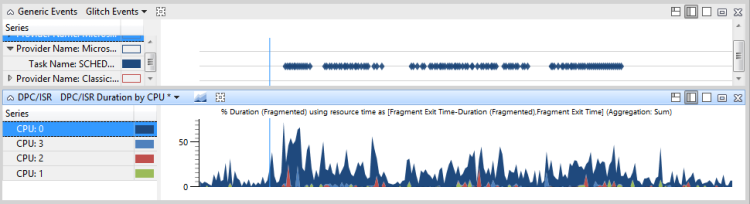
図 47 Problem Events and DPC/ISR Activity
図 48 DPC/ISR 問題イベントに関連しない場合、DPC/ISR はパフォーマンス上の問題に関連していないと示されます。
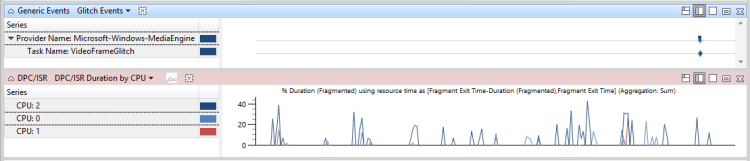
図 48 問題事象と無関係なDPC/ISR
図 49 では、DPC/ISR 干渉による遅延では、パフォーマンスの問題を引き起こす DPC/ISR が示されています。
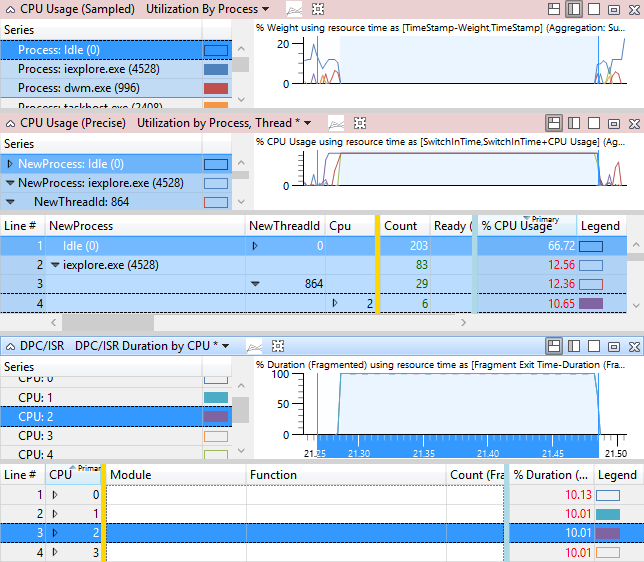
図 49 DPC/ISR 干渉による遅延
調査
DPC/ISR が問題や遅延に関係していると判断した場合、具体的にどの DPC/ISR が関係しているのか、なぜそれが頻繁に発生するのか、または過剰に長く動作するのかを特定する必要があります。
テクニック 評価で報告された DPC/ISR 問題をレビューする。
評価レポートされたDPC/ISR問題では、DPCまたはISRによって割り込まれる主要なプロセスを表示する問題を展開することができます。 影響を受けたアクティビティに最も関連するプロセスの DPC アクティビティを表示するには、スタックを展開し、DPC が何を行っていたかを理解します。 図 50 Expanded DPC Stack は、拡張されたスタックを示しています。
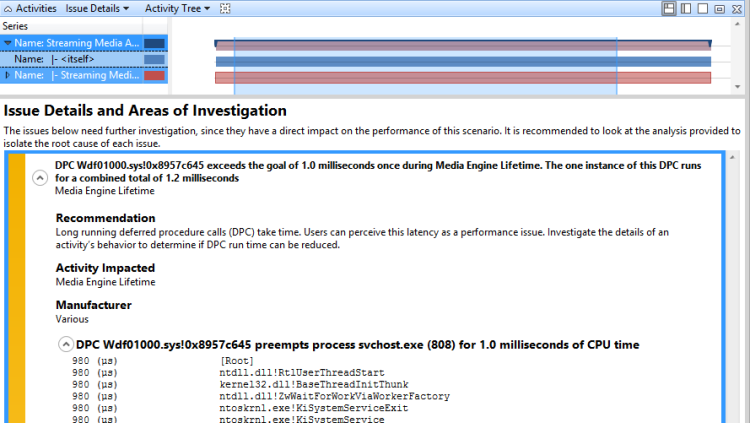
図 50 拡張 DPC スタック
テクニック 最も持続時間の長い DPC/ISR を見つけ、スタックを見直す。
評価で DPC/ISR が問題と報告されなかった場合、DPC/ISR および CPU Usage (Sampled) グラフを使用して、最も関連性の高い DPC のスタック情報を取得することができます。 関心のある DPC/ISR を見つけ、そのモジュールと関数をメモしてから CPU 使用率 (サンプリング) グラフでサンプルを見つけて、完全なスタック情報を取得することをお勧めします。
高持続時間の DPC/ISR を見つけ、スタックを確認する 。
関心のある間隔にズームします。
DPC/ISRグラフで、プリセットDPC/ISR Duration by Module, Functionを選択します。
シンボルがロードされている場合、DPC/ISRイベントは総時間でソートされ、その後モジュールと機能で分解されます。 リストの一番上の行には、おそらくイベントの問題を引き起こした DPC/ISR イベントが含まれています。 モジュール名と関数名をメモしておいてください。
CPU 使用率(サンプリング)グラフで、プロセス別の使用率プリセットを選択します。 デフォルトでは、このプリセットは DPC/ISR アクティビティを非表示にします。
ビューエディタ を開き、詳細設定 をクリックします。
フィルタ タブで、フィルタに一致する行を隠すの設定をフィルタに一致する行を残すに変更します。 これにより、DPC/ISR のアクティビティが表示されるようになります。
Process カラムを削除し、Stack カラムを追加して DPC/ISR をスタックでソートして表示します。
現在の行の選択を解除します。
スタック列のセルを右クリックし、この列の検索をクリックします。
この手順のステップ 2 でメモしたモジュールと関数を入力します。
現在の選択範囲に追加 をチェックし、すべて検索 をクリックして関数のすべてのインスタンスを選択します。
すべての行が選択されたら、右クリックしてButterfly/View Calleesをクリックします。
このビューには、この特定の関数のアクティビティが、総所要時間でソートされて表示されます。 このビューは、アセスメントで報告された課題の詳細ビューのスタック表示と似ています。 cぷ重み列は、スタック上で各関数が費やした包括的な時間をミリ秒単位で概算しています。
このビューは、図 51「おおよその期間で並べ替えされた DPC の呼び出し者」に示されています。

図 51 DPC のキャリーをおおよその時間順に並べたもの。
テクニック 長時間稼働しているDPC/ISRを見直す。
DPC/ISRの総所要時間も重要ですが、個々のDPC/ISRが長時間稼働していると、遅延の原因になりやすいのです。 DPC/ISR グラフでは、包括継続時間 (ミリ秒) 列に、降順にソートして、個々の DPC/ISR の最大継続時間が表示されます。 一部の評価プロファイルで利用可能なプリセット Long DPC/ISR では、このビューをフィルタリングして、1ミリ秒 を超える包括的な継続時間を持つ DPC/ISR のみを表示することができます。
ノート このプリセットが利用できない場合、ビュー エディタの詳細セクションを開いてフィルタを追加することができます。
解決方法
DPC/ISRのアクティビティは、多くの場合ハードウェアまたはソフトウェアの問題を反映しており、ハードウェアまたはコンポーネントレベルで修正する必要があります。 構成レベルでは、ハードウェアを交換するか、関連するドライバーを固定バージョンにアップグレードできます。 コンポーネント レベルでは、ハードウェアとドライバーは MSDN の DPC/ISRs のベスト プラクティスに従う必要があります。また、可能な場合はスレッド DPC を使用する必要があります。 スレッド化された DPC は、Windows のクライアント エディションではディスパッチ レベルで実行されません。 DPC/ISR のベスト プラクティスの詳細については、「ISR と DPC の動作に関するガイドライン」と「スレッド DPC の概要」を参照してください。
関連トピック
電源管理と ACPI - アーキテクチャとドライバーのサポート
Windows Vista および Windows Server 2008