組織データをアップロードする (後続のアップロード)
組織のデータが高度な分析情報アプリに既にアップロードされている場合、管理者は、この記事の情報を使用して、次のことができます。
- 既存のデータを編集する
- 既存のデータを置き換える
- 既存のデータから組織の属性と従業員を削除する
「組織データの準備」の説明に従ってデータを準備した後、これらの手順 を完了します。
重要
組織のデータを初めてアップロードしない場合にのみ、次の手順に従ってください。 これが初めてのアップロードの場合は、「 組織データのアップロード (最初のアップロード)」の手順に従います。
従来のアプリから引き継がれるお客様:
従来の高度な分析情報アプリから移行する場合、レガシ アプリにアップロードしたデータは、新しいアプリで自動的に使用できるようになります。 新しいアプリを使用してデータをアップロードし始めたら、ここにそれ以降のすべてのアップロードを行います。 新しいアプリを引き続き使用すると、データの不整合が防止されます。
ワークフロー
ソース データを準備した後、アップロード プロセスは次の手順に従います。この手順については、次のセクションで説明します。
.csv ファイルをアップロードします。
フィールドをマップします。
アプリによってデータが検証されます。 (検証が成功しない場合は、「 検証に失敗する」で説明されているいくつかのオプションから選択できます)。
アプリによってデータが処理されます。 (処理が成功しない場合は、「 処理が失敗する」で説明されているいくつかのオプションから選択できます)。
データの検証と処理が正常に完了すると、データのアップロード タスク全体が完了します。
データを更新、置換、または削除するには
3 つのアクションはすべて、同じ 2 つの最初の手順を共有します。
[データ ハブ] タブの [スタート] ボタンまたは [データ接続] タブの [データ ソースの管理] ボタンを選択します。
![[データ ソースの管理] ボタンを示すスクリーンショット。](../images/data-quality-manage-data.png)
結果のページには、次の 4 つのオプションが一覧表示されます。
- データの追加または編集
- 省略可能なフィールドを削除する
- 従業員データを削除する
- すべてのデータを置き換える
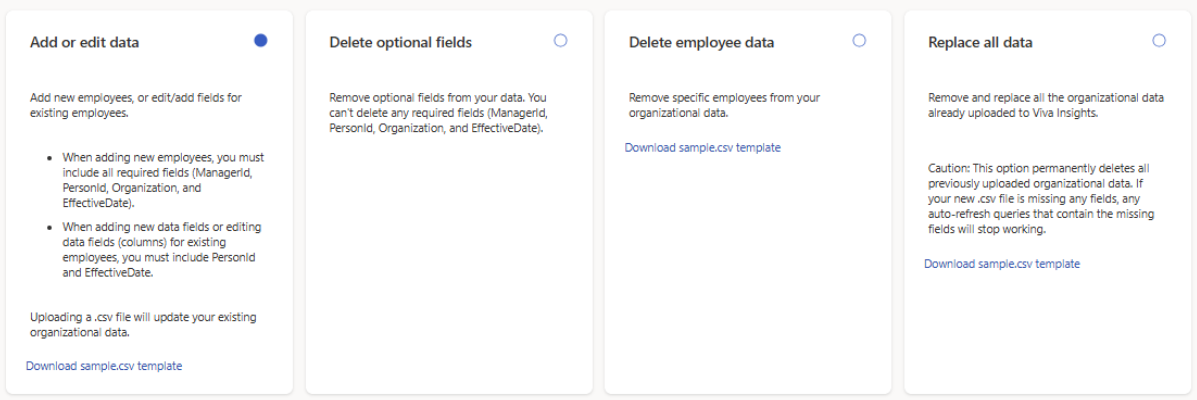
実行する内容に基づいて選択を行い、手順 3 の下の対応するセクションに移動します。
アクション Section 注釈 新しい従業員 (行) を追加する 既存の組織データを更新する ファイルには、すべての必須フィールド (PersonId、 ManagerId、 および Organization) とその他の省略可能なフィールドが含まれている必要があります。 新しいフィールド (列) を追加する 既存の組織データを更新する ファイルには 、PersonId やその他の省略可能なフィールドを含める必要があります。 フィールドの編集 (列) 既存の組織データを更新する ファイルには 、PersonId やその他の省略可能なフィールドを含める必要があります。 属性を削除する 既存の組織データから省略可能なフィールドを削除する 削除できるのは省略可能な属性のみです。 自動参照クエリで使用されるフィールドを削除すると、それらのクエリは無効になります。 既存のすべての組織データを置き換える 既存のデータを置き換える このオプション は、過去に アップロードしたすべての組織データを完全に削除します。 ファイルにフィールドがない場合、それらのフィールドを使用するクエリの自動参照は無効になります。 組織データから従業員を削除する 既存の組織データから特定の従業員を削除する このオプションを使用すると、.csv ファイルを使用して、組織のデータから特定の従業員を削除できます。
既存のデータを更新して置き換える
既存のデータを更新する
ファイルのアップロード
[ ファイルのアップロード] で、アップロードするファイルを選択し、[ 次へ] を選択します。
これで、フィールドをマップする準備ができました。 次の手順については、 フィールド マッピングに関するページを参照してください。
例: 新しいデータ列の追加
たとえば、従業員ごとに新しいエンゲージメント スコア値をアップロードするとします。 推奨される 13 か月以上のスナップショット データ (すべての従業員に必要な列を含む) を既にアップロードしました。ここで、エンゲージメント スコアの値をすべての履歴データに適用します。 [ 既存の組織データの更新 ] オプションを選択します。 新しい EngagementScore データ列をアップロードするには、それを含むファイルをアップロードする必要があります。
組織属性を編集するための重要な手順
過去の属性を編集する場合は、更新された値が正しい期間に適用されるように、.csv ファイルに正しい EffectiveDates を持つ更新された値を含める必要があります。
たとえば、Viva Insights内の組織データのこの初期状態を考えてみましょう。
| StartDate | EndDate | PersonId | ManagerId | BadgeData | コメント |
|---|---|---|---|---|---|
| 01/01/0001 | 09/01/2023 | W@contoso.com | R@contoso.com | - | この期間では、BadgeData は - です |
| 09/01/2023 | 09/08/2023 | W@contoso.com | R@contoso.com | 102 | この期間、BadgeData は 102 です |
| 09/08/2023 | 12/31/9999 | W@contoso.com | R@contoso.com | 106 | この期間では、BadgeData は 106 です |
このシナリオでは、2023 年 9 月 6 日から ManagerId 値を編集し、新しい値を今後無期限に適用する場合は、過去のすべての増分アップロードから 09/06/2023 以降のすべての EffectiveDate の ManagerId を更新する必要があります(ManagerId フィールドがそれらの増分アップロードの一部ではない場合でも)。
そのため、新しいアップロードは次のようになります。
| EffectiveDate | PersonId | ManagerId |
|---|---|---|
| 09/06/2023 | W@contoso.com | D@contoso.com |
| 09/08/2023 | W@contoso.com | D@contoso.com |
そのアップロードにより、組織のデータは次のようになります。 2023 年 9 月 6 日と 2023 年 9 月 8 日の両方で、ManagerId が "D" に更新されたことに注意してください。
| StartDate | EndDate | PersonId | ManagerId | BadgeData | コメント |
|---|---|---|---|---|---|
| 01/01/0001 | 09/01/2023 | W@contoso.com | R@contoso.com | - | |
| 09/01/2023 | 09/06/2023 | W@contoso.com | R@contoso.com | 102 | |
| 09/06/2023 | 09/08/2023 | W@contoso.com | D@contoso.com | 102 | この行は追加されましたが、既存の将来のエントリがあるため、EndDate は 2023 年 9 月 8 日です。 |
| 09/08/2023 | 12/31/9999 | W@contoso.com | D@contoso.com | 106 |
または、別のシナリオを想像してみましょう。 2023 年 9 月 6 日から 2023 年 9 月 8 日までの日付に対してのみ ManagerId を変更する場合は、次のアップロードになります。
| EffectiveDate | PersonId | ManagerId |
|---|---|---|
| 09/06/2023 | W@contoso.com | D@contoso.com |
そのアップロード後、組織のデータは次のようになります。 2023 年 9 月 8 日以降も、2023 年 9 月 8 日に過去のエントリに変更が加えられなかったため、ManagerId は "R" のままであることに注意してください。
| StartDate | EndDate | PersonId | ManagerId | BadgeData | コメント |
|---|---|---|---|---|---|
| 01/01/0001 | 09/01/2023 | W@contoso.com | R@contoso.com | - | |
| 09/01/2023 | 09/06/2023 | W@contoso.com | R@contoso.com | 102 | |
| 09/06/2023 | 09/08/2023 | W@contoso.com | D@contoso.com | 102 | この行は追加されましたが、既存の将来のエントリがあるため、EndDate は 2023 年 9 月 8 日です。 |
| 09/08/2023 | 12/31/9999 | W@contoso.com | R@contoso.com | 106 |
最後に、EffectiveDate フィールドの以前の値を覚えていない場合は、編集する必要がある列を削除し、更新された値で列をもう一度アップロードする必要があります。 または、編集する必要がある列が複数ある場合は、過去のすべてのデータを更新された値で新しいアップロードに置き換えることもできます。
既存のデータを置き換える
ファイルのアップロード
アップロード名を入力します。
[ ファイルのアップロード] で、アップロードする .csv ファイルを選択します。
.csv ファイルが次であることを確認します。
UTF-8 エンコード
アップロード プロセスを開始するときに別のプログラムで開かない
[
![準備とアップロード] ウィンドウを示す 1 GB 以下のスクリーンショット。](../images/admin-prepare-upload.png)
注:
.csv ファイルの構造とガイドラインを確認し、アップロード中の一般的な問題を回避するには、[テンプレートの ダウンロード] リンク .csv 使用してテンプレートをダウンロードできます。
[次へ] を選択してファイルをアップロードします。 アップロードを取り消す必要がある場合は、[キャンセル] を選択 します。
これで、フィールドをマップする準備ができました。 次の手順については、 フィールド マッピングに関するページを参照してください。
既存の組織データから省略可能なフィールドを削除する
- 後で参照できるように、削除アクションに名前を付けます。
- 削除する属性を特定し、対応するボックスチェックします。
- 結果の画面には、削除された属性が一覧表示されます。 [ 戻る ] を選択してデータ ハブに戻ります。
削除プロセスが完了しました。
重要
次のセクションは、 アクションのアップロード と 置換 にのみ適用されます。
既存の組織データから従業員とデータを削除する
このオプションを選択すると、不要になった組織データを削除したり、従業員の履歴データを削除したりして、クリーンスレートでデータを編集できます。 従業員を削除した後、新しいファイルをアップロードして、削除した従業員の新しいデータを追加できます。
ファイルをアップロードする方法
削除する従業員の名前を含む .csv ファイルを作成します。 このファイルには、"PersonId" という名前の列と、その列の各行に削除する各ユーザーのメール アドレスが含まれている必要があります。 ガイダンスについては、 このテンプレート ファイルを使用してください。 .csv ファイルが次であることを確認します。
- UTF-8 エンコード
- アップロード プロセスを開始するときに別のプログラムで開かない
- 1 GB 以下
[削除] アクション名を入力します。
[ 削除する従業員と一緒にファイルをアップロードする] で、.csv ファイルを選択します。
ファイルをアップロードするには、[送信] を選択 します。 アップロードを取り消すには、[キャンセル] を選択 します。
[ インポート履歴] テーブルには、削除の状態が表示されます。
- ダウンロード アイコンを選択して、操作によって削除された従業員の一覧をダウンロードします。 ダウンロード リンクには最大 30 日間アクセスできます。
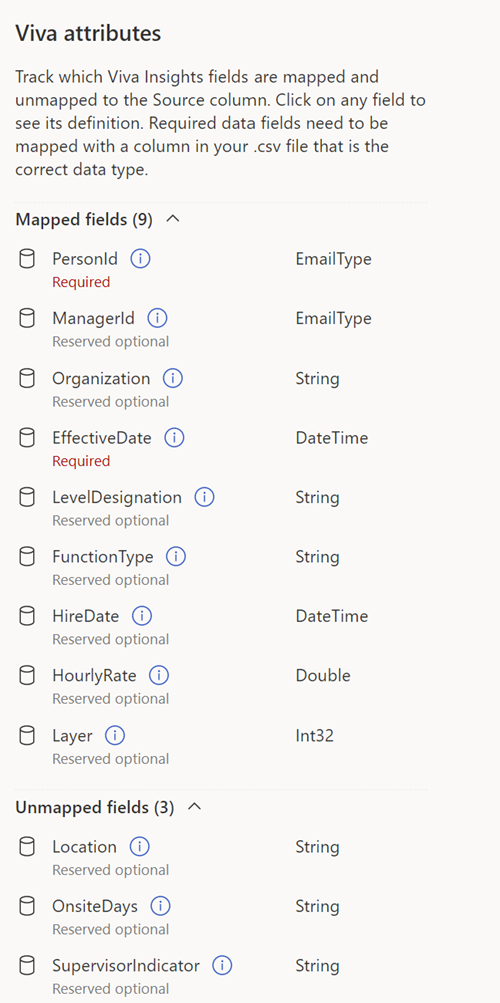
フィールドのマッピング
ファイルをアップロードすると、フィールド マッピング ページが表示されます。 データから分析情報を表示するには、.csv ファイルのフィールド (列) を、アプリが認識するフィールド名にマップする必要があります。
フィールドには、 システムの既定値 と カスタムの 2 種類があります。
システムの既定値 (必須または省略可能)
システムの既定のフィールドは、PersonId、ManagerId、Organization のいずれか、または省略可能です。 これらの必須フィールドと省略可能なフィールドは、グループ化やフィルター処理以外の特定の計算で使用Viva Insights属性を表します。
重要
すべての必須フィールドには、すべての行に有効な null 以外の値が必要です。 .csv ファイル内の列ヘッダーがViva Insights値名と完全に一致しない場合でも、必要なすべてのViva Insights値をマップする必要があります。
省略可能なフィールドは、アプリが使用を提案する一般的なシステム フィールドです。 organizationにデータがない場合は、省略可能なフィールドをマップする必要はありません。
フィールドが必須か省略可能かを確認するには、マッピング リストの右側にあるViva属性セクションを参照してください。 必須の属性には "必須" ラベルがあり、省略可能な属性には "省略可能" ラベルがあります。
カスタム
カスタム フィールドは、作成できるオプションの属性です。 次のセクションの手順 5a では、カスタム属性をマップして名前を付ける方法について説明します。
フィールドをマッピングするには
次の手順に従って、.csv データをViva Insights属性にマップします。
重要
[ ソース列名] の下に表示されるすべての .csv ヘッダー フィールドは、アップロード プロセスの次の部分に進む前にマップする必要があります。
必須のViva Insightsフィールドごとに、次の手順を実行します。
[ソース列名] で対応する 列ヘッダーを見つけます。 後で検証エラーが発生しないようにするには、この列が適切なデータ型であることを確認します。
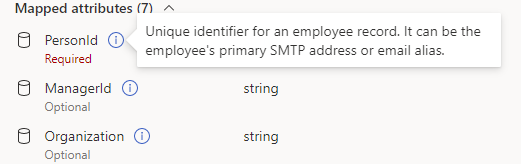
[Map to Viva Insights field column] でドロップダウン リストを開き、手順 a で指定した列ヘッダーに対応するViva Insights属性を選択します。

ヒント
属性名にカーソルを合わせると、その説明が読み上げられます。
データ を更新する 場合は、追加した新しい列または変更した列ヘッダーのみを表示するように選択できます。 これを行うには、[ 無効なフィールドのみを表示 する] トグルを選択します。
カスタム フィールドと省略可能なフィールドに対して手順 4a と 4b を繰り返します。
- ユーザー設定フィールドを追加するには、データ ファイルに列として含めるだけです。 アプリによって自動的に名前が割り当てられ、マップされます。 Viva Insightsのこのリリースでは、すべてのカスタム属性に既定の名前が割り当てられ、String データ型としてのみ分類できます。
重要
TimeZone を列としてアップロードしないでください。 エラーが発生します。
- ユーザー設定フィールドを追加するには、データ ファイルに列として含めるだけです。 アプリによって自動的に名前が割り当てられ、マップされます。 Viva Insightsのこのリリースでは、すべてのカスタム属性に既定の名前が割り当てられ、String データ型としてのみ分類できます。

フィールドをマップした後、アプリは、次のセクションで説明するようにデータを検証して処理します。 検証と処理が成功した場合、アップロード プロセスへの入力は完了です。
予期される列がないか除外されている場合
クエリを正常に実行するには、特定の属性 (列) が組織データに存在する必要があります。 この要件は、自動更新オプションがオンになっているクエリにも当てはまります。 クエリで使用される属性 (列) がデータのアップロードに含まれていない場合、アプリから警告が表示されます。 属性フィールドとそのフィールドが使用されているクエリを一覧表示するテーブルと、警告メッセージが表示されます。"続行すると、これらのクエリが無効になります。 関数の進行中にこれらのフィールドを含む自動更新クエリが作成された場合、そのクエリも無効になります。
不足している属性を確認した後:
- データのアップロードまたは置換を続行しない場合は、[キャンセル] を選択 します。 このボタンをクリックすると、フィールド マッピング ページに戻ります。
- 属性が見つからない場合でもデータのアップロードを続行する場合は、[ 次へ] を選択します。 この選択により、上記のクエリの自動更新がオフになります。 これらのクエリの最後の実行の結果には引き続きアクセスできます。
Validation
属性をマップすると、アプリはデータの検証を開始します。
ほとんどの場合、ファイルの検証は迅速に完了する必要があります。 組織のデータ ファイルが大きい場合、検証には最大 1 分または 2 分かかることがあります。
このフェーズが完了すると、検証は成功または失敗します。
次に何が起こるかについては、適切なセクションに移動します。
検証成功
検証が成功すると、Viva Insightsは新しいデータの処理を開始します。 処理には数時間から 1 日かかる場合があります。 処理中に、[アップロードまたは削除中] テーブルの [データ接続] > [処理] 状態が表示されます。
処理が完了すると、成功または失敗します。 結果に応じて、[ データ接続 ] 画面の右上隅に成功通知または失敗通知が表示されます。
処理が成功する
処理が成功すると、[ アップロードまたは削除履歴 ] テーブルに "成功" 状態が表示されます。 この時点で、アップロード プロセスは完了です。

組織データが次のエクスペリエンスにアップロードされた後に反映されるために必要な一般的な時間を次に示します。
[データ接続] > [インポート履歴] に表示される成功状態: 数時間
[データ品質] タブ、柔軟なクエリ、Power BI テンプレート: 1 日から 2 日
Teams アプリのリーダー/マネージャー レポート: 次回の毎週更新
"成功" 状態を受け取ると、次のことができます。
検証結果の概要を表示するには、ビュー (目) アイコンを選択します。

マッピング アイコンを選択すると、ワークフローのマッピング設定が表示されます。

注:
各テナントは、一度に 1 つのアップロードのみを実行できます。 1 つのデータ ファイルのワークフローを完了する必要があります。つまり、次のデータ ファイルのワークフローを開始する前に、検証と処理の成功に導くか、破棄します。 アップロード ワークフローの状態またはステージは、[ データ接続 ] タブに表示されます。
処理が失敗する
処理が失敗した場合は、[ アップロードまたは進行中の削除 ] テーブルに失敗した状態が表示されます。 状態でリンクを選択すると、エラーの説明が表示されます。
[ 編集] を選択するか、新しいアップロードを開始します。 このボタンを使用すると、前にアップロードしたデータ ファイルに対して次のことを実行できます。
- 編集して、新しい行または列を追加します。
- 属性を削除します。
- 既存のファイルを新しいファイルに置き換えます。
注:
処理エラーは通常、バックエンド エラーが原因です。 永続的な処理エラーが発生し、アップロードしたファイル内のデータを修正した場合は、サポート チケットを Microsoft に記録してください。
検証失敗
データの検証が失敗した場合は、"検証に失敗しました" エラーとエラーに関するいくつかの情報を含む新しい画面が表示されます。 アップロード プロセスを続行しない場合は、[ アップロードのキャンセル] ボタンを選択できます。
ソース ファイルを変更してアップロードを再試行する前に、[ 問題のダウンロード] を選択できます。 このログ ファイルには、検証エラーの原因となった可能性のあるデータの問題が記述されています。 この情報を使用して、次に何を行うかを決定します。ソース データを修正するか、マッピング設定を変更します。
データのエラーを修正するガイドライン
任意のデータ行または列に属性に無効な値がある場合、ソース ファイルを修正するまで (または属性マッピングを修正するまで) アップロード全体が失敗します。
エラーを防ぐためのファイルの書式設定については、「 ファイルルールと検証エラー」を参照してください。