Always On 可用性グループでの復旧キューのトラブルシューティング
この記事では、復旧キューに関連する問題の解決策について説明します。
復旧キューとは
可用性グループ データベース内のプライマリ レプリカに加えられた変更は、同じ可用性グループで定義されているすべてのセカンダリ レプリカに送信されます。 これらの変更がセカンダリ レプリカに到着した後、まず可用性グループ データベースのトランザクション ログ ファイルに書き込まれます。 次に、Microsoft SQL Server は、 recovery または redo 操作を使用してデータベース ファイルを更新します。
可用性グループに対する変更がデータベース トランザクション ログ ファイルに到着し、復旧できるよりも速く書き込まれると、 回復キュー が形成されます。 このキューは、書き込まれたトランザクション ログ トランザクションのうち、回復されず、データベースに復元もされなかったもので構成されています。
回復 (やり直し) キューの症状と影響
プライマリ レプリカとセカンダリ レプリカのクエリを実行すると、異なる結果が返される
セカンダリ レプリカにクエリを実行する読み取り専用ワークロードでは、古いデータに対してクエリを実行する可能性があります。 復旧キューが発生した場合、同じデータを照会するときに、プライマリ レプリカ データベース上のデータに対する変更がセカンダリ データベースに反映されない可能性があります。
変更はセカンダリ データベースに到着し、データベース ログ ファイルに書き込まれますが、変更は復旧されてデータベース ファイルに復元されるまでクエリされません。 回復操作によって、これらの変更が読み取り可能になります。
詳細については、「Always On 可用性グループの可用性モードの違い」のセカンダリ レプリカでの Data 待機時間に関するセクションを参照してください。
フェールオーバー時間が長いか、RTO を超えています
目標復旧時間 (RTO) は、組織が処理できるデータベースの最大ダウンタイムです。 RTO では、停止後に組織がデータベースへのアクセスを回復できる速度についても説明します。 フェールオーバーの発生時にセカンダリ レプリカに大量の復旧キューが存在する場合、復旧に時間がかかる場合があります。 復旧後、データベースはプライマリ ロールに移行し、フェールオーバー前に存在していたデータベースの状態を表します。 復旧時間が長くなると、フェールオーバー後に運用環境が再開する速度が遅れる可能性があります。
可用性グループの復旧キューに関するさまざまな診断機能レポート
復旧キューの場合、SQL Server Management Studio (SSMS) の Always On ダッシュボードで異常な可用性グループが報告される場合があります。
復旧 (再実行) キューを確認する方法
復旧キューは、プライマリ レプリカの Always On ダッシュボードを使用するか、プライマリ レプリカまたはセカンダリ レプリカの sys.dm_hadr_database_replica_states 動的管理ビュー (DMV) を使用して、データベースごとの測定を確認できます。 パフォーマンス モニター カウンターは、回復キューと回復率を確認します。 これらのカウンターは、セカンダリ レプリカに対してチェックする必要があります。
次のいくつかのセクションでは、可用性グループ データベース復旧キューをアクティブに監視する方法について説明します。
クエリ sys.dm_hadr_database_replica_states
sys.dm_hadr_database_replica_states DMV は、可用性グループ データベースごとに 1 行を報告します。 レポート内の 1 つの列が redo_queue_size。 この値は、KB 単位で測定された回復キューのサイズです。 次のクエリのようなクエリを設定して、30 秒ごとに回復キュー サイズの傾向を監視できます。 クエリはプライマリ レプリカで実行されます。 redo_queue_sizeとredo_rateが関連するセカンダリ レプリカのデータをレポートするには、is_local=0述語を使用します。
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
出力の外観を次に示します。

Always On ダッシュボードで回復キューを確認する
回復キューを確認するには、次の手順に従います。
SSMS オブジェクト エクスプローラーの可用性グループを右クリックして、SSMS の Always On ダッシュボードを開きます。
[ダッシュボードの表示] 選択。
可用性グループ データベースは最後に一覧表示され、データベースに関していくつかのデータが報告されます。 Redo Queue Size (KB)と Redo Rate (KB/sec)) は既定では表示されませんが、次の手順のスクリーンショットに示すように、このビューに追加できます。
これらのカウンターを追加するには、データベース レポートの上にあるヘッダーを右クリックし、使用可能な列の一覧から選択します。
Redo Queue Size (KB)と Redo Rate (KB/sec)を追加するには、次のスクリーンショットで赤で強調表示されているヘッダーを右クリックします。

既定では、Always On ダッシュボードは Redo Queue Size (KB) と Redo Rate (KB/sec) を 60 秒ごとに自動更新します。



パフォーマンス モニターで回復キューを確認する
回復キューのサイズは、各セカンダリ レプリカとデータベースに固有です。 そのため、可用性グループ データベースの復旧キューを確認するには、次の手順に従います。
セカンダリ レプリカでパフォーマンス モニターを開きます。
追加 (カウンター) ボタンを選択します。
Available カウンターで、SQLServer:Database Replica を選択し、Recovery Queue と Redone Bytes/sec カウンターを選択します。
Instance リスト ボックスで、復旧キューを監視する可用性グループ データベースを選択します。
[追加]>[OK] の順に選択します。
復旧キューの増加は次のようになります。
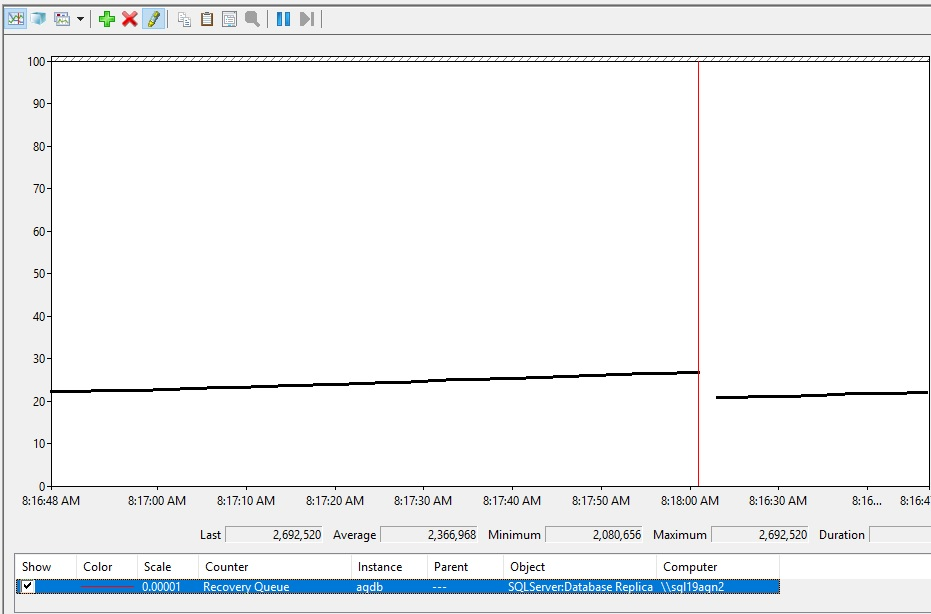

リカバリー・キュー値の解釈
このセクションでは、前のセクションで決定した復旧キューに関連する値を解釈する方法について説明します。
復旧キューに問題があるのはいつですか? どの程度の回復キューに入れますか?
復旧キューが 0 の値を報告している場合、そのレポートの時点で復旧キューが発生していないと想定する場合があります。 ただし、運用環境がビジー状態の場合は、正常な AlwaysOn 環境であっても、復旧キューが 0 以外の値を頻繁に報告することを想定する必要があります。 一般的な運用環境では、この値が 0 から 0 以外の値の間で変動することを想定する必要があります。
時間の経過と伴う復旧キューの増加を確認した場合は、さらなる調査が必要です。 この追加アクティビティは、何かが変更されたことを示します。 回復キューが急激に増加する場合は、次の測定値がトラブルシューティングに役立ちます。
- Log Redo Rate (KB/sec) (AlwaysOn ダッシュボード)
- DMV sys.dm_hadr_database_replica_statesのRedo_rate
やり直し率のベースライン レートを取得する
正常な AlwaysOn パフォーマンス中に、ビジー状態の可用性グループ データベースの再実行率を監視します。 一般的に忙しい営業時間中はどのように表示されますか? 大規模なトランザクション (インデックスの再構築、ETL プロセス) によってシステムのトランザクション スループットが高くなる場合、メンテナンス期間中のこれらのレートは何ですか? 回復キューの増加を観察するときにこれらの値を比較して、何が変更されたかを判断できます。 ワークロードが通常より大きい場合があります。 やり直し率が低い場合は、理由を判断するためにさらに調査が必要になる場合があります。
ワークロードボリュームが重要
大規模なワークロード (100 万行に対する UPDATE ステートメント、1 テラバイト テーブルでのインデックスの再構築、数百万行を挿入している ETL バッチなど) がある場合は、すぐにまたは時間の経過と同時に、復旧キューの増加が予想されます。 これは、可用性グループ データベースで大量の変更が突然行われる場合に想定されます。
復旧 (再実行) キューを診断する方法
特定のセカンダリ レプリカ可用性グループ データベースの復旧キューを特定した後、セカンダリ レプリカに接続し、 sys.dm_exec_requests クエリを実行して、復旧スレッドの wait_type と wait_time を確認します。 ループ内で実行できるクエリを次に示します。 1 つ以上の待機の種類の高い頻度と、それらの待機の種類の待機時間を探しています。 1 秒ごとに実行され、可用性グループ "agdb" の待機の種類と待機時間を報告するサンプル クエリを次に示します。
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
重要
意味のある待機の種類の出力では、前に説明したいずれかの方法を使用してこの状態を監視するときに、回復キューが増加していることを確認する必要があります。
この例では、一部の I/O 関連の待機の種類が報告されます (PAGEIOLATCH_UP、 PAGEIOATCH_EX)。 次の列で報告されているように、これらの待機の種類が最大の wait_times 値を引き続き持っているかどうかを確認するために監視します。

SQL Server 再実行待機の種類
待機の種類が特定されたら、次の記事「 SQL Server 2016/2017: 可用性グループセカンダリ レプリカの再実行モデルとパフォーマンス - Microsoft Tech Community 回復キューを引き起こす一般的な待機の種類の相互参照として、問題を解決するためのヘルプを参照してください。
セカンダリ レポート サーバー上のブロックされた再実行スレッド
ソリューションがセカンダリ レプリカ上の可用性グループ データベースに対してレポート (クエリ) を実行する場合、これらの読み取り専用クエリはスキーマの安定性 (Sch-S) ロックを取得します。 これらの Sch-S ロックは、再実行スレッドがスキーマ変更 (Sch-M) ロック ("スキーマ変更ロック" または LCK_M_SCH_M とも呼ばれます) を取得して、 ALTER TABLE や ALTER INDEXなどのデータ定義言語 (DDL) の変更を行うのをブロックできます。 ブロックされた再実行スレッドは、ブロックが解除されるまでログ レコードを適用できません。 これにより、復旧キューが作成される可能性があります。
ブロックされたやり直しの履歴証拠を確認するには、SSMS を使用してセカンダリ レプリカ上の AlwaysOn_health Xevent トレース ファイルを開きます。 lock_redo_blockedイベントを探します。

パフォーマンス モニターを使用して、回復キューへのブロックされた再実行の影響をアクティブに監視します。 SQL Server::D atabase Replica::Redo blocked/sec および SQL Server::D atabase Replica::Recovery Queue カウンターを追加します。 次のスクリーンショットは、セカンダリ レプリカ上の同じテーブルに対して実行時間の長いクエリが実行されている間にプライマリ レプリカに対して実行される ALTER TABLE ALTER COLUMN コマンドを示しています。 Redo blocked/sec カウンターは、ALTER TABLE ALTER COLUMN コマンドが実行されたことを示します。 実行時間の長いクエリがセカンダリ レプリカ上の同じテーブルで実行されている間は、プライマリで後続の変更が行われると、復旧キューが増加します。

再実行スレッドが取得しようとするスキーマ変更ロック待機の種類を監視します。 これを行うには、前に説明したクエリを使用して、 sys.dm_exec_requestsに対する再実行操作について報告される待機の種類を確認します。 進行中の再実行ブロックの LCK_M_SCH_M の待機時間が長くなっているのを確認できます。

シングル スレッドやり直し
SQL Server では、Microsoft SQL Server 2016 でセカンダリ レプリカ データベースの並列復旧が導入されました。 SQL Microsoft Server 2012 または Microsoft SQL Server 2014 の実行時に復旧キューが発生している場合は、プログラムの新しいバージョンにアップグレードして、運用環境での再実行のパフォーマンスを向上させることができます。
シングル スレッドの再実行は、並列復旧アーキテクチャが使用される、より高度な SQL Server バージョンでも発生する可能性があります。 これらのバージョンでは、SQL Server インスタンスは並列再実行に最大 100 個のスレッドを使用できます。 プロセッサ数と可用性グループ データベースの数に応じて、並列再実行スレッドは最大 100 個の合計スレッドに割り当てられます。 100 スレッドの再実行の制限に達した場合、可用性グループ内の一部のデータベースには 1 つの再実行スレッドが割り当てられます。
可用性グループ データベースが並列復旧を使用しているかどうかを確認するには、セカンダリ レプリカに接続し、次のクエリを使用して、可用性グループ データベースの復旧を適用する行 (スレッド) の数を確認します。 次の例では、"agdb" データベースが 1 つのスレッドであり、そのコマンドが DB STARTUP場合、復旧ワークロードは並列復旧のメリットを得る可能性があります。
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

データベースでシングル スレッドの再実行が使用されていることを確認する場合は、前述のアルゴリズムを確認して、SQL Server が並列復旧専用のワーカー スレッド数が 100 個を超えるかどうかを判断します。 このような状態は、"agdb" データベースが復旧に 1 つのスレッドのみを使用している理由である可能性があります。
SQL Server 2022 では、ワークロードに基づく並列復旧のためにワーカー スレッドが割り当てられるように、新しい並列復旧アルゴリズムが使用されるようになりました。 これにより、ビジー状態のデータベースがシングル スレッド復旧のままになる可能性がなくなります。 詳細については、「Always On 可用性グループの前提条件、制限、および推奨事項」の 可用性グループ別の使用状況 セクションを参照してください。