Always On 可用性グループのフェールオーバーのトラブルシューティング
Note
この記事で説明されている手動分析を自動化するには、「 AGDiag を使用して可用性グループの正常性イベントを診断するを参照してください。
この記事では、可用性グループがフェールオーバーされた理由を判断するのに役立つトラブルシューティング手順について説明します。
Always On の正常性の問題またはフェールオーバーの影響
Always On は、プライマリ レプリカ、基になるクラスター、およびシステムの正常性をホストする Microsoft SQL Server インスタンスの正常性を確保するために、さまざまなメカニズムを通じて堅牢な正常性監視を実装します。 運用環境のワークロードは、Windows クラスターまたは Always On の正常性の問題が特定されると、一時的に中断されます。
正常性状態が検出されると、通常、次の一連のイベントが発生します。 このトラブルシューティング ツール全体を通して、正常性イベントは次のイベントを参照して説明します。
可用性グループのレプリカとデータベースは、プライマリ ロールからロールの解決に移行します。
可用性グループ データベースはオフラインに移行し、アクセスできなくなります。
Windows クラスターは、可用性グループのクラスター化されたリソースを失敗としてマークします。
Windows クラスターは、可用性グループの役割をオンラインに戻そうとします (元のフェールオーバー パートナー レプリカまたは自動フェールオーバー パートナー レプリカ上)。
可用性グループの役割は、Always On と Windows クラスターの正常性の監視によって正常であることが検出された場合、正常にオンラインになります。
成功した場合、可用性グループのレプリカとデータベースはプライマリ ロールに移行し、可用性グループ データベースはオンラインになり、アプリケーションからアクセスできます。
アプリケーションが可用性グループ データベースにアクセスできない
正常性状態が検出されると、可用性グループのレプリカとデータベースが解決ロールに移行し、可用性グループ データベースがオフラインになります。 レプリカがプライマリ ロール (元のレプリカ サーバーまたはフェールオーバー パートナー レプリカ サーバー) でオンラインになると、レプリカとデータベースは再びオンラインに移行します。 レプリカとデータベースが解決され、オフラインになっている間、それらの可用性グループ データベースにアクセスしようとするアプリケーションは失敗し、"エラー 983" というメッセージが生成されます: Unable to access availability database...。 このエラーは、失敗したログイン試行を記録するように SQL Server が構成されている場合も、Microsoft SQL Server エラー ログに記録されます。
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
可用性グループがプライマリ ロールでオンラインに戻るまでの解決ロールの期間は、通常、数秒または 1 秒未満です。
Always On 可用性グループの正常性イベントまたはフェールオーバーを特定して診断する
1. Always On の正常性の傾向を特定する
1 つの Always On 正常性イベントを調査する場合や、運用を断続的に中断している最近または継続的な正常性の問題の傾向が存在する可能性があります。 次の質問は、これらの正常性の問題に関連する可能性がある運用環境での最近の変更を絞り込んで関連付けるのに役立ちます。
- Always On またはクラスターの正常性イベントの傾向はいつ始まりますか?
- 正常性イベントは特定の日に発生しますか?
- 正常性イベントは特定の時刻に発生しますか?
- 正常性イベントは月の特定の日または週に発生しますか?
傾向を検出した場合は、システム (仮想環境のホスト システム)、ETL バッチ、およびこれらの正常性イベントと関連する可能性があるその他のジョブで、スケジュールされたメンテナンスを確認します。 システムが仮想マシンの場合は、停止時に発生した可能性のある変更についてホスト システムを調査します。
正常性の問題の時刻 (たとえば、ユーザーが最初にシステムにログオンしたとき、またはユーザーが昼食から戻った後など) に関連する可能性がある、ビジーなアドホック運用ワークロードを検討してください。
Note
ここでは、週と月を通してパフォーマンス データを収集する計画を検討することをお勧めします。 システムが最も多い時期をよりよく理解するために、 Processor Information::% Processor Time、 Memory::Available MBytes、 MSSQLServer:SQL Statistics::Batch Requests/secなどの Windows パフォーマンス モニター カウンターを測定できます。
2. クラスター ログを確認する
Windows クラスター ログは、Always On またはクラスターの正常性イベントの種類と、イベントの原因となった検出された正常性状態を識別するために使用する最も包括的なログです。 クラスター ログを生成して開くには、次の手順に従います。
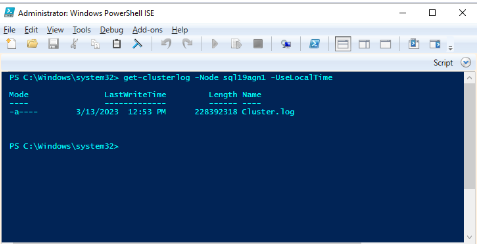
Windows PowerShell を使用して、正常性イベントの発生時にプライマリ レプリカをホストするクラスター ノードに Windows クラスター ログを生成します。 たとえば、SQL Server ベースのサーバー名として 'sql19agn1' を使用して、管理者特権の PowerShell ウィンドウで次のコマンドレットを実行します。
get-clusterlog -Node sql19agn1 -UseLocalTime
Note
既定では、ログ ファイルは %WINDIR%\cluster\reports に作成されます。
3. クラスター ログで正常性イベントを見つける
Always On では、複数の正常性監視メカニズムを使用して可用性グループの正常性を監視します。 Windows クラスターの正常性イベント (Windows クラスターがクラスター ノード間の正常性の問題を検出するイベント) に加えて、Always On には 4 種類の正常性チェックがあります。
- SQL Server サービスが実行されていない
- SQL Server のリース タイムアウト
- SQL Server 正常性チェックのタイムアウト
- SQL Server の内部正常性の問題
クラスター ログで文字列 ( [hadrag] Resource Alive result 0) を検索することで、Always On 固有の正常性イベントのいずれかを見つけることができます。 これらのイベントのいずれかが検出されると、この文字列はクラスター ログに保存されます。 例えば次が挙げられます。
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
ツールを使用すると、クラスター ログ内のすべての正常性イベントを検索して、Always On 正常性の問題の概要レポートを生成できます。 これは、時系列の傾向を特定し、特定の Always On の正常性状態が繰り返し発生しているかどうかを判断するのに役立ちます。 次のスクリーンショットは、テキスト エディター (この場合は NotePad++) を使用して、 [hadrag] Resource Alive result 0 文字列を含むクラスター ログ内のすべての行を検索する方法を示しています。

フェールオーバーをトリガーした正常性の問題を特定して解決する
プライマリ レプリカのクラスター ログの正常性の問題を特定するには、次のセクションで説明する問題と比較します。 AG フェールオーバーの一般的な理由は次のとおりです。
- クラスターの正常性イベント
- SQL Server サービスがダウンしている (Always On 正常性イベント)
- リース タイムアウト (Always On 正常性イベント)
- 正常性チェックのタイムアウト (Always On 正常性イベント)
- SQL Server の正常性 (Always On 正常性イベント)
クラスターの正常性イベント
Microsoft Windows クラスターは、クラスター内のメンバー サーバーの正常性を監視します。 正常性の問題が検出されると、クラスター メンバー サーバーがクラスターから削除される可能性があります。 また、クラスター リソース (削除されたクラスター メンバー サーバーでホストされている可用性グループ ロールを含む) は、自動フェールオーバー用に構成されている場合、可用性グループ フェールオーバー パートナー レプリカに移動されます。
現象
クラスター ログのクラスター正常性イベントの例を次に示します。 可用性グループロールの変更またはフェールオーバー中に存在する可能性があるため、 Lost quorum または Cluster service has terminated を検索できます。
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
このイベントを識別するもう 1 つの方法は、Windows システム イベント ログを検索することです。
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
クラスターの正常性イベントを診断する
Windows イベント ログ (イベント 1135 および 1177) のエラーは、ネットワーク接続がイベントの原因であることを示しています。 これは、クラスターの正常性の問題が検出される最も一般的な理由です。 次の例は、可用性グループのプライマリ レプリカをホストするこのサーバーと他のクラスター メンバー サーバーが通信できず、この問題によってクラスターノードがクラスターから削除されたことを示しています。
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
クラスター ログで、ノードへの接続エラーの証拠を検索できます。
Lost quorumが見つかったクラスター ログ内の場所から、Failed to connect to remote endpoint、unreachable、is brokenなどの文字列を後方に検索します。
解決方法
クラスターの正常性の監視がホスト環境に適していることを確認します。 Microsoft Azure でホストされている SQL Server Always On 可用性グループの詳細については、「 Windows Server フェールオーバー クラスターの概要 - Azure VM 上の SQL Server」を参照してください。
必要な場合は、Microsoft Windows 高可用性サポートに連絡してサポート インシデントを開くことを検討してください。
SQL Server サービスがダウンしています: Always On 正常性イベント
Always On 正常性監視では、可用性グループのプライマリ レプリカをホストする SQL Server サービスが実行されなくなったかどうかを検出できます。
現象
可用性グループ ロール "ag" のクラスター ログ レポートのサンプルを次に示します。これは、 QueryServiceStatusEx がプロセス ID 0を返したために失敗したことを示しています。
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
SQL サービスのシャットダウン イベントを診断する
Windows システム イベント ログと SQL Server エラー ログで、予期しない SQL Server のシャットダウンを確認します。
システムのシャットダウンまたは管理シャットダウンによって SQL Server がシャットダウンされた場合、SQL Server エラー ログに次のエントリが表示されます。
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Windows システム イベント ログには、次のエラー エントリが表示されます。
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
SQL Server が予期せずシャットダウンした場合、Windows システム イベント ログには次のエラー エントリが表示されます。
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
手掛かりについては、SQL Server エラー ログの末尾を確認してください。 エラー ログが突然終了した場合、これは強制的にシャットダウンされたことを意味します。 たとえば、タスク マネージャーを使用して SQL Server が終了した場合、SQL Server エラー レポートでは、プロセスのシャットダウンの原因となった内部の問題に関する情報は表示されません。
解決方法
SQL Server サービスの予期しない終了を最小限に抑えるために、承認されたデータベース管理者とシステム管理者がシステムにアクセスできることを確認します。 イベント ログを調べた後、サービスを予期せず終了する必要があった理由を調査します。
SQL Server の内部正常性の問題によって SQL Server が予期せず終了した場合、SQL エラー ログの最後に致命的な例外 (メモリ ダンプ診断ファイルが生成されるなど) の手掛かりが生じる可能性があります。 手掛かりを確認し、必要なアクションを実行します。 ダンプ ファイルが見つかる場合は、Microsoft SQL Server サポートに問い合わせて、詳細な調査のために SQL Server エラー ログとダンプ ファイルの内容を提供することを検討してください。
リース タイムアウト: Always On 正常性イベント
Always On では、"リース" メカニズムを使用して、SQL Server がインストールされているコンピューターの正常性を監視します。 既定のリース タイムアウトは 20 秒です。
現象
クラスター ログからの Always On リース タイムアウトの出力例を次に示します。 これらの文字列を検索して、クラスター ログでリース タイムアウトを見つけることができます。
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
リースタイムアウトの詳細については、「 Always On 可用性グループのリース、クラスター、正常性チェックのタイムアウトのガイドライン」の「リリース メカニズム」セクションを参照してください。
Always On リース タイムアウト イベントを診断して解決する
リースタイムアウトをトリガーする主な問題は 2 つあります。
SQL Server メモリ ダンプ: SQL Server は、アクセス違反、アサーション、スケジューラのデッドロックなどの特定の内部正常性イベントを検出すると、SQL Server \LOG フォルダーに診断ダンプ ファイル (.mdmp) を生成します。 メモリ ダンプを生成するプロセスでは、SQL Server の実行が短時間中断されます。 その期間中、リース メカニズムはサービス応答の欠如を検出し、アクションをトリガーできます。 詳細については、ダンプ生成の 出力を参照してください。
システム全体のパフォーマンスの問題: リースタイムアウトは、必ずしも SQL Server の正常性の問題を示すわけではありません。 代わりに、SQL Server ベースのサーバーの正常性にも影響するシステム全体の正常性の問題を示している可能性があります。
- システムでの CPU 使用率が高い (100% に近い)。
- メモリ不足の状態 - 仮想メモリが少ない、またはいずれかのプロセスがページアウトされています。
- クォーラム損失が原因で WSFC がオフラインになる
- パフォーマンスに影響を与え、リースの有効期限が発生する VM の調整。
解決方法
トラブルシューティングの詳細な手順については、 MSSQLSERVER_19407を参照してください。 最も一般的な 2 つの問題を次に示します。
1. SQL サーバー ダンプ ファイルの診断
SQL Server は、アクセス違反、アサーション、デッドロックされたスケジューラなどの内部正常性の問題を検出する場合があります。 このような場合、プログラムは、診断のために SQL Server プロセスの SQL Server \LOG フォルダーにミニ ダンプ ファイル (.mdmp) を生成します。 ミニ ダンプ ファイルがディスクに書き込まれる間、SQL Server プロセスは数秒間フリーズします。 この間、SQL Server プロセス内のすべてのスレッドは固定状態になります。これには、Always On 正常性監視によって監視されるリース スレッドが含まれます。 そのため、Always On はリースタイムアウトを検出する可能性があります。
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
この問題を解決するには、メモリ ダンプ ファイルの診断で根本原因を調べる必要があります。 詳細な調査のために、Microsoft SQL Server サポートに問い合わせて、SQL Server エラー ログとダンプ ファイルの内容を提供することを検討してください。
2. 高い CPU 使用率またはその他のシステム パフォーマンスの問題
リースタイムアウトは、SQL Server を含むシステム全体に影響するパフォーマンスの問題を示します。 システムの問題を診断するために、Always On 正常性診断では、クラスター ログにパフォーマンス モニター データが報告され、リースタイムアウト イベントが含まれます。 パフォーマンス データは、リース タイムアウト イベントまでの約 50 秒に及び、CPU 使用率、空きメモリ、ディスク待機時間に関するレポートが表示されます。
クラスター ログのリース タイムアウトを示す、報告されたパフォーマンス データの例を次に示します。 このサンプル出力では、リース タイムアウトに関連する可能性がある全体的な CPU 使用率が高くなります。
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
リースタイムアウト時にパフォーマンス データの CPU 使用率が高い、メモリの状態が低い、またはディスク待機時間が長い場合は、プライマリ レプリカで 1 日分のパフォーマンス モニターデータの収集を開始して、これらの症状を調査します。 パフォーマンス モニターのデータをより長い期間にわたってキャプチャすることで、これらのリソースのベースライン値とピーク値をより適切に識別し、リースタイムアウトが発生したときにこれらのリソースの変更を監視できます。 このデータを収集するときは、SQL Server に、これらのリソースの問題と正常性イベントの時刻に関連する特定のスケジュールされたワークロードまたはアドホック ワークロードがあるかどうかを検討します。
次のような同じシステム リソースの使用状況を報告するカウンターもキャプチャする必要があります。
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
正常性チェックのタイムアウト: Always On 正常性イベント
Always On では、正常性チェック メカニズムを使用して、SQL Server の正常性とクライアント アプリケーションが接続する機能を監視します。
現象
可用性グループ レプリカがプライマリ ロールに移行すると、Always On 正常性監視によって SQL Server インスタンスへのローカル ODBC 接続が確立されます。 Always On が接続され、監視されている間に、可用性グループの正常性チェック タイムアウト (既定値は 30 秒) に設定されている期間内に SQL Server が ODBC 接続経由で応答しない場合、正常性チェックタイムアウト イベントがトリガーされます。 この状況では、可用性グループはプライマリ ロールから解決中ロールに移行し、フェールオーバーを開始します (これを行う構成の場合)。
正常性チェックのタイムアウトの詳細については、「正常性チェックのタイムアウト操作」の「」セクションと、Always On 可用性グループのリース、クラスター、正常性チェックのタイムアウトのガイドラインを参照してください。
クラスター ログで報告される Always On 正常性チェックタイムアウトを次に示します。
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Always On 正常性チェックのタイムアウト イベントを診断して解決する
次のセクションでは、検出され、報告される Always On 正常性チェックのタイムアウトに関連する可能性がある "bread crumb" イベントの SQL Server ログを確認するのに役立ちます。 ここで確認するログには、クラスター ログ (正常性チェックのタイムアウトが確認される場所)、 system_health 拡張イベント ログと SQL Server エラー ログ (両方とも SQL Server \LOG フォルダーにあります)、Windows システム イベント ログが含まれます。 これらのログとその他のログを使用して、正常性チェックタイムアウトの原因の範囲を指定するのに役立つ可能性のある関連イベントを探します。
1. 非生成スケジューラ イベントを確認する
Always On 正常性チェックのタイムアウトは、SQL Server の "非生成" イベントが原因で発生する場合が多いです。 SQL Server は、スケジューラでスレッドが生成されていないことを検出すると、生成されないスケジューラ イベントが発生したことを報告します。 CPU 時間を受け取っていない同じスケジューラ上の他のタスクが表示される場合、これは非生成スケジューラの主な兆候です。 この動作により、これらのタスクの実行が遅れ、特定の CPU 時間スケジューラに割り当てられるワークロードが "不足" する可能性があります。
生成されていないスケジューラ イベントを確認するには、次の手順に従います。
SQL Server
system_health拡張イベント ログを調べて、Always On 正常性チェックタイムアウト イベントの前後に何らかの非生成スケジューラ イベントが報告されたかどうかを確認します。 見つかる可能性のある非生成イベントには、次のようなものがあります。scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
プライマリ レプリカの SQL Server システム正常性拡張イベント ログを、正常性チェックタイムアウトの疑いがある時刻まで開きます。
SQL Server Management Studio (SSMS) で、 File > Open に移動し、 Merge 拡張イベント ファイルを選択します。
追加 ボタンを選択します。
[ ファイルを開く ] ダイアログ ボックスで、SQL Server \LOG ディレクトリ内のファイルに移動します。
Control を長押しし、名前が
system_health_xxx.xelで始まるファイルを選択します。Open>OK を選択します。
結果をフィルター処理します。 name列の下にあるイベントを右クリックし、 [この値でフィルター] を選択。
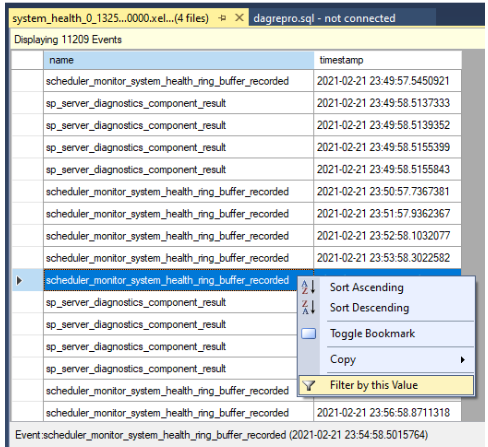
次のスクリーンショットに示すように、 name 列の値に
yieldが含まれる行を並べ替えるフィルターを定義します。 これにより、system_healthログに記録された可能性がある、すべての種類の非生成イベントが返されます。
タイムスタンプを比較して、正常性チェックのタイムアウト時に非生成イベントがあったかどうかを確認します。クラスター ログで報告される正常性チェックのタイムアウトを次に示します。
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.正常性チェックのタイムアウト時に発生した非生成イベントがあることがわかります。
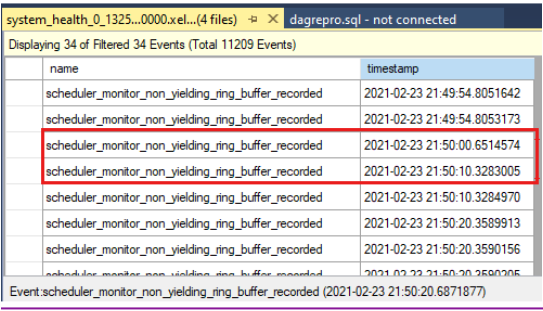
非生成イベントが検出された場合は、非生成イベントの原因を確認します。 非生成イベントを調査するには、SQL Server サポート チームに問い合わせてください。
2. SQL Server エラー ログを確認する
SQL Server エラー ログで、正常性チェックタイムアウト時のイベントを関連付けます。これらのイベントは、正常性チェックタイムアウトの根本原因を範囲指定する追加の手順を提案する "パンくず" を提供する場合があります。
たとえば、次のログ エントリは、クラスター ログで正常性チェックタイムアウトが発生したことを示しています。
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
SQL Server エラー ログでは、正常性チェックのタイムアウトから数秒以内に、重大な I/O 待機時間が検出されたと SQL Server から報告されます。
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
システム イベント ログで、正常性チェックタイムアウト イベントに関連する可能性のあるシステムの手掛かりを確認します。 Windows システム イベント ログを確認すると、同じ正常性チェック タイムアウトに対して同時に報告される I/O の問題が見つかる場合があります。
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server の正常性: Always On 正常性イベント
Always On は、さまざまな種類の SQL Server 正常性イベントを監視します。 可用性グループのプライマリ レプリカをホストしている間、SQL Server は、さまざまなコンポーネントを使用して SQL Server の正常性を報告する sp_server_diagnostics を継続的に実行します。 正常性の問題が検出されると、 sp_server_diagnostics はその特定のコンポーネントのエラーを報告し、その結果を Always On 正常性検出プロセスに戻します。 エラーが報告されると、可用性グループ ロールは失敗した状態と、可用性グループがこれを実行するように構成されている場合はフェールオーバーの可能性を示します。
現象
クラスター ログの sp_server_diagnostics によって報告される SQL Server の正常性の問題の例を次に示します。 SQL Server は、システム コンポーネントの "エラー" 状態を Always On 正常性監視に報告し、"contoso-ag" 可用性グループが失敗状態に移行します。
Note
SQL Server の正常性の問題により、正常性チェックタイムアウトと同様のレポートが生成されます。どちらの正常性イベントも Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel報告します。 SQL Server 正常性イベントの違いは、SQL Server コンポーネントが "警告" から "エラー" に変更されたことを報告することです。
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
SQL Server の正常性イベントを診断する
SQL Server の正常性によって報告される正常性の問題の種類によって、根本原因分析の方向が決まります。
既定では、可用性グループをデプロイすると、 FAILURE_CONDITION_LEVEL は 3 に設定されます。 これにより、一部の SQL Server 正常性プロファイルではなく、一部の SQL Server 正常性プロファイルの監視がアクティブになります。 既定のレベルでは、SQL Server が生成するダンプ ファイルが多すぎる場合、書き込みアクセス違反、または孤立したスピンロックが生成されると、Always On によって正常性イベントがトリガーされます。 可用性グループをレベル 4 または 5 に設定すると、監視される SQL Server の正常性の問題の種類が拡張されます。 SQL Server の正常性 Always On モニターの詳細については、「 可用性グループの柔軟な自動フェールオーバー ポリシーを構成する - SQL Server Always On」を参照してください。
Always On 固有の正常性の問題を特定するには、次の手順に従います。
疑わしい SQL Server 正常性イベントが発生した時点まで、プライマリ レプリカの SQL Server クラスター診断拡張イベント ログを開きます。
SSMS で、 File>Open に移動し、 Merge 拡張イベント ファイルを選択します。
[追加] を選択します。
[ ファイルを開く ] ダイアログ ボックスで、SQL Server \LOG ディレクトリ内のファイルに移動します。
Controlキーを押し、名前が
<servername>_<instance>_SQLDIAG_xxx.xelに一致するファイルを選択し、Open>OK を選択します。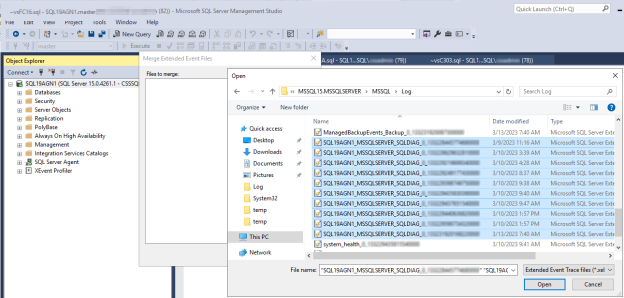
次のスクリーンショットに示すように、拡張イベントを含む新しいタブ付きウィンドウが SSMS に表示されます。
SQL Server の正常性の問題を調査するには、
state_desc値がerrorcomponent_health_resultを見つけます。 Always On 正常性監視にエラーを報告したシステム コンポーネント イベントの例を次に示します。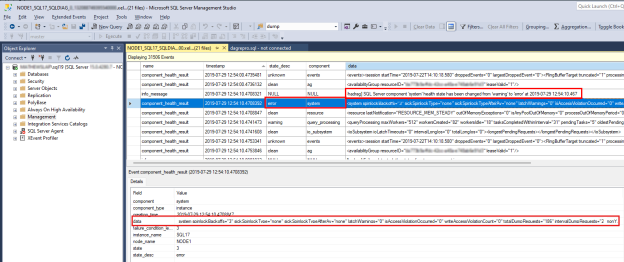
下のウィンドウの data 列をダブルクリックします。 これにより、詳細なコンポーネント データが新しい SSMS ウィンドウ ウィンドウに表示され、確認が行われます。 システム コンポーネント のデータは次のようになります。

"totalDumprequests=186" データは、この SQL Server で生成されたダンプ ファイル診断イベントが多すぎることを示していることに注意してください。 これは、システム コンポーネントがエラー状態を報告した理由です。 Always On 正常性監視は、このエラー状態を受け取ると、可用性グループの正常性イベントをトリガーします。 また、システム コンポーネント データに指定されたデータから、書き込みアクセス違反や孤立スピンロックが検出されていないことを確認することもできます。



解決方法
検出した問題の種類に応じて、それに応じて対処する必要があります。 可用性グループの柔軟な自動フェールオーバー ポリシーを構成する - SQL Server Always On 記事で説明されているように、さまざまな問題が発生する可能性があります。 以下に例を示します。
- SQL Server サービスがダウンした。
- リース タイムアウト。
- 可用性レプリカがエラー状態である。
- 孤立したスピンロック、アクセス違反、または短時間で生成されたメモリ ダンプが多すぎることによって生成されるメモリ ダンプ。
- SQL Server 内部リソース プールの永続的なメモリ不足状態。
- スケジューラ デッドロックの検出。
- 解決不可能なデッドロックが検出された。
必要な場合は、SQL Server サポートに問い合わせてサポート インシデントを開き、これらの内部 SQL Server の正常性の問題の根本原因を見つける方法についてさらにサポートを受けてください