Azure Windows 仮想マシンでの CPU 使用率の高い問題のトラブルシューティング
適用対象: ✔️ Windows VM
まとめ
パフォーマンスの問題はさまざまなオペレーティング システムまたはアプリケーションで発生し、いずれの問題にも固有のトラブルシューティング アプローチが必要です。 こうした問題のほとんどは、問題が発生する主な場所として CPU、メモリ、ネットワーク、および入出力 (I/O) が中心となっています。 このような領域ごとに異なる現象が (時には同時に) 発生し、異なる診断と解決策が必要です。
この記事では、Windows オペレーティング システムを実行する Azure Virtual Machines (VM) で発生する CPU 使用率が高い問題について説明します。
Azure Windows VM 上の CPU が高い問題
I/O とネットワーク待機時間の問題を除けば、CPU とメモリのトラブルシューティングには、オンプレミスのサーバーと同じツールと手順が必要です。 Microsoft によって一般的にサポートされているツールの 1 つとして、PerfInsights があります (Windows と Linux の両方で使用できます)。 PerfInsights を使用すると、わかりやすいレポートで Azure VM のベスト プラクティス診断を確認できます。 PerfInsights はラッパー ツールでもあり、ツール内で選択されたフラグに応じて、Perfmon、Xperf、および Netmon データを収集するために役立ちます。
オンプレミスのサーバーに使用される Perfmon や Procmon などの既存のパフォーマンス トラブルシューティング ツールのほとんどは、Azure Windows VM 上で動作します。 ただし、PerfInsights は、Azure VM 向けに明示的に設計されており、Azure のベスト プラクティス、SQL のベスト プラクティス、高解像度の I/O 待機時間グラフ、[CPU] および [メモリ] タブなど、より多くの分析情報が提供されます。
ユーザーモードまたはカーネルモードのどちらで実行する場合でも、アクティブ プロセスのスレッドには、ビルド元のコードを実行するための CPU サイクルが必要です。 多くの問題は、ワークロードに直接関係しています。 サーバーに存在するワークロードの種類によって、CPU などのリソース消費が発生します。
一般的な要因
CPU が高い状況では、次の要因が一般的です。
インターネット インフォメーション サービス (IIS)、Microsoft SharePoint、Microsoft SQL Server、またはサードパーティ アプリケーションなどのアプリに主に該当する最近のコード変更または展開。
OS レベルの更新プログラム、またはアプリケーションレベルの累積的な更新プログラムと修正プログラムに関連する可能性のある最近の更新プログラム。
クエリの変更または古いインデックス。 SQL Server および Oracle データ層アプリケーションには、もう 1 つの要因として、クエリ プランの最適化もあります。 データの変更や適切なインデックスの欠如により、複数のクエリが多くのコンピューティング処理を要することになる可能性があります。
Azure VM 固有。 RDAgent などの特定のプロセスと、Monitoring Agent、MMA エージェント、セキュリティ クライアントなどの拡張機能固有のプロセスがあり、CPU の消費量が多くなる可能性があります。 構成または既知の問題の観点から、このようなプロセスを確認する必要があります。
問題のトラブルシューティング
この記事では、問題のあるプロセスを特定することに重点を置いています。 さらに詳細な分析は、CPU の消費量が多いプロセスに固有のものです。
たとえば、プロセスが SQL Server (sqlservr.exe) の場合、次の手順は、特定の期間に最も多くの CPU サイクルを使用していたクエリを分析することです。
問題の範囲を調べる
問題をトラブルシューティングする際には、次の質問事項を確認してください。
この問題にはパターンがありますか。 たとえば、CPU が高い問題は、毎日、毎週、または毎月の特定の時間に発生しますか。 その場合、この問題をジョブ、レポート、またはユーザー ログインに関連付けることはできますか。
CPU が高い問題が始まったのは、最近のコード変更後ですか。 Windows またはアプリケーションで更新プログラムを適用しましたか。
CPU が高い問題が始まったのは、ユーザー数の増加、データ流入の増加、レポート数の増加など、ワークロードの変化の後ですか。
Azure の場合、CPU が高い問題は、次のいずれかの条件で始まりましたか。
- 最近の再デプロイまたは再起動後
- SKU または VM の種類が変更されたとき
- 新しい拡張機能が追加されたとき
- ロード バランサーの変更が行われた後
Azure に関する注意事項
ワークロードを理解する。 VM を選択する場合、全体的な月ごとのホスティング コストを調べるときに、仮想 CPU (vCPU) の数を過小評価することがあります。 ワークロードがコンピューティング集中型である場合、vCPU 数が 1 つまたは 2 つの小規模な VM SKU を選択すると、ワークロードの問題が発生する可能性があります。 ワークロードのさまざまな構成をテストして、必要とする最適なコンピューティング機能を決定してください。
品質保証 (QA) とテストに推奨される、B (バースト モード) シリーズなどの特定の VM シリーズがあります。 このようなシリーズを運用環境で使用すると、CPU クレジットが使い果たされた後にコンピューティング機能が制限されます。
SQL Server、Oracle、RDS (リモート デスクトップ サービス)、Azure Virtual Desktop、IIS、SharePoint などの既知のアプリケーションには、これらのワークロードの最小限の構成に関する推奨事項を含む Azure ベスト プラクティスに関する記事があります。
現在発生している CPU が高い問題
問題が現在発生している場合、これはプロセス トレースをキャプチャして問題の原因を特定するために最適な機会です。 オンプレミスの Windows サーバーに使用してきた既存のツールを使用して、プロセスを特定することができます。 Azure VM の Azure サポートでは、次のツールが推奨されています。
PerfInsights
PerfInsights は、VM のパフォーマンスの問題に関して Azure サポートから推奨されているツールです。 ベスト プラクティスと、CPU、メモリ、および高解像度の I/O グラフ専用の分析に関するタブを表示するように設計されています。 Azure portal または VM 内から、オンデマンドで実行できます。 Azure サポート チームとデータを共有できます。
PerfInsights を実行する
PerfInsights は、Windows と Linux OS の両方に用意されています。 Windows の場合、次のオプションがあります。
Azure portal を使用してレポートを実行および分析する
Azure portal を使用してインストールすると、実際には VM に拡張機能がインストールされます。 また、VM ブレードの [拡張機能] に直接移動し、パフォーマンス診断オプションを選択することで、拡張機能として PerfInsights をインストールすることもできます。
Azure portal のオプション 1
VM ブレードを表示し、[パフォーマンス診断] オプションを選択します。 選択した VM にオプション (拡張機能を使用) をインストールするように求められます。
![[パフォーマンス診断] オプションの [パフォーマンス診断のインストール] ボタンのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/install-performance-diagnostics.png)
Azure portal のオプション 2
VM ブレードの [問題の診断と解決] を表示し、[VM Performance Issues]\(VM のパフォーマンスに関する問題\) を探します。
![[問題の診断と解決] オプションの VM パフォーマンスの問題のスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/troubleshoot-vm-performance-issues.png)
[トラブルシューティング] を選択した場合は、PerfInsights のインストール画面が読み込まれます。
[インストール] を選択すると、インストールによってさまざまな収集オプションが提供されます。
![[パフォーマンス診断] オプションの [パフォーマンス分析] 設定のスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/performance-analysis.png)
スクリーンショットの番号付きオプションは、次のコメントに関連しています。
[High-CPU]\(高 CPU \) のオプションの場合は、[パフォーマンス解析] または [詳細] を選択します。
ここで現象を追加すると、レポートに追加されます。これは、Azure サポートと情報を共有するために役立ちます。
データ収集の期間を選択します。 [High-CPU]\(高 CPU \) オプションの場合は 15 分以上を選択します。 Azure portal モードでは、最大 15 分のデータを収集できます。 収集の期間を長くするには、VM 内の実行可能ファイルとしてプログラムを実行する必要があります。
Azure サポートからこのデータを収集するように求められた場合は、ここでチケット番号を追加できます。 このフィールドは省略可能です。
使用許諾契約書 (EULA) に同意するには、このフィールドを選択します。
このレポートを Azure サポート チームが使用できるようにする場合は、このフィールドを選択します。
このレポートは、サブスクリプションのいずれかのストレージ アカウントに保存されます。 後で表示してダウンロードすることができます。
VM 内から PerfInsights を実行する
この方法は、PerfInsights を長期間実行する場合に使用できます。 PerfInsights の記事には、PerfInsights を実行可能ファイルとして実行するために必要なさまざまなコマンドとフラグの詳細なチュートリアルが記載されています。 高い CPU 使用率の目的では、次のいずれかのモードが必要です。
高度なシナリオ
PerfInsights /run advanced xp /d 300 /AcceptDisclaimerAndShareDiagnostics
VM が遅い (パフォーマンス) シナリオ
PerfInsights /run vmslow /d 300 /AcceptDisclaimerAndShareDiagnostics /sa <StorageAccountName> /sk <StorageAccountKey>
コマンドの出力は、PerfInsights 実行可能ファイルを保存したフォルダーと同じフォルダーに格納されます。
レポートの要注目点
レポートを実行した後、コンテンツの場所は、レポートが Azure portal を使用して実行されたか、実行可能ファイルとして実行されたかによって異なります。 どちらのオプションでも、生成されたログ フォルダーにアクセスするか、ローカルにダウンロード (Azure portal の場合) して分析します。
Azure portal を使用して実行する
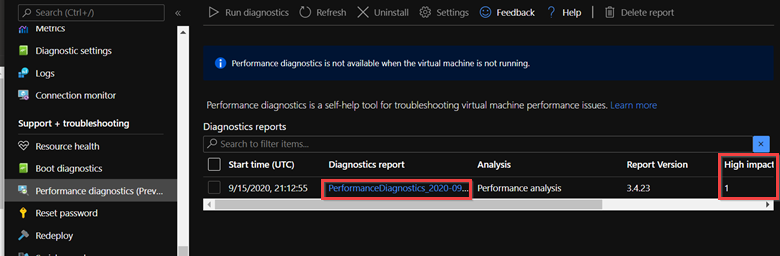
![[パフォーマンス診断レポート] ページの [レポートのダウンロード] ボタンのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/download-report.png)
VM 内から実行する
フォルダー構造は次の図のようになります。
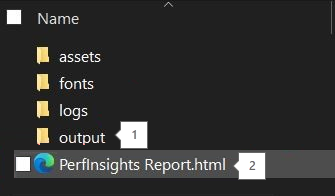
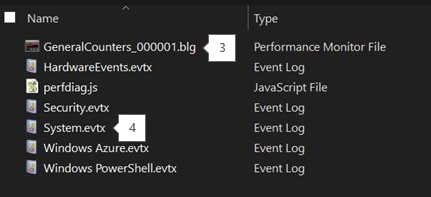
Perfmon、Xperf、Netmon、SMB ログ、イベント ログなど、その他のコレクションは出力フォルダーにあります。
分析と推奨事項を含む実際のレポート。
パフォーマンス (VMslow) と詳細の両方について、レポートには PerfInsights の実行中の perfmon 情報が収集されます。
イベント ログでは、役に立つシステムレベルまたはプロセスのクラッシュの詳細をすばやく確認できます。
開始する場所
PerfInsights レポートを開きます。 [検出結果] タブには、リソース消費の観点から外れ値がログに記録されます。 CPU 使用率が高いインスタンスがある場合、[検出結果] タブでは [影響: 大] または [影響: 中] のいずれかに分類されます。
![PerfInsights レポート ページの CPU 部分の [結果] タブのスクリーンショット。この例では、影響レベルは中です。](media/troubleshoot-high-cpu-issues-azure-windows-vm/impact-level-resources.png)
前の例と同様に、PerfInsights は 30 分間実行されました。 その半分の時間、強調表示されているプロセスによって、高い数値で CPU が使い果たされていました。 収集時間全体にわたってこの同じプロセスが実行されていた場合、影響レベルは高に変更されます。
[検出結果] イベントを展開すると、いくつかの重要な詳細が表示されます。 このタブには、[平均 CPU] 消費量ごとにプロセスが降順で一覧表示され、プロセスがシステム、Microsoft 所有のアプリ (SQL、IIS)、またはサードパーティのプロセスのいずれに関連していたかが示されます。
[詳細]
[CPU] には専用のサブタブがあり、コアごと、またはプロセスごとの詳細なパターン分析に使用できます。
[Top CPU Consumers]\(上位の CPU コンシューマー\) タブには、対象のセクションが個別に 2 つあり、ここでプロセッサごとの統計情報を表示できます。 多くの場合、アプリケーションの設計はシングルスレッドであるか、それ自体が 1 つのプロセッサに固定されています。 このシナリオでは、1 つまたはいくつかのコアは 100% で実行され、他のコアは想定されているレベルで実行されます。 このようなシナリオは、サーバー上の平均的な CPU は想定どおりに実行されているように見えますが、使用率の高いコアに固定されているプロセスは想定よりも遅くなるため、より複雑です。
![パフォーマンス診断分析期間と CPU 使用率の高い期間を示す PerfInsights レポート ページの CPU 部分の [上位 CPU コンシューマー] タブのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/high-cpu-usage.png)
2 つ目のセクション (同様に重要) は、[Top Long Running CPU Consumers]\(実行時間が長い上位の CPU コンシューマー\) です。 このセクションには、プロセスの詳細と CPU 使用パターンの両方が表示されます。 この一覧は、平均 CPU コンシューマーが高い順に並べ替えられています。
![[実行時間の長い CPU コンシューマーの上位] セクションのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/top-long-running-cpu-consumers.png)
これらの 2 つのタブを使用すると、次のトラブルシューティング手順のパスを設定できます。 CPU が高い状態を引き起こしているプロセスに応じて、以前に確認した質問事項に対応する必要があります。 SQL Server (sqlservr.exe) や IIS (w3wp.exe) などのプロセスの場合、この状態を引き起こしているクエリまたはコードの変更に対する特定のドリルダウンが必要です。 WMI や Lsass.exe などのシステム プロセスの場合は、別のパスに従う必要があります。
RDAgent、OMS、監視拡張機能の実行可能ファイルなどの Azure VM 関連のプロセスの場合、Azure サポート チームの支援を受けて、新しいビルドまたはバージョンを修正することが必要になる場合があります。
Perfmon
Perfmon は、Windows Server のリソースの問題をトラブルシューティングするための、ごく初期からあるツールの 1 つです。 推奨事項や検出結果を含む明確なレポートは用意されていません。 代わりに、収集されたデータを調べて、さまざまなカウンター カテゴリで特定のフィルターを使用する必要があります。
PerfInsights を使用すると、VMSlow および高度なシナリオの追加のログとして Perfmon を収集できます。 ただし、Perfmon は個別に収集することができ、さらに次の利点があります。
リモートで収集できます。
タスクを使用してスケジュールできます。
ロールオーバー機能を使用して、長期間または連続モードで収集できます。
PerfInsights に表示されているものと同じ例を検討して、Perfmon ではそのデータがどのように表示されるかを確認してください。 必須のカウンター カテゴリは次のとおりです。
%Processor Time > _Total>プロセッサ情報
%ProcessorTime > すべてのインスタンス>処理
開始する場所
Perfmon の出力ファイル名には .blg の拡張子が付いています。 これらのファイルは、個別に、または PerfInsights を使用して収集することができます。 この説明では、PerfInsights データに含まれ、前の例で収集された Perfmon .blg を使用します。
Perfmon で使用できる既定のユーザー対応レポートはありません。 グラフの種類を変更するさまざまなビューはありますが、プロセスのフィルター処理 (または原因のプロセスを特定するために必要な作業) は手動です。
Note
PAL Tool では、.blg ファイルを使用し、詳細なレポートを生成することができます。
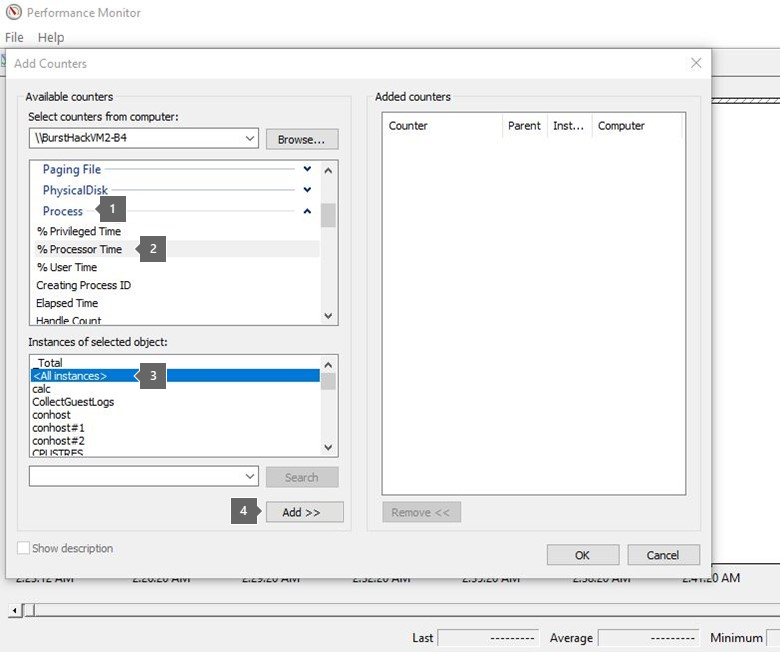
開始するには、[カウンターの追加] カテゴリを選択します。
[使用可能なカウンター] の下にある [プロセッサ情報] カテゴリで %ProcessorTime カウンターを選択します。
_Total を選択します。これにより、すべての結合されたコアの統計情報が表示されます。
[追加] を選択します。 このウィンドウの [追加されたカウンター] に %ProcessorTime が表示されます。
![パフォーマンス モニターの [カウンターの追加] ダイアログのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/add-processor-time.png)
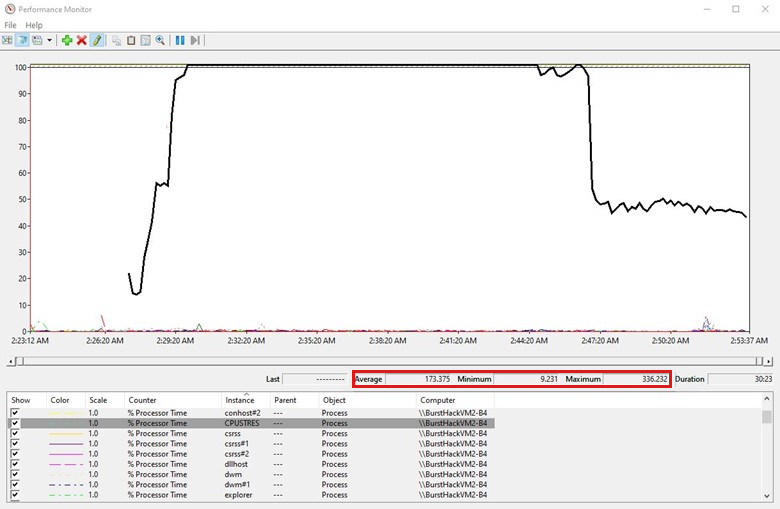
カウンターが読み込まれると、収集時間枠の折れ線のトレンド グラフが表示されます。 カウンターをオンまたはオフにすることができます。 これまでに追加したカウンターは 1 つだけです。
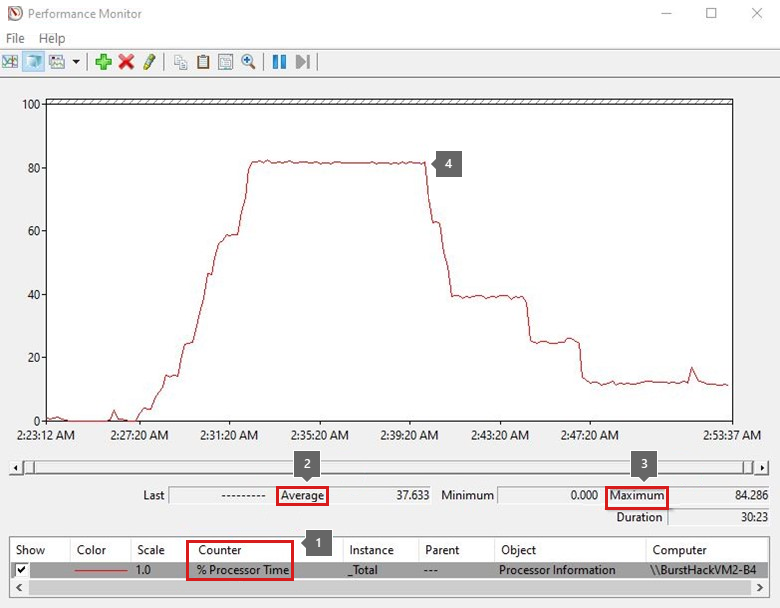
すべてのカウンターには、[平均]、[最小]、および [最大] の値があります。 平均値はデータ収集の期間によって変動する可能性があるため、[平均] と [最大] の値の両方に注目してください。 収集全体が 40 分間で、CPU が高いアクティビティが 10 分間見られた場合、平均値ははるかに低くなります。
前のトレンド グラフは、合計プロセッサが約 15 分間で 80% 近くの範囲にあったことを示しています。
プロセスを特定する
特定の期間、サーバーの CPU 消費量が高かったことは特定しましたが、その要因はまだ特定していません。 PerfInsights を使用する場合とは異なり、原因プロセスを手動で検索する必要があります。
このタスクでは、以前に追加した %ProcessorTime カウンターをクリアまたは削除してから、新しいカテゴリを追加する必要があります。
- %ProcessorTime > すべてのインスタンス>処理
このカテゴリを選択すると、その時点で実行されているすべてのプロセスのカウンターが読み込まれます。
一般的な運用コンピューターでは、数百単位のプロセスが実行されている可能性があります。 そのため、トレンド グラフが低いか平坦なように見えるすべてのカウンターをクリアするのにも時間がかかる場合があります。
このプロセスを高速にするには、[ヒストグラム] ビューを使用します。ビューの種類を [折れ線] から [ヒストグラム] に変更すると、棒グラフが表示されます。 収集時に CPU 使用率が高いプロセスを選択するのが簡単であることがわかります。
[合計] の棒は常に表示されるため、高い消耗率を示している棒に注目してください。 他の棒を削除して、ビューを整理することができます。 次に、[折れ線] ビューに戻ります。
![パフォーマンス モニターの [ヒストグラム ビュー] ボタンと、高い枯渇率を示す 2 つのバーを含むグラフの例のスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/performance-monitor-2.png)
これで、原因プロセスを簡単に見つけられるようになりました。 既定では、[最大] と [最小] の値は、サーバー上のコアまたはプロセスのスレッドの数の倍数になります。
使用可能なツールの一覧は、Perfmon 用の PerfInsights だけではありません。 ProcessMonitor (ProcMon) や Xperf などの他のツールも利用できます。 必要に応じて使用できるサードパーティ ツールが多数あります。
Azure 監視ツール
Azure VM には、CPU、ネットワーク I/O、I/O バイトなどの基本情報を含む信頼性の高いメトリックがあります。 Azure Monitor などの高度なメトリックの場合、指定したストレージ アカウントを構成して使用するには、いくつかの選択を行うだけで済みます。
基本 (既定) のカウンター
![Azure Monitor の [メトリック] ページのスクリーンショット。この例では、[集計] 設定の [CPU 使用率] オプションが選択されています。](media/troubleshoot-high-cpu-issues-azure-windows-vm/chart-metrics.png)
Azure Monitor の有効化
Azure Monitor のメトリックを有効にすると、このソフトウェアによって VM に拡張機能がインストールされ、Perfmon カウンターを含む詳細なメトリックの収集が開始されます。
![[診断設定] ページの [概要] タブの [診断ストレージ アカウント] フィールドのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/diagnostics-storage-account.png)
[基本] カウンター カテゴリが既定値として設定されます。 ただし、[カスタム] の収集を設定することもできます。
![[診断設定] ページの [パフォーマンス カウンター] タブにある [基本カテゴリ] オプションのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/performance-counters.png)
この設定を有効にすると、[メトリック] セクションでこのような [ゲスト] カウンターを表示できます。 メトリックが特定のしきい値に達した場合の [アラート] (メール メッセージを含む) を設定することもできます。
![[メトリック] ページの [メトリック名前空間] フィールドと [新しいアラート ルール] ボタンのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/metrics-namespace.png)
Azure Monitor を使用して Azure VM を管理する方法の詳細については、「Azure Monitor を使用して Azure 仮想マシンを監視する」を参照してください。
事後対応のトラブルシューティング
問題が既に発生している場合は、まず CPU が高い問題の原因を特定する必要があります。 事後対応の態勢には注意が必要です。 問題は既に発生しているため、データ収集モードはそれほど役に立ちません。
この問題が 1 回だけ発生した場合、どのアプリが原因であるかを特定することは困難な可能性があります。 Azure VM が OMS またはその他の診断追跡を使用するように構成されている場合でも、問題の原因に関する分析情報を得ることができます。
繰り返しパターンを扱う場合は、次に問題が発生する可能性が高い時間帯にデータを収集します。
PerfInsights には、まだスケジュールされた実行機能がありません。 ただし、Perfmon は、コマンド ラインから実行およびスケジュールできます。
Logman コマンド
Logman Create Counter コマンドは、コマンド ラインから Perfmon コレクションを実行する場合、タスク マネージャーからスケジュールする場合、リモートで実行する場合に使用されます。
サンプル (リモート コレクション モードを含む)
Logman create counter LOGNAME -u DOMAIN\USERNAME * -f bincirc -v mmddhhmm -max 300 -c "\\SERVERNAME\LogicalDisk(*)\*" "\\SERVERNAME\Memory\*" "\\SERVERNAME\Network Interface(*)\*" "\\SERVERNAME\Paging File(*)\*" "\\SERVERNAME\PhysicalDisk(*)\*" "\\SERVERNAME\Process(*)\*" "\\SERVERNAME\Redirector\*" "\\SERVERNAME\Server\*" "\\SERVERNAME\System\*" "\\SERVERNAME\Terminal Services\*" "\\SERVERNAME\Processor(*)\*" "\\SERVERNAME\Cache\*" -si 00:01:00
Logman.exe は、同じ VNET 内のピア Azure VM コンピューターから起動することもできます。
このようなパラメーターの詳細については、「logman create counter」を参照してください。
問題の発生中に Perfmon データが収集された後の、データを分析するためのその他の手順は、前に説明したものと同じです。
まとめ
パフォーマンスの問題が発生した場合、問題を解決するには、ワークロードを理解することが重要です。 さまざまな VM SKU に対するオプションやさまざまなディスク ストレージ オプションは、運用ワークロードに重点を置いて評価する必要があります。 異なる VM 上で解決策をテストするプロセスは、最適な決定を下すために役立ちます。
ユーザーの操作とデータの量はさまざまであるため、VM のコンピューティング、ネットワーク、および I/O 機能には常にバッファーを確保してください。 現在、ワークロードの急激な変化には、それほど大きな影響はありません。
ワークロードがすぐに増加すると予測される場合は、より多くのコンピューティング能力を備えたより高い SKU に移行してください。 ワークロードがコンピューティング集計型になる場合は、VM SKU を慎重に選択してください。
お問い合わせはこちらから
質問がある場合やヘルプが必要な場合は、サポート要求を作成するか、Azure コミュニティ サポートにお問い合わせください。 Azure フィードバック コミュニティに製品フィードバックを送信することもできます。