Azure Kubernetes Services での API サーバーと etcd の問題のトラブルシューティング
このガイドは、大規模な Microsoft Azure Kubernetes Services (AKS) デプロイで API サーバー内で発生する可能性のある問題を特定して解決できるように設計されています。
Microsoft は、5,000 ノードと 200,000 ポッドの規模で API サーバーの信頼性とパフォーマンスをテストしました。 API サーバーを含むクラスターには、自動的にスケールアウトし、 Kubernetes サービス レベル目標 (SLO) を提供する機能があります。 待機時間が長い場合やタイムアウトが発生した場合は、分散 etc ディレクトリ (etcd) にリソース漏えいが発生しているか、問題のあるクライアントが過剰な API 呼び出しを行っている可能性があります。
前提条件
Kubernetes kubectl ツール。 Azure CLI を使用して kubectl をインストールするには、 az aks install-cli コマンドを実行します。
有効にされ、 Log Analytics ワークスペースに送信される AKS 診断ログ (具体的には kube-audit イベント。 リソース固有または Azure 診断 モードを使用してログが収集されるかどうかを確認するには、Azure portal の Diagnostic Settings ブレードを確認します。
AKS クラスターの Standard レベル。 Free レベルを使用している場合、API サーバーと etcd には限られたリソースが含まれます。 Free レベルの AKS クラスターでは、高可用性は提供されません。 これは多くの場合、API サーバーと etcd の問題の根本原因です。
kubernetes コントロール プレーンを使用せずに AKS ノードでコマンドを直接実行するための kubectl-aks プラグイン。
基本的な正常性チェック
リソースの正常性イベント
AKS は、重要なコンポーネントのダウンタイムのためのリソース正常性イベントを提供します。 先に進む前に、 Resource Health に重大なイベントが報告されていないことを確認します。
問題の診断と解決
AKS には、 クラスターとコントロール プレーンの可用性とパフォーマンス専用のトラブルシューティング カテゴリが用意されています。
![[クラスターとコントロール プレーンの可用性とパフォーマンス] カテゴリを示すスクリーンショット。](media/troubleshoot-apiserver-etcd/cluster-control-plane-availability-performance.png)

![[クラスターとコントロール プレーンの可用性とパフォーマンス] カテゴリを示すスクリーンショット。](media/troubleshoot-apiserver-etcd/cluster-control-plane-availability-performance.png#lightbox)
現象
次の表は、API サーバーの障害の一般的な症状の概要を示しています。
| 現象 | 説明 |
|---|---|
| API サーバーからのタイムアウト | AKS API サーバーの SLA 保証を超える頻繁なタイムアウト。 たとえば、 kubectl コマンドはタイムアウトになります。 |
| 待機時間が長い | Kubernetes SLO が失敗する待機時間が長い。 たとえば、 kubectl コマンドはポッドの一覧表示に 30 秒以上かかります。 |
api server pod in CrashLoopbackOff status or facing webhook call failures |
API サーバーの呼び出しをブロックしているカスタム アドミッション Webhook ( Kyverno ポリシー エンジンなど) がないことを確認します。 |
トラブルシューティングのチェックリスト
待機時間が長い場合は、次の手順に従って、問題のあるクライアントと失敗する API 呼び出しの種類を特定します。
手順 1: 要求の数で上位のユーザー エージェントを識別する
最も多くの要求 (および API サーバーの負荷が最も高い可能性がある) を生成するクライアントを特定するには、次のコードのようなクエリを実行します。 次のクエリでは、送信された API サーバー要求の数で上位 10 人のユーザー エージェントが一覧表示されます。
AKSAudit
| where TimeGenerated between(now(-1h)..now()) // When you experienced the problem
| summarize count() by UserAgent
| top 10 by count_
| project UserAgent, count_
Note
クエリで結果が返されない場合は、診断ログを照会するために間違ったテーブルを選択している可能性があります。 リソース固有モードでは、データはリソースのカテゴリに応じて個々のテーブルに書き込まれます。 診断ログは、 AKSAudit テーブルに書き込まれます。 Azure 診断モードでは、すべてのデータが AzureDiagnostics テーブルに書き込まれます。 詳細については、Azure リソース ログに関するページを参照してください。
どのクライアントが最も高い要求ボリュームを生成するかを知ると役に立ちますが、要求量が多いだけでは問題の原因にならない可能性があります。 各クライアントが API サーバーで生成する実際の負荷のより良いインジケーターは、発生する応答の待機時間です。
手順 2: ユーザー エージェントあたりの API サーバー要求の平均待機時間を特定してグラフ化する
タイム チャートにプロットされたユーザー エージェントごとの API サーバー要求の平均待機時間を特定するには、次のクエリを実行します。
AKSAudit
| where TimeGenerated between(now(-1h)..now()) // When you experienced the problem
| extend start_time = RequestReceivedTime
| extend end_time = StageReceivedTime
| extend latency = datetime_diff('millisecond', end_time, start_time)
| summarize avg(latency) by UserAgent, bin(start_time, 5m)
| render timechart
このクエリは、「要求の数で上位のユーザー エージェントを識別する」セクションの のクエリのフォローアップです 。 時間の経過と同時に各ユーザー エージェントによって生成される実際の負荷に関するより多くの分析情報が得られる場合があります。
ヒント
このデータを分析することで、AKS クラスターまたはアプリケーションの問題を示す可能性のあるパターンと異常を特定できます。 たとえば、特定のユーザーの待機時間が長いことがわかります。 このシナリオでは、API サーバーまたは etcd に過剰な負荷を引き起こしている API 呼び出しの種類を示すことができます。
手順 3: 特定のユーザー エージェントに対する無効な API 呼び出しを特定する
次のクエリを実行して、特定のクライアントのさまざまなリソースの種類にわたる API 呼び出しの 99 パーセンタイル (P99) 待機時間を表します。
AKSAudit
| where TimeGenerated between(now(-1h)..now()) // When you experienced the problem
| extend HttpMethod = Verb
| extend Resource = tostring(ObjectRef.resource)
| where UserAgent == "DUMMYUSERAGENT" // Filter by name of the useragent you are interested in
| where Resource != ""
| extend start_time = RequestReceivedTime
| extend end_time = StageReceivedTime
| extend latency = datetime_diff('millisecond', end_time, start_time)
| summarize p99latency=percentile(latency, 99) by HttpMethod, Resource
| render table
このクエリの結果は、アップストリームの Kubernetes SLO で失敗する API 呼び出しの種類を特定するのに役立ちます。 ほとんどの場合、問題のあるクライアントは、大きすぎるオブジェクトまたはオブジェクトの大規模なセットに対して LIST 呼び出しが多すぎる可能性があります。 残念ながら、API サーバーのスケーラビリティについてユーザーをガイドするためのハード スケーラビリティの制限はありません。 API サーバーまたは etcd のスケーラビリティの制限は、 Kubernetes のスケーラビリティしきい値で説明されているさまざまな要因によって異なります。
原因 1: ネットワーク ルールによって、エージェント ノードから API サーバーへのトラフィックがブロックされる
ネットワーク ルールは、エージェント ノードと API サーバー間のトラフィックをブロックできます。
正しく構成されていないネットワーク ポリシーが API サーバーとエージェント ノード間の通信をブロックしているかどうかを確認するには、次の kubectl-aks コマンドを実行します。
kubectl aks config import \
--subscription <mySubscriptionID> \
--resource-group <myResourceGroup> \
--cluster-name <myAKSCluster>
kubectl aks check-apiserver-connectivity --node <myNode>
config import コマンドは、クラスター内のすべてのノードの仮想マシン スケール セット情報を取得します。 次に、 check-apiserver-connectivity コマンドは、この情報を使用して、API サーバーと指定されたノード (特にその基になるスケール セット インスタンス) 間のネットワーク接続を確認します。
Note
check-apiserver-connectivity コマンドの出力にConnectivity check: succeededメッセージが含まれている場合、ネットワーク接続は妨げされません。
解決策 1: ネットワーク ポリシーを修正してトラフィックのブロックを削除する
コマンド出力に接続エラーが発生したことが示されている場合は、エージェント ノードと API サーバー間のトラフィックを不必要にブロックしないようにネットワーク ポリシーを再構成します。
原因 2: 問題のあるクライアントが etcd オブジェクトをリークし、etcd の速度低下を引き起こす
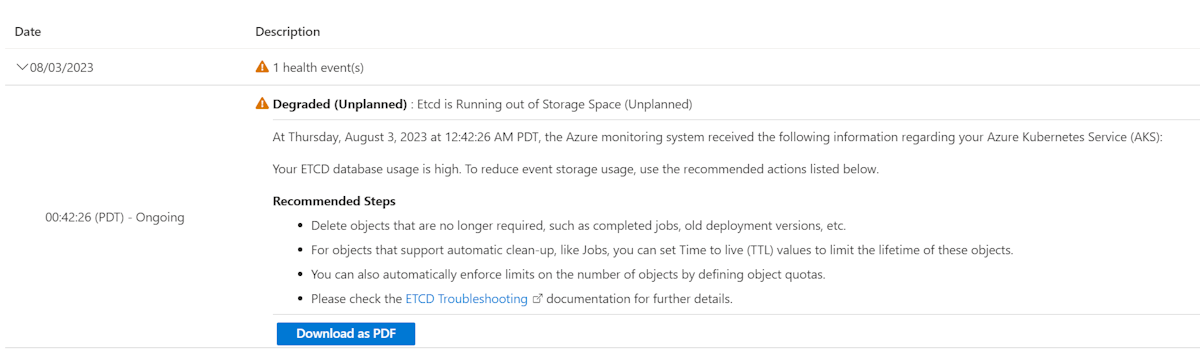
一般的な問題は、etcd データベース内の未使用のオブジェクトを削除せずにオブジェクトを継続的に作成することです。 これにより、etcd が任意の型のオブジェクト (10,000 を超える) を扱いすぎると、パフォーマンスの問題が発生する可能性があります。 このようなオブジェクトに対する変更が急激に増加すると、etcd データベース のサイズ (既定では 4 ギガバイト) を超える可能性もあります。
etcd データベースの使用状況を確認するには、Azure portal で Diagnose と Solve の問題 に移動します。 検索ボックスで "etcd" を検索して、Etcd 可用性の問題診断ツールを実行します。 診断ツールには、使用状況の内訳とデータベースの合計サイズが表示されます。

etcd データベースの現在のサイズをバイト単位で簡単に表示する場合は、次のコマンドを実行します。
kubectl get --raw /metrics | grep -E "etcd_db_total_size_in_bytes|apiserver_storage_size_bytes|apiserver_storage_db_total_size_in_bytes"
Note
前のコマンドのメトリック名は、Kubernetes のバージョンによって異なります。 Kubernetes 1.25 以前の場合は、 etcd_db_total_size_in_bytesを使用します。 Kubernetes 1.26 から 1.28 の場合は、 apiserver_storage_db_total_size_in_bytesを使用します。
解決策 2: etcd でオブジェクトの作成、オブジェクトの削除、またはオブジェクトの有効期間を制限するためのクォータを定義する
etcd が容量に達してクラスターのダウンタイムを引き起こすのを防ぐために、作成されるリソースの最大数を制限できます。 また、リソース インスタンスに対して生成されるリビジョンの数を遅くすることもできます。 作成できるオブジェクトの数を制限するには、オブジェクト クォータを定義。
使用されなくなったがリソースを占有しているオブジェクトを特定した場合は、それらを削除することを検討してください。 たとえば、完了したジョブを削除して領域を解放できます。
kubectl delete jobs --field-selector status.successful=1
自動クリーンアップをサポートするオブジェクトの場合は、Time to Live (TTL) 値を設定して、これらのオブジェクトの有効期間を制限できます。 また、ラベル セレクターを使用して特定の種類のすべてのオブジェクトを一括削除できるように、オブジェクトにラベルを付けることもできます。 オブジェクト間 所有者参照 を確立すると、親オブジェクトが削除された後に依存オブジェクトが自動的に削除されます。
原因 3: 問題のあるクライアントが過剰な LIST または PUT 呼び出しを行う
etcd が過剰な数のオブジェクトでオーバーロードされていないと判断した場合、問題のあるクライアントが API サーバーへの LIST や PUT 呼び出しを行いすぎる可能性があります。
解決策 3a: API 呼び出しパターンを調整する
コントロール プレーンの負荷を軽減するために、クライアントの API 呼び出しパターンを調整することを検討してください。
解決策 3b: コントロール プレーンを過負荷にしているクライアントを調整する
クライアントを調整できない場合は、Kubernetes の Priority と Fairness 機能を使用してクライアントを調整できます。 この機能は、コントロール プレーンの正常性を維持し、他のアプリケーションが失敗するのを防ぐのに役立ちます。
次の手順では、問題のあるクライアントの LIST Pods API を 5 つの同時呼び出しに設定して調整する方法を示します。
問題のあるクライアントの API 呼び出しパターンに一致する FlowSchema を作成します。
apiVersion: flowcontrol.apiserver.k8s.io/v1beta2 kind: FlowSchema metadata: name: restrict-bad-client spec: priorityLevelConfiguration: name: very-low-priority distinguisherMethod: type: ByUser rules: - resourceRules: - apiGroups: [""] namespaces: ["default"] resources: ["pods"] verbs: ["list"] subjects: - kind: ServiceAccount serviceAccount: name: bad-client-account namespace: defaultクライアントの不適切な API 呼び出しを調整する優先順位の低い構成を作成します。
apiVersion: flowcontrol.apiserver.k8s.io/v1beta2 kind: PriorityLevelConfiguration metadata: name: very-low-priority spec: limited: assuredConcurrencyShares: 5 limitResponse: type: Reject type: LimitedAPI サーバーメトリックで調整された呼び出しを観察します。
kubectl get --raw /metrics | grep "restrict-bad-client"
原因 4: カスタム Webhook が API サーバー ポッドでデッドロックを引き起こす可能性がある
Kyverno などのカスタム Webhook によって、API サーバー ポッド内でデッドロックが発生している可能性があります。
API サーバーに関連するイベントを確認します。 次のテキストのようなイベント メッセージが表示される場合があります。
内部エラーが発生しました: webhook "mutate.kyverno.svc-fail" の呼び出しに失敗しました: webhook の呼び出しに失敗しました: post "https://kyverno-system-kyverno-system-svc.kyverno-system.svc:443/mutate/fail?timeout=10s": write unix @->/tunnel-uds/proxysocket: write: broken pipe
この例では、Webhook の検証によって一部の API サーバー オブジェクトの作成がブロックされています。 このシナリオはブートストラップ時に発生する可能性があるため、API サーバーと Konnectivity ポッドを作成できません。 そのため、Webhook はこれらのポッドに接続できません。 この一連のイベントにより、デッドロックとエラー メッセージが発生します。
解決策 4: webhook 構成を削除する
この問題を解決するには、Webhook 構成の検証と変更を削除します。 Kyverno でこれらの webhook 構成を削除するには、 Kyverno のトラブルシューティングに関する記事を確認してください。
サードパーティのお問い合わせ窓口に関する免責事項
サードパーティのお問い合わせ窓口に関する情報は、ユーザーの便宜のために提供されているものであり、 この連絡先情報は、予告なしに変更される可能性があります。 マイクロソフトは、掲載されている情報に対して、いかなる責任も負わないものとします。
サードパーティの情報に関する免責事項
この資料に記載されているサードパーティ製品は、マイクロソフトと関連のない他社の製品です。 明示的か黙示的かにかかわらず、これらの製品のパフォーマンスや信頼性についてマイクロソフトはいかなる責任も負わないものとします。
お問い合わせはこちらから
質問がある場合やヘルプが必要な場合は、サポート要求を作成するか、Azure コミュニティ サポートにお問い合わせください。 Azure フィードバック コミュニティに製品フィードバックを送信することもできます。