ソリューション アーキテクチャを調べる
機械学習運用 (MLOps) ワークフローに対して決定したアーキテクチャを確認して、コードを検証する場所とタイミングを理解しましょう。
注意
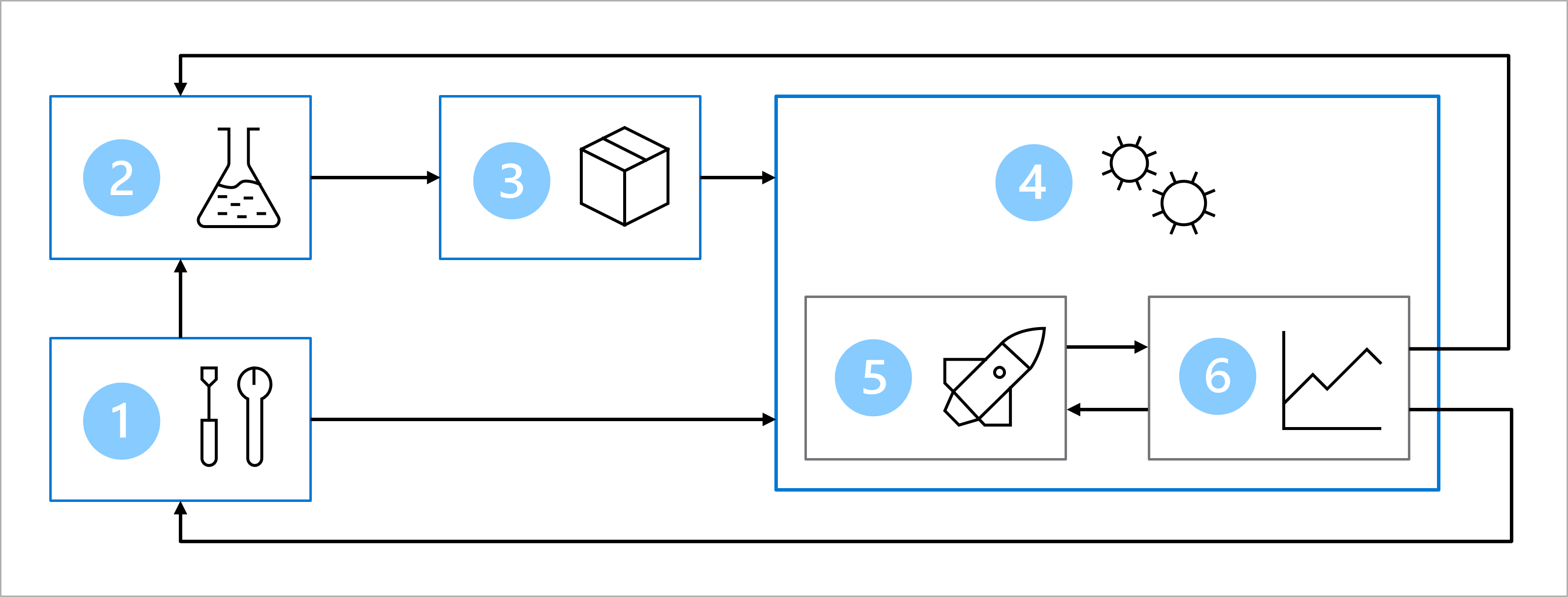
この図は、MLOps アーキテクチャを簡略化したものです。 より詳細なアーキテクチャを表示するには、MLOps (v2) ソリューション アクセラレータのさまざまなユース ケースをご確認ください。
MLOps アーキテクチャの主な目標は、堅牢で再現可能なソリューションを作成することです。 これを実現するために、アーキテクチャに次のものが含まれます。
- セットアップ: ソリューションに必要なすべての Azure リソースを作成します。
- モデル開発 (内部ループ): モデルをトレーニングおよび評価するためのデータを探して処理します。
- 継続的インテグレーション: モデルをパッケージ化して登録します。
- モデル デプロイ (外部ループ): モデルをデプロイします。
- 継続的デプロイ: モデルをテストし、運用環境にレベル上げします。
- 監視: モデルとエンドポイントのパフォーマンスを監視します。
モデルを開発からデプロイに移行するには、継続的インテグレーションが必要です。 継続的インテグレーション時に、モデルをパッケージ化して登録します。 しかし、モデルをパッケージ化する前に、モデルのトレーニングに使用するコードを検証する必要があります。
データ サイエンス チームと共に、トランクベースの開発を使用することに同意しました。 ブランチでは運用コードを保護するだけでなく、提案された変更を運用コードとマージする前に自動的に検証することもできます。
データ サイエンティストのワークフローを見てみましょう。
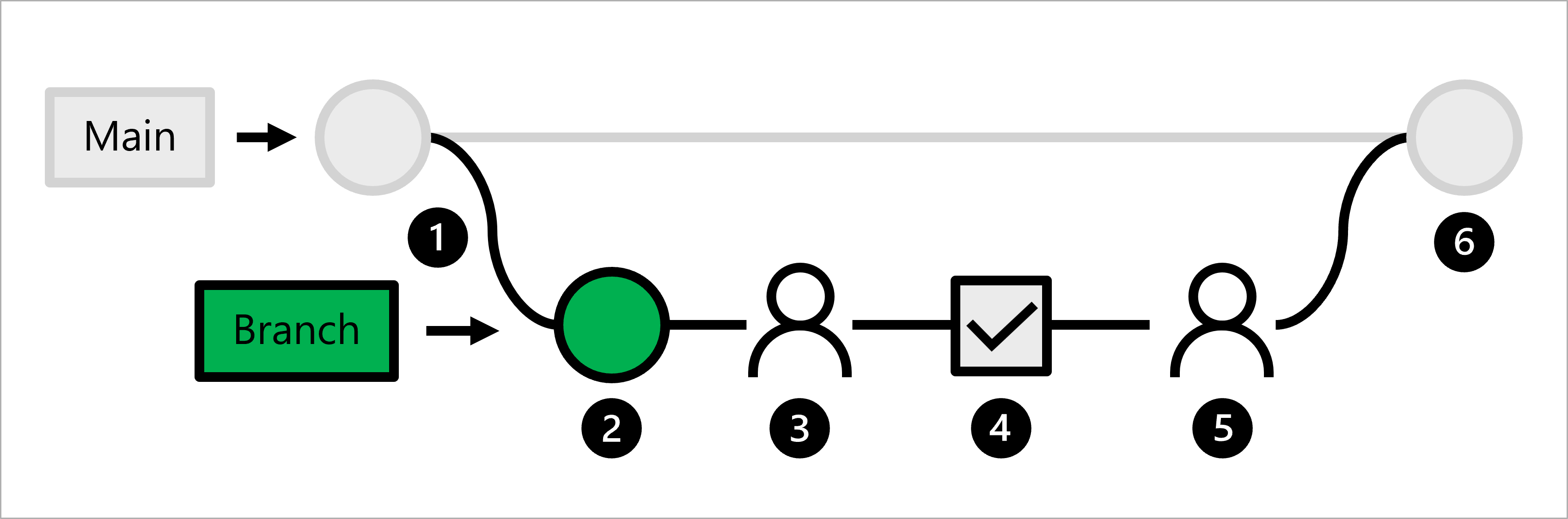
- 運用コードは、メイン ブランチにホストされます。
- データ サイエンティストは、モデル開発用の機能ブランチを作成します。
- データ サイエンティストは、変更をメイン ブランチにプッシュすることを提案する pull request を作成します。
- pull request が作成されると、コードを検証するために GitHub Actions ワークフローがトリガーされます。
- コードがリンティングおよび単体テストに合格したら、リード データ サイエンティストが提案された変更を承認する必要があります。
- リード データ サイエンティストが変更を承認した後、pull request がマージされ、それに応じてメイン ブランチが更新されます。
機械学習エンジニアは、pull request が作成されるたびにリンターおよび単体テストを実行してコードを検証する GitHub Actions ワークフローを作成する必要があります。
ヒント
詳細については、トランクベースの開発やコードのローカルでの検証など、機械学習プロジェクトのソース管理を操作する方法に関するページを参照してください。