デルタ テーブルを最適化する
Spark は並列処理フレームワークであり、データは 1 つまたは複数のワーカー ノードに格納されます。 しかも、Parquet ファイルは不変であるため、更新または削除のたびに新しいファイルが書き込まれます。 この構造上、Spark のデータは多数の小さいファイルに格納される可能性があり、"微小ファイル問題" と呼ばれる問題、つまり、大量のデータに対するクエリの低速化や完了不可のエラーが発生します。
OptimizeWrite 関数
OptimizeWrite は、書き込まれるファイルの個数を少なくする Delta Lake の機能です。 この機能には、書き込みを少数の大きいファイルにまとめ、多数の小さいファイルが作成されることを防ぐ働きがあります。 したがって、"微小ファイルの問題" を防ぎ、パフォーマンスの低下を防ぐために役立ちます。
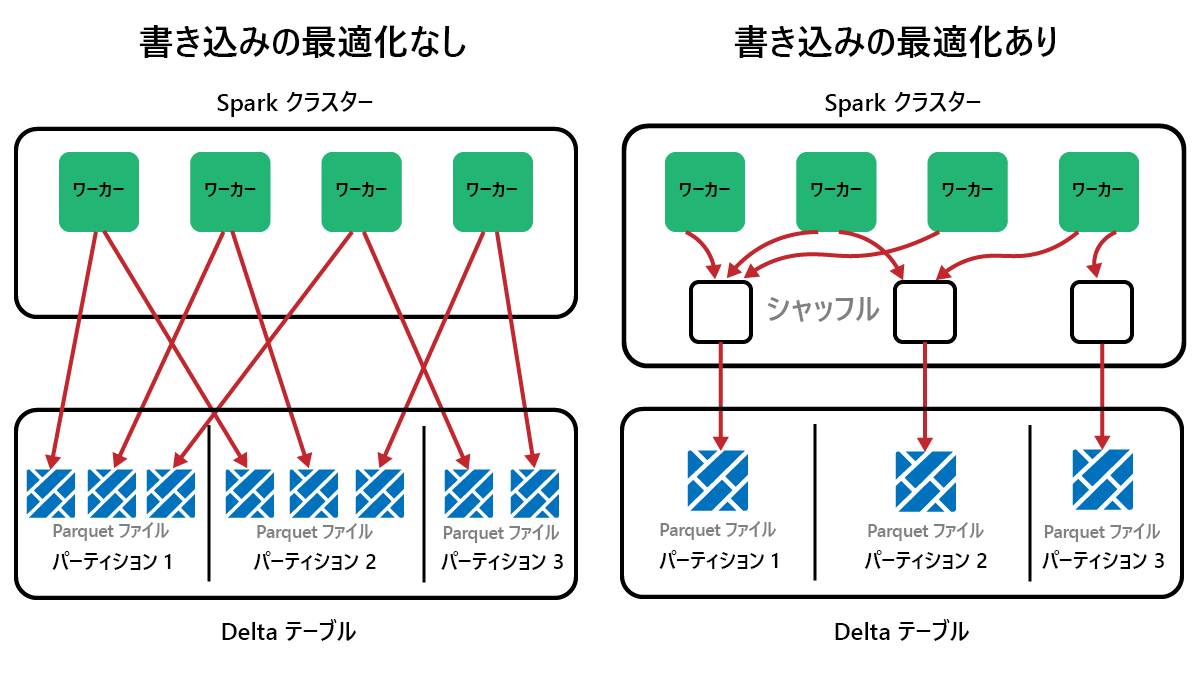
Microsoft Fabric では、OptimizeWrite は既定で有効になっています。 この設定は、以下のようにして Spark セッション レベルで有効または無効にすることができます。
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Note
また、OptimizeWrite をテーブルのプロパティで設定することや、個別の書き込みコマンドに指定することもできます。
最適化
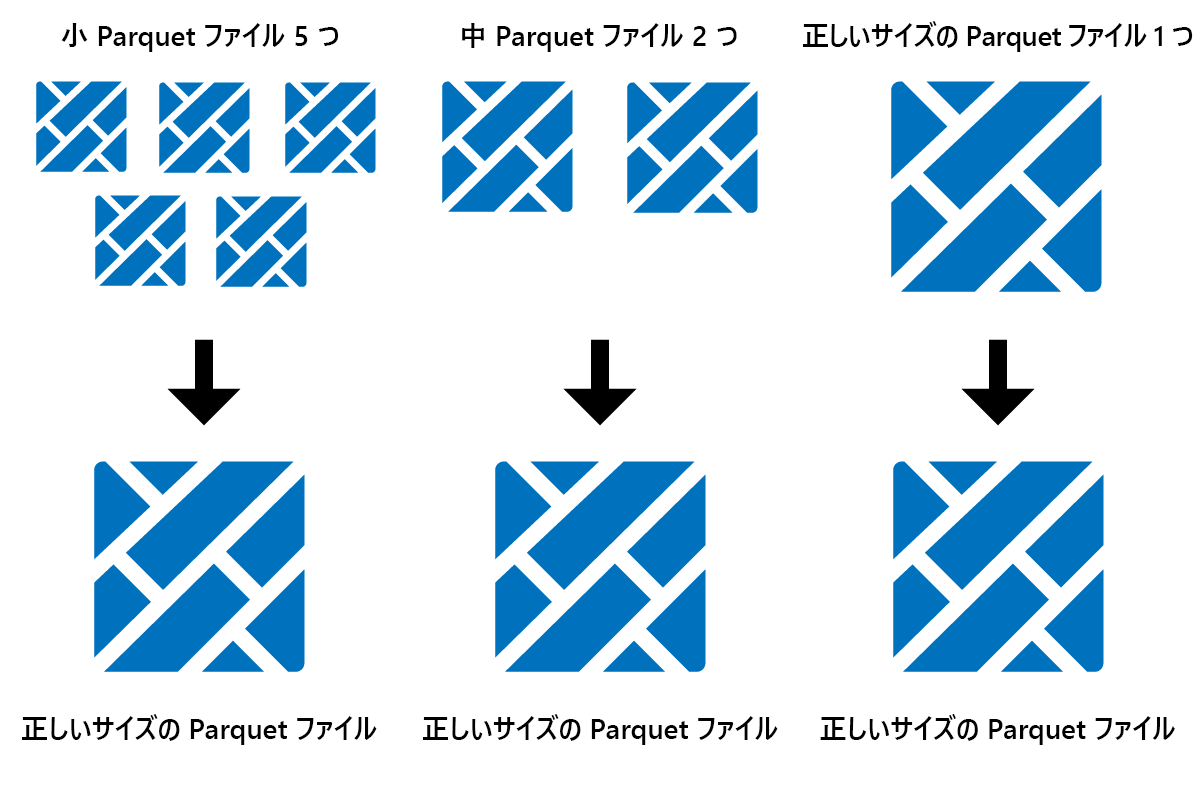
Optimize は、小さい Parquet ファイルを少数の大きいファイルにまとめるテーブル メンテナンス機能です。 大きいテーブルを読み込んだ後に Optimize を実行すると、以下の効果が得られます。
- データを少数の大きいファイルに集約
- 圧縮率を向上
- ノード間のデータ分散を効率化
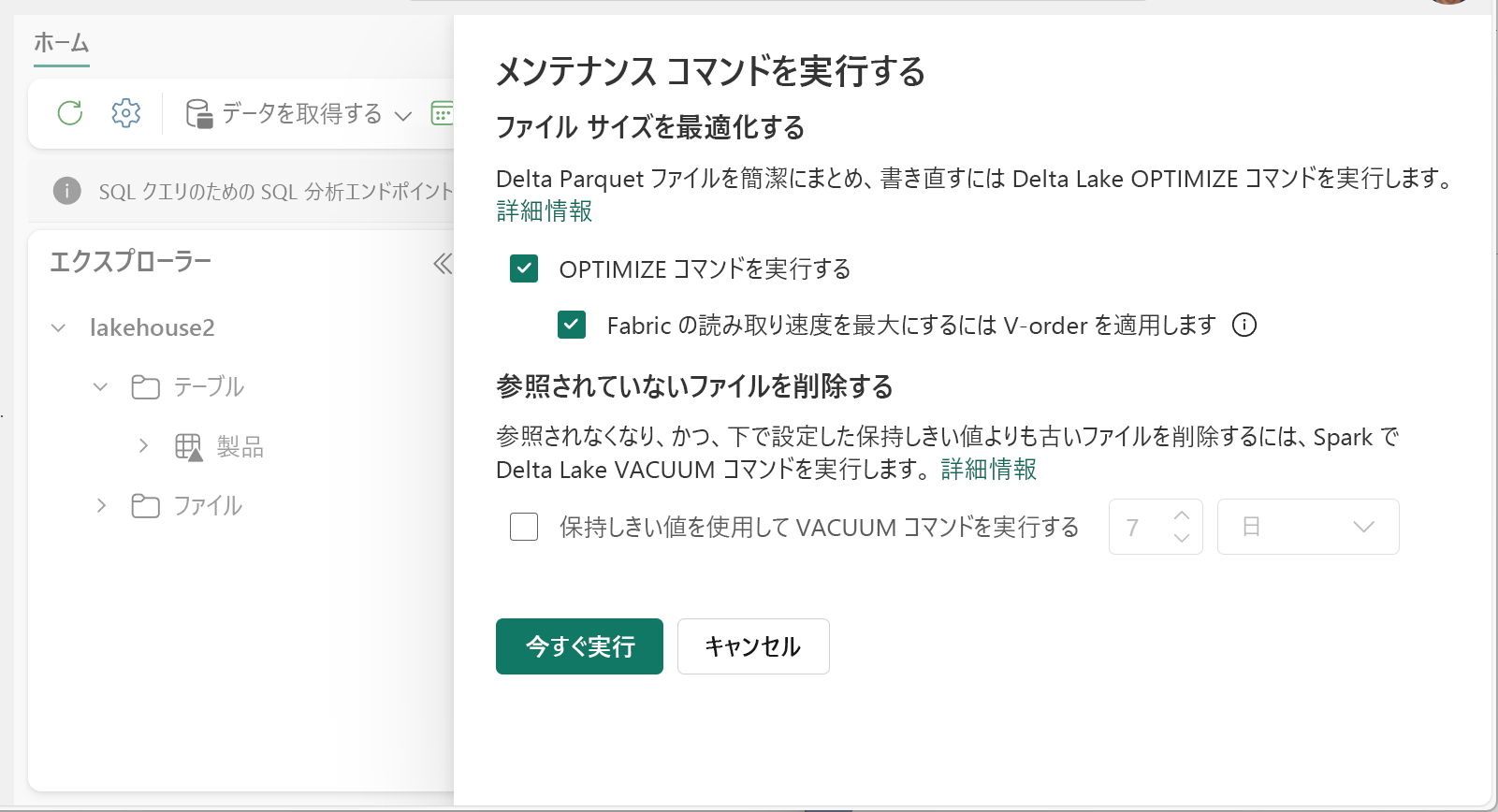
Optimize を実行する方法:
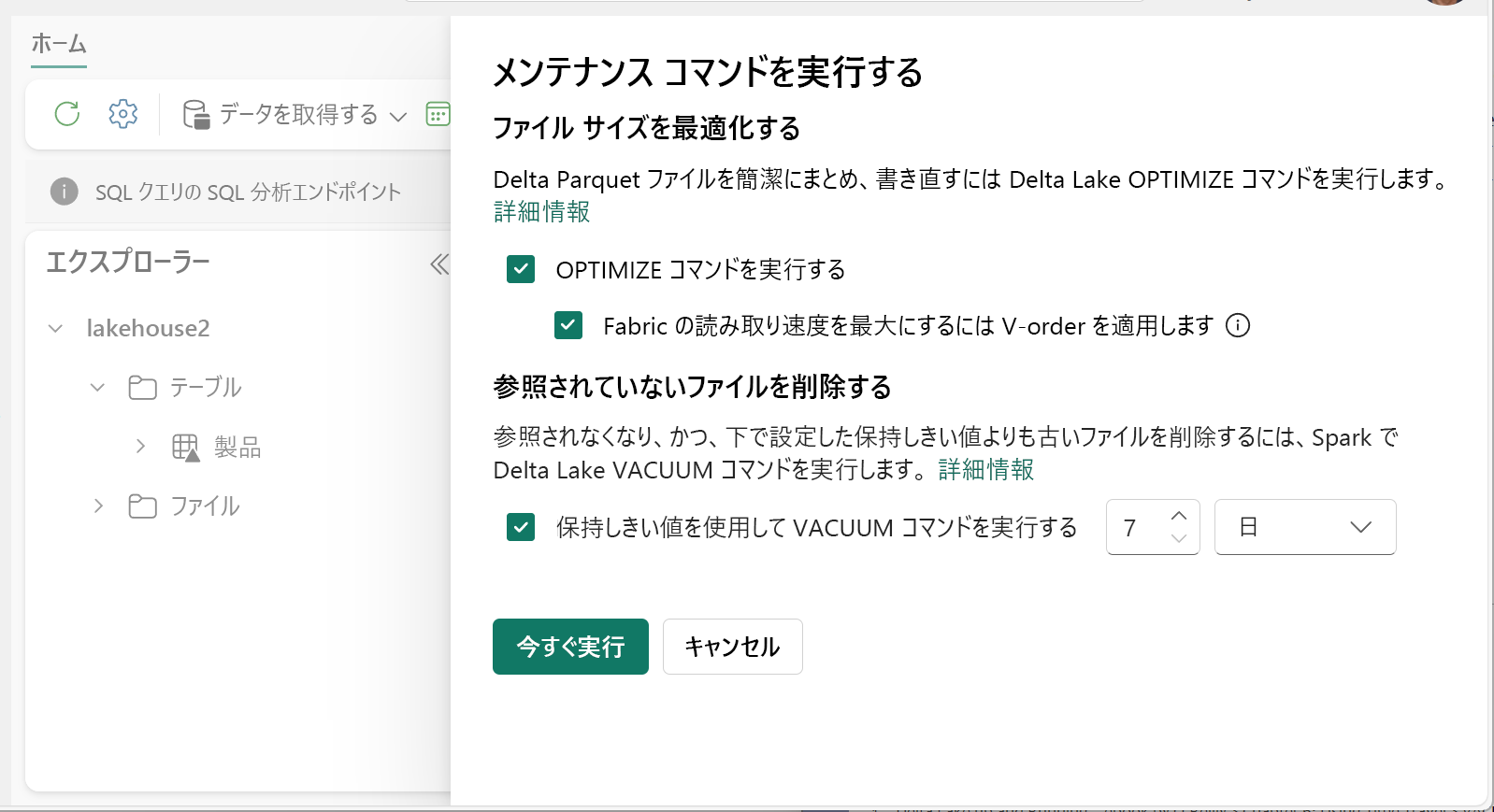
- レイクハウス エクスプローラーで、テーブル名の横の [...] メニューを選択し、[メンテナンス] を選択します。
- [OPTIMIZE コマンドを実行する] を選択します。
- 必要に応じて、[Fabric での読み取り速度を最大化するために V オーダーを適用する] を選択します。
- [今すぐ実行] を選択します。
V オーダー機能
Optimize を実行する際には、必要に応じて、Fabric の Parquet ファイル形式向けに設計された V オーダーを適用できます。 V オーダーには、インメモリに近いデータアクセス時間での超高速読み取りを可能にする働きがあります。 また、読み取り時のネットワーク、ディスク、CPU リソース負荷を軽減してコスト効率を高める効果があります。
Microsoft Fabric では V オーダーが既定で有効になっており、データの書き込み時に適用されます。 V オーダーには約 15% の小さなオーバーヘッドがあり、書き込みがやや低速になります。 しかし、V オーダーを使用すると、Power BI、SQL、Spark などの Microsoft Fabric コンピューティング エンジンでの読み取りが高速化されます。
Microsoft Fabric では、Power BI エンジンと SQL エンジンに、V オーダー最適化効果を最大限に活用して読み取りの高速化を実現する Microsoft Verti-Scan テクノロジが採用されています。 Spark やその他のエンジンにおいても、VertiScan テクノロジの採用はありませんが V オーダー最適化のメリットを享受でき、約 10% (場合により最大 50%) の読み取り速度向上効果が得られます。
V オーダーは、特殊な並べ替え、行グループの配布、辞書のエンコード、Parquet ファイルへの圧縮を適用することによって機能します。 オープンソースの Parquet 形式に 100% 準拠しているため、すべての Parquet エンジンで読み取り可能です。
V オーダーは、書き込みの比重が大きいシナリオには適さないことがあります。たとえば、ステージング データ ストアなどでデータの読み取りが 1 回か 2 回しか実行されない場合にはメリットが得られません。 そのようなシナリオでは、V オーダーを無効にしたほうがデータ インジェストの全体的な処理時間を短縮できることがあります。
テーブル メンテナンス機能を使用して OPTIMIZE コマンドを実行し、個々のテーブルに V オーダーを適用します。
VACUUM
VACUUM コマンドでは、古いデータ ファイルを削除できます。
更新や削除が実行されると、そのたびに新しい Parquet ファイルが作成され、トランザクション ログにエントリが作成されます。 古い Parquet ファイルはタイム トラベル用に保持されるため、時間が経つにつれて多数の Parquet ファイルが蓄積されていきます。
VACUUM コマンドを実行すると古い Parquet データ ファイルが削除され、トランザクション ログは削除されずに残ります。 VACUUM を実行した場合、タイム トラベルで保持期間以前まで遡ることはできなくなります。
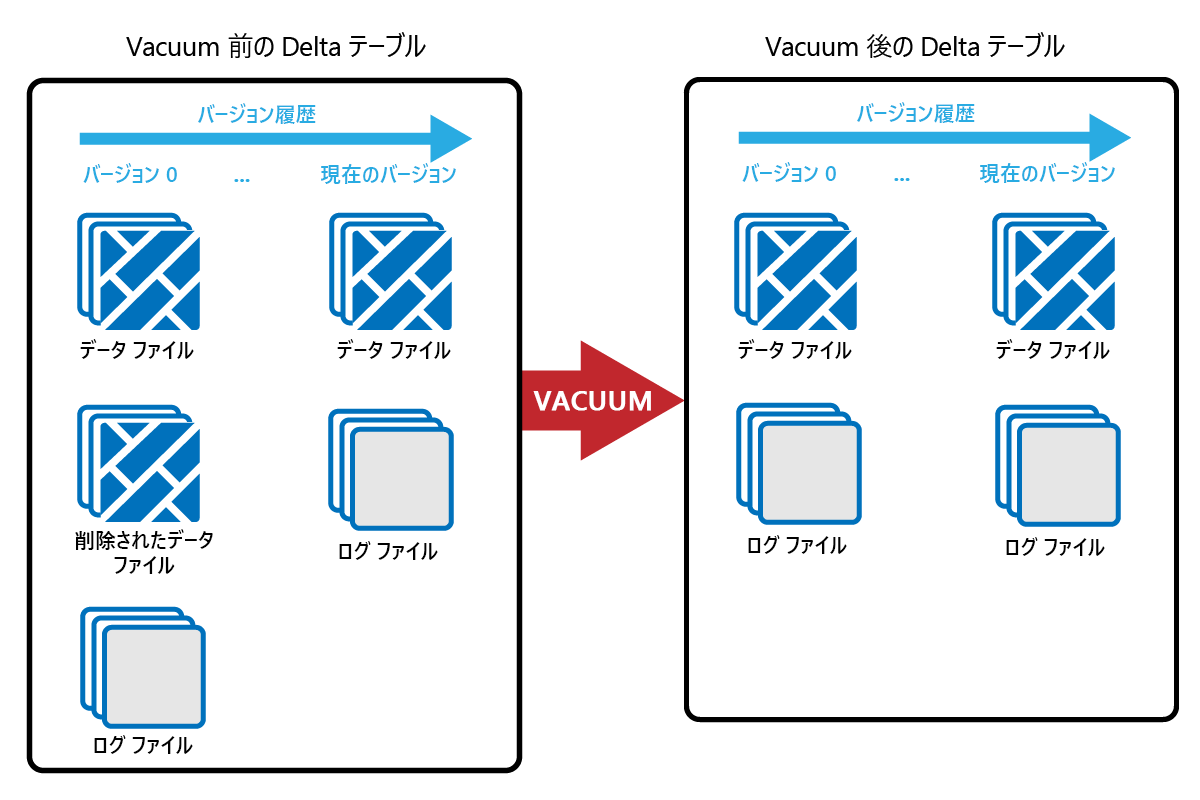
データ ファイルのうち、トランザクション ログで現在参照されておらず、指定された保持期間よりも古いものは、VACUUM を実行すると完全に削除されます。 保持期間を選択する際は以下のような要素を考慮してください。
- データ保持の要件
- データ サイズとストレージ コスト
- データの変更頻度
- 規制による要件
既定の保持期間は 7 日間 (168 時間) で、これよりも短い保持期間を設定することはできません。
VACUUM は、アドホック ベースで実行することも、Fabric ノートブックでスケジュールを設定して実行することもできます。
テーブル メンテナンス機能を使用し、個々のテーブルに対して VACUUM を実行します。
- レイクハウス エクスプローラーで、テーブル名の横の [...] メニューを選択し、[メンテナンス] を選択します。
- [保持しきい値を使用して VACUUM コマンドを実行する] を選択し、保持しきい値を設定します。
- [今すぐ実行] を選択します。
以下のように、ノートブックで VACUUM を SQL コマンドとして実行することもできます。
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM は Delta トランザクション ログにコミットするため、DESCRIBE HISTORY で以前の実行を確認できます。
%%sql
DESCRIBE HISTORY lakehouse2.products;
Delta テーブルのパーティション分割
Delta Lake では、データをパーティションに分けて整理できます。 パーティション分割を使用すると、"データ スキップ" (オブジェクトのメタデータに基づいて無関係なデータ オブジェクトをスキップする手法) が可能になる場合があり、パフォーマンスの向上につながる可能性があります。
たとえば、これから大量の販売データが格納される場合について考えてみましょう。 この状況で、売上データを年ごとに分割するとします。 パーティションは、"year=2021"、"year=2022" などの名前が付いたサブフォルダーに保存されます。2024 年の売上データのみについてレポートを作成する場合は、その他の年のパーティションをスキップすることで読み取りパフォーマンスを向上できます。
ただし、データ量が少ない場合にパーティション分割を使用するとパフォーマンスが低下する可能性もあります。これは、ファイルの数が増えて "微小ファイル問題" が悪化するおそれがあるためです。
以下のような場合、パーティション分割は効果的です。
- データ量が非常に多い。
- テーブルを少数の大きいパーティションに分割できる。
以下のような場合、パーティション分割は適していません。
- データ量が少ない。
- パーティション分割列のカーディナリティが大きく、作成するパーティションの数が多くなる。
- 1 つのパーティション分割列に複数のレベルが発生する可能性がある。
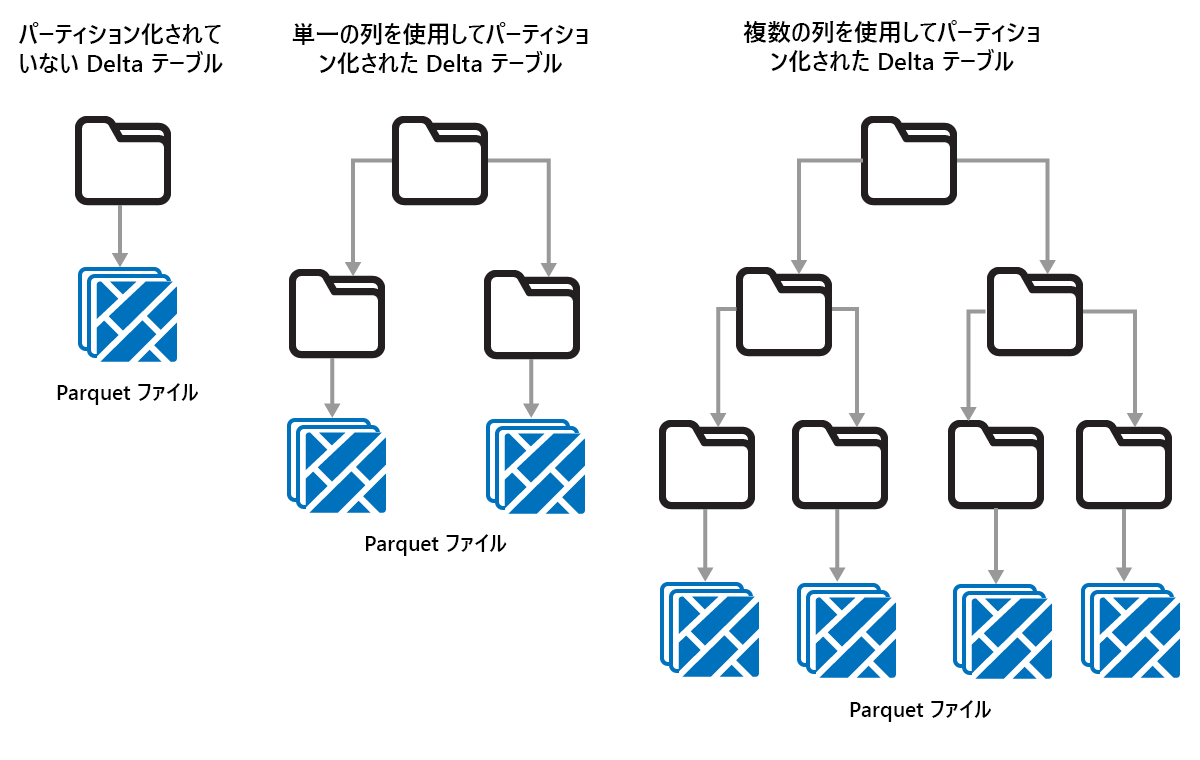
パーティションは固定データ レイアウトであり、さまざまに異なるクエリ パターンには適応できません。 パーティション分割の使用方法を検討する際は、データの実際の使われ方と粒度を考慮してください。
この例では、製品データを含む DataFrame が Category に基づいてパーティション分割されています。
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
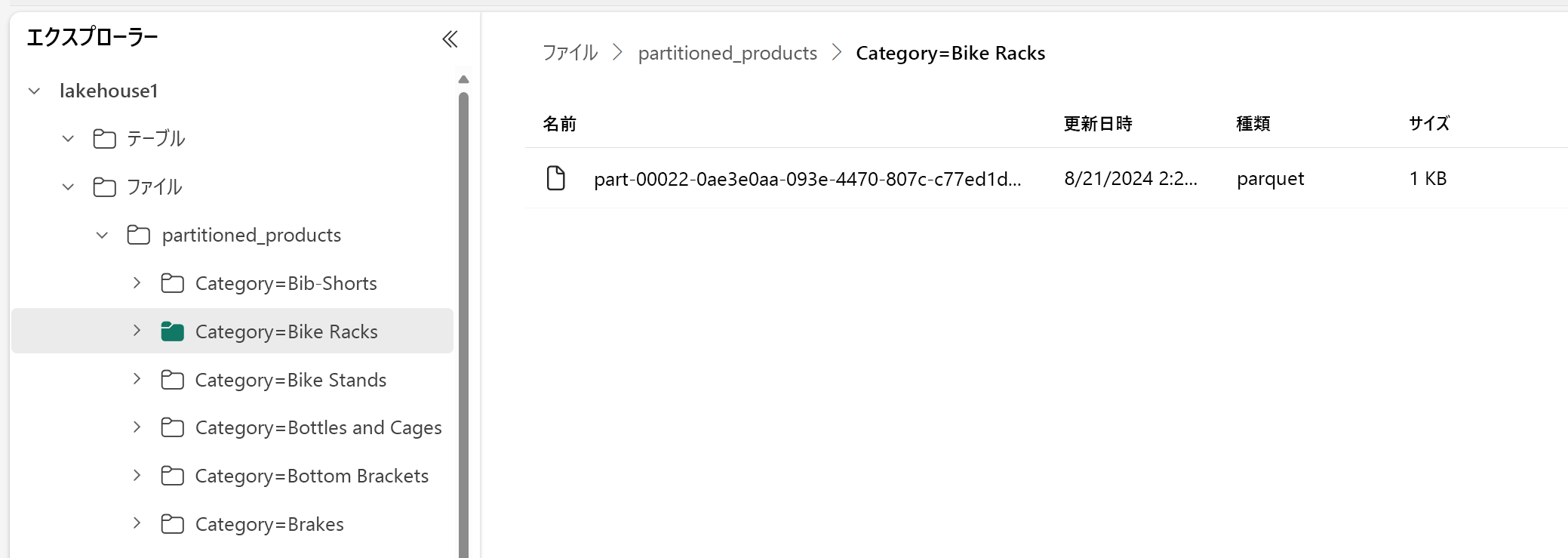
レイクハウス エクスプローラーに、このデータはパーティション分割されたテーブルであることが示されています。
- そのテーブル用の、"partitioned_products" というフォルダーが 1 つあります。
- 個々のカテゴリに対応したサブフォルダー ("Category=Bike Racks" など) があります。
これと同様のパーティション分割テーブルを SQL で作成するには以下のようにします。
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);