ノートブックで Spark を使用する
Python または Scala スクリプトのコード、Java アーカイブ (JAR) としてコンパイルされた Java コードなど、さまざまな種類のアプリケーションを Spark で実行できます。 Spark は、一般的に次の 2 種類のワークロードで使用されます。
- データの取り込み、クリーニング、変換を行うバッチ処理ジョブまたはストリーム処理ジョブ。多くの場合、自動化されたパイプラインの一部として実行されます。
- データの探索、分析、視覚化を行う対話型分析セッション。
ノートブックでの Spark コードの実行
Azure Databricks には、Spark を操作するための統合ノートブック インターフェイスが含まれています。 ノートブックは、コードと Markdown ノートを組み合わせる直感的な方法を提供します。これは、データ科学者やデータ アナリストによってよく使用されます。 Azure Databricks 内の統合されたノートブック エクスペリエンスの外観は、一般的なオープンソースのノートブック プラットフォームである Jupyter ノートブックと似ています。
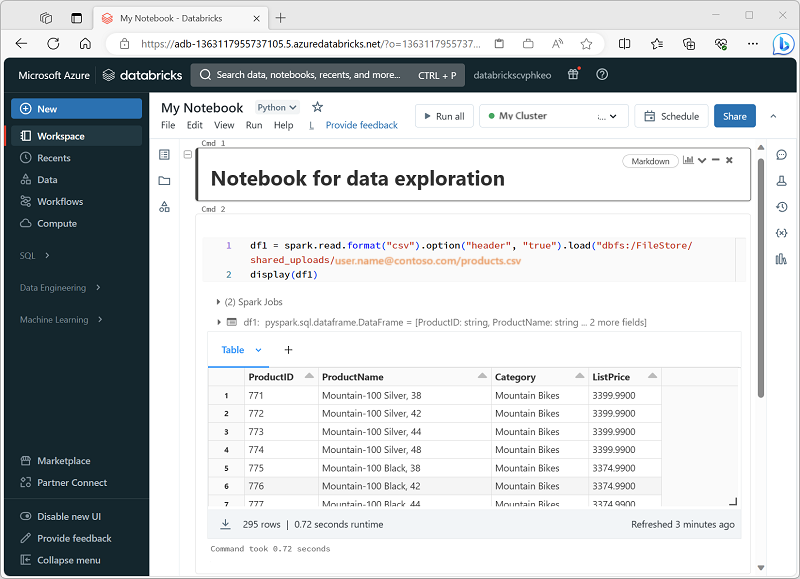
ノートブックは 1 つ以上の "セル" で構成され、それぞれにコードまたはマークダウンが含まれています。 ノートブックのコード セルには、次のような生産性を高めるのに役立ついくつかの機能があります。
- 構文の強調表示とエラーのサポート。
- コードのオートコンプリート。
- 対話型のデータ視覚化。
- 結果をエクスポートする機能。
ヒント
Azure Databricks でのノートブックの使用について詳しくは、Azure Databricks のドキュメントの記事「ノートブック」をご覧ください。