Spark について知る
Azure Databricks で Apache Spark を使ってデータを処理および分析する方法をいっそうよく理解するには、基になっているアーキテクチャを理解することが重要です。
概要
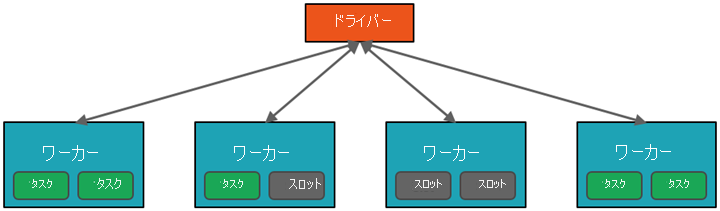
上位レベルから見ると、Azure Databricks サービスでは、Azure サブスクリプション内で Apache Spark クラスターが起動され、管理されます。 Apache Spark クラスターは 1 台のコンピューターとして扱わるコンピューターのグループで、ノートブックから発行されたコマンドの実行を処理します。 クラスターを使うと、データの処理を多くのコンピューターで並列化して、スケールとパフォーマンスを向上させることができます。 これらは、Spark の "ドライバー" ノードと "ワーカー" ノードで構成されます。 ドライバー ノードはワーカー ノードに作業を送信し、指定したデータ ソースからデータをプルするように指示します。
Databricks では、通常、ノートブック インターフェイスがドライバー プログラムです。 このドライバー プログラムは、プログラムのメイン ループを含み、クラスターに分散データセットを作成してから、それらのデータセットに操作を適用します。 ドライバー プログラムは、デプロイの場所に関係なく、SparkSession オブジェクトを通して Apache Spark にアクセスします。
Microsoft Azure はクラスターを管理し、使用量とクラスターの構成時に使用した設定に基づいて、必要に応じて自動スケーリングします。 自動終了を有効にすることもでき、これにより Azure は、指定された非アクティブな時間 (分) 後にクラスターを終了できます。
Spark ジョブの詳細
クラスターに送信された作業は、必要な数の独立したジョブに分割されます。 このような方法で、作業はクラスターのノード全体に分散されます。 ジョブはさらにタスクに分割されます。 1 つのジョブへの入力は、1 つまたは複数のパーティションに分割されます。 これらのパーティションは、各スロットの作業単位です。 タスクの間で、パーティションを再編成し、ネットワーク経由で共有することが必要になる場合があります。
Spark のハイ パフォーマンスの秘密は並列処理です。 "垂直方向" のスケーリング (1 台のコンピューターにリソースを追加します) は、有限の量の RAM、スレッド、CPU 速度に制限されます。一方、クラスターは "水平方向" にスケーリングし、必要に応じて新しいノードがクラスターに追加されます。
Spark では、2 つのレベルでジョブが並列化されます。
- 第 1 のレベルの並列化は Executor です。これは、ワーカー ノード上で実行される Java 仮想マシン (JVM) であり、通常はノードごとに 1 つのインスタンスです。
- 第 2 のレベルの並列化は "スロット" で、その数は各ノードのコアと CPU の数によって決まります。
- 各 Executor には、並列化されたタスクを割り当てることができる複数のスロットがあります。
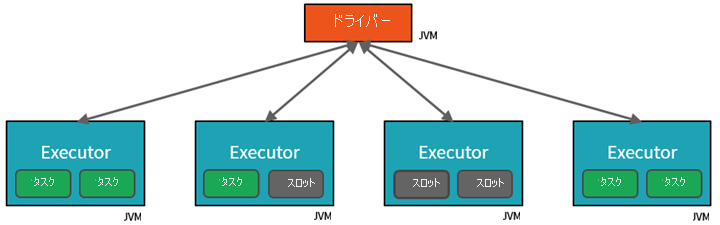
JVM はもともとマルチスレッドですが、単一の JVM (ドライバーでの作業を調整するものなど) には有限の上限があります。 作業をタスクに分割することで、ドライバーは、並列実行のためにワーカー ノード上の Executor の*スロットに作業単位を割り当てることができます。 さらに、ドライバーによって、並列処理のために分散できるようデータをパーティション分割する方法が決定されます。 そのため、ドライバーは各タスクにデータのパーティションを割り当てて、処理するデータの部分を各タスクが認識できるようにします。 開始すると、各タスクは自分に割り当てられたデータのパーティションをフェッチします。
ジョブとステージ
実行されている作業によっては、複数の並列化されたジョブが必要になる場合があります。 各ジョブは "ステージ" に分割されます。 わかりやすくたとえるなら、ジョブを、家を建てることと考えてください。
- 最初のステージでは、基礎を構築します。
- 2 番目のステージでは、壁を立てます。
- 3 番目のステージは、屋根を追加することです。
これらのステップのいずれかを異なる順番で行うのは、意味がないだけでなく、実際に不可能な場合もあります。 同様に、Spark は各ジョブをステージに分割して、すべてが適切な順序で実行されるようにします。
モジュール性
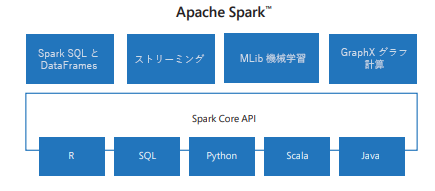
Spark には、SQL からストリーミング、機械学習に至るまでのタスク用のライブラリが含まれており、データ処理タスク用のツールになります。 Spark ライブラリには次のようなものがあります。
- Spark SQL:構造化データの操作用。
- SparkML:機械学習用。
- GraphX:グラフ処理用。
- Spark Streaming:リアルタイム データ処理用。
互換性
Spark は、Hadoop YARN、Apache Mesos、Kubernetes、または Spark 独自のクラスター マネージャーなど、さまざまな分散システム上で実行できます。 また、HDFS、Cassandra、HBase、Amazon S3 などのさまざまなデータ ソースの読み取りと書き込みも行います。