レプリケーションと論理デコードについて説明する
パラメーター wal_level を使うと、ログに書き込む必要がある情報の量を定義できます。 LOGICAL または REPLICA の 2 つのオプションがあります。 REPLICA が既定値です。 このパラメーターは、サーバーの起動時に設定されます。
高可用性
高可用性は Azure Database for PostgreSQL のサービスであり、ライブ サーバーで障害が発生した場合に引き継ぐことができるスタンバイ サーバーを提供します。 Azure Database for PostgreSQL フレキシブル サーバーの高可用性では、レプリケーションを使って、データの変更でスタンバイ サーバーが自動的に更新されます。
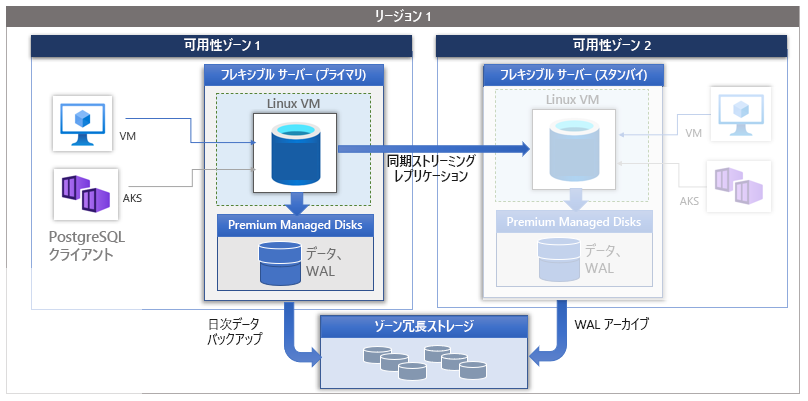
Azure Database for PostgreSQL フレキシブル サーバーの高可用性を構成すると、プライマリ サーバーが 1 つの可用性ゾーンに配置され、スタンバイ サーバーが別の可用性ゾーンに作成されます。 データは、PostgreSQL のストリーミング レプリケーションを同期モードで使って、プライマリ サーバーからスタンバイ サーバーにレプリケートされます。
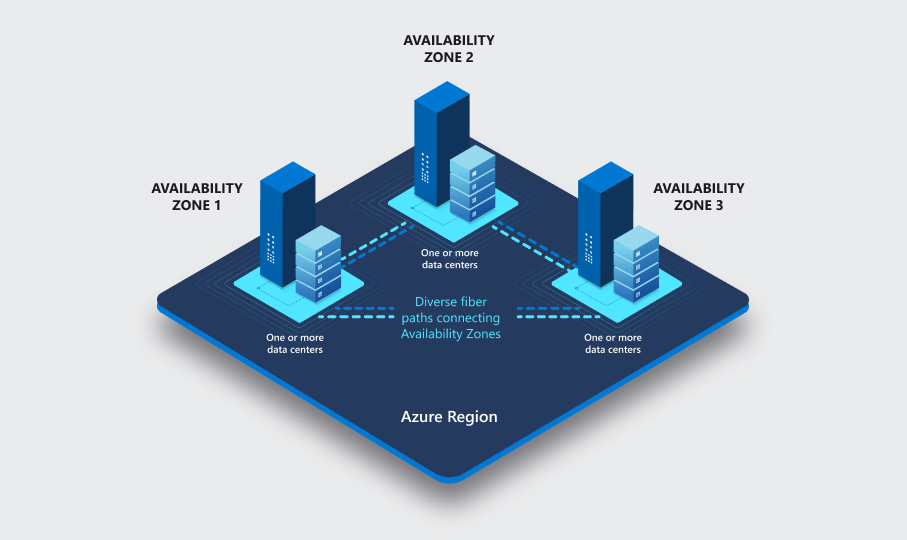
各可用性ゾーンは、1 つ以上のデータセンターで構成されます。 可用性ゾーンは、独自の電源、冷却システム、ネットワーク インフラストラクチャなどを備えており、互いに独立しています。 データ ファイルと先書きログ (WAL) ファイルの 3 つのコピーが、各可用性ゾーン内のローカル冗長ストレージに格納され、プライマリ サーバーとスタンバイ サーバーの間の物理的な分離を実現します。 1 つの可用性ゾーンで障害が発生した場合、他の 2 つは動作し続ける可能性が高いです。 リージョン内の可用性ゾーンは、ラウンドトリップ待機時間が 2 ミリ秒未満の高速ファイバー ネットワークによって接続されます。
Note
すべてのリージョンに可用性ゾーンがあるわけではありません。
高可用性では、データベースが使われている間は常にデータが複製され、元のデータの最新のコピーが提供されます。 クラッシュが発生した場合は、元のデータベースの代わりにレプリカを使用できます。 レプリケーションには、プライマリ サーバーとスタンバイ サーバーがあります。 プライマリ サーバーは、スタンバイ サーバーに WAL ログ ファイルを送信します。
スタンバイ サーバーは、書き込んだ最後の先書きログや、ディスクにフラッシュした最後の位置などの情報を使用して、プライマリ サーバーに報告します。WAL レシーバーがレポートを送り返す最小頻度を定義するには、wal_receiver_status_interval パラメーターを設定します。 max_replication_slots パラメーターは、サーバーがサポートできるレプリケーション スロットの最大数を定義します。 wal_level が REPLICA に設定されている場合、max_replication_slots は 1 以上にする必要があります。ただし、許容される値の範囲は 0 から 262,143 です。
max_wal_senders パラメーターは、WAL センダー プロセスの最大数を設定します。
プライマリとスタンバイ サーバーは監視され、スタンバイ サーバーへのフェールオーバーのトリガーなど、問題を修復するための適切なアクションが実行されます。 ゾーン冗長の高可用性の状態は次のとおりです。
- 初期化中 - 新しいスタンバイ サーバーの作成中です。
- レプリケート中 - データ レプリケーションは安定状態にあり、正常です。
- 正常 - スタンバイはプライマリによって更新されています。
- フェールオーバー中 - プライマリ データベース サーバーはスタンバイにフェールオーバー中です。
- スタンバイ削除中 - スタンバイ サーバーの削除中です。
- 無効 - ゾーン冗長高可用性は有効になっていません。
既存のデータベース サーバーに高可用性を追加できます。 ライブ サーバーで高可用性を有効または無効にする場合は、アクティビティがほとんどないときに操作を実行します。
Azure ポータルで次の手順を実行します。
- お使いの Azure Database for PostgreSQL サーバーに移動します。
- [概要] セクションで、現在の [構成] を選びます。 [コンピューティングとストレージ] セクションが表示されます。
- [高可用性] で、[High Availability (zone redundant)] (高可用性 (ゾーン冗長)) チェック ボックスをオンにして高可用性を有効にします。 高可用性は、バースト可能レベルではサポートされていません。
高可用性はディザスター リカバリー オプションであることに注意することが重要です。 読み取り専用データベースへのアクセスの許可など、他の目的にスタンバイ サーバーを使うことはできません。 ただし、パブリッシャーとサブスクライバー モデルを使って、2 つの Azure Database for PostgreSQL サーバー間のレプリケーションを構成することはできます。 この構成により、サーバー間でレプリケートされるデータを使用して 2 つのサーバーが維持されます。 その後は、サブスクライバー サーバーにフル アクセスでき、任意の目的でデータベースを使用できます。 このモジュールの最後の演習では、この構成について練習します。
論理デコード
論理デコードでは、先書きログに送信されたデータも使われます。 名前が示すように、先書きログのエントリをデコードして理解できるようにします。 INSERT、UPDATE、DELETE のすべての変更を、論理デコードに使用できます。
論理デコードは、監査、分析、または何がいつ変更されたかを知ることに関心があるその他の理由で、使用できます。
論理デコードでは、データベース内のすべてのテーブルから変更が抽出されます。 レプリケーションとは異なり、これらの変更を別の PostgreSQL インスタンスに送信することはできません。 代わりに、PostgreSQL 拡張機能には、変更をストリーミングするための出力プラグインが用意されています。
論理デコードを使うと、先書きログの内容をわかりやすい形式にデコードできます。これは、データベースの構造の知識がなくても解釈できます。 Azure Database for PostgreSQL は、Azure Database for Postgres サーバーにインストールされている wal2json 拡張機能を使用した論理デコードをサポートしています。
レプリケーションを論理ストリーミングできる pglogical 拡張機能など、他の拡張機能を使用できます。
論理デコードを使うには、[サーバー パラメーター] で以下を設定します。
- wal_level を LOGICAL
- max_replication_slots = 10
- max_wal_senders = 10
これらの変更を行った後、サーバーを再起動する必要があります。
Azure portal から pglogical 拡張機能を使用するには:
- お使いの Azure Database for PostgreSQL サーバーに移動します。
- [サーバー パラメーター] を選び、shared_preload_libraries を見つけます。 ドロップダウン ボックスから、pglogical を選びます。
- azure.extensions を見つけます。 ドロップダウン ボックスから、pglogical を選びます。
- 変更を適用するには、サーバーを再起動します。
レプリケーションに対する管理者ユーザーのアクセス許可も付与する必要があります。
ALTER ROLE <adminname> WITH REPLICATION;
詳しくは、pglogical 拡張機能のオンライン ドキュメントをご覧ください。
論理デコードでは、論理レプリケーション スロットと呼ばれるストリームとして、データの変更が出力されます。
- 各スロットには 1 つの出力プラグインがあり、定義することができます。
- 各スロットでは 1 つのデータベースからの変更のみが提供されますが、1 つのデータベースで複数のスロットを使用できます。
- 通常、各データ変更はスロットごとに 1 回出力されます。
- PostgreSQL が再起動すると、スロットが変更を再出力する可能性があり、クライアントはそれを処理する必要があります。
- スロットを監視する必要があります。 未使用のスロットは、すべての WAL ファイルをそれらの未使用の変更のために保持します。 この状況の結果、ストレージがいっぱいになったり、トランザクション ID が最初に戻ったりする可能性があります。