統計を理解する
クエリを実行するときは、データへのアクセス方法を決定するプランを作成する必要があります。 たとえば、SELECT クエリがすべての行を返す場合、インデックスを使用してもメリットはなく、テーブル全体をスキャンする方が効率的です。 このシナリオでは、クエリを計画するのは簡単ですが、ほとんどのクエリ プランは簡単に解決できません。
$10.00 から $20.00 の間のすべての注文を検索するクエリを実行しているシナリオを想像してみてください。 最初は、クエリがテーブル内のすべてのデータを返すのか、それとも小さなサブセットしか返さないのかはわかりません。 この不明な場合、データが表示されるまでクエリ戦略を計画するのは困難です。 テーブルに購入価格が $1.00 から $800.00 の注文が含まれていることがわかっている場合は、インデックスを使用してデータの小さなサブセットを検索できます。 ただし、適切なクエリ プランを生成するのに十分な情報がない可能性があります。 この例では、注文の購入価格は $1.00 ~ $800.00 ですが、注文の 95% は $10.00 から $20.00 の間であり、実際にはデータのスキャンが最も効果的なプランです。
前の例のようなシナリオでは、PostgreSQL では、最適なクエリ プランを使用できるように詳細な統計が必要です。
計画と実行の統計を監視するには、pg_stat_statementsと呼ばれる PostgreSQL 拡張機能があります。 pg_stat_statements は Azure Database for PostgreSQL で既定で有効になっており、pg_read_all_stats ロールのメンバーは複数の pg_stat ビューを使用して統計を照会できます。 次のクエリは、pg_stat_activity ビューを使用してクエリ アクティビティを返します。
SELECT * FROM pg_stat_activity;

pg_stat_statementsをオフにする
クエリが一意で、同じクエリを定期的に繰り返さない場合、履歴クエリ データの方が役に立ちません。 また、pg_stat ビューを使用しない場合は、利点はありません。 pg_stat_statementsの維持にはオーバーヘッドがあり、最大で 50%に達する可能性があり、これらのシナリオでは pg_stat_statements の追跡を無効にすることができます。
pg_stat_statementsの追跡を無効にするには、次の手順に従います。
Azure portal に移動し、Azure Database for PostgreSQL サーバーを選択します。
サーバー パラメーターを選択し、pg_stat_statements.track 設定に移動します。
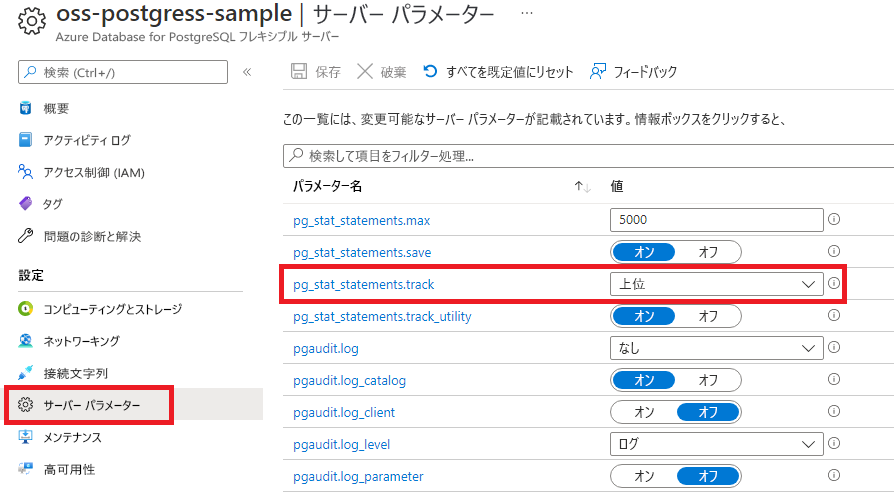
追跡を無効にする場合は、[なし] 選択します。
より正確な追跡を行いたい場合は、ALLを選択します。
既定の設定は TOP です。
を選択して、[保存]します。
