Network Watcher メトリックとログを使用してネットワークのトラブルシューティングを行う
問題をすばやく診断するには、Azure Network Watcher ログで使用可能な情報を理解する必要があります。
あなたは、自分のエンジニアリング会社で、スタッフがネットワーク構成の問題の診断と解決にかける時間を最小限にしたいと考えています。 彼らが、ログごとに得られる情報の内容を確実に認識できるようにしたいと考えています。
このモジュールでは、フロー ログ、診断ログ、トラフィック分析に注目します。 これらのツールが Azure ネットワークのトラブルシューティングにどのように役立つかを学習します。
使用量とクォータ
各 Microsoft Azure リソースは、そのクォータの最大限まで使用できます。 各サブスクリプションには個別のクォータが設けられ、サブスクリプションごとに使用状況が追跡されます。 リージョンごとに 1 サブスクリプションにつき Network Watcher インスタンスが 1 つだけ必要です。 このインスタンスでは、使用量とクォータが表示されるので、クォータに達する可能性があるかどうかを確認できます。
使用量とクォータの情報を表示するには、[すべてのサービス]>[ネットワーク]>[Network Watcher] の順に移動し、[使用量とクォータ] を選択します。 使用量とリソースの場所に基づいて詳細なデータが表示されます。 次のメトリックのデータがキャプチャされます。
- ネットワーク インターフェイス
- ネットワーク セキュリティ グループ (NSG)
- 仮想ネットワーク
- パブリック IP アドレス
ポータルで使用量とクォータが示されている例を次に示します。

ログ
ネットワーク診断ログでは、詳細なデータが提供されます。 このデータを使用すると、接続とパフォーマンスの問題をより理解できるようになります。 Network Watcher には、次の 3 つのログ表示ツールがあります。
- NSG フロー ログ
- 診断ログ
- トラフィック分析
これらの各ツールを見てみましょう。
NSG フロー ログ
NSG フロー ログでは、ネットワーク セキュリティ グループのイングレス IP トラフィックとエグレス IP トラフィックの情報を確認できます。 フロー ログには、フローが適用されるネットワーク アダプターに基づいて、ルールごとの送信および受信フローが示されます。 NSG フロー ログには、キャプチャされた 5 タプルの情報に基づいてトラフィックが許可または拒否されたかどうかが示されます。 この情報には、以下が含まれます。
- 送信元 IP
- 送信元ポート
- 宛先 IP
- 宛先ポート
- プロトコル
次の図は、NSG が従うワークフローを示しています。
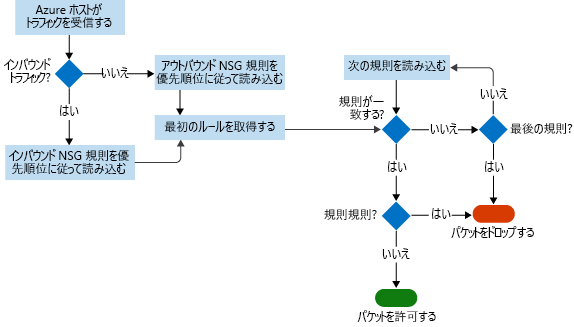
フロー ログでは、データは JSON ファイルに格納されます。 Azure に大規模なインフラストラクチャをデプロイしている場合は特に、ログ ファイルを手動で検索してこのデータに関する分析情報を取得することが困難になる場合があります。 この問題を解決するには、Power BI を使用してください。
Power BI では、以下の方法で NSG フロー ログを視覚化できます。 次に例を示します。
- トップ トーカー (IP アドレス)
- 方向別のフロー (受信および送信)
- 意思決定別のフロー (許可および拒否)
- 宛先ポート別のフロー
Elastic Stack、Grafana、Graylog などのオープンソース ツールを使用して、ログを分析することもできます。
Note
NSG フロー ログでは、Azure クラシック ポータルのストレージ アカウントはサポートされていません。
診断ログ
Network Watcher では、診断ログは、Azure ネットワーク リソースのログを有効または無効にするための中心的な場所です。 これらのリソースには、NSG、パブリック IP、ロード バランサー、アプリ ゲートウェイなどがあります。 目的のログを有効にすると、ツールを使用してログ エントリに対してクエリを実行したりログ エントリを表示したりすることができます。
診断ログを Power BI およびその他のツールにインポートして分析することができます。
トラフィック分析
クラウド ネットワーク全体のユーザーとアプリのアクティビティを調査するには、トラフィック分析を使用します。
このツールを使用すると、サブスクリプション全体のネットワーク アクティビティに関する分析情報が得られます。 開放されているポート、既知の有害なネットワークと通信している VM、トラフィック フロー パターンなど、セキュリティの脅威を診断できます。 トラフィック分析では、Azure リージョンとサブスクリプション全体の NSG フロー ログが分析されます。 このデータを使用して、ネットワーク パフォーマンスを最適化することができます。
このツールでは、Log Analytics が必要です。 Log Analytics ワークスペースは、次のリージョンに存在する必要があります。
ユース ケース シナリオ
次に、Azure Network Watcher のメトリックとログが役に立つ可能性のあるユース ケース シナリオをいくつか見てみましょう。
パフォーマンスの低下を報告する顧客レポート
パフォーマンスの低下を解決するには、問題の根本原因を特定する必要があります。
- サーバーのトラフィックを過度に調整しているか
- VM のサイズはジョブに適しているか
- スケーラビリティのしきい値は適切に設定されているか
- 悪意のある攻撃が発生していないか
- VM ストレージの構成は正しいか
まず、VM のサイズがジョブに適していることを確認します。 次に、VM で Azure Diagnostics を有効にして、CPU 使用率やメモリ使用量など、特定のメトリックについて詳細なデータを取得します。 ポータルを使用して VM 診断を有効にするには、その VM に移動し、[診断設定] を選択して、診断を有効にします。
正常に実行されている VM があるとしましょう。 ただし、その VM のパフォーマンスが最近低下しています。 リソースのボトルネックがあるかどうかを確認するには、キャプチャしたデータを確認する必要があります。
まず、報告された問題の発生前、発生時、発生後にキャプチャされたデータの時間範囲を使用して、パフォーマンスの正確なビューを取得します。 これらのグラフは、同じ期間に異なるリソースの動作を相互参照する場合にも役立ちます。 次のことを確認します。
- CPU のボトルネック
- メモリのボトルネック
- ディスクのボトルネック
CPU のボトルネック
パフォーマンスの問題を調査する場合は、傾向を調べることで、サーバーに影響があるかどうかを把握できます。 傾向を特定するには、ポータルで監視グラフを使用します。 監視グラフには、さまざまな種類のパターンが表示されることがあります。
- 分離されたスパイク。 スパイクは、スケジュールされたタスクや予想されるイベントに関連している可能性があります。 このタスクが何かわかっている場合、それは必要なパフォーマンス レベルで実行されていますか? パフォーマンスに問題がない場合は、容量を増やす必要がない可能性があります。
- スパイクして持続。 新しいワークロードによって、この傾向が生じる場合があります。 VM で監視を有効にして、負荷の原因となっているプロセスを見つけます。 消費量の増加は、非効率的なコードが原因で発生する場合もあれば、新しいワークロードの通常の消費量である場合もあります。 使用量が正常である場合、プロセスは必要なパフォーマンス レベルで動作していますか?
- 一定 VM は常にこのようになっていますか? その場合は、リソースの大部分を消費しているプロセスを特定し、容量を追加することを検討してください。
- 着実に増加。 使用量が持続的に増加していますか? その場合、この傾向は、非効率的なコードや、より多くのユーザー ワークロードを処理するプロセスを示している可能性があります。
CPU 使用率が高いことを確認した場合は、次のいずれかを行うことができます。
- VM のサイズを増やして、より多くのコアでスケーリングする。
- 問題をさらに調査する。 アプリとプロセスを見つけ、それに応じてトラブルシューティングを行います。
VM をスケールアップしても、CPU が 95% を超えて実行されている場合、アプリのパフォーマンスは向上していますか、またアプリのスループットは許容レベルまで向上していますか? そうでない場合は、個々のアプリのトラブルシューティングを行います。
メモリのボトルネック
VM で使用されているメモリの量を表示できます。 ログは、傾向や、問題が発生した時間にマップされていかどうかを把握する場合に役立ちます。 100 MB 以上のメモリを常に使用可能にしておく必要があります。 次の傾向に注意してください。
- 消費量がスパイクして持続。 メモリ使用率の高さがパフォーマンスの低下の原因でない場合があります。 リレーショナル データベース エンジンなど、一部のアプリは、メモリ集中型を仕様としています。 しかし、メモリ消費量の多いアプリが複数あると、メモリの競合によってディスクにトリミングやページングが発生するため、パフォーマンスが低下する可能性があります。 これらのプロセスがパフォーマンスに悪影響を及ぼします。
- 消費量が着実に増加。 この傾向としては、アプリの "ウォームアップ" が考えられます。 これは、データベース エンジンの起動時によく見られます。 しかしながら、アプリでメモリ リークが発生している兆候である可能性もあります。
- ページングまたはスワップ ファイルの使用。 Windows ページ ファイルを多用しているか、/dev/sdb にある Linux スワップ ファイルを使用しているかどうかを確認します。
高いメモリ使用率を解決するには、次の解決策を検討してください。
- 直ちにファイルの使用を軽減またはページングするには、VM のサイズを増やしてメモリを追加し、監視します。
- 問題をさらに調査する。 ボトルネックの原因となっているアプリまたはプロセスを特定して、トラブルシューティングを行います。 アプリがわかっている場合は、メモリの割り当てに上限を設定できるかどうかを確認してください。
ディスクのボトルネック
ネットワーク パフォーマンスは、VM の記憶域サブシステムに関連している場合もあります。 ポータルで VM のストレージ アカウントを調査できます。 ストレージに関する問題を特定するには、ストレージ アカウント診断と VM 診断のパフォーマンス メトリックを調べます。 特定の問題の時間範囲内で問題が発生したときの主要な傾向を探します。
- Azure Storage のタイムアウトを確認するには、ClientTimeOutError、ServerTimeOutError、AverageE2ELatency、AverageServerLatency、TotalRequests のメトリックを使用します。 TimeOutError メトリックに値が表示される場合、I/O 操作に時間がかかりすぎてタイムアウトになりました。AverageServerLatency が TimeOutErrors と同時に増加している場合は、プラットフォームの問題である可能性があります。 Microsoft テクニカル サポートに問題を報告してください。
- Azure Storage の調整を確認するには、ストレージ アカウントのメトリック ThrottlingError を使用します。 調整が確認された場合は、アカウントの IOPS 制限に達しています。 この問題は、メトリック TotalRequests を調査することで確認できます。
ディスクの高い使用率と待機時間の問題を修復するには:
- 仮想ハード ディスク (VHD) の制限を超えているものをスケーリングするため、VM I/O を最適化します。
- スループットを向上させ、待機時間を短縮します。 待機時間の影響を受けやすいアプリがあり、高いスループットが必要な場合は、VHD を Azure Premium Storage に移行します。
トラフィックをブロックする仮想マシンのファイアウォール規則
NSG フローの問題のトラブルシューティングを行うには、Network Watcher の IP フロー検証ツールと NSG フロー ログを使用して、トラフィック フローを妨害する NSG またはユーザー定義のルーティング (UDR) が存在するかどうかを確認します。
IP フロー検証を実行し、ローカル VM とリモート VM を指定します。 [確認] をクリックすると、Azure で論理テストが所定の規則で実行されます。 結果としてアクセスが許可されている場合は、NSG フロー ログを使用します。
ポータルで [NSG] に移動します。 フロー ログ設定の下で [オン] を選択します。 これで、VM への接続を再試行してみます。 Network Watcher のトラフィック分析を使用してデータを視覚化します。 結果としてアクセスが許可されている場合は、妨げている NSG ルールはありません。
この時点に到達しても問題を診断できない場合は、リモート VM に何か問題がある可能性があります。 リモート VM でファイアウォールを無効にしてから、接続を再テストします。 ファイアウォールを無効にしてリモート VM に接続できる場合は、リモート ファイアウォールの設定を確認します。 その後、ファイアウォールを再び有効にします。
フロントエンドとバックエンドのサブネットが通信できない
既定では、すべてのサブネットが Azure で通信できます。 2 つのサブネット上の 2 つの VM が通信できない場合は、通信をブロックしている構成が存在するはずです。 フロー ログを確認する前に、フロントエンド VM からバックエンド VM への IP フロー検証ツールを実行します。 このツールにより、ネットワーク上のルールに対して論理テストが実行されます。
結果が、バックエンド サブネット上の NSG がすべての通信をブロックしている場合は、その NSG を再構成します。 フロントエンドはパブリック インターネットに公開されるため、セキュリティ上の理由から、フロントエンドとの一部の通信をブロックする必要があります。
バックエンドへの通信をブロックすることによって、マルウェアやセキュリティ攻撃が発生した場合の露出の量を制限します。 ただし、NSG ですべてがブロックされる場合は、正しく構成されていません。 必要な特定のプロトコルとポートを有効にします。