はじめに
クラスタリングは、オブジェクトの類似性に基づいてオブジェクトをグループ化するプロセスです。 たとえば、次の図には、左上 (黄色)、下部 (赤)、右上 (青) の 3 つのカテゴリにクラスター化された 2D 座標のコレクションがあります。
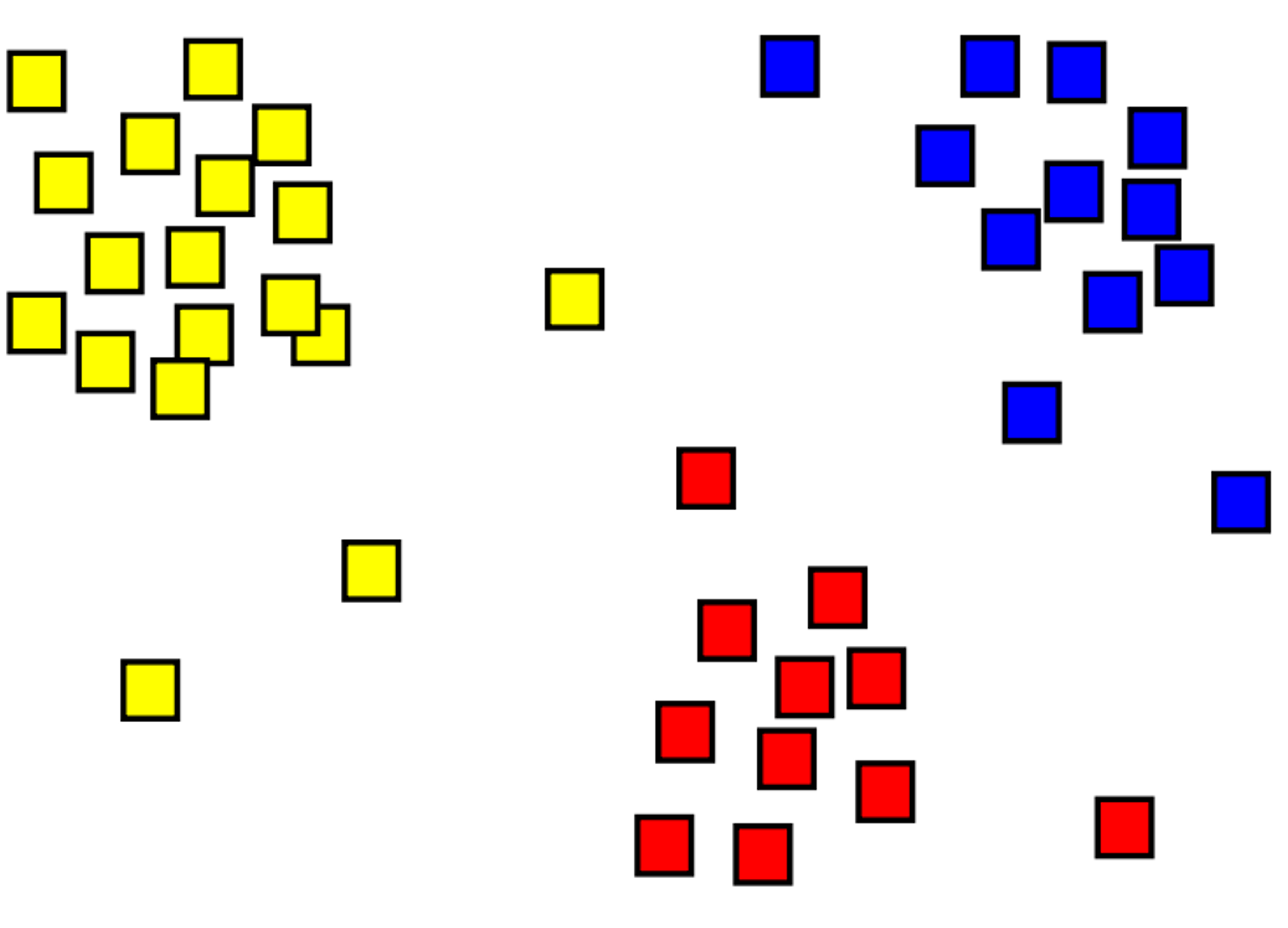
クラスタリングと分類のモデルの主な違いは、クラスタリングが "教師なし" の方法であり、"トレーニング" がラベルなしで行われる点です。 クラスタリング モデルでは、類似する特徴のコレクションを持つ例が識別されます。 上記の図では、似た場所にある例がグループ化されています。
クラスタリングは一般的であり、大まかなカテゴリなど、データ ポイント間のパターンがまだ知られていない新しいデータの探索に便利です。 これは、ソーシャル ネットワークの分析、脳の接続性、スパムのフィルター処理など、複雑なデータにラベルを自動的に付ける必要がある多くの分野で使用されます。