Azure AI Search プッシュ API を使ってデータにインデックスを付ける
Azure AI Search インデックスにデータをプッシュするには、REST API が最も柔軟な方法です。 任意のプログラミング言語を使用することも、JSON 要求をエンドポイントに投稿できる任意のアプリで対話形式で使用することもできます。
ここでは、REST API を効果的に使用する方法と、使用可能な操作について確認します。 次に、.NET Core コードと、API を使用して大量のデータの追加を最適化する方法を確認します。
サポートされている REST API の操作
AI Search でサポートされている REST API は 2 つあります。 検索と管理の API です。 このモジュールでは、検索の次の 5 つの機能に対する操作を提供する検索 REST API に重点を置いています。
| 特徴量 | Operations |
|---|---|
| インデックス | 作成、削除、更新、構成。 |
| ドキュメント | 取得、追加、更新、削除。 |
| Indexer | 限られたデータ ソースに対してデータ ソースとスケジュールを構成します。 |
| スキルセット | 取得、作成、削除、一覧表示、更新。 |
| シノニム マップ | 取得、作成、削除、一覧表示、更新。 |
検索 REST API を呼び出す方法
検索 API のいずれかを呼び出す場合は、次の手順を実行する必要があります。
- 検索サービスによって提供される HTTPS エンドポイント (既定のポート 443 経由) を使用します。api-version を URI に含める必要があります。
- 要求ヘッダーには api-key 属性を含める必要があります。
エンドポイント、api-version、api-key を見つけるには、Azure portal に移動します。

ポータルで検索サービスに移動し、[Search エクスプローラー] を選択します。 REST API エンドポイントは、[要求 URL] フィールドにあります。 URL の最初の部分がエンドポイント (https://azsearchtest.search.windows.net など) であり、クエリ文字列に api-version (api-version=2023-07-01-Preview など) が表示されます。

左側で api-key を見つけるには、[キー] を選択します。 REST API を使用してインデックスにクエリを実行する以外の操作を行う場合は、プライマリまたはセカンダリの管理者キーを使用できます。 インデックスの検索だけが必要な場合は、クエリ キーを作成して使用できます。
インデックス内でデータを追加、更新、または削除するには、管理者キーを使用する必要があります。
インデックスにデータを追加する
次の形式のインデックス機能を使用して HTTP POST 要求を使用します。
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
要求の本文では、ドキュメントに対して実行するアクション、アクションを適用するドキュメント、および使用するデータを REST エンドポイントに通知する必要があります。
JSON は次の形式にする必要があります。
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| アクション | 説明 |
|---|---|
| upload | SQL の upsert と同様に、ドキュメントが作成または置換されます。 |
| merge | マージによって、指定したフィールドで既存のドキュメントが更新されます。 ドキュメントが見つからない場合、マージは失敗します。 |
| mergeOrUpload | マージによって、指定したフィールドで既存のドキュメントが更新され、ドキュメントが存在しない場合はアップロードされます。 |
| delete | ドキュメント全体が削除されます。key_field_name を指定するだけです。 |
要求が成功した場合、API は 200 状態コードを返します。
Note
すべての応答コードとエラー メッセージの完全な一覧については、「ドキュメントの追加、更新、または削除 (Azure AI Search REST API)」を参照してください
次の例の JSON では、前のユニットの顧客レコードがアップロードされています。
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
値配列には、必要な数のドキュメントを追加できます。 ただし、最適なパフォーマンスを得るために、要求内のドキュメントを最大 1,000 ドキュメント、または合計サイズで 16 MB までバッチ処理することを検討してください。
.NET Core を使用してデータにインデックスを付ける
パフォーマンスを最大限に高めるには、最新の Azure.Search.Document クライアント ライブラリ (現在バージョン 11) を使用してください。 クライアント ライブラリは、次の NuGet でインストールできます。
dotnet add package Azure.Search.Documents --version 11.4.0
インデックスのパフォーマンスは、次の 6 つの重要な要因に基づいています。
- 検索サービス レベルと、有効にしたレプリカとパーティションの数。
- インデックス スキーマの複雑さ。 各フィールドに含まれるプロパティ (検索可能、ファセット可能、並べ替え可能) の数を減らしてください。
- 各バッチ内のドキュメントの数。最適なサイズは、インデックス スキーマとドキュメントのサイズによって異なります。
- アプローチがどのようにマルチスレッド化されているか。
- エラー処理と調整。 エクスポネンシャル バックオフの再試行戦略を使用してください。
- データがどこに存在するか。検索インデックスに近いデータにインデックスを付けてみてください。 たとえば、Azure 環境内からアップロードを実行します。
最適なバッチ サイズを確認する
最適なバッチ サイズの確認は、パフォーマンスを向上させるための重要な要素であるため、アプローチをコードで見てみましょう。
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
このアプローチでは、バッチ サイズを増やし、有効な応答を受信するまでの時間を監視しています。 コードは 100 から 1000 まで、100 のドキュメント ステップでループします。 バッチ サイズごとに、ドキュメント サイズ、応答を取得するまでの時間、MB あたりの平均時間が出力されます。 このコードを実行すると、次のような結果が得られます。
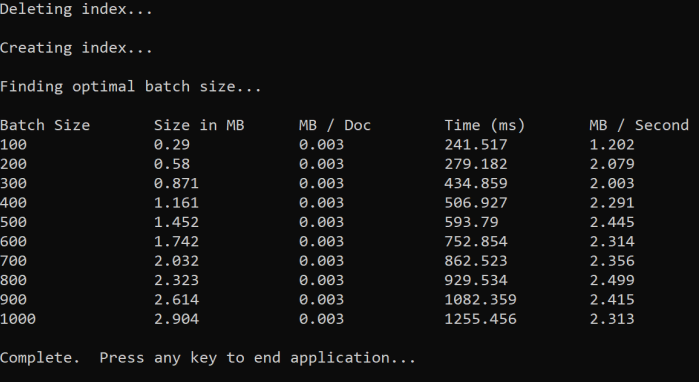
上記の例では、スループットに最適なバッチ サイズは 1 秒あたり 2.499 MB、バッチあたり 800 ドキュメントです。
エクスポネンシャル バックオフの再試行戦略を実装する
オーバーロードが原因でインデックスが要求の調整を開始すると、503 (負荷が高いため要求が拒否されました) または 207 (一部のドキュメントがバッチで失敗しました) の状態で応答します。 これらの応答を処理する必要があり、適切な戦略はバックオフです。 バックオフとは、要求を再試行する前にしばらく一時停止することを意味します。 エラーごとにこの時間を増やすと、指数関数的にバックオフされます。
次のコードを見てみましょう。
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
このコードは、失敗したドキュメントをバッチで追跡します。 エラーが発生した場合は、延期時間を待機してから、次のエラーの延期時間を 2 倍にします。
最終的に、最大数の再試行が行われ、この最大数に達した場合はプログラムが存在します。
スレッド化を使用してパフォーマンスを向上させる
上記のバックオフ戦略とスレッド化アプローチを組み合わせて、ドキュメント アップロードアプリを完成させることができます。 次にコード例をいくつか示します。
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
このコードでは、バックオフ戦略を実装する関数 ExponentialBackoffAsync の非同期呼び出しを使用します。 スレッドを使用して、プロセッサのコア数などの関数を呼び出します。 スレッドの最大数が使用されている場合、コードはスレッドが完了するまで待機します。 その後、すべてのドキュメントがアップロードされるまで新しいスレッドが作成されます。