Azure Data Factory を使用して外部データ ソースのデータのインデックスを作成する
Azure に存在しない外部データを追加することは、組織の検索ソリューションで一般的なニーズです。 Azure AI 検索では、さまざまな方法でデータを作成してインデックスにプッシュできるため、Azure AI 検索には柔軟性があります。
Azure Data Factory (ADF) を使用して検索インデックスにデータをプッシュする
最初の方法は、ADF を使用してインデックスにデータをプッシュするためのゼロコード オプションです。 ADF には、約 100 の異なるデータ ストアへの接続が用意されています。 HTTP や REST などのコネクタを使用すると、無制限にデータ ストアを接続できます。 これらのデータ ストアは、パイプラインのソースまたはターゲット (コピー アクティビティではシンクと呼ばれます) として使用されます。
Azure AI 検索インデックス コネクタは、コピー アクティビティにおけるシンクとして使用できます。
ADF パイプラインを作成して、検索インデックスにデータをプッシュする
検索インデックスにデータをプッシュするために使用する必要がある手順と ADF パイプラインを次に示します。
- データを保存したいすべてのフィールドを含む Azure AI 検索インデックスを作成します。
- データのコピー ステップを使用してパイプラインを作成します。
- データが存在する場所へのデータ ソース接続を作成します。
- 検索インデックスに接続するためのシンクを作成します。
- ソース データのフィールドを検索インデックスにマップします。
- パイプラインを実行して、データをインデックスにプッシュします。
たとえば、外部でホストされている JSON 形式の顧客データがあるとします。 これらの顧客を検索インデックスにコピーする必要があります。 JSON は次の形式です。
{
"_id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": 1558
},
"phoneNumbers": [
{
"type": "home",
"number": "+1 (830) 465-2965"
},
{
"type": "home",
"number": "+1 (889) 439-3632"
}
]
}
検索インデックスを作成する
Azure AI 検索サービスと、この情報を保存するインデックスを作成します。 「Azure AI 検索ソリューションの作成」モジュールを完了している場合は、これを行う方法は確認済みということになります。 手順に従って検索サービスを作成しますが、データのインポート時点で停止してください。 インデックスにデータをプッシュする場合、インデクサーまたはスキルセットを作成する必要はありません。
インデックスを作成し、次のフィールドとプロパティを追加します。

ADF ではインデックスを作成できないため、現時点では、最初にインデックスを作成する必要があります。
ADF データコピー ツールを使用してパイプラインを作成する
Azure Data Factory Studio を開き、ご自分の Azure サブスクリプションとデータ ファクトリ名を選択します。

[取り込む] を選択します。
[次へ] を選択します。
注意
ご自分のデータが変更され、インデックスを最新の状態に保つ必要がある場合は、パイプラインのスケジュールを設定できます。 この例では、データを 1 回インポートします。
ソース リンク サービスの作成
[ソースの種類] で、[HTTP] を選択します。
[接続] の横にある [新しい接続] を選択します。
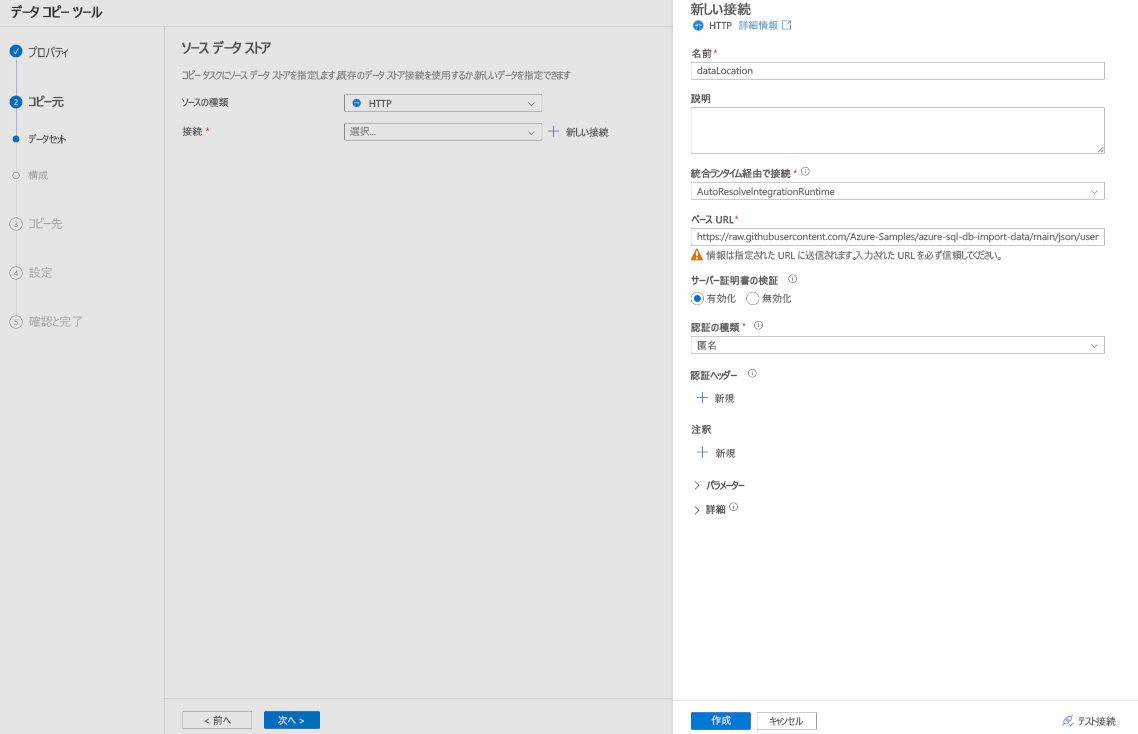
[新しい接続] ペインの [名前] に「dataLocation」と入力します。
[ベース URL] に JSON ファイルが存在する場所を入力します。この例では、「https://raw.githubusercontent.com/Azure-Samples/azure-sql-db-import-data/main/json/user1.json」と入力します。
[認証の種類] で、[匿名] を選択します。
[作成] を選択します。
[次へ] を選択します。
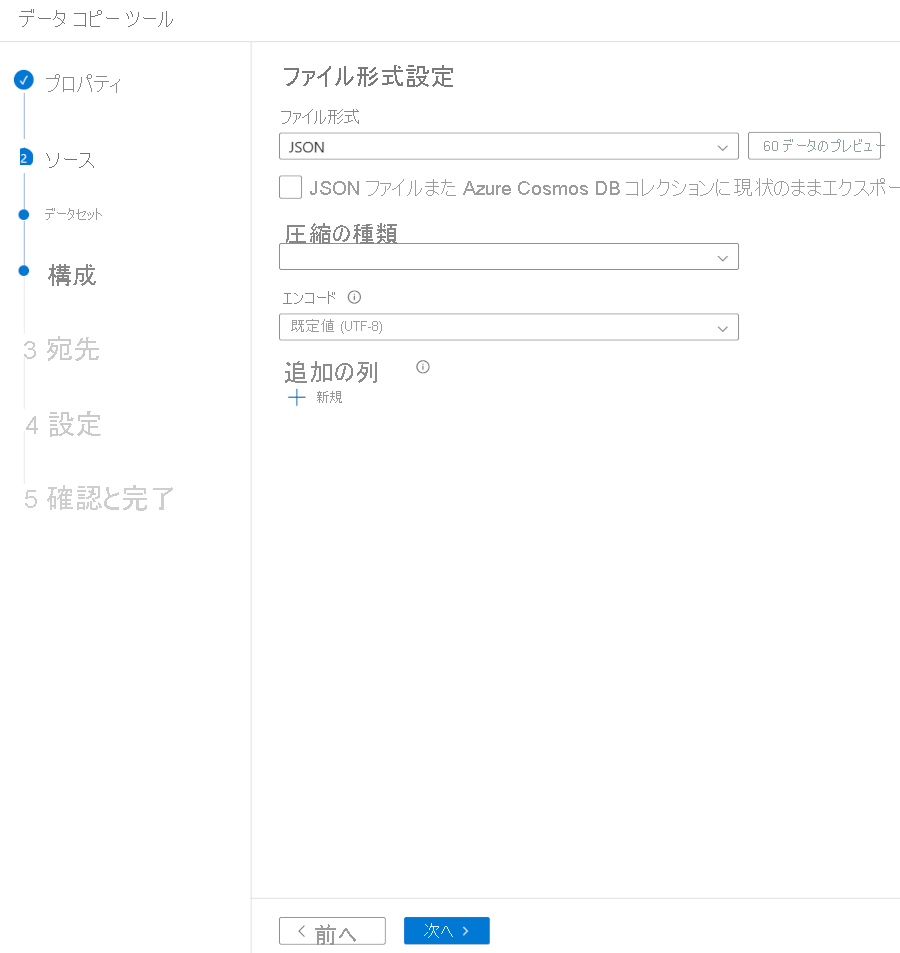
[ファイル形式] で、[JSON] を選択します。
[次へ] を選択します。


ターゲット リンク サービスの作成
[宛先の種類] で、[Azure Search] を選択します。 次に、[+新しい接続] を選択します。
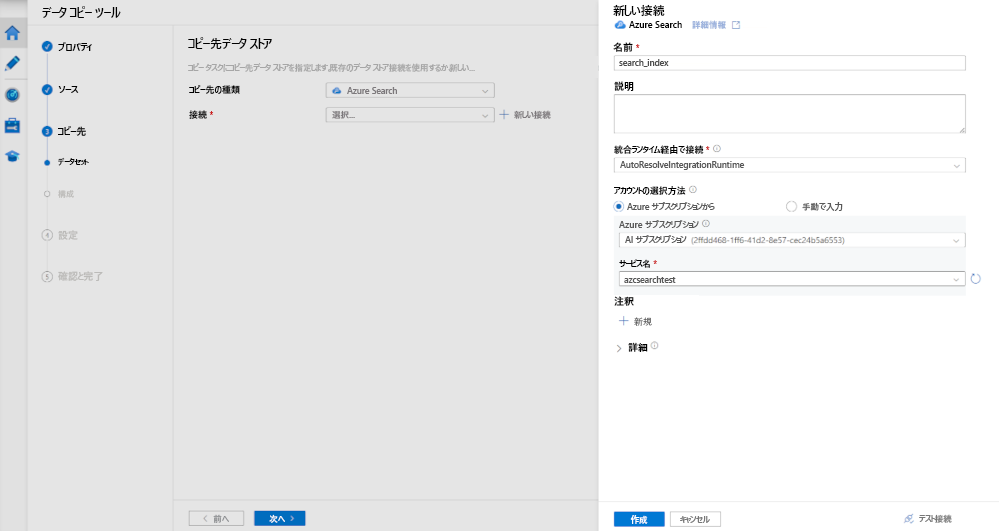
[新しい接続] ペインの [名前] に「search_index」と入力します。
[Azure サブスクリプション] で、ご使用の Azure サブスクリプションを選択します。
[サービス名] で、Azure AI 検索サービスを選択します。
[作成] を選択します
[宛先データ ストア] ペインの [ターゲット] で、作成した検索インデックスを選択します。

ソース フィールドをターゲット フィールドにマップする
[次へ] を選択します。
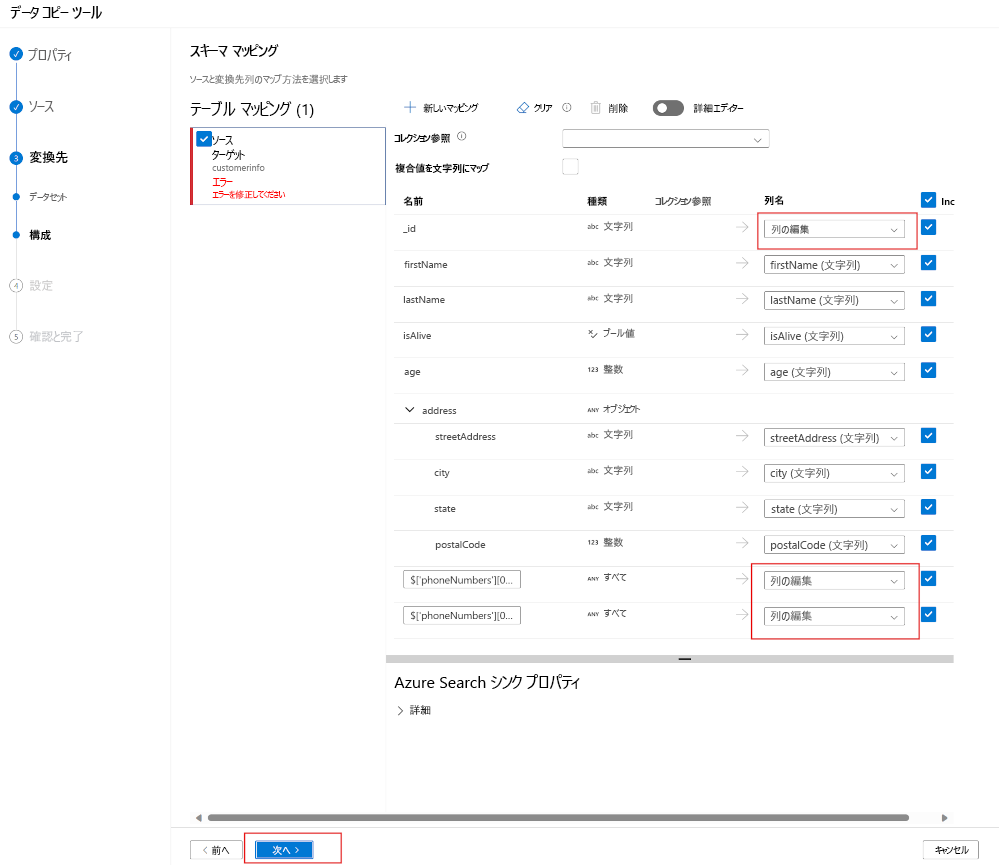
JSON 属性と一致するフィールド名を持つインデックスを作成した場合、ADF により JSON が検索インデックスのフィールドに自動的にマップされます。
上記の例では、JSON ドキュメントの 3 つのフィールドがインデックス内のフィールドにマッピングされている必要があります。
フィールドをマップし、[次へ] を選択します。
[設定] ウィンドウの [タスク名] に「jsonToSearchIndex」と入力します。
[次へ] を選択します。

パイプラインを実行して、データをインデックスにプッシュする
[概要] ペインで、[次へ] を選択します。
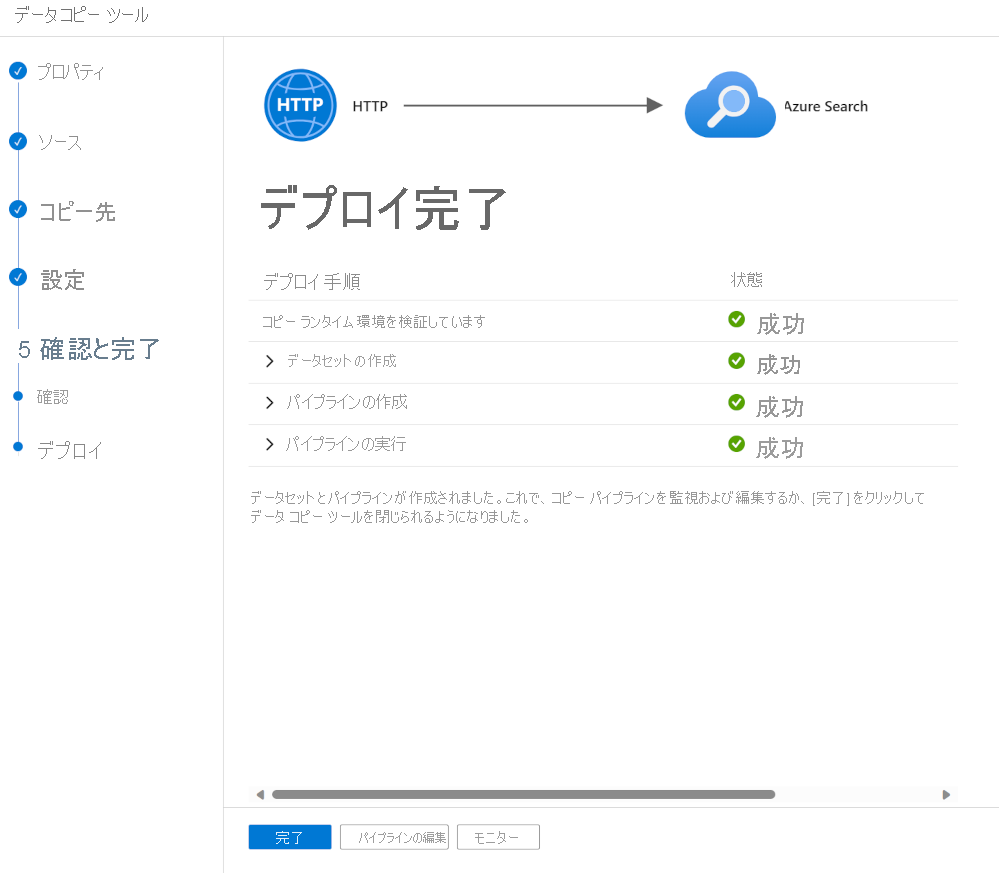
パイプラインが検証されてデプロイされたら、[完了] を選択します。

パイプラインがデプロイされ、実行されました。 JSON ドキュメントが検索インデックスに追加されます。 Azure portal を使用し、検索エクスプローラーで検索を実行できます。 インポートされた JSON データが表示されているはずです。

これらの手順に従って、インデックスにデータをプッシュする方法を確認しました。 既定で作成したパイプラインは、更新をインデックスにマージします。 JSON データを修正してパイプラインを再実行すると、検索インデックスが更新されます。 書き込み動作を変更してアップロードできるのは、パイプラインを実行するたびにデータを置き換える場合のみです。
組み込みの Azure AI 検索をリンク サービスとして使用する場合の制限事項
現在、シンクとしての Azure AI 検索リンク サービスでサポートされているのは、以下のフィールドだけです。
| Azure AI Search のデータ型 |
|---|
| String |
| Int32 |
| Int64 |
| Double |
| Boolean |
| DataTimeOffset |
つまり、ComplexTypes と配列は現在サポートされていません。 上記の JSON ドキュメントを見ると、顧客のすべての電話番号をマップすることはできないことがわかります。 最初の電話番号のみがマップされています。