演習: 移行されたデータベースの保護、監視、チューニング
あなたは、AdventureWorks という組織のデータベース開発者として働いています。 AdventureWorks では、10 年以上にわたってエンドユーザーと販売代理店に自転車や自転車の部品を直接販売しています。 会社のシステムでは、以前に Azure Database for PostgreSQL に移行したデータベースに情報を格納しています。
移行を実行した後に、システムが正常に動作していることを保証する必要があります。 サーバーの監視に使用できる Azure ツールを使用することにします。 競合と待機時間が原因で応答時間が遅くなる可能性を軽減するために、読み取りレプリケーションを実装することにしました。 構築したシステムを監視し、それをフレキシブル サーバー アーキテクチャと比較する必要があります。
この演習では、以下のタスクを実行します。
- Azure Database for PostgreSQL サービスの Azure メトリックを構成します。
- 複数のユーザーがデータベースに対してクエリを実行することをシミュレートするサンプル アプリケーションを実行します。
- メトリックを表示します。
環境を設定する
Cloud Shell でこれらの Azure CLI コマンドを実行し、AdventureWorks データベースのコピーを使用して Azure database for PostgreSQL を作成します。 最後のコマンドでは、サーバー名が出力されます。
SERVERNAME="adventureworks$((10000 + RANDOM % 99999))"
PUBLICIP=$(wget http://ipecho.net/plain -O - -q)
git clone https://github.com/MicrosoftLearning/DP-070-Migrate-Open-Source-Workloads-to-Azure.git workshop
az postgres server create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--name $SERVERNAME \
--location westus \
--admin-user awadmin \
--admin-password Pa55w.rdDemo \
--version 10 \
--storage-size 5120
az postgres db create \
--name azureadventureworks \
--server-name $SERVERNAME \
--resource-group <rgn>[sandbox resource group name]</rgn>
az postgres server firewall-rule create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--server $SERVERNAME \
--name AllowMyIP \
--start-ip-address $PUBLICIP --end-ip-address $PUBLICIP
PGPASSWORD=Pa55w.rdDemo psql -h $SERVERNAME.postgres.database.azure.com -U awadmin@$SERVERNAME -d postgres -f workshop/migration_samples/setup/postgresql/adventureworks/create_user.sql
PGPASSWORD=Pa55w.rd psql -h $SERVERNAME.postgres.database.azure.com -U azureuser@$SERVERNAME -d azureadventureworks -f workshop/migration_samples/setup/postgresql/adventureworks/adventureworks.sql 2> /dev/null
echo "Your PostgreSQL server name is:\n"
echo $SERVERNAME.postgres.database.azure.com
Azure Database for PostgreSQL サービスの Azure メトリックを構成する
Web ブラウザーを使用して新しいタブを開き、Azure portal に移動します。
Azure portal で、[すべてのリソース] を選択します。
Adventureworks で始まる Azure Database for PostgreSQL のサーバー名を選択します。
[監視] で [メトリック] を選びます。
[グラフ] ページで、次のメトリックを追加します。
プロパティ 値 スコープ adventureworks[nnn] メトリック名前空間 PostgreSQL サーバーの標準メトリック メトリック アクティブな接続 集約 Avg このメトリックでは、サーバーに対して行われた接続の 1 分ごとの平均数が表示されます。
[メトリックの追加] を選択し、次のメトリックを追加します。
プロパティ 値 スコープ adventureworks[nnn] メトリック名前空間 PostgreSQL サーバーの標準メトリック メトリック CPU 使用率 集約 Avg [メトリックの追加] を選択し、次のメトリックを追加します。
プロパティ 値 スコープ adventureworks[nnn] メトリック名前空間 PostgreSQL サーバーの標準メトリック メトリック メモリの割合 集約 Avg [メトリックの追加] を選択し、次のメトリックを追加します。
プロパティ 値 スコープ adventureworks[nnn] メトリック名前空間 PostgreSQL サーバーの標準メトリック メトリック IO の割合 集約 Avg これらの最後の 3 つのメトリックでは、テスト アプリケーションによってリソースがどのように使用されているかが示されます。
グラフの時間の範囲を [過去 30 分間] に設定します。
[ダッシュボードにピン留めする] を選択してから、[ピン留めする] を選択します。
複数のユーザーがデータベースに対してクエリを実行することをシミュレートするサンプル アプリケーションを実行する
Azure portal の Azure Database for PostgreSQL サーバーのページで、[設定] の下の [接続文字列] を選択します。 ADO.NET 接続文字列をクリップボードにコピーします。
~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTest フォルダーに移動します。
cd ~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTestコード エディターを使用して App.config ファイルを開きます。
code App.configDatabase の値を azureadventureworks に置き換え、ConectionString0 をクリップボードの接続文字列に置き換えます。 User Id を azureuser@adventureworks[nnn] に変更し、Password を Pa55w.rd に設定します。 完成したファイルは、下の例のようになります。
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="INSERT CONNECTION STRING HERE" /> <add key="ConnectionString2" value="INSERT CONNECTION STRING HERE" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="1"/> </appSettings> </configuration>注意
ここでは、ConnectionString1 と ConnectionString2 の設定を無視します。 これらの項目は、後でラボで更新します。
変更を保存してエディターを閉じます。
Cloud Shell プロンプトで、次のコマンドを実行してアプリをビルドして実行します。
dotnet runアプリが起動すると、ユーザーをそれぞれシミュレートするスレッドが多数生成されます。 スレッドでは、一連のクエリを実行するループが実行されます。 下に示すようなメッセージが表示され始めます。
Client 48 : SELECT * FROM purchasing.vendor Response time: 630 ms Client 48 : SELECT * FROM sales.specialoffer Response time: 702 ms Client 43 : SELECT * FROM purchasing.vendor Response time: 190 ms Client 57 : SELECT * FROM sales.salesorderdetail Client 68 : SELECT * FROM production.vproductanddescription Response time: 51960 ms Client 55 : SELECT * FROM production.vproductanddescription Response time: 160212 ms Client 59 : SELECT * FROM person.person Response time: 186026 ms Response time: 2191 ms Client 37 : SELECT * FROM person.person Response time: 168710 ms次の手順を実行している間、このアプリを実行したままにしておきます。
メトリックを表示する
Azure portal に戻ります。
左側のペインで、[ダッシュボード] を選択します。
Azure Database for PostgreSQL サービスのメトリックを示すグラフが表示されます。
グラフを選択して、[メトリック] ペインに開きます。
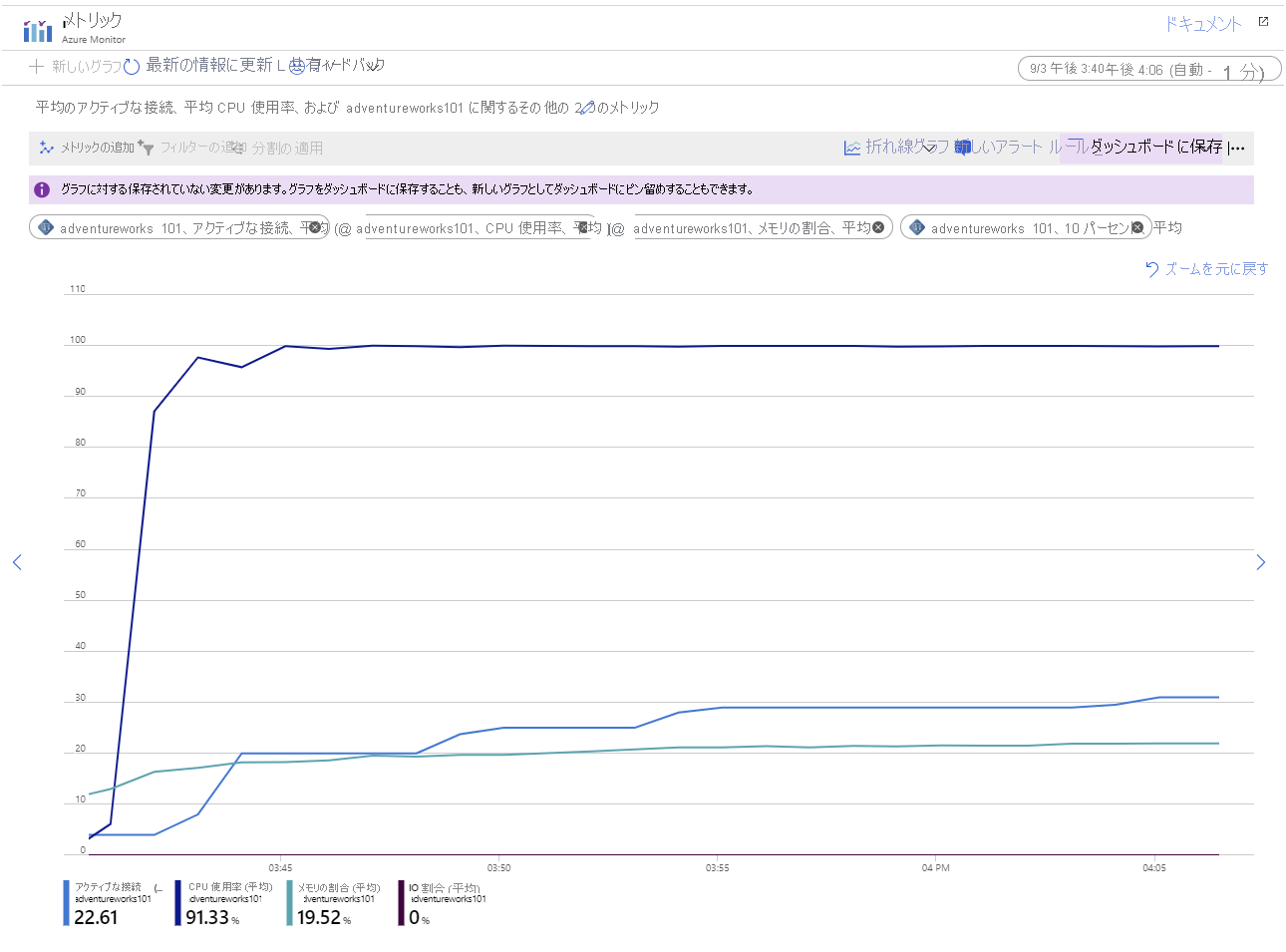
アプリを数分間実行します (なるべく長く実行してください)。 時間が経過すると、グラフ内のメトリックは次の図に示すパターンのようになります。
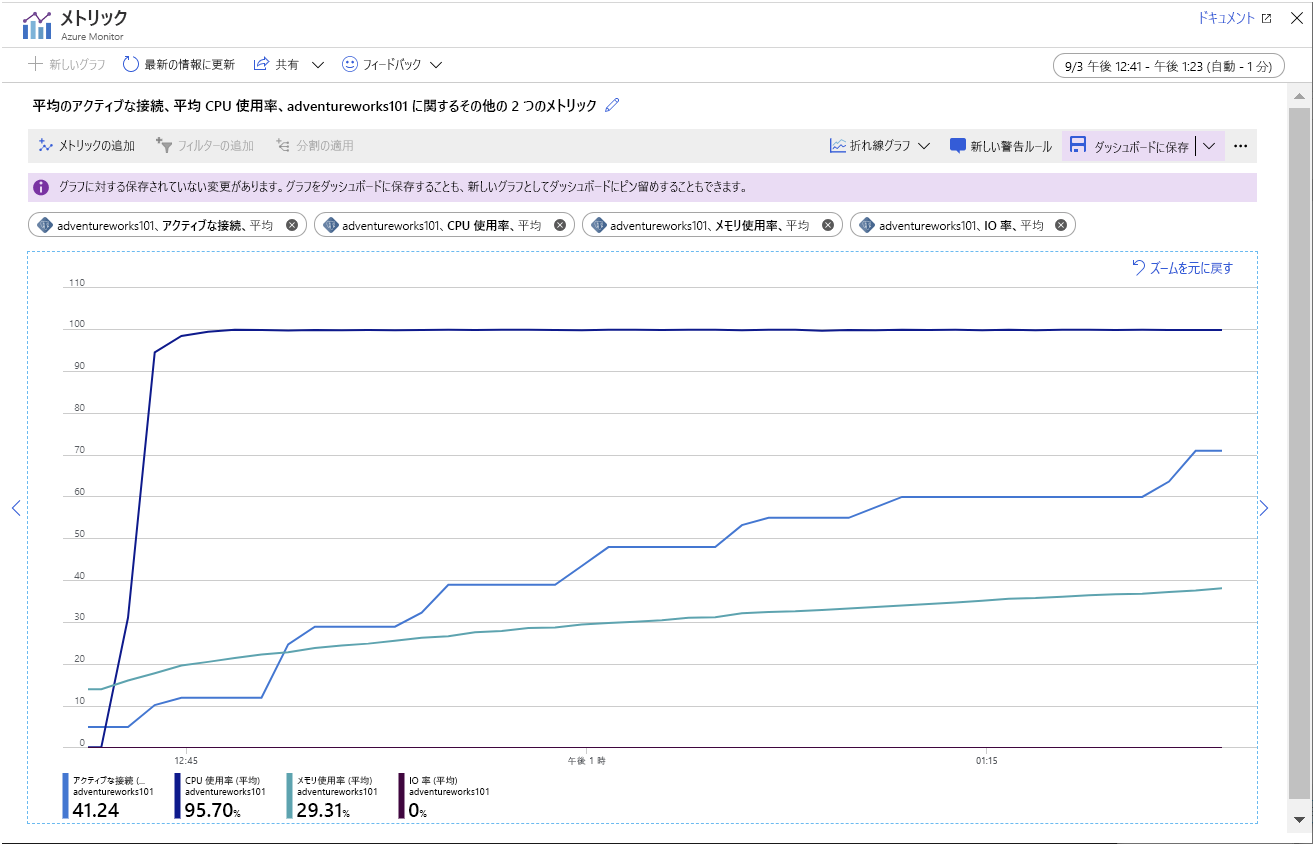
このグラフでは、次のようなことがわかります。
- CPU は、処理能力をすべて使用して実行されています。使用率は非常に速く 100% に達しています。
- 接続数は徐々に増加しています。 このサンプル アプリケーションは、101 個のクライアントを短時間で連続して起動するように設計されていますが、サーバーで開くことができるのは一度にいくつかの接続のみです。 グラフの各 "ステップ" に追加される接続の数が少なくなり、"ステップ" 間の時間が増加しています。 約 45 分後に、システムでは 70 個のクライアント接続を確立することしかできませんでした。
- メモリ使用率は、時間の経過と共に増加し続けています。
- IO 使用率はほぼゼロです。 クライアント アプリケーションで必要なすべてのデータは、現在メモリにキャッシュされています。
アプリケーションを十分に長く実行しておくと、次の図に示したエラー メッセージが表示され、接続が失敗し始めます。
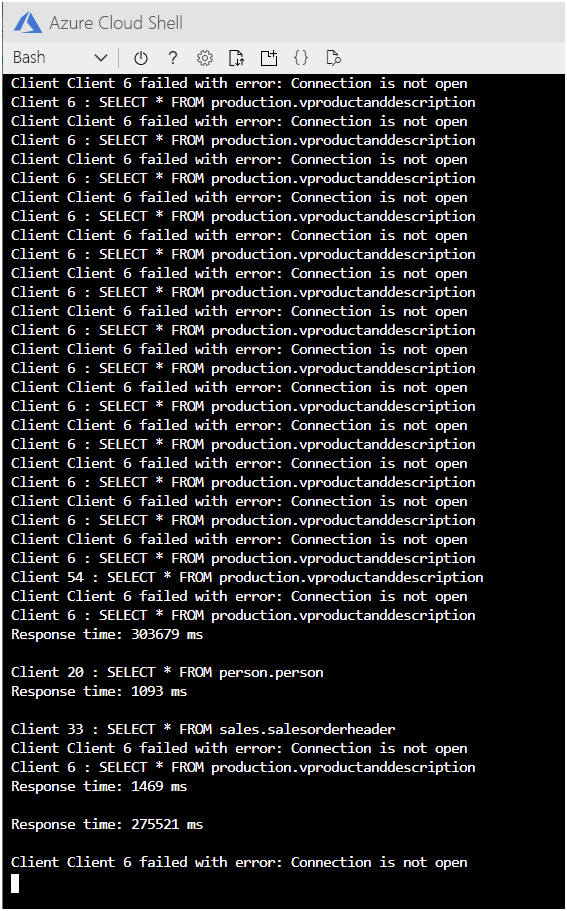
Cloud Shell で、Enter キーを押してアプリケーションを停止します。
クエリ パフォーマンスのデータを収集するようにサーバーを構成する
Azure portal の Azure Database for PostgreSQL サーバーのページで、[設定] の下の [サーバー パラメーター] を選択します。
[サーバー パラメーター] ページで、次のパラメーターを下の表で指定されている値に設定します。
パラメーター [値] pg_qs.max_query_text_length 6000 pg_qs.query_capture_mode ALL pg_qs.replace_parameter_placeholders ON pg_qs.retention_period_in_days 7 pg_qs.track_utility ON pg_stat_statements.track ALL pgms_wait_sampling.history_period 100 pgms_wait_sampling.query_capture_mode ALL [保存] を選択します。
クエリ ストアを使用してアプリケーションによって実行されるクエリを検査する
Cloud Shell に戻り、サンプル アプリを再起動します。
dotnet runアプリを 5 分間実行してから続行します。
アプリを実行したままにして、Azure portal に切り替えます
Azure Database for PostgreSQL サーバーのページの [インテリジェント パフォーマンス] で、[Query Performance Insight] を選択します。
[Query Performance Insight] ページの [実行時間の長いクエリ] タブで、[クエリの数] を 10 に、[選択基準] を [avg] に、[期間] を [過去 6 時間] に設定します。
グラフの上にある拡大 ("+" 記号が付いた虫眼鏡アイコン) を数回選択して、最新のデータを表示します。
アプリケーションを実行した期間に応じて、下のようなグラフが表示されます。 クエリ ストアでは、クエリの統計が 15 分ごとに集計されるため、各棒グラフには、各クエリによって消費された相対的な時間が 15 分ごとに表示されます。
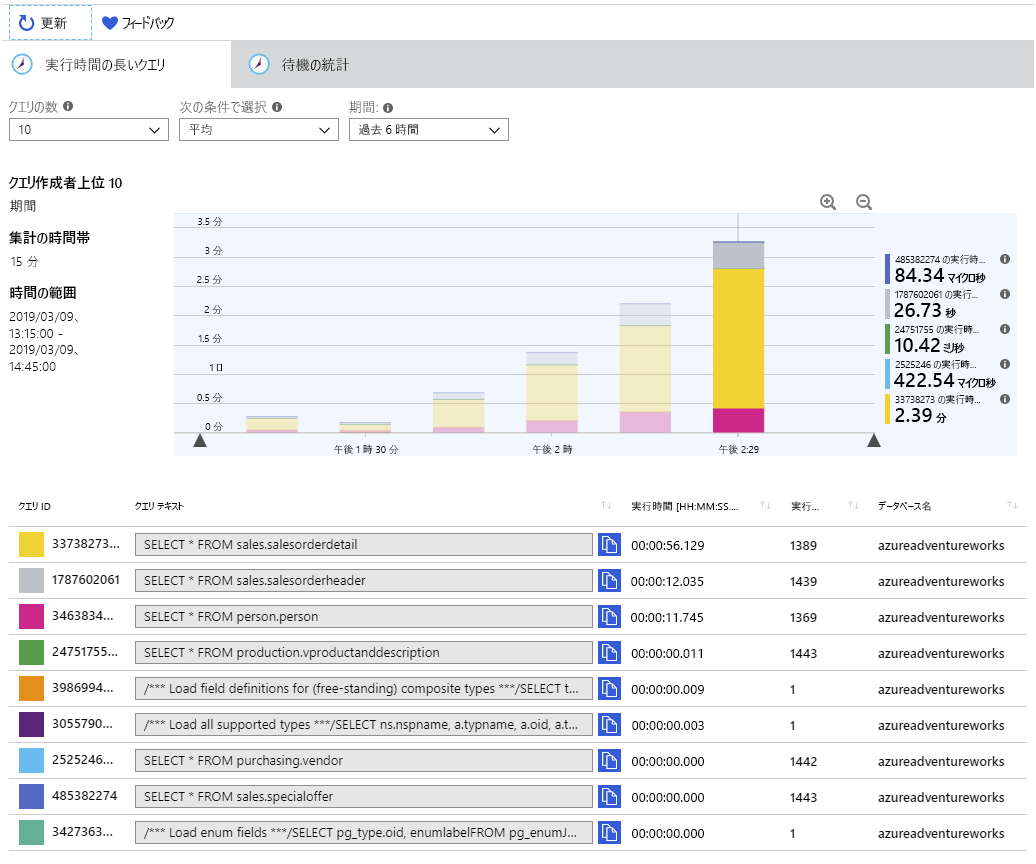
各棒グラフの上にマウス ポインターを合わせると、その期間のクエリの統計情報が表示されます。 システムで実行時間の大半が費やされている 3 つのクエリは、次のとおりです。
SELECT * FROM sales.salesorderdetail SELECT * FROM sales.salesorderheader SELECT * FROM person.personこの情報は、システムを監視する管理者にとって役立ちます。 ユーザーとアプリによって実行されるクエリの分析情報を確認すると、実行されているワークロードを理解でき、アプリケーション開発者がコードを改善する方法についての推奨事項を作成できることもあります。 たとえば、sales.salesorderdetail テーブルから 121,000 以上の行をすべて取得する処理はアプリケーションに本当に必要でしょうか。
クエリ ストアを使用して発生した待機を検査する
[待機の統計] タブを選択します。
[期間] を [過去 6 時間] に、[グループ化] を [イベント] に、[グループの最大数] を 5 に設定します。
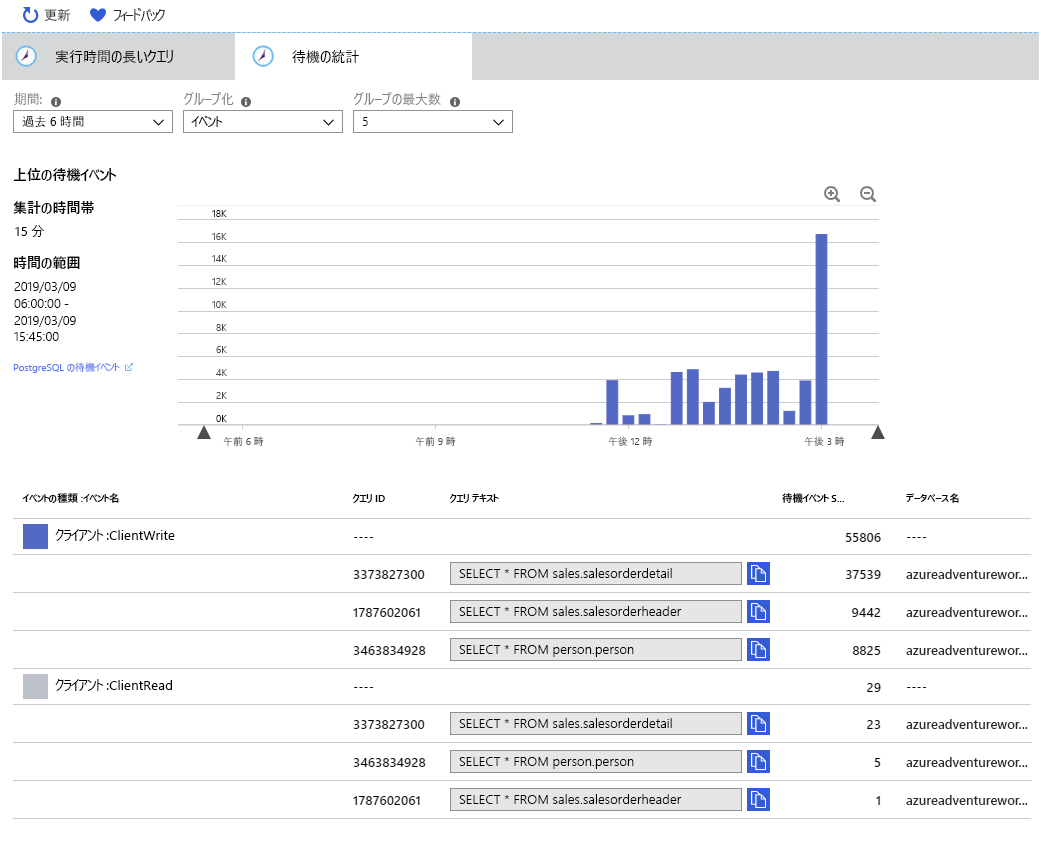
[実行時間の長いクエリ] タブと同様に、データは 15 分ごとに集計されます。 グラフの下の表には、システムで次の 2 種類の待機イベントが発生していることが示されています。
- クライアント: ClientWrite。 この待機イベントは、サーバーでデータ (結果) をクライアントに書き戻しているときに発生します。 データベースへの書き込み中に発生した待機を示すものではありません。
- クライアント: ClientRead。 この待機イベントは、サーバーでクライアントからのデータ (クエリ要求またはその他のコマンド) の読み取りを待機しているときに発生します。 データベースからの読み取りに費やされた時間には関連していません。
Note
データベースに対する読み取りと書き込みは、クライアント イベントではなく IO イベントによって示されます。 このサンプル アプリケーションでは、最初の読み取り後に、必要なすべてのデータがメモリにキャッシュされるため、IO 待機は発生しません。 メモリが不足していることがメトリックに示されている場合は、IO 待機イベントが発生し始める可能性があります。
Cloud Shell に戻り、Enter キーを押してサンプル アプリケーションを停止します。
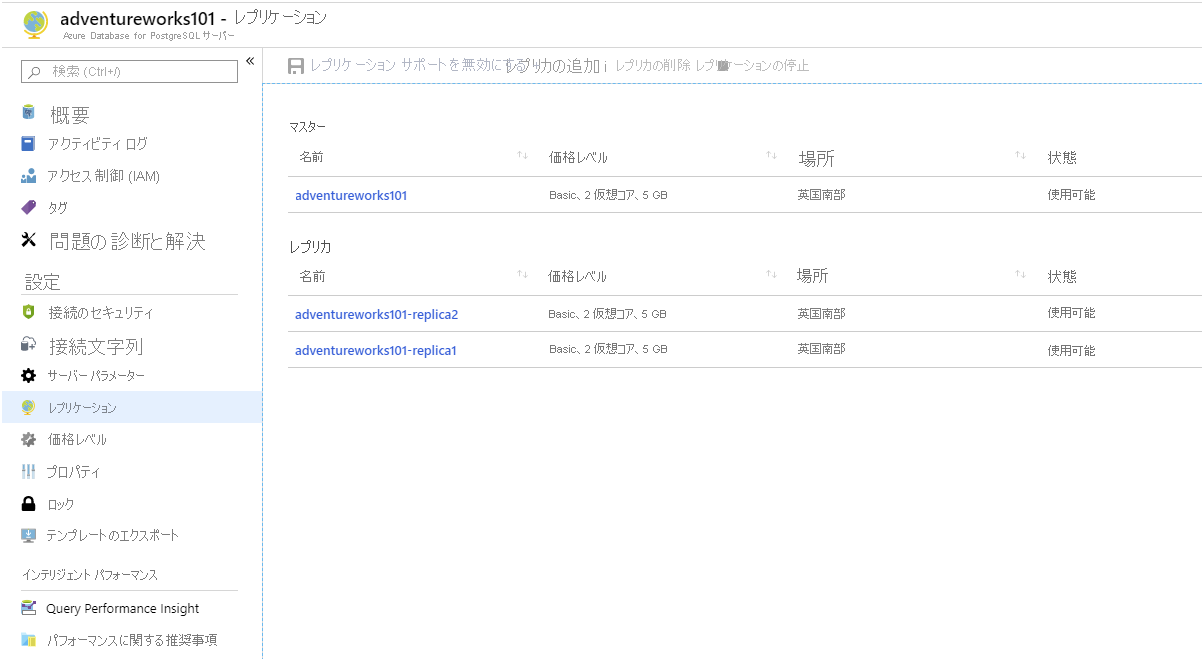
Azure Database for PostgreSQL サービスにレプリカを追加する
Azure portal の Azure Database for PostgreSQL サーバーのページで、[設定] の下の [レプリケーション] を選択します。
[レプリケーション] ページで、[レプリカの追加] を選択します。
PostgreSQL サーバーのページの [サーバー名] ボックスに「adventureworks[nnn]-replica1」と入力し、[OK] を選択します。
最初のレプリカが作成されたら (数分かかります)、前の手順を繰り返して、adventureworks[nnn]-replica2 という名前の別のレプリカを追加します。
両方のレプリカの状態が [デプロイ中] から [使用可能] に変わるまで待機してから続行します。
クライアントがアクセスできるようにレプリカを構成する
- [Adventureworks[nnn]-replica1] レプリカの名前を選択します。 このレプリカの Azure Database for PostgreSQL ページが表示されます。
- [設定] で [接続のセキュリティ] を選択します。
- [接続のセキュリティ] ページで、[Azure サービスへのアクセスを許可] を [オン] に設定し、[保存] を選択します。 この設定により、Cloud Shell を使用して実行するアプリケーションでサーバーにアクセスできるようになります。
- 設定が保存されたら、前の手順を繰り返して、Azure サービスで adventureworks[nnn]-replica2 レプリカにアクセスできるようにします。
各サーバーを再起動する
注意
レプリケーションの構成では、サーバーを再起動する必要はありません。 このタスクの目的は、アプリケーションの再実行時に収集されるメトリックが "クリーン" になるように、各サーバーからメモリおよび関係のない接続をクリアすることです。
- Adventureworks[nnn] サーバーのページに移動します。
- [概要] ページで、[再起動] を選択します。
- [サーバーの再起動] ダイアログ ボックスで、[はい] を選択します。
- サーバーが再起動されるまで待ってから続行します。
- 同じ手順に従って、adventureworks[nnn]-replica1 と adventureworks[nnn]-replica2 サーバーを再起動します。
レプリカを使用するようにサンプル アプリケーションを再構成する
Cloud Shell で、App.config ファイルを編集します。
code App.configConnectionString1 と ConnectionString2 の設定に接続文字列を追加します。 これらの値は ConnectionString0 の値と同じである必要がありますが、Server と User Id 要素でテキスト adventureworks[nnn] が adventureworks[nnn]-replica1 と adventureworks[nnn]-replica2 に置き換えられています。
Numreplicas の設定を 3 に設定します。
App.config ファイルは次のようになります。
<configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="Server=adventureworks101-replica1.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica1;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString2" value="Server=adventureworks101-replica2.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica2;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="3"/> </appSettings> </configuration>ファイルを保存して、エディターを閉じます。
アプリの実行をもう一度開始します。
dotnet runアプリケーションは、以前と同様に実行されます。 ただし、今回は要求が 3 つのサーバーに分散されます。
アプリを数分間実行してから続行します。
アプリを監視してパフォーマンス メトリックの違いを確認する
アプリを実行したままにして、Azure portal に戻ります。
左側のペインで、[ダッシュボード] を選択します。
グラフを選択して、[メトリック] ペインに開きます。
このグラフには、adventureworks*[nnn]* サーバーのメトリックが表示されますが、レプリカのメトリックは表示されません。 各レプリカの負荷はほぼ同じです。
このグラフの例では、開始から 30 分間にわたってアプリケーションで収集されたメトリックが示されています。 このグラフは、CPU 使用率が依然として高いものの、メモリ使用率が低かったことを示しています。 また、約 25 分後に、システムで 30 個を超える接続が確立されました。 これは、以前の構成と比較して好ましくない可能性があります。以前の構成では、45 分後に 70 個の接続がサポートされました。 ただし、ワークロードが 3 台のサーバーに分散されるようになり、すべて同じレベルで実行され、101 個の接続がすべて確立されました。 さらに、システムでは、接続エラーが報告されずに実行することができました。
CPU 使用率の問題に対処するには、CPU コアが多いより高い価格レベルにスケールアップします。 このラボで使用されているシステムの例は、2 コアを持つ Basic 価格レベルを使用して実行されています。 General purpose 価格レベルに変更すると、最大 64 コアが提供されます。
Cloud Shell に戻り、Enter キーを押してアプリを停止します。
ここでは、Azure portal で使用できるツールを使用して、サーバーのアクティビティを監視する方法について学習しました。 また、レプリケーションを構成する方法についても学習しました。読み取りが集中的に行われるデータのシナリオで読み取り専用レプリカを作成してワークロードを分散する方法についても学習しました。