演習 - 機械学習モデルをトレーニングする
正常に動作している製造デバイスと故障した製造デバイスからセンサー データを収集しました。 ここで、Model Builder を使用して、マシンが故障するかどうかを予測する機械学習モデルをトレーニングしたいと考えています。 機械学習を使用してこれらのデバイスの監視を自動化すると、よりタイムリーで信頼性の高いメンテナンスを提供できることによって、会社の費用を節約できます。
新しい機械学習モデル (ML.NET) 項目の追加
トレーニング プロセスを開始するには、新しい機械学習モデル (ML.NET) 項目を新規または既存の .NET アプリケーションに追加する必要があります。
C# クラス ライブラリを作成する
一から始めるので、機械学習モデルの追加先となる新しい C# クラス ライブラリ プロジェクトを作成します。
Visual Studio を起動します。
開始ウィンドウで、[新しいプロジェクトの作成] を選択します。
[新しいプロジェクトの作成] ダイアログで、検索バーに「クラス ライブラリ」と入力します。
オプション リストから [クラス ライブラリ] を選択します。 言語が C# であることを確認し、[次へ] を選択します。
[プロジェクト名] テキスト ボックスに、「PredictiveMaintenance」と入力します。 他のすべてのフィールドは既定値のままにし、[次へ] を選択します。
[フレームワーク] ドロップダウン リストで [.NET 6.0 (プレビュー)] を選択してから、[作成] を選択して C# クラス ライブラリをスキャフォールディングします。

プロジェクトに機械学習を追加する
クラス ライブラリ プロジェクトが Visual Studio で開いたら、機械学習をそこに追加します。
Visual Studio ソリューション エクスプローラーで、プロジェクトを右クリックします。
[追加]>[機械学習モデル] を選択します。
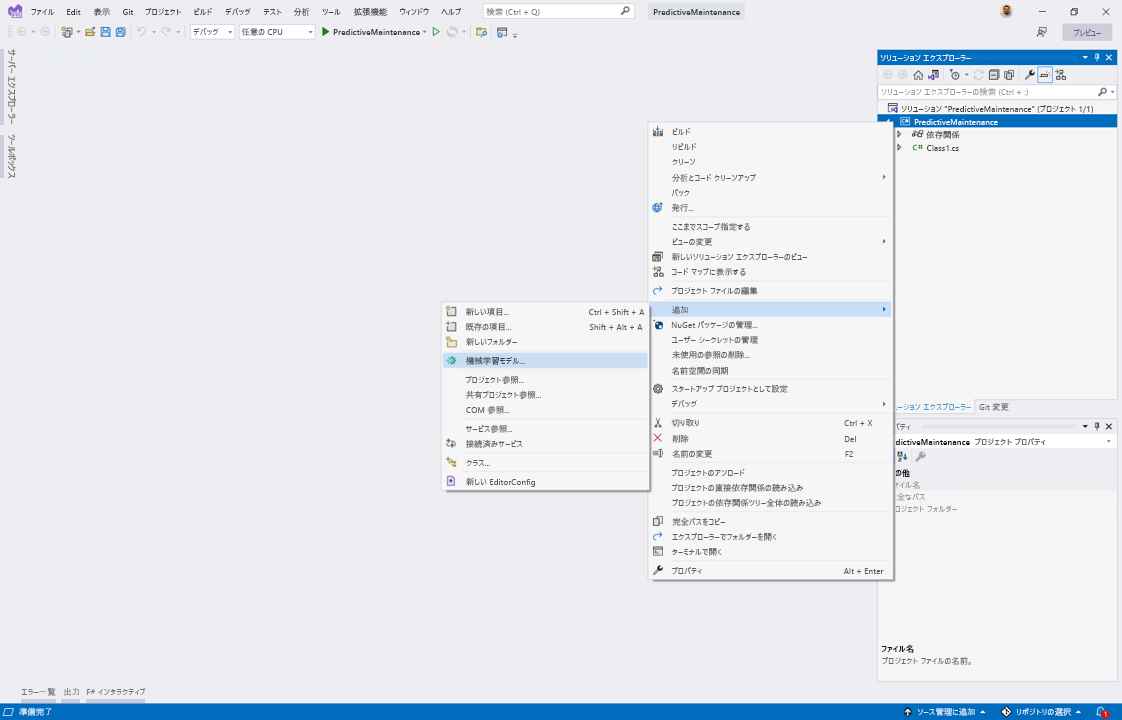
[新しい項目の追加] ダイアログにある新しい項目の一覧から、[機械学習モデル (ML.NET)] を選択します。
[名前] テキスト ボックスで、モデルの名前として「PredictiveMaintenanceModel.mbconfig」を使用し、[追加] を選択します。


数秒後に、PredictiveMaintenanceModel.mbconfig というファイルがプロジェクトに追加されます。
シナリオの選択
プロジェクトに機械学習モデルを初めて追加すると、Model Builder 画面が開きます。 次に、シナリオを選択できます。
今回のユース ケースでは、マシンが壊れているかどうかを判断しようとしています。 オプションは 2 つだけで、マシンの状態を判断する必要があるので、データ分類シナリオが最も適切です。
Model Builder 画面の [シナリオ] ステップで、[データ分類] シナリオを選択します。 このシナリオを選択すると、すぐに [環境] ステップに進みます。

環境の作成
データ分類シナリオでサポートされるのは、CPU を使用するローカル環境のみです。
- Model Builder 画面の [環境] ステップでは、既定で [ローカル (CPU)] が選択されています。 既定の環境を選択したままにしてください。
- [次のステップ] を選択します。

データの読み込みと準備
シナリオとトレーニング環境を選択したので、次は Model Builder を使用して収集したデータを読み込み、準備します。
データを準備する
ファイルを任意のテキスト エディターで開きます。
元の列名には、特殊なかっこ文字が含まれています。 データ解析に関する問題を回避するには、列名から特殊文字を削除します。
元のヘッダー:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNF更新されたヘッダー:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNF変更内容が含まれる ai4i2020.csv ファイルを保存します。
データ ソースの種類の選択
予測メンテナンス データセットは CSV ファイルです。
Model Builder 画面の [データ] ステップで [データ ソースの種類] として [ファイル (csv、tsv、txt)] を選択します。
データの場所の指定
[参照] ボタンを選択し、エクスプローラーを使用して ai4i2020.csv データセットの場所を指定します。
ラベル列の選択
[予測する列 (ラベル)] ドロップダウン リストから [マシン障害] を選択します。

詳細データ オプションを選択する
既定では、ラベル以外のすべての列が特徴として使用されます。 一部の列には冗長な情報が含まれていたり、他の列では予測に関する情報が含まれていなかったりします。 それらの列を無視するには、詳細データ オプションを使用します。
[詳細なデータ オプション] を選択します。
[詳細なデータ オプション] ダイアログで、[列の設定] タブを選択します。
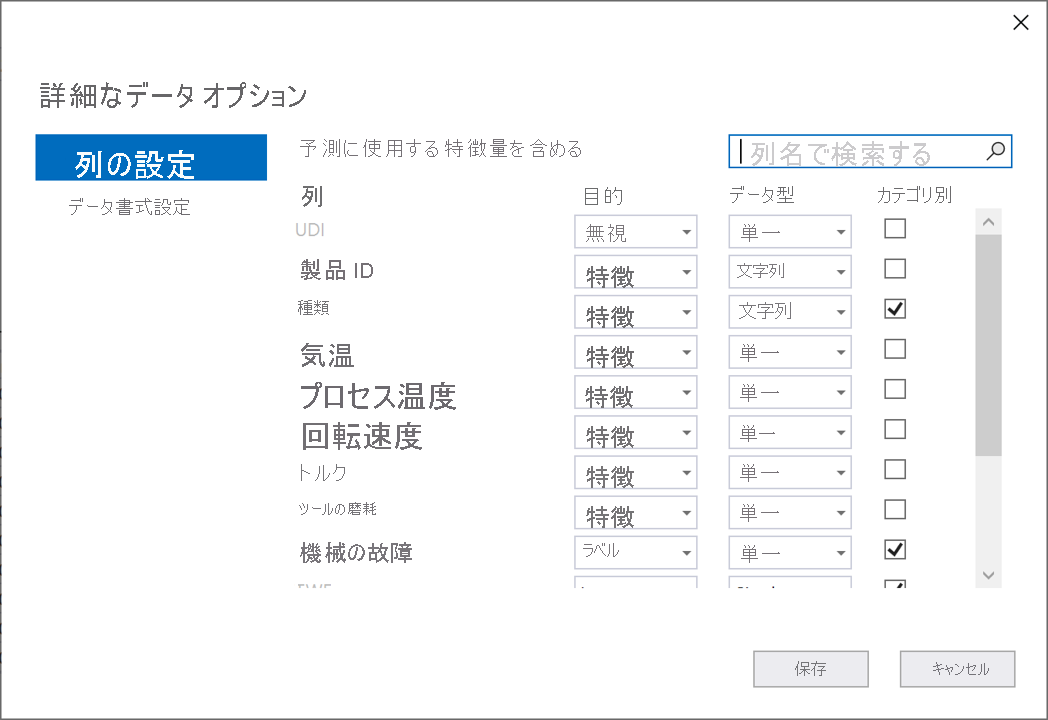
列の設定を次のように構成します。
[列] 目的 データ型 Categorical UDI Ignore Single Product ID 機能 String Type 特徴量 String X 気温 機能 Single 加工温度 機能 Single 回転速度 機能 Single Torque 機能 Single 工具磨耗 機能 Single マシン障害 ラベル Single X TWF Ignore Single X HDF Ignore Single X PWF Ignore Single X OSF Ignore Single X RNF Ignore Single X [保存] を選択します。
Model Builder 画面の [データ] ステップで、[次のステップ] を選択します。

モデルをトレーニングする
Model Builder と AutoML を使用してモデルをトレーニングします。
トレーニング時間の設定
Model Builder では、ファイルのサイズに基づいてトレーニングが必要な時間の長さが自動的に設定されます。 この場合、Model Builder でさらに多くのモデルを調べることができるように、トレーニング時間により大きい数値を指定します。
- Model Builder 画面の [トレーニング] ステップで、[トレーニングする時間 (秒)] を [30] に設定します。
- [Train](トレーニング) を選択します。
トレーニング プロセスを追跡する

トレーニング プロセスが開始されると、Model Builder によってさまざまなモデルが調べられます。 トレーニング プロセスは、トレーニング結果と Visual Studio 出力ウィンドウで追跡されます。 トレーニング結果には、トレーニング プロセス全体で見つかった最適なモデルに関する情報が示されます。 出力ウィンドウに、使用されているアルゴリズムの名前、トレーニングにかかった時間、およびそのモデルのパフォーマンス メトリックなどの詳細情報が表示されます。
同じアルゴリズム名が複数回表示されることもあります。 これは、Model Builder によってさまざまなアルゴリズムが試されるだけでなく、それらのアルゴリズムでさまざまなハイパーパラメーター構成が試されるためです。
モデルを評価する
評価メトリックとデータを使用して、モデルのパフォーマンスの精度をテストします。
モデルの検査
Model Builder 画面の [評価] ステップでは、最適なモデルに対して選択された評価メトリックとアルゴリズムを検査できます。 選択したアルゴリズムとハイパーパラメーターが異なる場合があるため、結果がこのモジュールで説明した結果と異なっていても問題ありません。
モデルのテスト
[評価] ステップの [独自のモデルを試す] セクションで、新しいデータを提供し、予測の結果を評価できます。

[サンプル データ] セクションでは、予測を行うために、モデルの入力データを提供します。 各フィールドは、モデルのトレーニングに使用される列に対応しています。 これは、モデルが想定どおりに動作するかどうかを確認するための便利な手段となります。 既定で、Model Builder によって、データセットの最初の行に、サンプル データが事前に設定されます。
モデルをテストして、予想される結果が得られるかどうかを確認しましょう。
[サンプル データ] セクションで、次のデータを入力します。 それは、UID 161 のデータセット行から取得したものです。
列 [値] Product ID L47340 種類 L 気温 298.4 加工温度 308.2 回転速度 1282 Torque 60.7 工具磨耗 216 [予測] を選択します。
予測結果の評価
[結果] セクションには、モデルによって行われた予測と、その予測における信頼度が表示されます。
データセット内の UID 161 の [マシン障害] 列を見ると、値が 1 であることがわかります。 これは、[結果] セクションで最も信頼度の高い予測値と同じです。
必要に応じて、さまざまな入力値でモデルを試し、予測を評価することができます。
おめでとうございます! マシン障害を予測するためのモデルをトレーニングしました。 次のユニットでは、モデル使用について学習します。