早期終了を構成する
ハイパーパラメーターのチューニングは、モデルを微調整し、モデルのパフォーマンスを最適化できるハイパーパラメーターの値を選ぶのに役立ちます。
ただし、最適なモデルを見つけることは、終わりのない戦いになる可能性があります。 新しいハイパーパラメーター値をテストし、よりパフォーマンスに優れたモデルを見つけることに時間と費用をかける価値があるかどうかを常に検討する必要があります。
スイープ ジョブの各試行では、ハイパーパラメーター値の新しい組み合わせを使って新しいモデルがトレーニングされます。 新しいモデルをトレーニングしても有意に優れたモデルにならない場合は、スイープ ジョブを停止し、これまでで最高のパフォーマンスになったモデルを使うことをお勧めします。
Azure Machine Learning でスイープ ジョブを構成するときに、最大試行回数を設定することもできもす。 新しいモデルで有意に良い結果が得られない場合、スイープ ジョブの停止がより洗練されたアプローチである可能性があります。 モデルのパフォーマンスに基づいてスイープ ジョブを停止するには、早期終了ポリシーを使用できます。
早期終了ポリシーを使うタイミング
早期終了ポリシーを使うかどうかは、使う検索空間とサンプリング方法に左右されることがあります。
たとえば、"グリッド サンプリング" 方法を "離散" 検索空間で使い、最大 6 回試行することを選択できます。 6 回試行すると、最大 6 つのモデルがトレーニングされ、早期終了ポリシーは不要になる場合があります。
早期終了ポリシーは、検索空間内で継続的なハイパーパラメーターを使う場合に特に役立ちます。 継続的なハイパーパラメーターは、選択できる値の数が無制限です。 早期終了ポリシーの使用が最も推奨されるのは、継続的なハイパーパラメーターとランダムまたはベイジアンのサンプリング方法を使う場合です。
早期終了ポリシーを構成する
早期終了ポリシーの使用を選ぶ場合、主なパラメーターが 2 つあります。
evaluation_interval: ポリシーを評価する間隔を指定します。 1 回の試行でプライマリ メトリックがログに記録されるたびに、1 つの間隔としてカウントされます。delay_evaluation: ポリシーの評価をいつ開始するかを指定します。 このパラメーターを使うと、早期終了ポリシーの影響を受けずに、少なくとも最小限の試行を完了することができます。
新しいモデルは、以前のモデルよりわずかに優れたパフォーマンスを発揮し続ける可能性があります。 モデルが以前の試行と比べてどの程度優れたパフォーマンスを発揮すべきかを判断できるように、早期終了には 3 つのオプションがあります。
- バンディット ポリシー:
slack_factor(相対) またはslack_amount(絶対) を使います。 新しいモデルは、最高のパフォーマンスを発揮するモデルの余裕期間範囲内で実行する必要があります。 - 中央値停止ポリシー: プライマリ メトリックの平均値の中央値を使います。 新しいモデルは、中央値よりも優れたパフォーマンスを発揮する必要があります。
- 切り捨て選択ポリシー:
truncation_percentageを使います。これは、最もパフォーマンスの低い試行の割合です。 新しいモデルは、最もパフォーマンスの低い試行よりも優れたパフォーマンスを発揮する必要があります。
バンディット ポリシー
バンディット ポリシーを使うと、ターゲット パフォーマンス メトリックが、指定したマージン分よりもこれまでの最高の試行を下回った場合、試行を停止できます。
たとえば、次のコードでは、5 回の試行の遅延でバンディット ポリシーを適用し、間隔ごとにポリシーを評価し、0.2 の絶対余裕期間を許容しています。
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
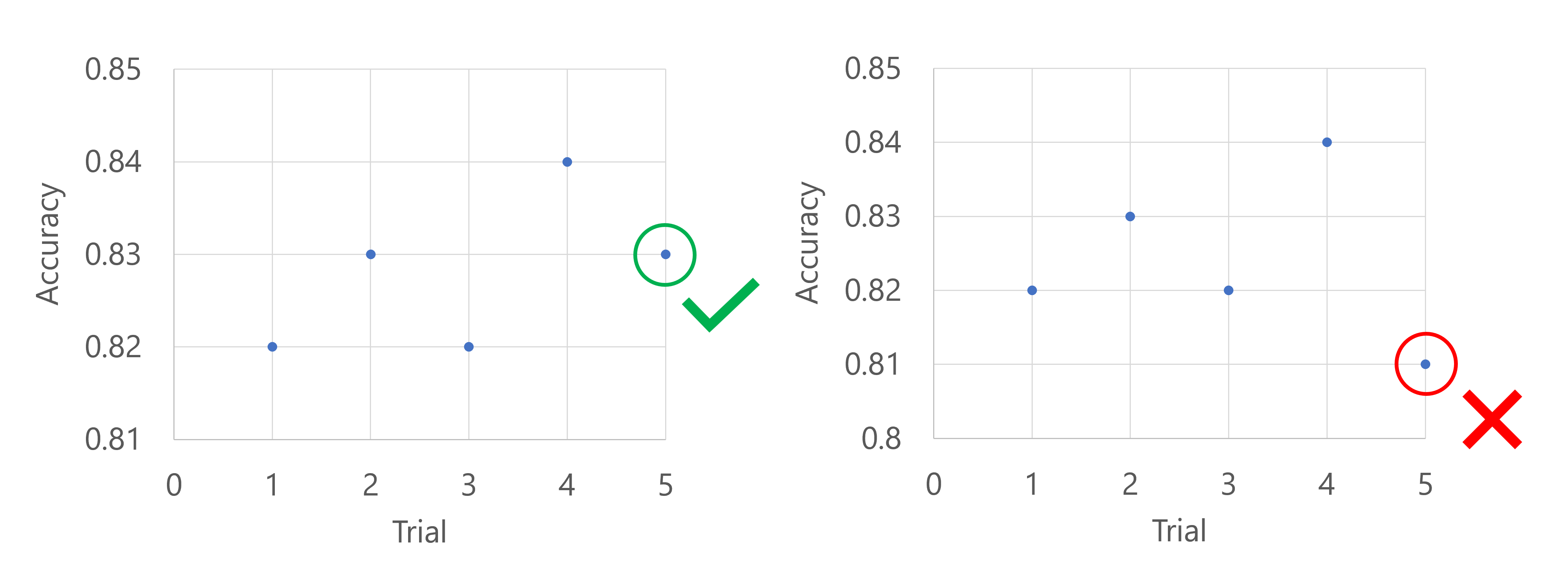
プライマリ メトリックはモデルの精度であるとします。 最初の 5 回の試行の後、パフォーマンスが最高のモデルの精度が 0.9 である場合、新しいモデルは (0.9-0.2) つまり 0.7 よりも優れたパフォーマンスである必要があります。 新しいモデルの精度が 0.7 を超える場合、スイープ ジョブは続行されます。 新しいモデルの精度が 0.7 未満の場合、ポリシーにより、スイープ ジョブは停止されます。
また、スラック "係数" を使用してバンディット ポリシーを適用することもできます。この場合、パフォーマンス メトリックは絶対値ではなく比率として比較されます。
中央値の停止ポリシー
中央値停止ポリシーでは、ターゲット パフォーマンス メトリックがすべての試行の移動平均の中央値を下回っている試行が破棄されます。
たとえば、次のコードでは、5 回の試行の遅延で中央値停止ポリシーを適用し、間隔ごとにポリシーを評価しています。
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
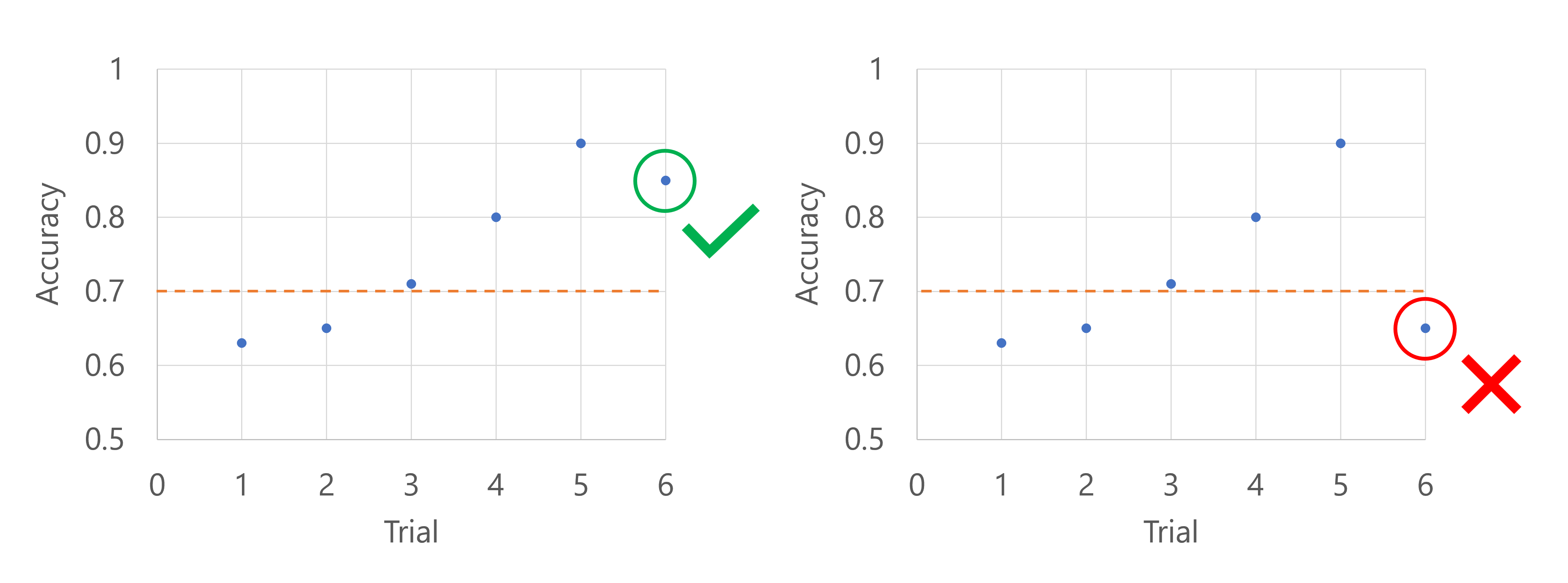
プライマリ メトリックはモデルの精度であるとします。 6 回目の試行で精度がログに記録されるとき、そのメトリックはこれまでの精度スコアの中央値より高い必要があります。 これまでの精度スコアの中央値が 0.82 であるとします。 新しいモデルの精度が 0.82 を超える場合、スイープ ジョブは続行されます。 新しいモデルの精度が 0.82 未満の場合、ポリシーにより、スイープ ジョブは停止され、新しいモデルはトレーニングされません。
切り捨て選択ポリシー
切り捨て選択ポリシーでは、X に対して指定した truncation_percentage 値に基づいて、各評価間隔でパフォーマンスが低い X% の試行を取り消します。
たとえば、次のコードでは、4 回の試行の遅延で切り捨て選択ポリシーを適用し、間隔ごとにポリシーを評価し、20% の切り捨て率を使っています。
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
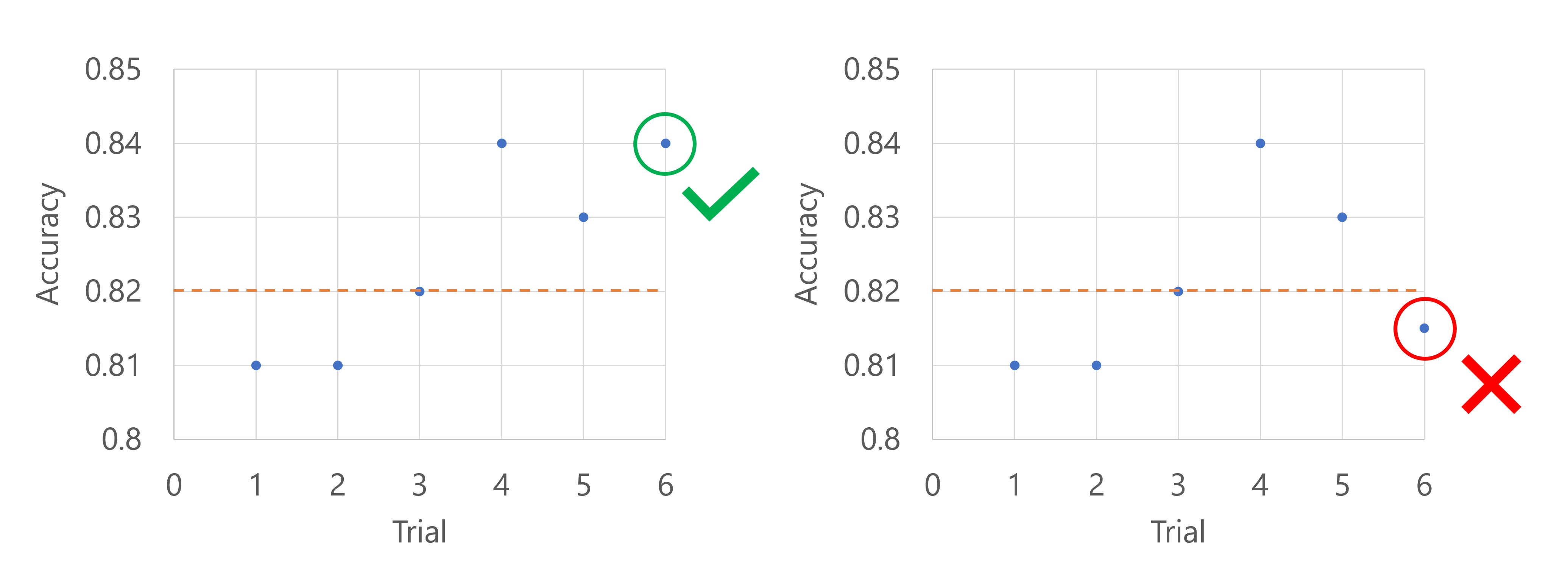
プライマリ メトリックはモデルの精度であるとします。 5 回目の試行で精度がログに記録されるとき、そのメトリックがこれまでの試行の下位 20% に入る場合は許容されません。 このケースでは、20% は 1 回の試行に相当します。 つまり、5 回目の試行がこれまでで最悪のパフォーマンスのモデルでない場合、スイープ ジョブは継続されます。 5 回目の試行がこれまでのすべての試行の中で精度スコアが最も低い場合、スイープ ジョブは停止されます。