演習 - Kafka データを Jupyter Notebook にストリーム配信し、データをウィンドウ処理する
Kafka クラスターでは現在、そのログにデータを書き込んでおり、そのデータは Spark Structured Streaming を使用して処理できます。
複製したサンプルには Spark ノートブックが組み込まれているので、そのノートブックを使用するには、それを Spark クラスターにアップロードする必要があります。
Python ノートブックを Spark クラスターにアップロードする
Azure portal で、[ホーム] > [HDInsight クラスター] の順にクリックしてから、先ほど作成した Spark クラスター (Kafka クラスターではありません) を選択します。
[クラスター ダッシュボード] ペインで、[Jupyter Notebook] をクリックします。

資格情報の入力を求められたら、管理者のユーザー名を入力し、クラスターの作成時に作成したパスワードを入力します。 Jupyter の Web サイトが表示されます。
[PySpark] をクリックしてから、[PySpark] ページの [アップロード] をクリックします。
GitHub からサンプルをダウンロードした場所に移動し、RealTimeStocks.ipynb ファイルを選択してから、[開く]、[アップロード] の順にクリックした後、インターネット ブラウザーで [最新の情報に更新] をクリックします。
ノートブックが PySpark フォルダーにアップロードされたら、[RealTimeStocks.ipynb] をクリックして、そのノートブックをブラウザーで開きます。
ノートブックの最初のセルを実行します。そのためには、そのセル内にカーソルを置き、Shift+Enter キーを押してセルを実行します。
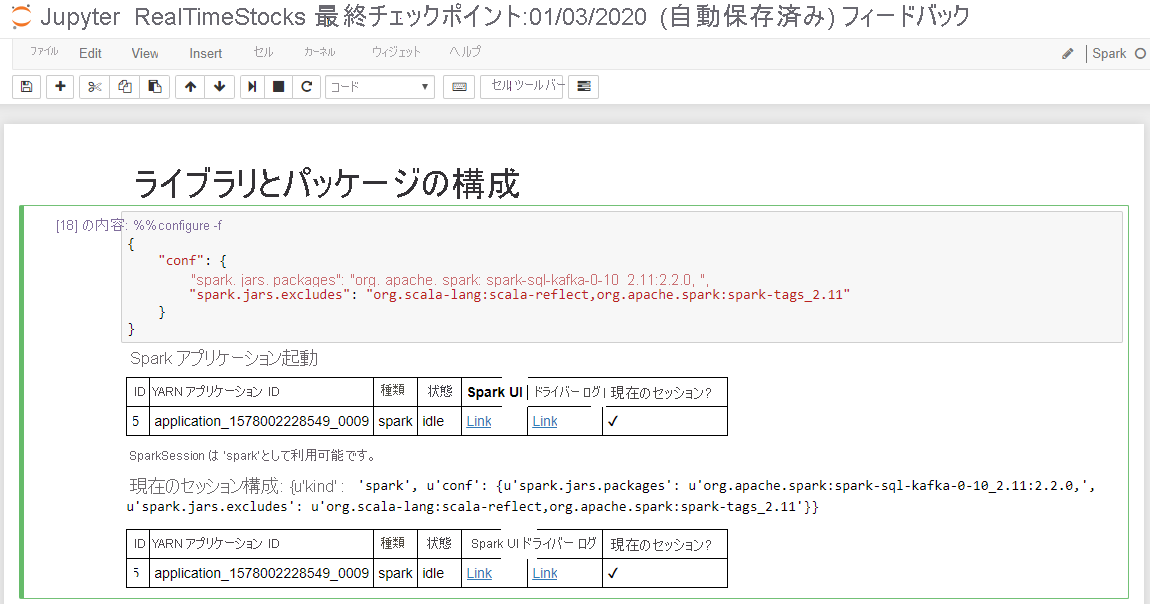
次の画面のキャプションに示すように、[ライブラリとパッケージの構成] セルに "Spark アプリケーションを開始中" のメッセージと追加情報が表示されると、セルは正常に完了します。
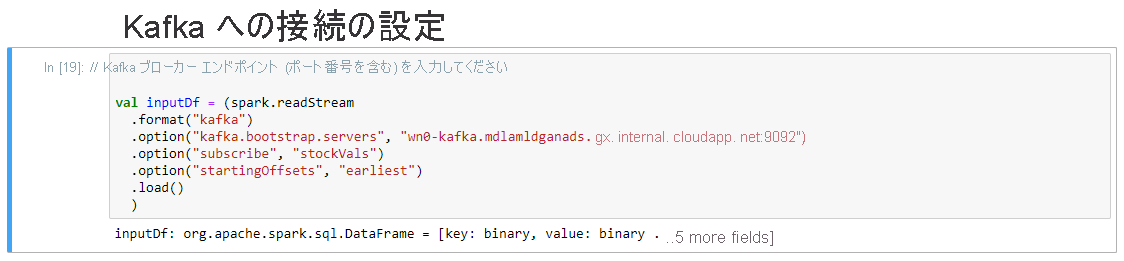
[Kafka への接続の設定] セルの .option("kafka.bootstrap.servers", "") 行で、2 番目の引用符セットの間に kafka ブローカーを入力します。 次に例を示します。 .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092")。次に、Shift + Enter キーを押してセルを実行します。
[Kafka への接続の設定] セルに次のメッセージが表示されると、セルは正常に完了します。"inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 more fields]" Spark では、readStream API を使用してデータを読み取ります。
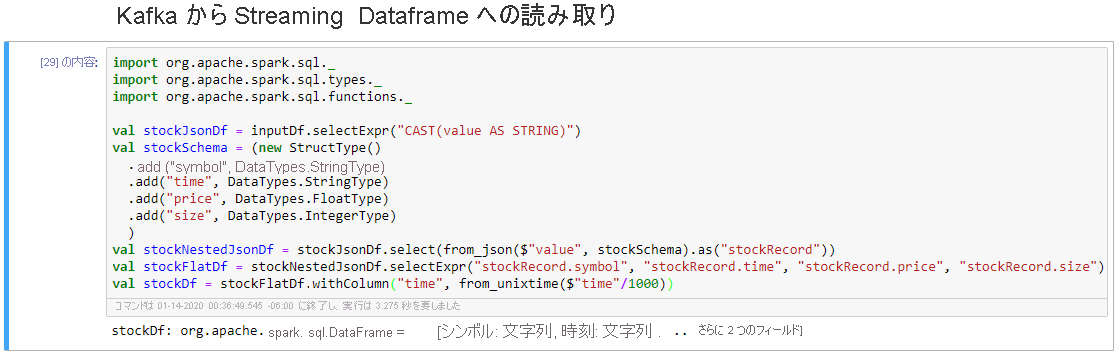
[Kafka からストリーミング データフレームへの読み取り] セルを選択してから、Shift+Enter キーを押してセルを実行します。
セルに次のメッセージが表示されると、セルは正常に完了します。"stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]"
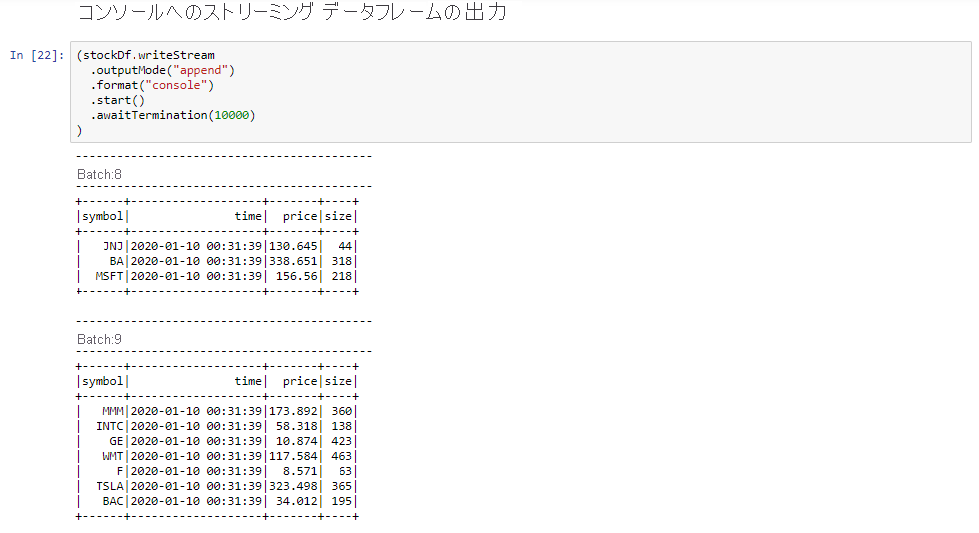
[コンソールへのストリーミング データフレームの出力] セルを選択してから、Shift+Enter キーを押してセルを実行します。
セルに次のような情報が表示されると、セルは正常に完了します。 出力には、マイクロ バッチで渡された各セルの値が表示されます (1 秒につき 1 つのバッチ)。
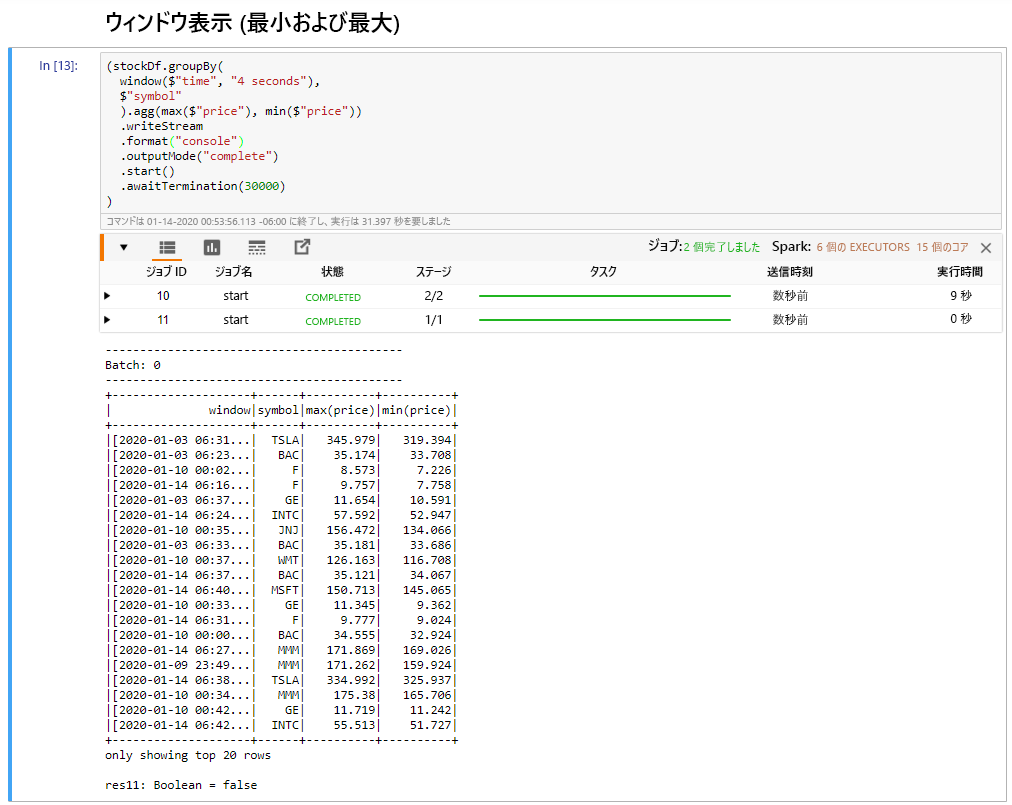
[ウィンドウ処理された株式の最安値と最高値] セルを選択してから、Shift+Enter キーを押してセルを実行します。
セルに定義された 4 秒間ウィンドウで各株式の最高値と最安値が表示されると、セルは正常に完了します。 前のユニットで説明したように、特定の時間ウィンドウに関する情報を提供することは、Spark Structured Streaming を使用することで得られる利点の 1 つです。
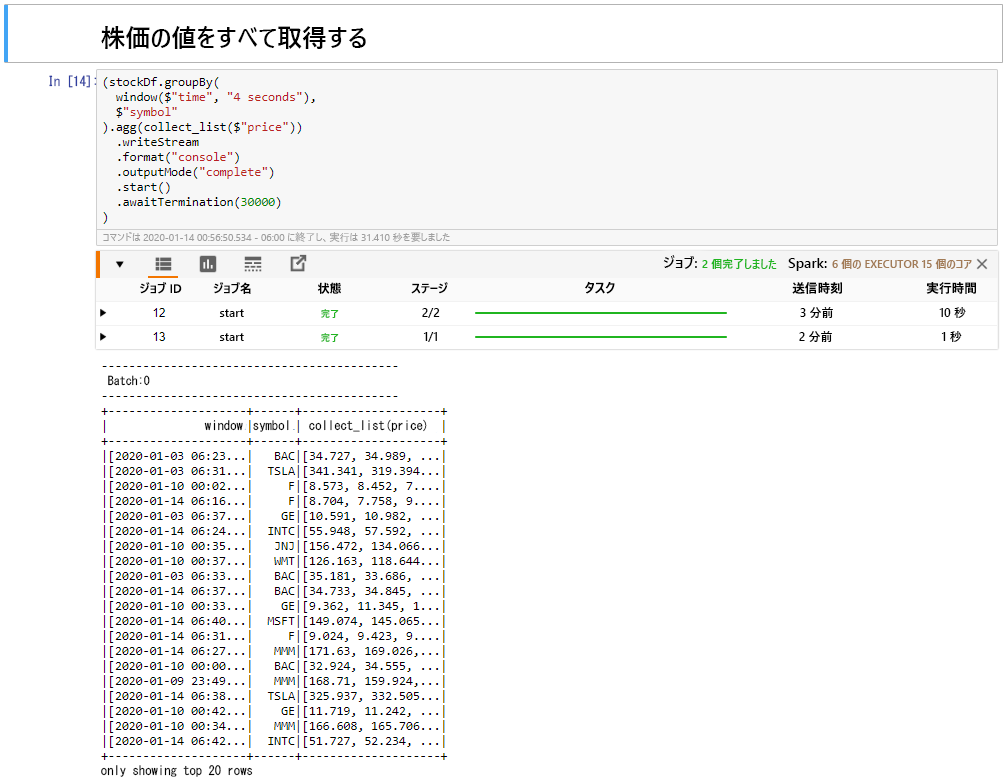
[ウィンドウ内の株価のすべての値を収集する] セルを選択してから、Shift+Enter キーを押してセルを実行します。
テーブル内の株式の価格表が表示されると、セルは正常に完了します。 OutputMode が完了すると、すべてのデータが表示されます。
このユニットでは、Jupyter Notebook を Spark クラスターにアップロードし、それを Kafka クラスターに接続しました。また、Python プロデューサー ファイルによって作成されたストリーミング データを Spark ノートブックに出力しました。さらに、ストリーミング データ用のウィンドウを定義して、そのウィンドウに株価の高値と安値を表示し、テーブル内のすべての株価を表示しました。 これで、Spark と Kafka を使用した構造化ストリーミングが正常に実行されました。