演習 - 高度なストリーミング データ変換を実行するために HDInsight をプロビジョニングする
Azure 仮想ネットワークを作成し、その仮想ネットワーク内に Kafka クラスターと Spark クラスターを作成するには、次の手順に従います。
こちらのリンクを開いて Azure portal にサインインし、新しいウィンドウで [カスタム デプロイ] ページを開きます。
このテンプレートでは、次のリソースを作成します。
- HDInsight 4.0 用の Kafka 2.1.1 クラスター。
- HDInsight 4.0 用の Spark 2.4.4 クラスター。
- Azure Virtual Network (HDInsight クラスターを含む)
次の情報に従って、 [カスタマイズされたテンプレート] セクションの各エントリに入力します。
設定 値 サブスクリプション クラスターの作成に使用するサブスクリプションを選択します。 Resource group [新規作成] をクリックして新しいリソース グループを作成し、そのリソース グループに一意の名前を付けます。 場所 リソースが作成される Azure リージョン。 [Spark Cluster Name](Spark クラスター名) Spark クラスターの名前を入力します (例: spark-mslearn-stock)。 最初の 6 文字は、Kafka クラスターの名前と異なるものにする必要があります。 [Kafka Cluster Name](Kafka クラスター名) Kafka クラスターの名前を入力します (例: kafka-mslearn-stock)。 最初の 6 文字は、Spark クラスターの名前と異なるものにする必要があります。 [Cluster Login User Name](クラスター ログイン ユーザー名) 既定値の [admin] のままにします。 [クラスター ログイン パスワード] クラスター ログイン用のパスワードを入力します。 [SSH ユーザー名] 既定値の [sshuser] のままにします。 [SSH パスワード] SSH ユーザーのパスワードを入力します。 使用条件を読み、 [上記の使用条件に同意する] をオンにします。
[購入] を選択します。
[通知] アイコンをクリックして、デプロイの進行状況を確認します。
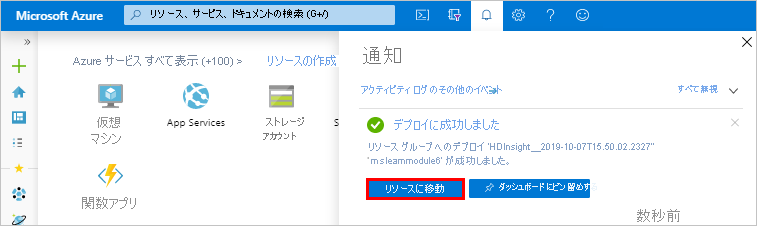
デプロイが成功すると、メッセージは [デプロイに成功しました] に変わります。
[通知] ウィンドウで、[リソースに移動] をクリックします。
デプロイに関するエラーが発生した場合は、[通知] アイコンをクリックし、Kafka と Spark のクラスター名が同じ 6 文字を共有していないことを確認します。 それらが同じ 6 文字を使用している場合は、Azure リソース テンプレートを再実行し、それらのクラスター名を修正します。