適切な MPI ライブラリを選択する
HB120_v2、HB60、および HC44 SKU では、InfiniBand ネットワーク相互接続がサポートされています。 PCI Express が Single-Root Input/Output (SR-IOV) 仮想化によって仮想化されているため、これらの HPC V で、すべての一般的な MPI ライブラリ (HPCX、OpenMPI、Intel MPI、MVAPICH、MPICH) を使用できます。
InfiniBand 経由で通信できる HPC クラスターの現在の制限は 300 台の VM です。 次の表に、InfiniBand 経由で通信している密結合された MPI アプリケーションでサポートされる並列プロセスの最大数を示します。
| SKU | 並列プロセスの最大数 |
|---|---|
| HB120_v2 | 36,000 プロセス |
| HC44 | 13,200 プロセス |
| HB60 | 18,000 プロセス |
Note
これらの制限は、今後変更される可能性があります。 高い上限を必要とする密結合された MPI ジョブがある場合は、サポート要求を送信してください。 状況に応じて上限を引き上げることができます。
HPC アプリケーションで特定の MPI ライブラリが推奨されている場合は、最初にそのバージョンを使用します。 選択できる MPI について柔軟性があり、最高のパフォーマンスを必要とする場合に、HPCX を試します。 全体として、HPCX MPI では、InfiniBand インターフェイスに UCX フレームワークを使用して、最高のパフォーマンスが発揮され、Mellanox InfiniBand のハードウェアとソフトウェアのすべての機能が利用されます。
次の図は、一般的な MPI ライブラリ アーキテクチャを比較しています。
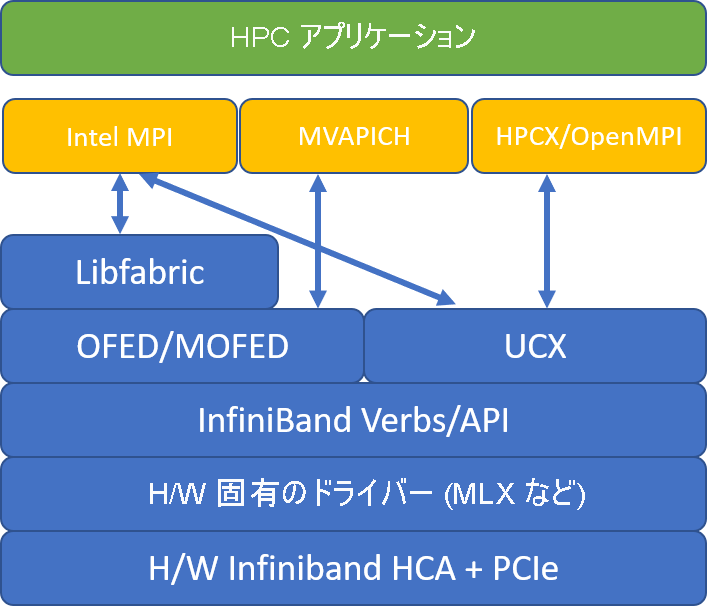
HPCX と OpenMPI は ABI 互換性があるため、OpenMPI でビルドされた HPCX で HPC アプリケーションを動的に実行できます。 同様に、Intel MPI、MVAPICH、MPICH は ABI 互換性があります。
低レベル ハードウェア アクセスによるセキュリティの脆弱性を防ぐために、キュー ペア 0 にはゲスト VM からアクセスできません。 これは、エンドユーザー HPC アプリケーションに影響を与えないはずですが、一部の低レベル ツールが正常に機能しなくなる可能性があります。
HPCX と OpenMPI の mpirun 引数
次のコマンドは、HPCX と OpenMPI の推奨されるいくつかの mpirun 引数を示しています。
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
そのコマンドについて説明します。
| パラメーター | Description |
|---|---|
$NPROCS |
MPI プロセスの数を指定します (例: -n 16)。 |
$HOSTFILE |
MPI プロセスが実行される場所を示すために、ホスト名または IP アドレスを含むファイルを指定します。 (例: --hostfile hosts)。 |
$NUMBER_PROCESSES_PER_NUMA |
各 NUMA ドメインで実行される MPI プロセスの数を指定します。 例: NUMA あたり 4 つの mpi プロセスを指定するには、--map-by ppr:4:numa:pe=1 を使用します。 |
$NUMBER_THREADS_PER_PROCESS |
MPI プロセスあたりのスレッド数を指定します。 例: NUMA あたり 1 つの MPI プロセスと 4 つのスレッドを指定するには、--map-by ppr:1:numa:pe=4 を使用します。 |
-report-bindings |
コアにマッピングされている MPI プロセスを出力します。これは、MPI プロセスの固定が正しいことを確認するのに役立ちます。 |
$MPI_EXECUTABLE |
MPI ライブラリにリンクが構築される MPI 実行可能ファイルを指定します。 MPI コンパイラ ラッパーでは、これが自動的に実行されます。 たとえば、mpicc や mpif90 などです。 |
密結合された MPI アプリケーションで、大量の集合通信を行っていると思われる場合は、Hierarchical Collectives (HCOLL) を有効にしてみることができます。 それらの機能を有効にするには、次のパラメーターを使います。
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Intel MPI mpirun 引数
Intel MPI 2019 リリースは、Open Fabrics Alliance (OFA) フレームワークから Open Fabrics Interfaces (OFI) f フレームワークに切り替えられており、現在は libfabric がサポートされています。 InfiniBand のサポートには、mlx と verbs の 2 つのプロバイダーがあります。 プロバイダー mlx は、HB および HC VM で優先されるプロバイダーです。
Intel MPI 2019 Update 5 以降の推奨されるいくつかの mpirun 引数を次に示します。
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
これらの引数について説明します。
| パラメーター | 説明 |
|---|---|
FI_PROVIDER |
使用する libfabric プロバイダーを指定します。これは、使用されている API、プロトコル、およびネットワークに影響します。 verbs はもう 1 つのオプションですが、一般に mlx の方がパフォーマンスに優れます。 |
I_MPI_DEBUG |
追加のデバッグ出力のレベルを指定します。これにより、プロセスが固定される場所と使用されるプロトコルとネットワークに関する詳細を指定できます。 |
I_MPI_PIN_DOMAIN |
プロセスを固定する方法を指定します。 たとえば、コア、ソケット、または NUMA ドメインへ固定できます。 この例では、この環境変数を numa に設定しています。これは、プロセスが NUMA ノード ドメインに固定されることを意味します。 |
他にもいくつかのオプションを試してみることができます。特に、集合演算で著しく時間がかかっている場合です。 Intel MPI 2019 Update 5 以上では、プロバイダー mlx がサポートされ、UCX フレームワークを使用して InfiniBand と通信します。 また、HCOLL もサポートされています。
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
MVAPICH mpirun 引数
次の一覧に、推奨されるいくつかの mpirun 引数を示します。
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
これらの引数について説明します。
| パラメーター | 説明 |
|---|---|
MV2_CPU_BINDING_POLICY |
使用するバインド ポリシーを指定します。これは、プロセスがコア ID に固定される方法に影響します。 この例では、scatter を指定するので、プロセスが NUMA ドメイン間で均等に分散されます。 |
MV2_CPU_BINDING_LEVEL |
プロセスを固定する場所を指定します。 この例では、それを numanode に設定しています。これは、プロセスが NUMA ドメインのユニットに固定されることを意味します。 |
MV2_SHOW_CPU_BINDING |
プロセスが固定されている場所に関するデバッグ情報を取得する必要がある場合に指定します。 |
MV2_SHOW_HCA_BINDING |
各プロセスで使用されているホスト チャネル アダプターに関するデバッグ情報を取得する必要がある場合に指定します。 |