プロセスの固定に関する考慮事項
プロセスとスレッドを固定する理由
実行間で最大のパフォーマンスを達成し、より一貫したパフォーマンスを得られるようにするため、プロセスを特定のコアに常に固定してください。
プロセスの固定:
すべてのメモリ チャネルが使用され、すべてのメモリ チャネルがコア間で均等に分散される場所にプロセスを配置または固定することで、メモリ帯域幅が最大化されます。
各プロセスがその独自のコア上にあることが保証されることで、浮動小数点パフォーマンスが向上します。 これにより、2 つのプロセスが同じコアに割り当てられる可能性をな排除します。
通信するプロセスが Non-Uniform Memory Access (NUMA) ドメイン ノードに配置されることで、プロセス間のデータ移動が最適化されます。 これにより、最短の待機時間と最高の帯域幅が確保されます。
オペレーティング システムによってプロセスが別のコアや NUMA ドメインに移動されることがないため、オペレーティング システムのオーバーヘッドが削減され、より一貫性のある結果が得られます。
プロセスとスレッドを固定する場所
プロセスとスレッドを固定する場所を特定するには、プロセッサとメモリのトポロジ、および具体的には NUMA ドメインの数と場所を把握する必要があります。
lstopo-no-graphics ユーティリティ (hwloc RPM から) と Intel Memory Latency Checker (MLC) は、プロセッサとメモリのトポロジを特定するのに便利なツールです。 例: VM にある NUMA ドメインの数はいくつですか。 各 NUMA ドメインのメンバーであるコアはどれですか。 各 NUMA ドメインで、それらが相互に通信するときのプロセスの待機時間と帯域幅はどのくらいですか。
次の画像は、Intel MLC によって生成される HB120_v2 NUMA ドメイン待機時間マップを示しています。 NUMA ドメイン間の待機時間が短いほど、それらの間の通信が速くなります。 この図は、HB120_v2 に 30 個の NUMA ドメインがあり、どの NUMA ドメインがどのソケット上にあるかを明確に示しています。 また、どの NUMA ドメインを一緒にグループ化して、最短のデータ転送および通信待機時間を達成できるかも示しています。

Intel プロセッサには 6 つのメモリ チャネルがあり、AMD EPYC プロセッサには 8 つのメモリ チャネルがあります。 使用可能なメモリ帯域幅を最大にするために、すべてのメモリ チャネルを使用するようにします。 これを行うには、並列プロセスを NUMA ノード ドメイン間に均等に分散します。 ハイブリッド並列アプリケーションでは、同じ NUMA ドメイン内にプロセスまたはスレッドのグループ化を維持して、同じ L3 キャッシュを共有することが理想的です。 合計スレッド数がコアの合計数を超えないようにします。
次の図は、2 つの NUMA ドメインと 44 個のコアがある HC44 SKU を示しています。
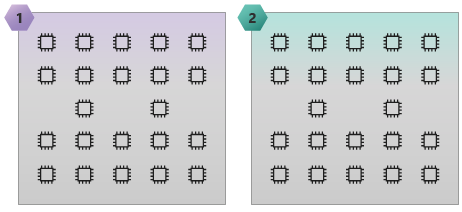
次の図は、15 個の NUMA ドメインと 60 個のコアがある HB60 SKU を示しています。
メモリ帯域幅にバインドされたアプリケーション
メモリ帯域幅に制約があるアプリケーションの場合、各 NUMA ノード ドメインでの並列プロセスとスレッドの数を減らすと、VM のパフォーマンスが向上する可能性があります。 これにより、プロセスあたりに割り当てられるメモリ帯域幅が増加し、場合によっては実時間が短縮されます。
たとえば、30 個の NUMA ノード ドメインで HB120_v2 SKU を使っている場合、NUMA ノード ドメインあたり 1 個、2 個、3 個のプロセスとスレッド (たとえば、VM あたり 30 個、60 個、90 個のプロセスとスレッド) の実行を試してみることができます。 こうして、最高のパフォーマンスが得られる構成を確認できます。