ソース システムを最適化する - 高度
VLDB システムのソースのエクスポートについては、こちらのより詳細なガイダンスが役に立つ場合があります。
Oracle の行 ID テーブルの分割
SAP からリリースされている SAP Note #1043380 には、WHR ファイルの WHERE 句を行 ID の値に変換するスクリプトが含まれます。 または、SWPM が Oracle から Oracle R3load への移行用に構成されている場合は、最新バージョンの SAPInst によって、行 ID 分割 WHR ファイルが自動的に生成されます。 SWPM によって生成される STR および WHR ファイルは、オペレーティング システムとデータベースに依存しません (OS と DB の移行プロセスのすべての側面と同様)。
OSS のノートには、"ターゲット データベースが Oracle 以外のデータベースである場合、行 ID テーブル分割は使用できません" と書かれています。 技術的には、R3load ダンプ ファイルは、データベースおよびオペレーティング システムから独立しています。 ただし、1 つの制限があり、SQL Server では、インポート中にパッケージを再起動することはできません。 そのような場合は、テーブル全体を削除し、テーブルのすべてのパッケージを再起動する必要があります。 1 つの分割 R3load が中止された場合は、常に、特定の分割テーブルに対する R3load タスクを終了し、テーブルを切り捨てて、インポート処理全体を再開することをお勧めします。 その理由は、R3load に組み込まれている回復プロセスには、1 つの行単位の DELETE ステートメントを実行して、R3load プロセスによって読み込まれたレコードを削除する処理が含まれるためです。 この処理は遅く、多くの場合、データベースでブロックやロックの状況が発生します。 経験上、この特定のテーブルのインポートを最初から始める方が高速であるため、SAP Note #1043380 で示されている制限は制限ではありません。
行 ID には、ダウンタイム中に分割の計算を行う必要があるという欠点があります。SAP Note #1043380 をご覧ください。
ソース データベースの "複製" を複数作成し、並列でエクスポートする
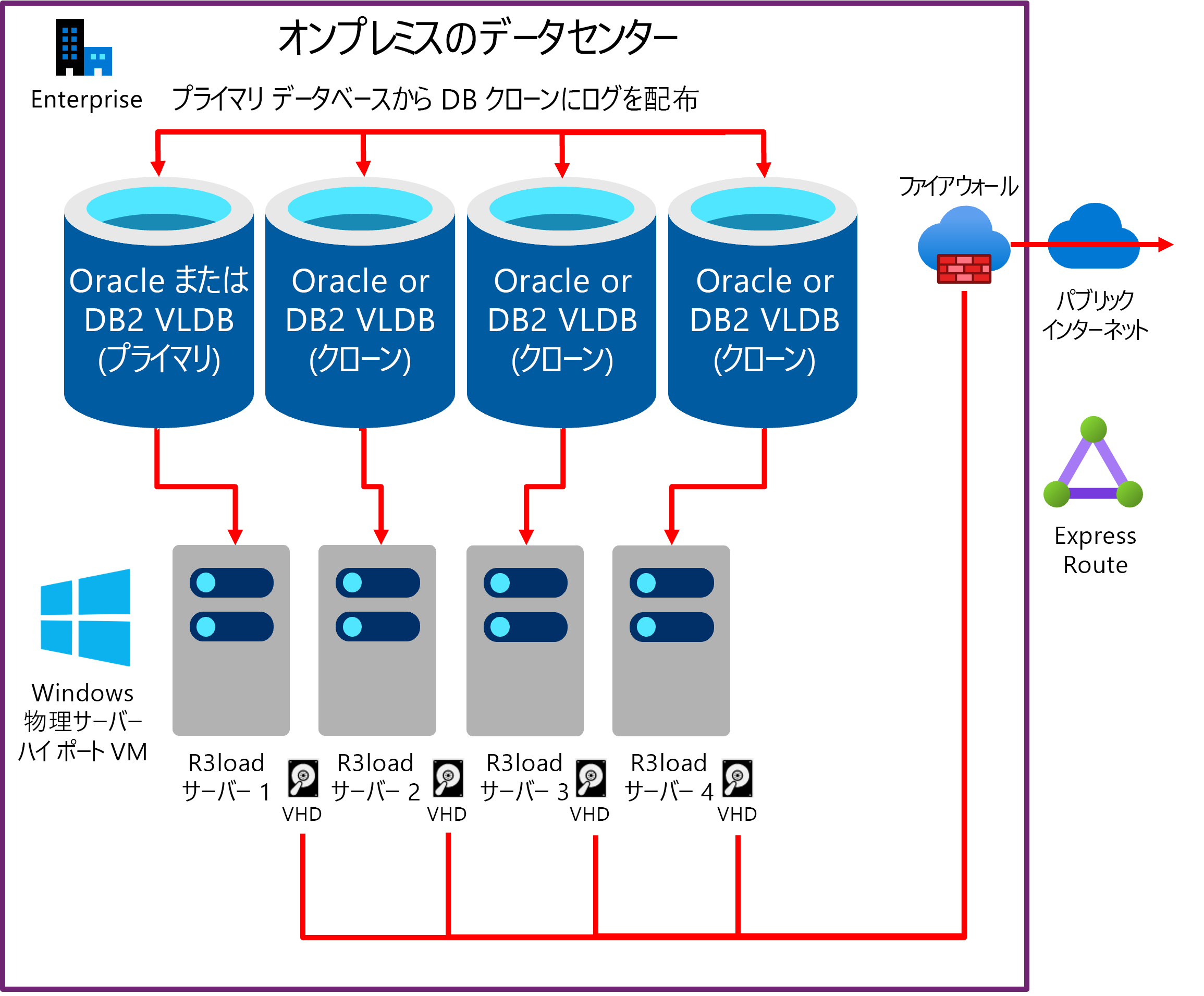
エクスポートのパフォーマンスを向上させる方法の 1 つは、同じデータベースの複数のコピーからエクスポートすることです。 サーバー、ネットワーク、ストレージなどの基になるインフラストラクチャがスケーラブルな場合、このアプローチを採用すると、直線的なスケーラビリティを実現できる傾向があります。 同じデータベースの 2 つのコピーからエクスポートすると 2 倍速く、4 つのコピーでは 4 倍速くなります。 Migration Monitor は、データベースの各 "複製" から選択した数のテーブルにエクスポートするように構成されています。 次の例では、エクスポート ワークロードは 4 つのデータベース サーバーのそれぞれに約 25% ずつ分散されます。
- DB サーバー 1 とエクスポート サーバー 1 – 最も大きい 1 から 4 個のテーブル専用 (ソース データベースでデータの分散がどの程度偏っているかにより異なります)
- DB サーバー 2 とエクスポート サーバー 2 – テーブル分割を含むテーブル専用
- DB サーバー 3 とエクスポート サーバー 3 – テーブル分割を含むテーブル専用
- DB サーバー 4 とエクスポート サーバー 4 – 残りのすべてのテーブル
データベースが正確に同期されるように注意する必要があります。そうしないと、データの損失やデータの不整合が発生する可能性があります。 この手順に厳密に従うと、データの整合性は維持されます。
この手法はシンプルで、標準の Intel ハードウェア製品を使うと安価ですが、独自の UNIX ハードウェアを実行しているお客様でも可能です。 サンドボックス、開発、QAS、トレーニング、DR システムが既に Azure に移行されている OS と DB の移行プロジェクトの中盤になれば、かなりのハードウェア リソースが空いています。 "複製" サーバーのハードウェア リソースが同一であることは、厳密な要件ではありません。 CPU、RAM、ディスク、ネットワークのパフォーマンスが十分であれば、各複製を追加することでパフォーマンスが向上します。
高いエクスポート パフォーマンスが引き続き必要になる場合は、エクスポート パフォーマンスを高める追加の手順について、BC-DB-MSS で SAP インシデントを開いてください (高度なコンサルタントのみ)。
複数の並列エクスポートを実装する手順は次のとおりです。
- プライマリ データベースをバックアップし、"n" 台のサーバーに復元します (n = クローンの数)。 この例では、n = 3 サーバーであり、合計 4 台の DB サーバーを想定しています。
- バックアップを 3 台のサーバーに復元します。
- プライマリ ソース DB サーバーから 3 台のターゲット "クローン" サーバーへのログ配布を確立します。
- ログ配布を数日間監視し、ログ配布が確実に動作していることを確認します。
- ダウンタイムの開始時に、PAS を除くすべての SAP アプリケーション サーバーをシャットダウンします。 すべてのバッチ処理が停止し、すべての RFC トラフィックが停止していることを確認します。
- トランザクション SM02 で、「Checkpoint PAS Running」というテキストを入力します。 これにより、テーブル TEMSG が更新されます。
- プライマリ アプリケーション サーバーを停止します。 SAP がシャットダウンされました。 ソース DB では、それ以上書き込みアクティビティを実行できません。 SAP 以外のアプリケーションがソース DB に接続されていないことを確認します (これは必須ではありませんが、DB レベルで SAP 以外のセッションを確認してください)。
- プライマリ DB サーバーで次のクエリを実行します:
SELECT EMTEXT FROM [schema].TEMSG; - ネイティブ DBMS レベルのステートメントを実行します:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(正確な構文はソース DBMS によって異なります。EMTEXT への INSERT) - トランザクション ログの自動バックアップを停止します。 プライマリ DB サーバーで、最後の 1 つのトランザクション ログ バックアップを手動で実行します。 ログ バックアップが複製サーバーにコピーされていることを確認します。
- 3 つのノードすべてで最後のトランザクション ログ バックアップを復元します。
- 3 つの "複製" ノードでデータベースを復旧します。
- 4 つのノード "すべて" で次の SELECT ステートメントを実行します:
SELECT EMTEXT FROM [schema].TEMSG; - 4 台の DB サーバー (プライマリと 3 台のクローン) のそれぞれで、SELECT ステートメントの結果画面をキャプチャします。 必ず各ホスト名を慎重に含めてください。これは、クローン DB とプライマリが同一であり、同じ時点の同じデータが含まれていることを証明するものとして機能します。
- 各 Intel R3load エクスポート サーバーで export_monitor.bat を開始します。
- Azure プロセスへのダンプ ファイルのコピーを始めます (AzCopy または Robocopy)。
- R3load Azure 仮想マシンで import_monitor.bat を開始します。
次の図は、"複製" データベースへの既存の運用 DB サーバーのログ配布を示したものです。 各 DB サーバーには、1 つまたは複数の Intel R3load サーバーがあります。