Azure AI 検索ソリューションのパフォーマンスを最適化する
検索ソリューションのパフォーマンスは、インデックスのサイズと複雑さの影響を受ける可能性があります。 また、効率的なクエリを記述して検索し、適切なサービス レベルを選択する方法を知る必要があります。
ここでは、これらすべてのディメンションを調べ、検索ソリューションのパフォーマンス向上のために実行できる手順を確認します。
現在の検索パフォーマンスを測定する
検索サービスのパフォーマンスがわかっていないと、最適化はできません。 ベースラインとなるパフォーマンス ベンチマークを作成することで、行った機能強化を検証できるだけでなく、時間の経過に伴うパフォーマンスの低下を確認することもできます。
まず、Log Analytics を使用して診断ログを有効にします。
- Azure portal で、[診断設定] を選択します。
- [+ 診断設定の追加] を選択します。

- 診断設定に名前を付けます。
- [allLogs] と [AllMetrics] を選択します。
- [Log Analytics ワークスペースへの送信] を選択します。
- Log Analytics ワークスペースを選択または作成します。
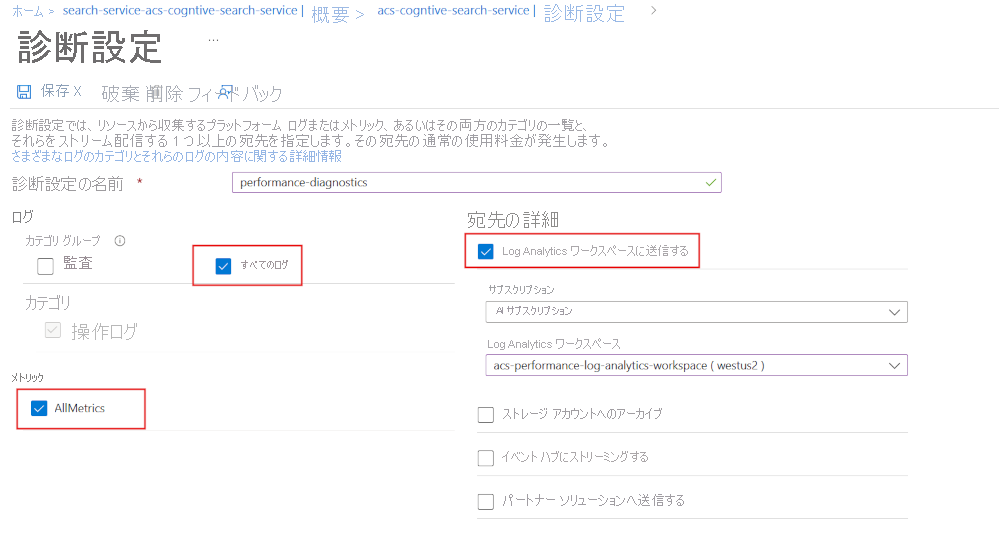
この診断情報は、検索サービス レベルで取得することが重要です。 エンド ユーザーまたはアプリにパフォーマンスの問題が表示される場所はいくつかあるためです。

パフォーマンスの問題が発生している場合、検索サービスのパフォーマンスが良好であることを証明できれば、考えられる要因からそれを排除できます。
検索サービスが調整されているかどうかを確認する
Azure AI 検索の検索とインデックスは調整できます。 ユーザーまたはアプリの検索が調整されている場合、Log Analytics で 503 HTTP 応答が取得されます。 インデックスが調整されている場合は、207 HTTP 応答として表示されます。
検索サービス ログに対して実行できるこのクエリは、検索サービスが調整されているかどうかを示します。

Azure portal の [監視] で [ログ] を選択します。 [新しいクエリ 1] タブでは、次のクエリを使います。
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
検索サービスの HTTP 応答の横棒グラフを表示するコマンドを実行します。 上記の場合、503 応答がいくつかあることがわかります。
個々のクエリのパフォーマンスを確認する
個々のクエリのパフォーマンスをテストする最良の方法は、Postman などのクライアント ツールを使用することです。 クエリへの応答にヘッダーが表示される任意のツールを使用できます。 Azure AI 検索から、サービスでクエリを完了するのにかかった時間を表す "elapsed-time" の値が常に返されます。

送信後にクライアントから応答を受信するまでにかかる時間を知るには、ラウンド トリップの合計から経過時間を差し引きます。 上記では、125 ミリ秒から 21 ミリ秒までであり、104 ミリ秒となります。
インデックスのサイズとスキーマを最適化する
検索クエリのパフォーマンスがどのようになるかは、インデックスのサイズと複雑さに直接関連しています。 インデックスがより小さく、より最適化されているほど、Azure AI 検索でのクエリへの応答が速くなる可能性があります。 個々のクエリでパフォーマンスの問題が見つかった場合に役立つヒントをいくつか次に示します。
注意していないと、インデックスは時間の経過とともに増加する可能性があります。 インデックス内のすべてのドキュメントがまだ関連性があり、検索可能である必要があることを確認する必要があります。
ドキュメントを削除できない場合は、スキーマの複雑さを軽減できますか? 同じフィールドを検索可能にしておく必要がありますか? 最初のインデックスでのすべてのスキルセットがまだ必要ですか?

各フィールドで有効にしたすべての属性を確認することを検討してください。 たとえば、フィルター、ファセット、並べ替えのサポートを追加すると、インデックスをサポートするために必要なストレージが 4 倍になります。
注意
フィールドは、属性が多すぎると機能が制限されます。 たとえば、ファセットとフィルターを使用できる検索可能なフィールドには、16 KB のみを格納できます。 一方、検索可能なフィールドは最大 16 MB のテキストを保持できます。
インデックスが最適化されているにもかかわらず、パフォーマンスが必要な水準にない場合は、検索サービスのスケールアップまたはスケールアウトを選択できます。
クエリのパフォーマンスを改善する
検索サービスのしくみがわかっていれば、クエリを調整してパフォーマンスを大幅に改善できます。 より効率的なクエリを記述するには、次のチェックリストを使用します。
- 検索する必要があるフィールドのみを、searchFields パラメーターを使用して指定します。 フィールドが増えるほど、追加の処理が必要になります。
- 検索結果ページに表示する必要がある最も少ない数のフィールドが返されるようにします。 返されるデータが多いほど、時間が長くかかります。
- プレフィックス検索や正規表現などの部分的な検索語句を避けるようにしてください。 これらの種類の検索は、計算コストが高くなります。
- 高スキップ値を使用しないでください。 これにより、検索エンジンは大量のデータを取得してランク付けする必要があります。
- ファセットとフィルターを処理可能なフィールドの使用は、カーディナリティの低いデータに制限します。
- フィルター条件では、個々の値ではなく検索関数を使用します。 たとえば、
$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121の代わりにsearch.in(userid, '123,143,563,121',',')を使用できます。
上記のすべてを適用しても個々のクエリでパフォーマンスの低いものがある場合は、インデックスをスケールアウトできます。 検索ソリューションの作成に使用したサービス レベルに応じて、最大 12 個のパーティションを追加できます。 パーティションは、インデックスが存在する物理ストレージです。 既定では、すべての新しい検索インデックスが 1 つのパーティションとともに作成されます。 さらにパーティションを追加すると、インデックスがそれらの全体に格納されます。 たとえば、インデックスが 200 GB で、パーティションが 4 つある場合、各パーティションに 50 GB のインデックスが含まれます。
追加のパーティションを加えると、各パーティションで検索エンジンを並列に実行できるため、パフォーマンス向上に役立ちます。 多数のドキュメントを返すクエリの場合、多数のドキュメントでのカウントを提供するファセットを使用したクエリの場合に、最も大きい改善が見られます。 これは、ドキュメントの関連性をスコア付けするための計算コストにかかわる要素です。
検索ニーズに最適なサービス レベルを使用する
さらにパーティションを追加することで、サービス レベルをスケールアウトできることを確認しました。 負荷が増加したためにスケーリングする必要がある場合は、レプリカを使用してスケールアウトできます。 より上位のレベルを使用して検索サービスを "スケールアップ" することもできます。

上記の 2 つの検索インデックスのサイズは 200 GB です。 S1 レベルでは 8 つのパーティションが使用されており、S2 レベルでは 2 つのみです。 これらはどちらも 2 つのレプリカを持ち、どちらもほぼ同じコストになります。 検索ソリューションに最適なレベルを選択するには、必要となるストレージのおおよその合計サイズを把握する必要があります。 現在サポートされている最大のインデックスは、合計 24 TB を提供する L2 レベルの 12 個のパーティションです。
| レベル | 型 | 記憶域 | レプリカ | メジャー グループ |
|---|---|---|---|---|
| F | Free | 50 MB | 1 | 1 |
| B | Basic | 2 GB | 3 | 1 |
| S1 | Standard | 25 GB/パーティション | 12 | 12 |
| S2 | Standard | 100 GB/パーティション | 12 | 12 |
| S3 | Standard | 200 GB/パーティション | 12 | 12 |
| S3HD | 高密度 | 200 GB/パーティション | 12 | 3 |
| L1 | ストレージ最適化 | 1 TB/パーティション | 12 | 12 |
| L2 | ストレージ最適化 | 2 TB/パーティション | 12 | 12 |
前述の例で、上記の 2 つのレベルのうち、どちらが最適だと思いますか? スケールアウトでは並列処理によりパフォーマンス上の利点が得られることを確認しました。 ただし、上位レベルには、Premium Storage、より強力なコンピューティング リソース、追加のメモリも付属しています。 2 つ目のオプションを選択すると、より強力なインフラストラクチャが提供され、今後のインデックスの増加に対応できます。 残念ながら、どのレベルのパフォーマンスが最も優れているかは、インデックスのサイズと複雑さ、その検索のために作成するクエリによって異なります。 そのため、どちらも最良の可能性があります。
検索ソリューションを使用するうえで、今後の拡張を計画することは、検索ユニットを検討する必要があることを意味します。 検索ユニット (SU) は、レプリカとパーティションの積です。 つまり、上記の S1 レベルでは 16 SU が使用されており、S2 レベルでは 4 SU のみです。 上位レベルでは SU あたりの課金額が多いため、コストは似たものになります。
負荷が増加したために検索ソリューションをスケーリングする必要がある場合について考えてみます。 両方のレベルにもう 1 つレプリカを追加すると、S1 レベルは 24 SU に増加しますが、S2 レベルは 6 SU に増加するだけです。