はじめに
機械学習は、データドリブンの意思決定と自動化を可能にすることで、ビジネスの運用方法を変革しています。 ただし、機械学習モデルの開発は、ほんの始まりにすぎません。 本当の課題は、運用環境にこれらのモデルをデプロイし、リアルタイムで分析情報や予測を提供することです。
Azure Databricks は、データ エンジニアリングとデータ サイエンスを組み合わせた汎用性の高いプラットフォームです。 これにより、機械学習モデルを大規模に構築、トレーニング、デプロイするプロセスを簡略化する統合分析プラットフォームが提供されます。 データ サイエンティストとエンジニアは、コラボレーション環境を使用して、効果的な機械学習ソリューションを作成できます。
Azure Databricks の機能を存分に活用するには、機械学習ワークフロー全体を理解することが不可欠です。
機械学習ワークフローを理解する
機械学習ワークフローは、いくつかの重要なタスクを含む包括的なプロセスであり、それぞれが効果的な機械学習モデルの開発とデプロイにおいて重要な役割を果たします。 機械学習ワークフローには、次のタスクが含まれます。
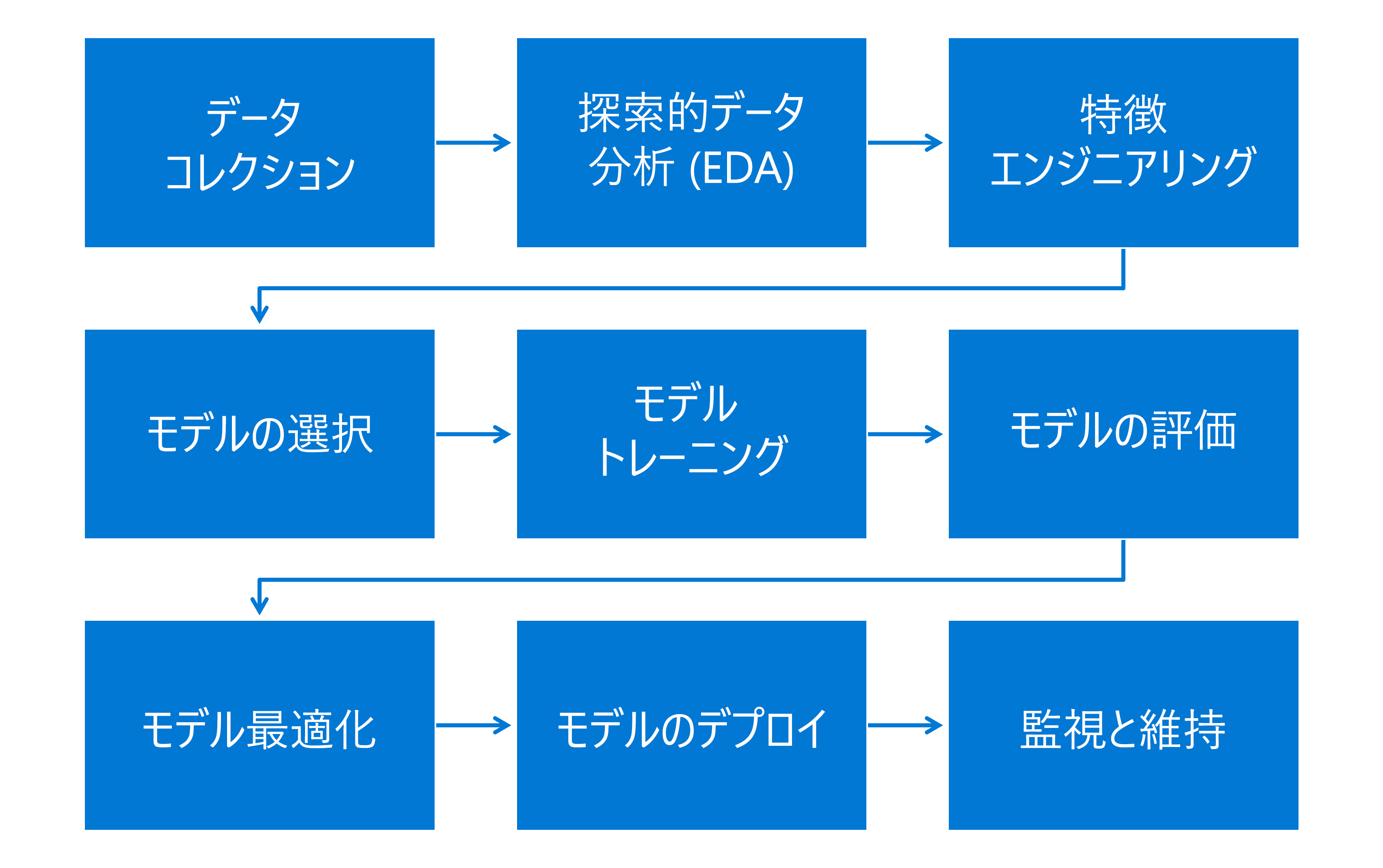
- データ収集:データは、機械学習させる内容に応じて、数値やイメージからテキストに至る、あらゆるデータが含まれます。
- EDA (探索的データ分析):データを分析して主な特性を要約し、パターンを明らかにします。
- 特徴量エンジニアリング:モデルのパフォーマンスを向上するために、新しい特徴を作成したり、既存の特徴を変更したりします。
- モデルの選択:モデルは、データ内のパターンを見つけることによって予測を行う数式またはアルゴリズムです。
- モデル トレーニング:機械学習アルゴリズムは、データを使用して、入力 (特徴) を出力 (ターゲット) につなぐパターンを学習します。 モデルはパラメーターを調整して、予測と、トレーニング データ内の実際の結果の差を最小限に抑えます。
- モデルの評価:モデルのパフォーマンスは、テスト セットと呼ばれる新しいデータ セットを使用して評価されます。 正確性、精度、再現率、ROC 曲線の領域などのメトリックは、さまざまな種類のモデルを評価するために使用されます。
- モデル最適化:モデルのパラメーターとアルゴリズムは、正確性と効率を向上するために微調整されます。
- モデルのデプロイ:モデルは、バッチまたはリアルタイムで予測を行う運用環境にデプロイされます。
- 監視と保守:継続的な監視は、新しいデータが生まれたり、基になるデータ分散で潜在的な変化が発生してもモデルの有効性を保つために重要です。
機械学習ワークフローの各フェーズをナビゲートし、モデルを運用環境に取り込むには、適切なツールとテクノロジを使用することが重要です。 Azure Databricks は、他の Azure サービスと共に、このプロセスのすべてのステップをサポートする一連のツールを提供します。 データ収集や特徴エンジニアリングからモデルのデプロイや監視に至るまで、Azure には、スムーズな統合と効率的なワークフローを可能にするツールが用意されています。
機械学習ワークフローを運用環境に取り込むのに役立つツールを見てみましょう。