Azure Machine Learning を使用してカスタム AI モデルを作成する
高度な AI モデルを利用できると、組織はデータ サイエンス プロジェクトに必要なリソースの量を大幅に削減できます。 組織が Azure Machine Learning を使用して機械学習の課題と運用にどのように取り組むことができるかを見てみましょう。
機械学習の課題と機械学習の運用の必要性
AI ソリューションを維持するには、通常、機械学習ライフサイクル管理して、データ、コード、モデル環境、および機械学習モデル自体を文書化して管理する必要があります。 モデルを開発、パッケージ化、配置して、モデルのパフォーマンスを監視し、場合によっては再トレーニングするためのプロセスを、確立する必要があります。 さらに、ほとんどの組織は、運用環境で複数のモデルを同時に管理しており、それが管理作業をより複雑にしています。
このように複雑な作業に効果的に対処するには、いくつかのベスト プラクティスが必要です。 そこでは、チーム間のコラボレーション、プロセスの自動化と標準化、モデルを簡単に監査、説明、再利用できるようにすることに、重点が置かれています。 これを実現するため、データ サイエンス チームは機械学習運用アプローチに依存します。 この手法は、アプリケーション開発サイクルの運用の管理に関する業界標準である DevOps (開発と運用) に着想を得ています。これは、開発者とデータ科学者の苦労が似ているためです。
Azure Machine Learning
データ科学者は、Microsoft のプラットフォームである Azure Machine Learning から機械学習 DevOps を管理および実行して、機械学習のライフサイクル管理と運用をより簡単に実践できます。 このようなツールは、自動化をによって多くのプロセスを最適化できる、共有された監査可能で安全な環境でチームが共同作業を行うのに役立ちます。
機械学習ライフサイクル管理
Azure Machine Learning では、事前トレーニング済みモデルとカスタム モデルのエンドツーエンドの機械学習ライフサイクル管理がサポートされています。 一般的なライフサイクルには、データ準備、モデルのトレーニング、モデルのパッケージ化、モデルの検証、モデルのデプロイ、モデルの監視、再トレーニングの手順が含まれます。
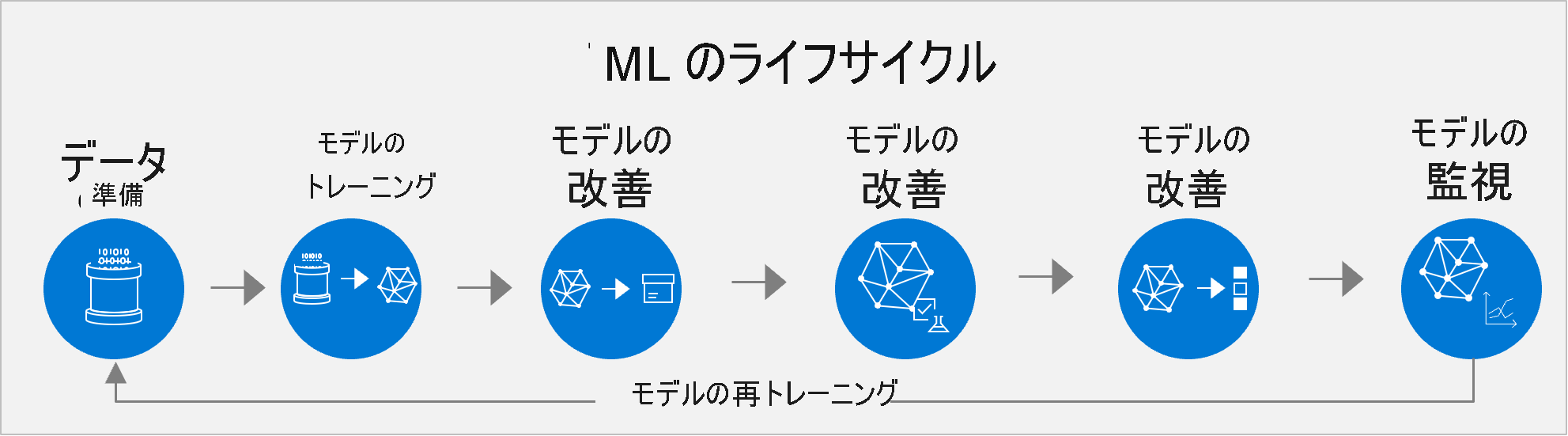
従来のアプローチでは、データ サイエンス プロジェクトの通常ステップがすべてカバーされています。
- データセットを準備する。 AI はデータから始まります。 データ科学者は、最初に、モデルのトレーニングに使うデータを準備する必要があります。 データ準備は、多くの場合、ライフサイクルの中で最も時間のかかる作業です。 このタスクでは、独自のデータセットを検索または構築してクリーニングすることで、マシンで簡単に読み取ることができるようにします。 データが代表的なサンプルであること、変数が目標に対して適切であることなどを確認する必要があります。
- トレーニングとテストを行う。 次に、データ科学者は、データにアルゴリズムを適用して、機械学習モデルをトレーニングします。 その後、新しいデータでモデルのテストを行い、その予測の精度を確認します。
- パッケージ化する。 モデルをアプリに直接取り込むことはできません。 コンテナー化することで、その上で構築されるすべてのツールやフレームワークで実行できるようにする必要があります。
- 検証する。 この時点で、チームは、モデルのパフォーマンスをビジネス目標と比較して評価します。 テストで十分なメトリックが返される場合でも、実際のビジネス シナリオで使うと、モデルが期待どおりに動作しない可能性があります。
- ステップ 1 から 4 を繰り返す。 モデルが条件を十分に満たすようになるまで何百時間ものトレーニングが必要になる可能性があります。 開発チームは、トレーニング データを調整したり、アルゴリズムのハイパーパラメーターを調整したり、まったく異なるアルゴリズムを試したりすることで、数多くのバージョンのモデルをトレーニングできます。 調整するたびにモデルが改善されるのが理想的です。 最終的に、ビジネスのユース ケースに最も適したモデルのバージョンを決定するのは、開発チームの役割です。
- デプロイ。 最後に、モデルをデプロイします。 デプロイのオプションには、クラウド内、オンプレミス サーバー上、カメラ、IoT ゲートウェイ、機械などのデバイス上があります。
- 監視して再トレーニングする。 モデルは、最初は問題なく機能していても、継続的に監視して、関連性と精度を維持するために再トレーニングを行う必要があります。
Note
事前トレーニング済みモデルを統合して、ビジネス ニーズに合わせて調整するには、カスタム モデルを統合するのとは異なるワークフローが必要です。 Azure Machine Learning を使用して、事前トレーニング済みモデルを使用するか、独自のモデルを構築することもできます。 複数のアプローチの中でどれを選択するのかは、シナリオによって異なります。 事前トレーニング済みモデルを使うと、必要なリソースが減り、結果をより短時間で提供できるという利点があります。 ただし、事前構築済みモデルは幅広いユース ケースを解決するようにトレーニングされているため、非常に限定的なニーズを満たすには苦労することがあります。 そのような場合は、完全なカスタム モデルの方が適している可能性があります。 多くの場合、両方のアプローチを柔軟に組み合わせて使うことが推奨され、スケーリングに役立ちます。 AI チームは、最も簡単なユース ケースに事前トレーニング済みモデルを使ってリソースを節約し、その一方で、最も困難なシナリオ向けのカスタム AI モデルの構築にこれらのリソースをつぎ込むことができます。 さらに、事前構築済みモデルを繰り返し再トレーニングすることで、それを改善できます。
機械学習の操作
機械学習の運用 (MLOps) は、DevOps (開発と運用) の手法を適用して、機械学習のライフサイクルをより効率的に管理します。 また、AI チームのすべての関係者間でよりアジャイルで生産的なコラボレーションが可能になります。 このようなコラボレーションには、データ サイエンティスト、AI エンジニア、アプリ開発者、その他の IT チームが関与します。
MLOps のプロセスとツールは、これらのチームの共同作業を支援し、共有の監査可能なドキュメントを通じて可視性を提供します。 MLOps テクノロジを使用すると、ユーザーは、データ、コード、モデル、その他のツールなど、すべてのリソースの変更を保存して追跡できます。 さらに、自動化、繰り返し可能なワークフロー、再利用可能な資産により、ライフサイクルの効率を高め、ライフサイクルを加速化できます。 このようなすべてのプラクティスにより、AI プロジェクトはよりアジャイルで効率的になります。
Azure Machine Learning では、次の MLOps プラクティスがサポートされています。
モデルの再現性: チームの別のメンバーが同じデータセットでモデルを実行し、同様の結果を得ることができることを意味します。 再現性は、運用環境のモデルの結果を信頼性の高いものにするうえで重要です。 Azure Machine Learning では、環境、コード、データセット、モデル、機械学習パイプラインなどの資産を一元的に管理して、モデルの再現性がサポートされています。
モデルの検証: モデルをデプロイする前に、そのパフォーマンス メトリックを検証することが重要です。 "ベスト" モデルを示すために使用されるメトリックがいくつかあります。 パフォーマンス メトリックをビジネス ユース ケースに関連した方法で検証することが重要です。 Azure Machine Learning では、損失関数や混同行列など、モデル メトリックを評価するための多くのツールでモデルの検証がサポートされています。
モデルのデプロイ: モデルをデプロイするときは、データ科学者と AI エンジニアが連携して最適なデプロイ オプションを決定することが重要です。 これらのオプションには、クラウド、オンプレミス、エッジ デバイス (カメラ、ドローン、機械) が含まれます。
モデルの再トレーニング: パフォーマンス問題を修正し、より新しいトレーニング データを活用するために、モデルを監視し、定期的に再トレーニングする必要があります。 Azure Machine Learning では、モデルの精度を継続的に改良し、確保するための体系的で反復的なプロセスがサポートされています。
ヒント

顧客ストーリー:ある医療組織が Azure Machine Learning を使用して、手術中の合併症の可能性を予測するカスタム機械学習モデルをトレーニングします。 モデルは、年齢、民族性、喫煙履歴、肥満度指数、血小板数などの要因を含む膨大な量のデータに基づいてトレーニングされます。 これらのモデルを使用すると、医療専門家はリスクをより適切に評価し、個々の患者に対する手術やライフスタイルの変化に関する推奨事項のオプションを決定できます。 Azure Machine Learning の責任ある AI ダッシュボードは、予測要因を説明し、人口統計学的要因からの偏りを軽減するのに役立ちます。 最終的には、予測モデリング ソリューションは、リスクと不確実性を軽減し、手術結果を改善するのに役立ちます。 完全な顧客ストーリー https://aka.ms/azure-ml-customer-story をご覧ください。
ヒント
組織でデータ サイエンスと機械学習の専門知識を活用してカスタム モデルを構築する方法を少し考えてみましょう。

次に、知識チェックを使ってまとめ上げましょう。