機械学習のためのDevOps
DevOps と MLOps
DevOps は、DevOps とは何ですか?.
機械学習モデルを使用する際の使用方法を理解するために、いくつかの重要な DevOps の原則をさらに調べてみましょう。
DevOps は、堅牢で再現可能なアプリケーションを開発者に提供するツールとプラクティスの組み合わせです。 DevOps の原則を使用する目的は、エンド ユーザーに価値を迅速に提供することです。
機械学習モデルをデータ変換パイプラインまたはリアルタイム アプリケーションに統合することで、より簡単に価値を提供したい場合は、DevOps の原則を実装することでメリットを得られます。 DevOps について学習すると、作業を整理して自動化するのに役立ちます。
エンドユーザーに価値を提供するために、堅牢で再現可能なモデルの作成、デプロイ、監視を行うことは、としての機械学習の運用 (MLOps) の目標です。
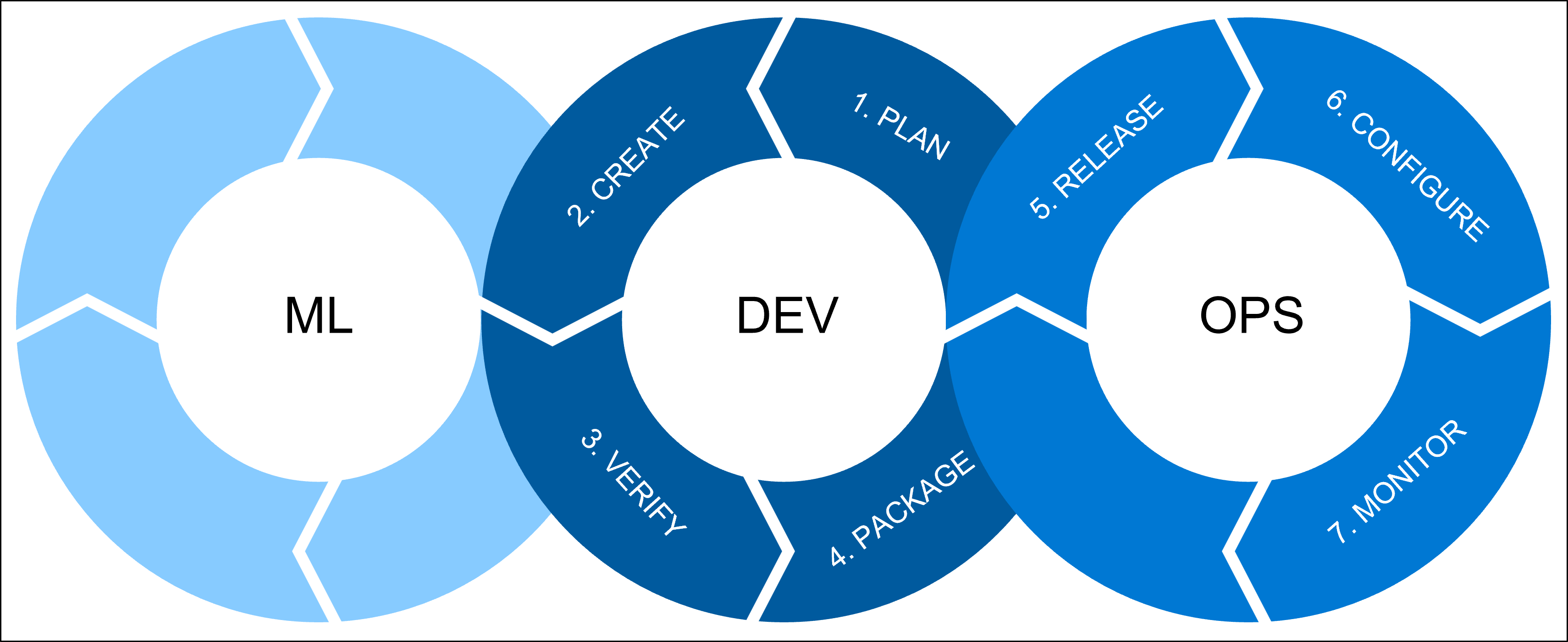 の MLOps の概要
の MLOps の概要
機械学習の操作 (MLOps) について話すたびに、3 つのプロセスを組み合わせる必要があります。
ML には、データ サイエンティストが担当するすべての機械学習ワークロードが含まれます。 データ サイエンティストは次のことを行います。
- 探索的データ分析 (EDA)
- 特徴エンジニアリング
- モデルのトレーニングとチューニング
DEV は、次を含むソフトウェア開発を指します。
- 計画: モデルの要件とパフォーマンス メトリックを定義します。
- の作成: モデルのトレーニングスクリプトとスコアリング スクリプトを作成します。
- を確認する: コードとモデルの品質を確認します。
- パッケージ: ソリューションをステージングしてデプロイの準備をします。
OPS は操作を指し、次のものが含まれます。
- リリース: モデルを運用環境にデプロイします。
- の構成: Infrastructure as Code (IaC) を使用してインフラストラクチャ構成を標準化します。
- 監視: メトリックを追跡し、モデルとインフラストラクチャが期待どおりに動作していることを確認します。
MLOps に不可欠な DevOps の原則をいくつか見てみましょう。
DevOps の原則
DevOps の主要な原則の 1 つは、自動化 です。 タスクを自動化することで、新しいモデルをより迅速に運用環境にデプロイすることを目指しています。 自動化を通じて、環境間で信頼性が高く一貫性のある再現可能なモデルも作成します。
特に、時間の経過と同時にモデルを定期的に改善する場合、自動化を使用すると、必要なすべてのアクティビティを迅速に実行して、運用環境のモデルが常に最高のパフォーマンスを発揮するモデルであることを確認できます。
自動化を実現するための重要な概念は、継続的インテグレーション と 継続的デリバリーと呼ばれる CI/CDです。
継続的インテグレーション
継続的インテグレーションは、作成 および 検証 アクティビティをカバーします。 目標は、コードを作成し、自動テストによってコードとモデルの両方の品質を検証することです。
MLOps では、継続的インテグレーションには次のものが含まれる場合があります。
- Jupyter Notebook の探索的コードを Python または R スクリプトにリファクタリングする。
- Python や R スクリプトでプログラムやスタイルのエラーを検出するためのリンティング。 たとえば、スクリプト内の行に含まれる文字数が 80 文字未満かどうかを確認します。
- スクリプトの内容のパフォーマンスを確認するための単体テスト。 たとえば、モデルがテスト データセットで正確な予測を生成するかどうかを確認します。
ヒント
機械学習の実験 運用環境の Python コードに変換する方法について説明
リンティングと単体テストを実行するには、Azure DevOps で Azure Pipelines を したり、GitHub Actions をなどの自動化ツールを使用できます。
継続的デリバリー
モデルのトレーニングに使用される Python または R スクリプトのコード品質を確認したら、モデルを運用環境に移行します。 継続的デリバリー には、モデルを運用環境にデプロイするために必要な手順が含まれます。可能な限り自動化することをお勧めします。
モデルを運用環境にデプロイするには、まずモデルをパッケージ化し、実稼働前環境にデプロイします。 実稼働前環境でモデルをステージングすることで、すべてが期待どおりに動作するかどうかを確認できます。
ステージング フェーズへのモデルのデプロイが成功し、エラーが発生しない場合は、モデルを 運用環境にデプロイすることを承認できます。
Python または R スクリプトで共同作業してモデルをトレーニングし、各環境にモデルをデプロイするために必要なコードを作成するには、ソース管理 使用します。
ソース管理
ソース管理 (またはバージョン管理 ) は、Git ベースのリポジトリを使用して最も一般的に実現されます。 リポジトリとは、ソフトウェア プロジェクトに関連するすべてのファイルを格納できる場所を指します。
機械学習プロジェクトでは、持っているプロジェクトごとにリポジトリが作成される可能性があります。 リポジトリには、Jupyter Notebook、トレーニング スクリプト、スコアリング スクリプト、パイプライン定義などが含まれます。
手記
好ましくは、リポジトリにトレーニング データを格納しないことが望ましいです。 代わりに、トレーニング データはデータベースまたはデータ レイクに格納され、Azure Machine Learning は データストアを使用してデータ ソースから直接データを取得します。
Git ベースのリポジトリは、Azure DevOps Azure Repos、または GitHub リポジトリを使用して使用できます。
リポジトリ内のすべての関連するコードをホストすることで、コードで簡単に共同作業を行い、チーム メンバーが行った変更を追跡できます。 各メンバーは、独自のバージョンのコードで作業できます。 過去のすべての変更を確認でき、変更がメイン リポジトリにコミットされる前に確認できます。
プロジェクトのどの部分で作業するかを決定するには、アジャイル計画 使用することをお勧めします。
アジャイル計画
モデルを運用環境に迅速にデプロイする必要がある場合、アジャイル計画は機械学習プロジェクトに最適です。
アジャイル計画 とは、作業をスプリントに分けます。 スプリント は、プロジェクトの目標の一部を達成する短い期間です。
目的は、コードを迅速に改善するためにスプリントを計画することです。 データとモデルの探索に使用されるコードか、運用環境にモデルをデプロイするか。
機械学習モデルのトレーニングは、終わりのないプロセスになる可能性があります。 たとえば、データ サイエンティストとして、データ ドリフトのためにモデルのパフォーマンスを向上させる必要がある場合があります。 または、新しいビジネス要件に合わせてモデルを調整する必要があります。
モデルトレーニングに時間がかかりすぎないように、アジャイル計画はプロジェクトの範囲を指定し、より短い期間の成果に同意して全員を調整するのに役立ちます。
作業を計画するには、Azure DevOps で Azure Boards を したり、GitHub の問題を などのツールを使用できます。
コードとしてのインフラストラクチャ (IaC)
DevOps の原則を機械学習プロジェクトに適用することは、堅牢な再現可能なソリューションを作成することを意味します。 つまり、実行または作成するすべての操作を繰り返して自動化できる必要があります。
モデルのトレーニングとデプロイに必要なインフラストラクチャを繰り返し自動化するために、チームは Infrastructure as Code (IaC) を使用します。 Azure でモデルをトレーニングしてデプロイする場合、IaC は、プロセスに必要なすべての Azure リソースをコードで定義し、コードがリポジトリに格納されることを意味します。
ヒント
DevOps 変換体験の に関する Microsoft Learn モジュールを調べる