Azure Data Explorer のしくみ
このユニットでは、システムの主要なコンポーネントについて確認することで、Azure Data Explorer がバックグラウンドでどのように動作するかを調べます。 次に、一般的なワークフローを探索することで、サービスと対話する方法について学習します。
- データ インジェスト
- Kusto Query Language (Kusto クエリ言語)
- データのビジュアル化
この知識は、Azure Data Explorer がご自身のデータのニーズに適しているかどうかを判断するために役立ちます。
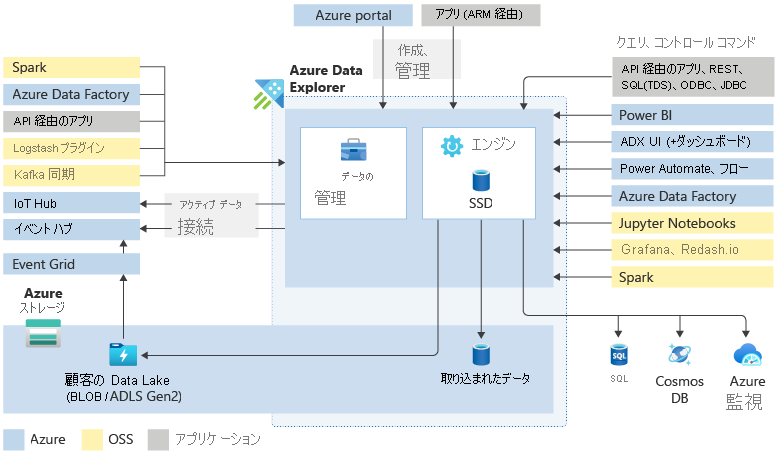
主要なコンポーネント
Azure Data Explorer クラスターにより、データのインジェスト、処理、クエリのすべての作業が実行されます。 クラスターは、ニーズに応じて自動的にスケーリングできます。 また、Azure Data Explorer を使用すると、Azure Storage にデータを格納し、このデータの一部をクラスターのコンピューティング ノードにキャッシュして、最適なクエリ パフォーマンスを実現することができます。
Azure Data Explorer クラスターに含まれているもの
各 Azure Data Explorer クラスターには最大 10,000 個のデータベース、各データベースには最大 10,000 個のテーブルを保持できます。 各テーブルのデータは エクステント と呼ばれるデータ シャードに格納されます。 すべてのデータは、インジェスト時間に基づいて自動的にインデックスが作成され、パーティション分割されます。 リレーショナル データベースとは異なり、プライマリ外部キーの制約や他の制約 (一意性など) はありません。 このような設計は、大量のさまざまなデータを格納できることを意味します。 また、この格納方法により、すばやいアクセスでクエリを実行できます。
データベースの論理構造は、他の多くのリレーショナル データベースと似ています。 Azure Data Explorer のデータベースには、次のものを含めることができます。
- テーブル: 列のセットで構成されます。 各列は、9 種類のデータ型のいずれかです。
- 外部テーブル: 基礎となるストレージが Azure Data Lake などの他の場所にあるテーブル。
一般的なワークフローの概要
一般に、Azure Data Explorer と対話するときは、次のワークフローを実行します。まず、データをシステムに取り込みます。 次に、データを分析します。 次に、分析の結果を視覚化します。 また、データ管理機能はいつでも使用することができます。 この Azure Data Explorer での作業は、クラスターとの対話を通じて行われます。 これらのリソースには、Web UI または SDK を使用してアクセスできます。
Azure Data Explorer にデータを取り込む方法
データ インジェストとは、Azure Data Explorer で 1 つ以上のソースからテーブルへデータ レコードを読み込むために使用されるプロセスのことです。 その他のデータ操作には、スキーマの照合と、データの整理、インデックス付け、エンコード、圧縮などがあります。 Data Manager は、データ インジェストをエンジンにコミットします。その結果、クエリで使用できるようになります。
ネイティブ Web UI ウィザードに加えて、さまざまなインジェスト ツールを使用できます。 たとえば、マネージド パイプライン、Event Grid、IoT Hub、Azure Data Factory などです。 Logstash プラグイン、Kafka コネクタ、Power Automate、Apache Spark コネクタなどのコネクタやプラグインを使用することもできます。 また、SDK や LightIngest を使用したプログラムによるインジェストも可能です。
バッチ処理またはストリーミングという 2 つのモードでデータを取り込むことができます。 バッチ処理インジェストは、インジェストの高スループットと高速なクエリの結果のために最適化されています。 ストリーミング インジェストを使用すると、テーブルごとに少量のデータ セットに対してほぼリアルタイムの待機時間を実現できます。
データを分析する方法
Azure Data Explorer には、データを分析するために独自の Kusto クエリ言語 (KQL) が使用されています。 これは、Microsoft で広く使用されています (Azure Monitor - Log Analytics と Application Insights、Microsoft Sentinel、Microsoft Defender XDR)。 KQL は、フローが高速で多様なビッグ データの探索のために最適化されています。 クエリからは、テーブル、ビュー、関数などのあらゆる表形式の式が参照されます。 異なるデータベースやクラスターのテーブルも含まれます。 クエリを実行するには、Web UI、さまざまなクエリ ツール、または Azure Data Explorer SDK のいずれかを使用できます。
Kusto クエリ言語のしくみ
Kusto クエリ言語は、表現力が高く、直感的で、生産性の高いクエリ言語です。 シンプルなワンライナーから複雑なデータ処理スクリプトへとスムーズに移行できます。また、構造化データ、半構造化データ、非構造化 (テキスト検索) データのクエリをサポートしています。 この言語には、さまざまなクエリ言語の演算子と関数 (集計、フィルター処理、時系列関数、地理空間関数、join、union など) が用意されています。 KQL は、クラスター間とデータベース間をまたがるクエリをサポートしており、解析 (json、XML など) の観点からも豊富な機能を備えています。 さらに、この言語は高度な分析をネイティブにサポートしています。
クエリ結果を表示する方法
Azure Data Explorer Web UI は、ビッグ データを考慮して設計されており、クエリを実行したり、ダッシュボードを構築したりすることができます。 最大 50 万件のレコードと数千列の表示をサポートしています。 非常にスケーラブルで、データからすばやく分析情報を引き出すために役立つ豊富な機能を備えています。 Azure Data Explorer のダッシュボードでは、データのさまざまな視覚的表示を使用することもできます。 Power BI や Grafana などの主要な視覚化サービスへのネイティブ コネクタを使用して、結果を表示することもできます。 また、Azure Data Explorer は、Tableau や Qlik などのツールへの ODBC および JDBC コネクタをサポートしています。
データを管理する方法
管理者は、Azure Data Explorer クラスターに対して、メンテナンスやポリシーに関するさまざまなタスクを実行したいと考えます。制御コマンドを使うとそのようなタスクを実行できます。 管理コマンドを使って、新しいクラスターまたはデータベースの作成、データ接続の確立、自動スケーリングの実行、クラスター構成の調整を行うことができます。 また、エンティティ、メタデータ オブジェクト、管理アクセス許可、セキュリティ ポリシーを制御および変更することもできます。 さらに、具体化されたビュー (継続的に更新される他のテーブルのフィルター表示)、関数 (ストアド関数とユーザー定義関数)、更新ポリシー (インジェスト後にトリガーされる関数) を変更することもできます。
制御コマンドは、Web UI、Azure portal、さまざまなクエリ ツール、または Azure Data Explorer SDK のいずれかを使用して、エンジン上で直接実行されます。