スケーラビリティについて
ビジネス環境では、成長が有益である場合があります。 ただし、成長の速度が速すぎて、それに対して適切に備えていなかった場合、成長によって問題が生じる可能性があります。 このような問題の 1 つが、トラフィックの大幅な増加に対処するように設計されていなかったアプリケーションやサービスの信頼性に対する成長の影響です。
顧客やユーザーにとって、停止は停止です。 彼らは、サイトにアクセスできない原因が何であるか知らず、バグのあるコードが原因であるか、完璧なコードで書かれたサイトを使おうとしている人が多すぎることが原因であるかに興味はありません。
スケーラビリティは、需要の増加やニーズの変化に適応するための機能です。 アプリケーションやサービスでは、増加に対応するために、より多量のワークロードを処理できる必要があります。 スケーラブルなアプリケーションでは、可用性やパフォーマンスに悪影響を与えずに、長期にわたって数が増大する要求を処理できます。
このユニットでは、スケーラビリティと信頼性の関係、スケーラビリティを実現するための容量計画の重要性について説明し、スケーリングに関するいくつかの基本的な概念と用語について簡単に確認します。
スケーラビリティと信頼性の関係
良いニュースは、アプリをよりスケーラブルにすれば、アプリの信頼性を高めることにもなる場合があるということです。 たとえば、システムで自動スケーリングが行われ、その後 1 つの仮想マシンでコンポーネント障害が発生した場合、自動スケーリング サービスにより、仮想マシン (VM) の最小数の要件を満たすために別のインスタンスがプロビジョニングされます。 システムの信頼性は高くなります。 別の例では、本質的にスケーラブルな Azure Storage のようなより高レベルのサービスを使用しています。 ストレージの問題がある場合、サービスは信頼できるように構築されているため、データがレプリケートされます。
次に、例えで説明します。ビルの外側でよく見られるような、当初は車いすの人に対応するように設計されたアクセシビリティの傾斜路を考えてみます。 それらは、その目的に役立ちます。 しかし、赤ちゃんをベビーカーやバギーに乗せている親や、階段の段が急すぎたり高すぎたりする小さな子供にも利用されます。 この使用方法は "二次的利益" です。
信頼性は、多くの場合、スケーラビリティの二次的な利点です。 システムをスケーラブルになるように設計すると、信頼性もおそらく向上します。
スケーラビリティと容量計画
容量計画では、現在と将来の両方の需要を満たすために必要なリソースを判断する必要があります。 この計画を立てるには、現在のリソース使用状況を分析してから、将来の成長を見積もります。
将来の容量ニーズを推定するには、以下のような要因を考慮に入れる必要があります。
- 予想されるビジネスの成長
- 周期的な変動 (季節など)
- アプリケーションの制約
- ボトルネックと制限要因の特定
ワークロードや環境の変化に応じて確実に目標を満たす、またはそれを上回る容量管理計画を作成できるように、サービス レベルの目標を設定する必要もあります。
容量計画は反復的なプロセスです。 このモジュールを進めながら、アプリケーション コンポーネントのリソース要件をマップする方法を学びます。
概念と用語
このモジュールで触れる概念と戦略を完全に理解するには、スケーリングに関連するいくつかの基本的な概念と基礎的な用語について、いくつかの前提となる知識を理解しておく必要があります。
- スケールアップ: 増加したワークロードを処理するためにコンポーネントのサイズを大きくします。 これは垂直方向のスケーリングとも呼ばれます。
- スケールアウト: コンポーネントまたはリソースをさらに追加し、分散アーキテクチャ上で負荷を分散させることです。 たとえば、一連のフロントエンドの背後に複数のバックエンドがある単純なアーキテクチャを使用するとします。 負荷が増加するにつれて、より多くのバックエンド (およびフロントエンド) サーバーを追加して負荷を処理します。 これは水平方向のスケーリングとも呼ばれます。
- 手動スケーリング: リソースの量を増やすには、人によるアクションが必要です。
- 自動スケーリング: システムは、負荷に基づいてリソースの量を自動的に調整します。 はっきり言えば、負荷の増減に基づいて、量は上下両方に調整されます。
- DIY 型のスケール: 自動スケーリングを構成する必要がある DIY 型のスケーリング。
- 固有のスケーリング: ユーザー側の関与をまったく必要とせずにバックグラウンドでこのスケーリングを処理するように構築されたスケーラブルなサービス。 ユーザーの視点からは、手動でプロビジョニングする必要なしにより多くのリソースをただ消費できるため、ほぼ無限にスケーラブルであるように見えます。
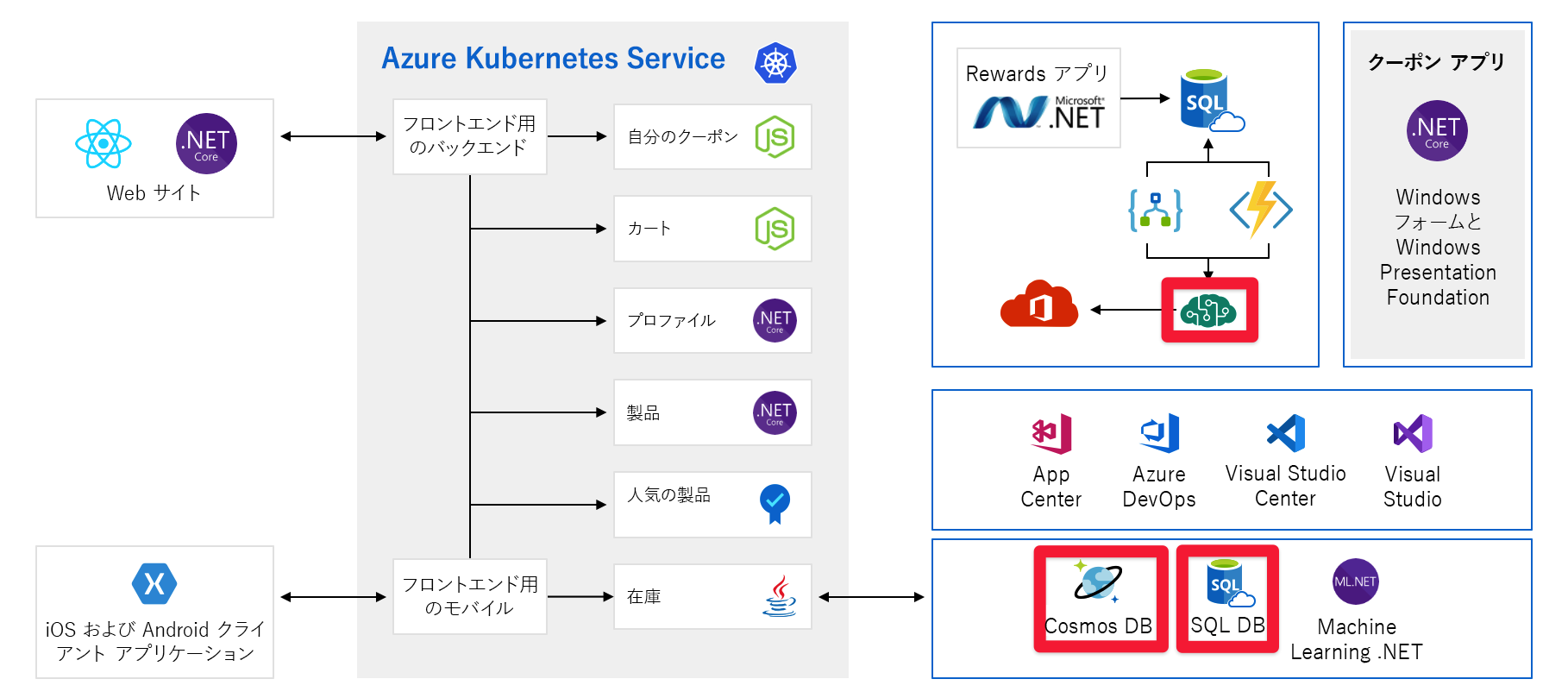
Tailwind Traders のアーキテクチャ
このモジュールでは、Tailwind Traders という架空のハードウェア会社からのアーキテクチャ例を使用します。 同社の e-コマース プラットフォームは次のようになっています。
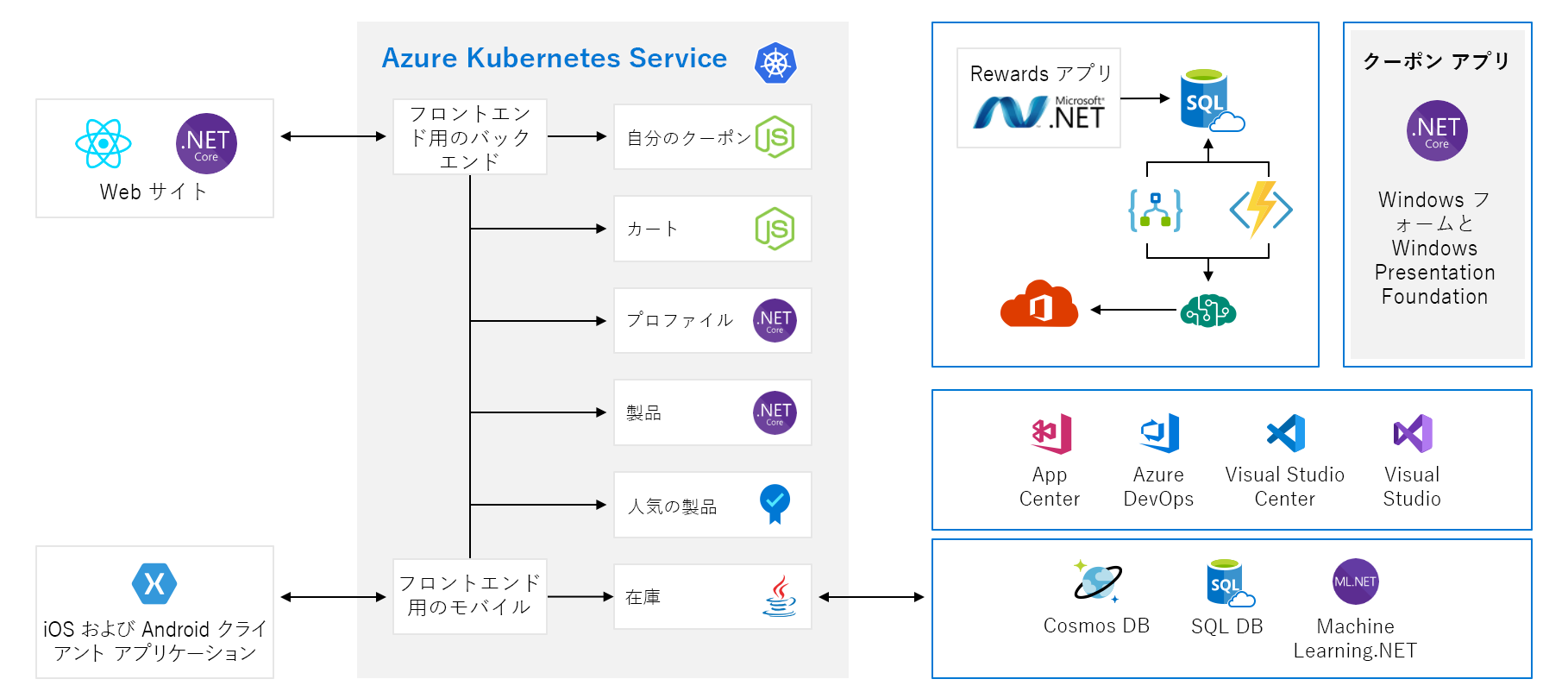
一見するとこの図はかなり複雑なので、順を追って確認しましょう。 Web サイトにはフロントエンドがあります。 tailwindtraders.com にアクセスした場合に、やりとりするところです。
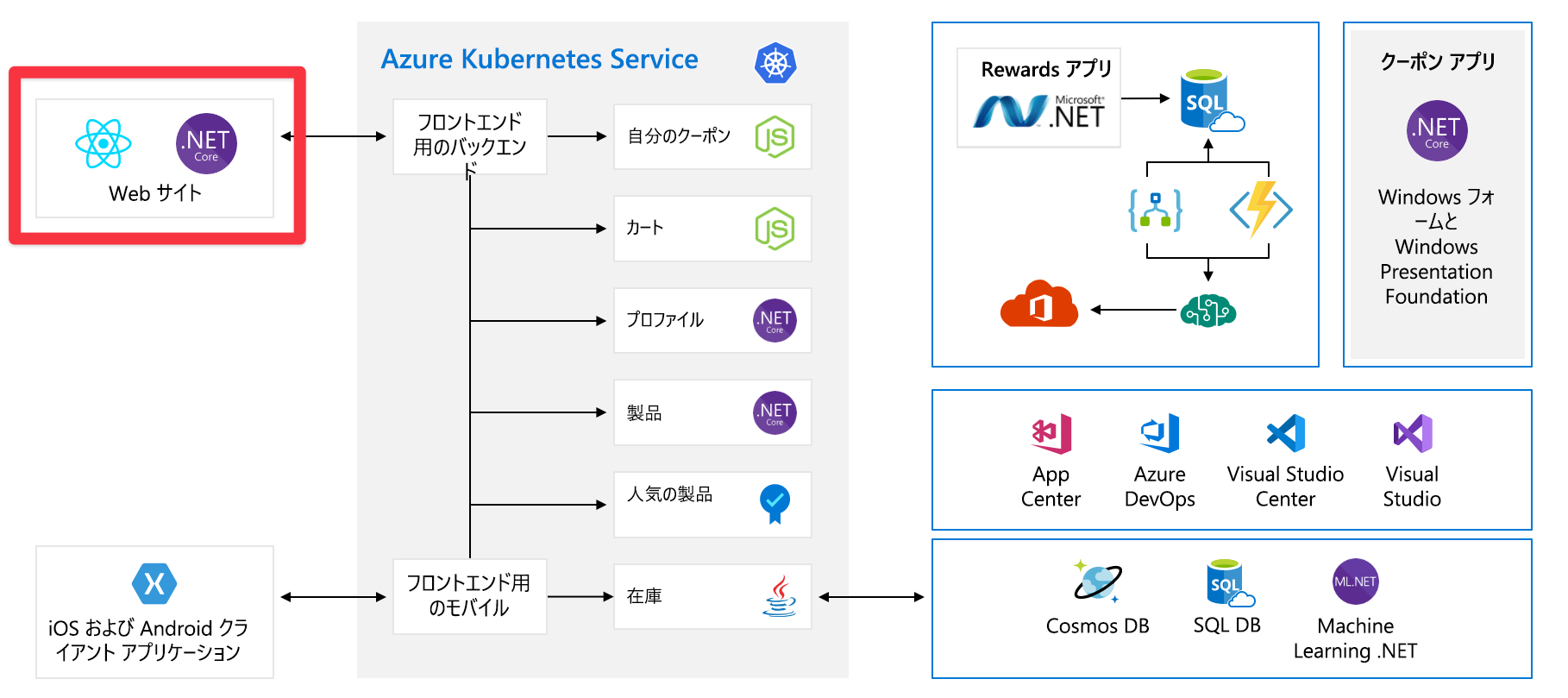
フロントエンドは、一連のバックエンド サービスに対して通信します。 これらのバックエンド サービスには、クーポン サービス、ショッピング カート サービス、在庫サービスなどの一般的な項目が含まれます。 これらはすべて、Azure Kubernetes Service で実行されています。 このアプリケーションと共に動作しているその他の部分とテクノロジがあります。 注目する必要があるのは、Kubernetes で実行されているフロントエンド サービスとバックエンド サービスだけです。
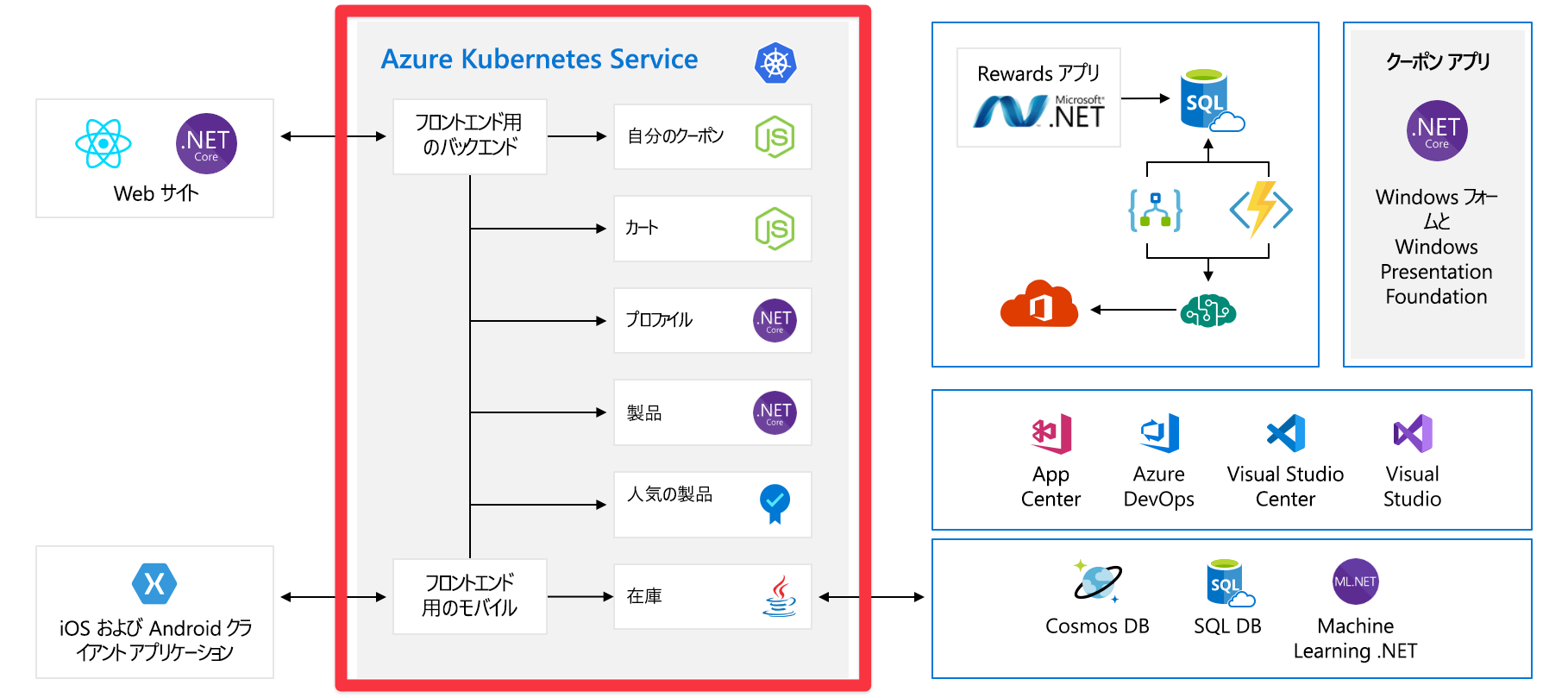
単一障害点
アーキテクチャ全体を見てきたので、少し時間を取って、単一障害点と、スケーリングについて考えるときに注意する必要がある場所を確認しましょう。
これらのサービスはすべて単一障害点であり、回復性やスケールを念頭に置いて構築されていません。 それらの 1 つが過負荷になった場合はクラッシュすることが多いですが、この時点でそれを解決する簡単な方法はありません。
このモジュールで後ほど、これらのサービスの拡張性と信頼性が高くなるように設計するその他の方法を確認します。
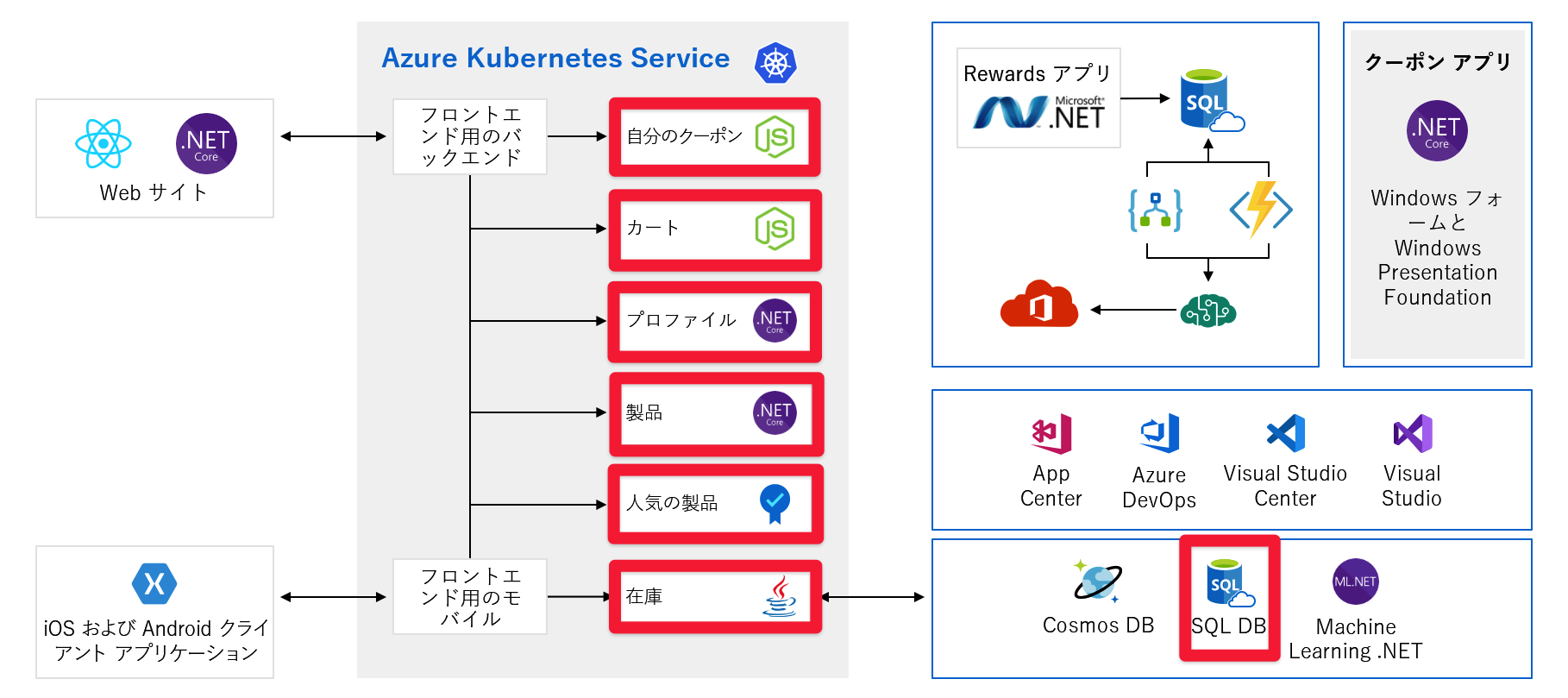
事前にプロビジョニングされた容量
問題が発生する可能性がある別の問題を見てみましょう。 容量を事前にプロビジョニングする必要があるサービスまたはコンポーネントを次に示します。
たとえば、Cosmos DB を使用する場合、そのスループットを事前にプロビジョニングします。 これらの制限を超えた場合は、お客様にエラー メッセージが返され始めます。 Azure AI サービスを使用する場合はレベルを選択しますが、そのレベルには 1 秒あたりの最大要求数があります。 これらのいずれかに達すると、クライアントは抑えられるようになります。
新製品の発売のようなトラフィックの急増があると、これらの制限に達するでしょうか。 現時点では不明です。 この問題については、このモジュールで後ほど確認します。
コスト
適切に準備した場合でも、拡張について計画する必要があります。 次のような従量課金制サービスがあります。
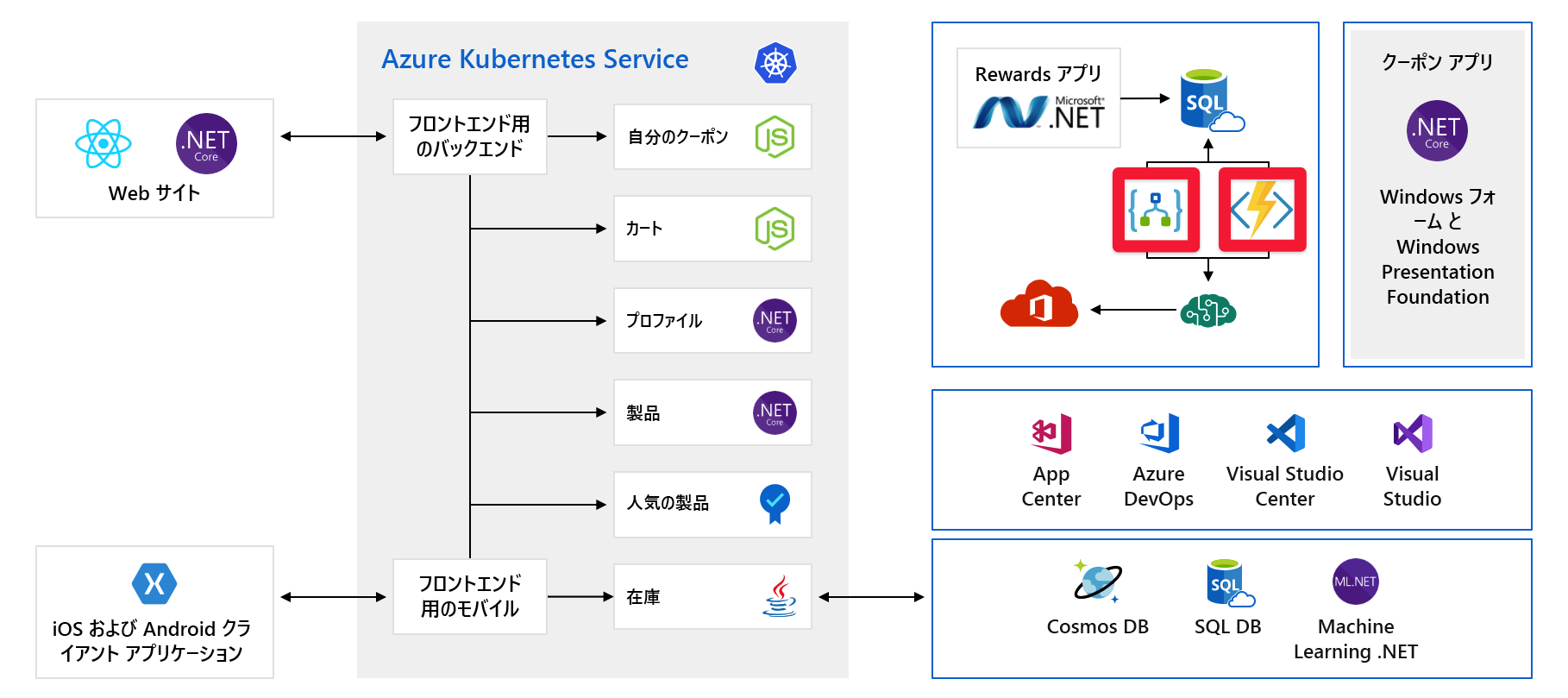
ここでは、Azure Logic Apps と Azure Functions を使用しています。これらはどちらも、サーバーレス技術の例です。 これらのサービスは自動的にスケーリングされ、要求ごとに支払いを行います。 請求額は、顧客ベースの拡大につれて増加します。 少なくとも、製品発表のような今後のイベントがクラウド支出に及ぼす可能性がある影響について注意しておく必要があります。 このモジュールでも後ほど、クラウド支出の理解と予測について説明します。