サービス レベル インジケーター (SLI) とサービス レベル目標 (SLO)
このモジュールではここまで、運用上の認識を高める方法、信頼性について理解を深める方法、信頼性の枠組みを変更する方法について説明し、作業に必要になる Azure Monitor ツールを学習しました。 次は、このモジュールの最も重要なアイデアの 1 つと、それを実装するプロセスについて説明します。
"組織内の信頼性を向上させるために、このようなすべての機能をどう使用すればよいですか?" という質問に答えましょう。
フィードバック ループに入る
問題を明らかにすることができる大きなアイデアがあります。
フィードバック ループが適切であれば、組織内の信頼性が向上します。
組織における信頼性の向上は、反復的なプロセスです。 このユニットでは、組織が信頼性を向上させるのに役立つ種類のフィードバック ループを組織内で作成して育成するために、サイト信頼性エンジニアリングの視点から効果の高い方法を紹介します。 少なくとも、客観的なデータに基づく信頼性について組織内で具体的な会話を始めるきっかけにはなります。
このモジュールの前半で、サイト信頼性エンジニアリングの定義として次のように説明しました。
サイト信頼性エンジニアリングとは、組織がシステム、サービス、製品で適切なレベルの信頼性を持続的に達成できるようにすることを目的としたエンジニアリング分野です。
ここで、"適切なレベルの信頼性" という概念が登場します。
サービス レベル インジケーター (SLI)
サービス レベル インジケーター (SLI) は、信頼性についての広範な理解に関する前述の説明に関連しています。 この図を覚えていますか?
SLI とは、どのようにしてシステムの信頼性を測定するかを明確にする試みです。 サービスが信頼性を持って動作している (期待する処理を実行している) ことを示すインジケーターは何でしょうか? これに答えるために、何を測定できるでしょうか?
例: Web サーバーの可用性と待機時間
たとえば、Web サーバーとその可用性について検討しているとします。 受信した HTTP 要求の数と、正常に応答した HTTP 要求の数に注目してみましょう。 より正確には、要求の合計数に対する成功した要求の比率を把握することによって、Web サーバーとしてどれだけ成功しているかを理解する必要があります。
要求の合計数を成功した要求の数で割ると、比率が得られます。 この比率に 100 を掛けてパーセンテージを取得できます。 概数を使用した例として、Web サーバーが 100 件の要求を受信し、そのうちの 80 件に正常に応答した場合、比率は 0.8 になります。 それを 100 で乗算すると、80% 使用可能であったと示すことができます。
もう 1 つ試してみましょう。 今度は、Web サービスの待機時間に関連する測定を明確にしましょう。 合計操作数に対する、10 ミリ秒未満で完了した操作の数の比率に注目してみましょう。 同じ数式を使用する、つまり要求の合計数 100 としきい値よりも高速に返された要求の数 80 を使用して除算すると、再び 0.8 という比率が計算されます。 100 で乗算すると、この測定による待機時間の要件に関しても 80% 成功したと言うことができます。
念のために言うと、これは Web サイトだけのことではありません。 データを処理するパイプライン サービスの場合には、カバレッジ (たとえば、処理したデータの量) を測定する必要があるということになるでしょう。 システムはまったく違っても、同じ基本的な数式になります。
SLI: 測定する場所
客観的なデータを使用した具体的な議論で SLI を役立たせるには、測定対象以外に明確にする必要があるものがもう 1 つあります。 SLI を作成する場合は、何を測定したかだけでなく、測定値が "どこで" 取得されたかにも注意する必要があります。
たとえば、前に説明した Web サーバーの可用性について何を測定するかを指定したとき、成功した HTTP 要求の数と、HTTP 要求の合計数をどこで取得したのかを特定しませんでした。 この Web サーバーの信頼性について同僚と会話しようとして、自分はサーバーの前にあるロード バランサーで収集された要求の統計情報を見ているのに、同僚がサーバー自体の統計情報を見ているとすれば、この会話はかみ合わない可能性があります。 それらの数値は根本的に異なることがあります。それは、ロード バランサーではネットワークに送信されたすべての要求が検出される可能性がありますが、ネットワークまたはロード バランサー自体に問題がある場合は、すべての要求がサーバーに到達するとは限らないためです。 2 つの異なるデータセットに基づいて結論を導くことになります。
これに対処する簡単な方法は、SLI でデータのソースを明確化することです。 Web サーバーの場合は、可用性を、「"ロード バランサーで測定された" 要求の合計数に対する成功した要求の比率」と言い表します。 待機時間については、「"クライアントで測定された" 操作の合計数に対する、10 ミリ秒未満で完了した操作の数の比率」のようになるでしょう。
ここで当然、"SLI を測定する最適な場所はどこか?" という疑問が生じます。 残念ながら、普遍的に "正しい" 答えはありません。 どちらの方法でもトレードオフがあることを理解したうえで決定する必要があります。 ここで提示できる 1 つのガイダンスとしては、信頼性についての前の議論に立ち戻り、顧客のエクスペリエンスを最も正確に反映している場所で測定を行うようにすることです。
サービス レベル目標 (SLO)
何を (どこで) 測定するかを決定することはすばらしい出発点になりますが、それでは目標の半分にしか到達しません。 たとえば、Web サーバーの可用性の SLI に必要なメトリックを取得し、実際に 80% 使用可能であることがわかったとします。
それは良いことでしょうか、または悪いことでしょうか? それは "適切なレベルの信頼性" でしょうか?
これらの疑問に答えるには、その SLI の目標、つまりサービス レベル目標 (SLO) を設定する必要があります。 この目標は、そのサービスの目標を明確に示すものです。
SLO を作成するための基本的な方式は、次の要素で構成されています。
測定する "対象": 要求の数、ストレージ検査の数、操作の数など、"何" を測定するか。
望ましい割合: たとえば、"その時間の 50% で成功"、"その時間の 99.9% で読み取り可能"、"その時間の 90% で 10 ミリ秒以内の戻り" など。
期間 目標に対して考慮する期間 (過去 10 分間、直前の四半期の間、30 日間のローリング ウィンドウ)。 SLO は、さまざまな期間のデータを比較できるように、通常はローリング ウィンドウ対 "1 か月" のようなカレンダー単位を使用して指定されます。
これらの構成要素をまとめ、重要な "どこで" の情報を含めた SLO の例は、次のようになります。
過去 30 日間という期間にロード バランサーによる報告で HTTP 要求の 90% が成功した。
同様に、待機時間を測定する基本的な SLO は次のようになります。
"過去 30 日間という期間にクライアントによる報告で HTTP 要求の 90% が 20 ms 以内に返された。"
この方法を組織に導入するときは、このように簡単で基本的な SLO から始めます。 後から必要に応じて、より複雑な SLO を作成することができます。
Azure Monitor での SLI と SLO
このユニットの最後の部分として、Log Analytics を使用して Azure Monitor で簡単な SLI と SLO を表現する方法を見てみましょう。 一貫性を保つために、Web サーバーの例に戻ります。
この前のユニットでは、Kusto クエリ言語 (KQL) を使用して Log Analytics でクエリを作成できることを学習しました。 Web サービスの可用性の SLI を表示する KQL クエリを次に示します。
requests
| where timestamp > ago(30d)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| project SLI, timestamp
| render timechart
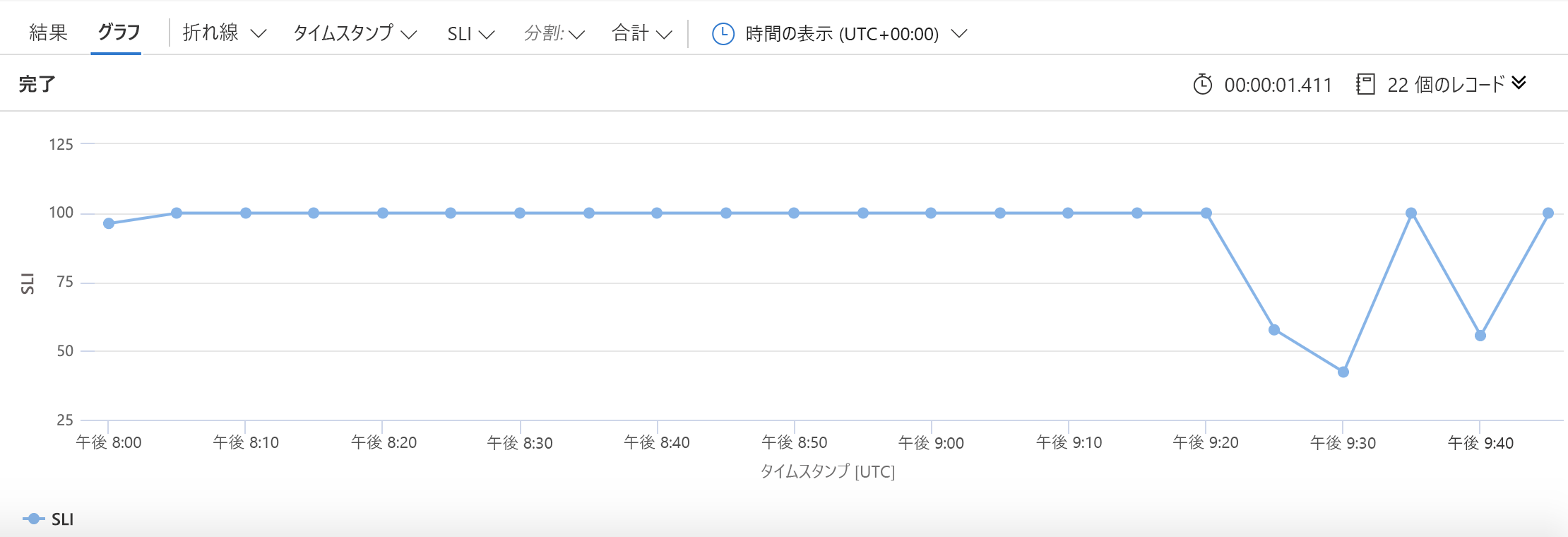
前と同様に、最初にデータのソース (requests テーブル) を指定します。 次に、使用するデータを過去 30 日分の情報のみに絞り込みます。 その後、成功した要求の数、失敗した要求の数、要求の合計数を (5 分単位で) 収集します。 SLI は、前述した簡単な算術演算を使用して作成されます。 ここでは、その SLI をタイムスタンプと共にプロットし、次のようなグラフを作成することを KQL に指示しています。
では、SLO の簡単な表現に手を加えましょう。
requests
| where timestamp > ago(5h)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| extend SLO = 80.0
| project SLI, timestamp, SLO
| render timechart
この例で前の内容から 2 行が変更されています。 その 1 つ目で SLO として使用する数値を定義し、2 つ目で SLO をグラフに含める必要があることを KQL に指示しています。 結果は次のようになります。
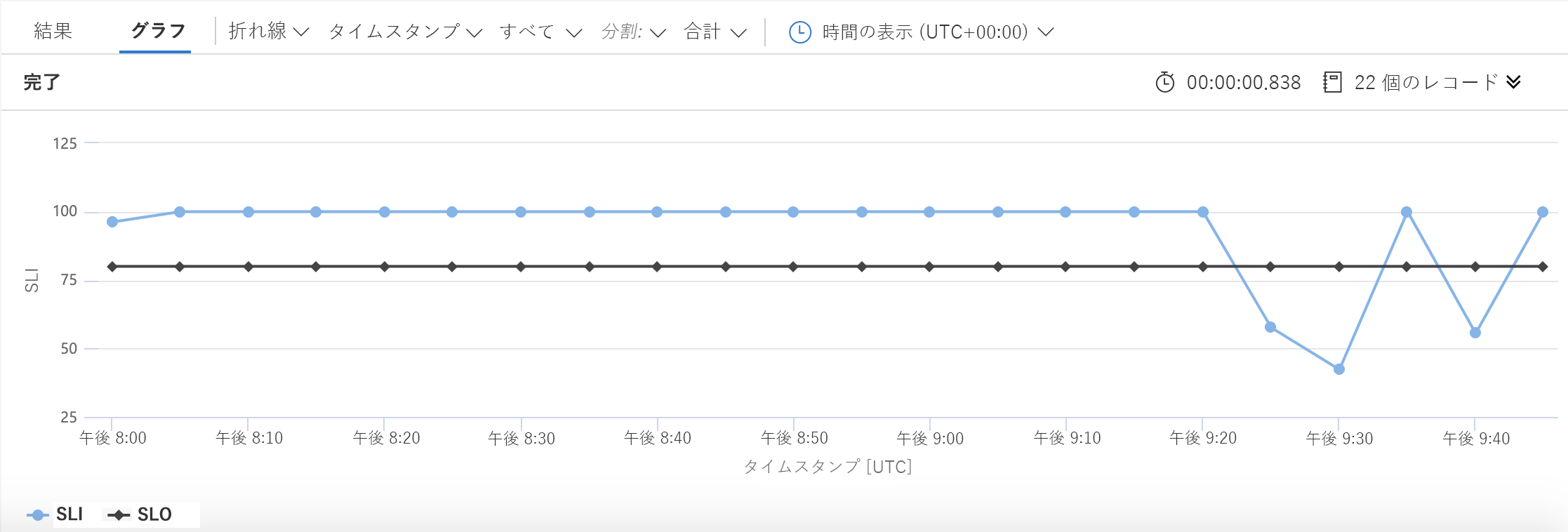
このグラフでは、いつ可用性の目標を下回ったかが簡単にわかります。
SLI と SLO を使用する
SLI と SLO について一定のチューニングを行うことが常に必要です (結局これは反復的なプロセスです)。 しかし、それが終わったら、情報をどのように処理すればよいのでしょうか?
さいわいなことに、おそらく SLI と SLO を作成するだけで組織にプラスの影響があることに気付くでしょう。 そのためには、利害関係者との協議や、物事を良い方向に向けるその他のコミュニケーションが必要です。 それらをどうすればよいかについての再協議も、同様に役に立ちます。
結局のところ、SLI と SLO は作業計画ツールです。 "サービスの新機能に取り組むべきか、または信頼性の問題に集中するべきか" といったエンジニアリング上の決定を行うのに役立ちます。前に説明したような種類のフィードバック ループで役に立ちます。
SLI と SLO の二次的な、しかし非常に一般的な用途としては、より直接的な監視および応答システムの一部として使用されます。 作業計画の側面 (最初に重視する必要がある) に加えて、多くの人がそれらを運用のシグナルとして使用します。 たとえば、サービスが長時間にわたって SLO を下回った場合に、担当者に通知することができます。 このモジュールの次のユニットで、そのような種類のアラートについて説明します。