インシデントの特性とライフサイクル
前のユニットで学んだように、"インシデント" は顧客とエンド ユーザーに影響を与えるサービス中断です。 インシデントには、ユーザーが不満を抱くパフォーマンスの低下 ("低速は停止と同様と見なされるようになった") から、一定期間サービスまたはサイトが完全に使用できなくなるシステム クラッシュの発生まで、多くの形があります。
インシデントの特性
インシデントは通常、予期することができず、考えられる最悪のタイミングで発生するように思えます (午前 2:00、または重要なプロジェクトに深く集中して取り組んでいるときなど)。 このため、インシデントは一般的に恐れられ、避けられます。インシデントの重要性が過小評価されることさえあります。 組織内のプレッシャーが非常に高く、叱責を恐れて停止を偽る、あるいは報告しないという誘惑があります。
少なくとも、インシデントは計画されていない作業を生み出します。やるべきことについて十分な知識を持ったうえで計画された業務にほとんどの時間を費やしているので、おそらくインシデントは悪いことであると考えられているでしょう。 しかし、別の見方をすることもできます。インシデントは実際には、エンド ユーザーに届けようとしている価値を提供するための投資*なのです。 インシデントの原因や影響の範囲にかかわらず、すべてのインシデントに共通するものが 1 つあります。有意義な学習機会を得られるということです。
インシデントは、"システムの脈拍" とみなす必要があります。 従来理解していたよりもシステムについて多くを知らせてくれます。その知識は良いものです。 強力な監視の基盤があり、システム内で何が起きているかについてより詳しく知るほど、必然的により多くのアラートやインシデント、対応の機会が生み出されます。 少なくとも、インシデントによって何が起きているかがわかり、したがって運用上の認識が高まります。 前の監視に関するモジュールでは、これを信頼性の取り組みに関する重要な前段階だと示しました。
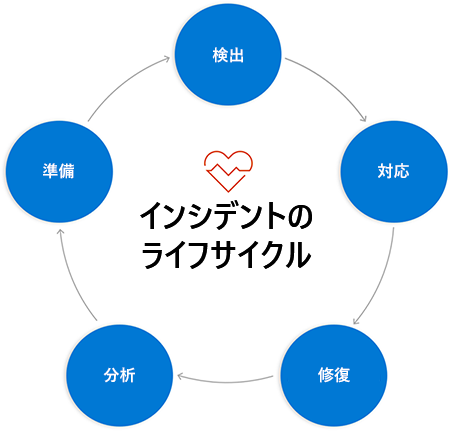
インシデントのライフサイクル
インシデント対応チームの状態を "エリート/高パフォーマー" に向上させるには、サービスの中断またはインシデントを単純な線形のタイムラインとして捉えるのではなく、サイクルという観点からアプローチする必要があります。
インシデントのライフサイクルは、個別のフェーズに分割することができます。それは論理的にサイクル内を次々とたどり、また最初に戻ります。 このサイクルを繰り返すたびに (何度も実行します)、適切に対応することができれば、システムについてより重要な洞察を得た状態で最初に戻ることができます。 計画的に作業すれば、次にインシデントが発生したときに迅速かつ効果的に対応できるように準備することもできます。
インシデントのフェーズ
インシデント対応プロセスの各フェーズは、使用するモデルによって多少異なります。 このモジュールでは、インシデントに対応するために、次の 5 つのフェーズがあります。
- 検出:このフェーズでは、このラーニング パスの前のモジュールの監視に関する知識を活用します。 監視ツールは、ログから情報を収集し、構成済みの顧客中心の目標に従って情報を分析し、人による介入が必要であることを知らせるための実用的なアラートを送信します。
- 対応:このフェーズは、チームがそのアラートを受け取った後に発生します。 このフェーズについては、このモジュールの中で詳しく説明します。この概念については後でさらに詳しく説明します。
- 修復:このフェーズでは、システムを通常の機能に復元します。 その方法は、サービスの中断の原因によって異なります。 サービスを復帰させて実行し、顧客が利用できるようにすることは、最優先事項です。 ただし、修復が完了しても、作業は終わりません。
- 分析:インシデントから継続的な価値を取得するには、それらから学習する必要があります。 このフェーズは、インシデント中に発生した内容とタイミングについての情報を収集し、適切な質問をすることで、そこから学べることを確認するプロセスです。 このフェーズに対処する「障害から学ぶ」という全体のモジュールもあります。
- 準備:分析フェーズにおいて学んだ教訓は、運用プラクティスに組み込む必要があります。 将来同様の停止を防ぐのに役立つアクション項目がある場合も、このフェーズの一部になります。
インシデント対応計画を作成する前に、インシデントの特性と価値を理解し、インシデント ライフサイクルのフェーズについて理解しておく必要があります。 次のステップでは、対応戦略が確実な基盤上に構築されていることを確認します。