小さい参照エンティティをモデリングする
このデータ モデルには、ProductCategory と ProductTag という 2 つの小さな参照データ エンティティが含まれています。 これらのエンティティは参照値に使用され、1:Many relationship によって他のエンティティに関連付けられます。
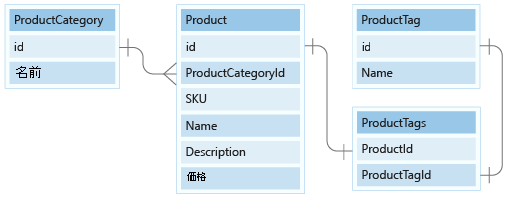
このユニットでは、このドキュメント モデルの ProductCategory エンティティと ProductTag エンティティをモデリングします。
製品カテゴリをモデリングする
最初に、カテゴリについては、id および name 列だけをプロパティとしてデータをモデリングし、ProductCategory という新しいコンテナーに格納します。
次に、パーティション キーを選択する必要があります。 このデータに対して実行する必要のある操作を見てみましょう。
新しい製品カテゴリを作成し、製品カテゴリを編集してから、すべての製品カテゴリを一覧表示します。 製品カテゴリの作成と編集は頻繁に実行される操作ではありません。 この eコマース アプリケーションでは、顧客が Web サイトにアクセスしたときに、すべての製品カテゴリが頻繁に一覧表示されます。 そのため、最後の操作が最も頻繁に実行される操作です。
この最後の操作のクエリは、SELECT * FROM c のようになります。
可能であれば読み取りが多い操作は 1 つのパーティションだけを使用して最適化したいところですが、id をパーティション キーとして選択すると、このクエリはクロスパーティションになります。 また、製品カテゴリのデータのサイズは 20 GB 近くまで増えないことがわかっており、この情報は、すべての製品カテゴリの一覧を取得するときに 1 つのパーティション クエリになるようにデータをモデリングするのに役立ちます。
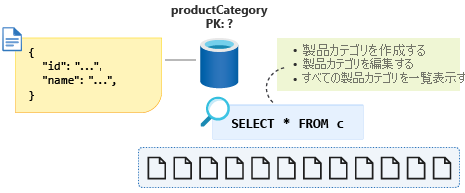
この少量のデータを 1 つのパーティションに強制的に戻すには、エンティティ識別子プロパティをスキーマに追加し、これをこのコンテナーのパーティション キーとして使用できます。 このプロパティに、コンテナー内のこの種類のすべてのドキュメントに対する定数値を割り当てることにより、単一パーティションのクエリになります。 この例では、プロパティを type という名前にして、category という定数値を指定しています。 これで、クエリは SELECT * FROM c WHERE c.type = ”category” のようになります。

製品タグをモデリングする
次は ProductTag エンティティです。 このエンティティの機能は、前のセクションで説明した ProductCategory エンティティとほぼ同じです。 ここでは同じアプローチを採用して、ID と名前のプロパティを含むようにドキュメントをモデリングし、type というエンティティ識別子プロパティ (この場合は定数値 tag) を作成します。 ProductTag という新しいコンテナーを作成し、type を新しいパーティション キーにしましょう。
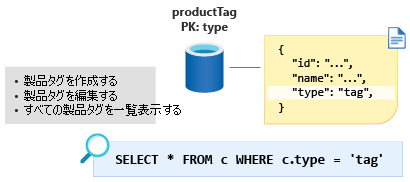
一部の人は、小さなルックアップ テーブルのモデリングにこの手法を使うことはおかしいと感じるでしょう。 ただし、このようにデータをモデリングすることで、次のモジュールでさらなる最適化を行うことが可能になります。