パーティション キーを選択する
JSON ドキュメントのデータは、Azure Cosmos DB データベースのコンテナー内に格納された後、物理パーティション間に分散され、そのときデータはパーティション キーの値に基づいて適切な物理パーティションにルーティングされることを思い出してください。
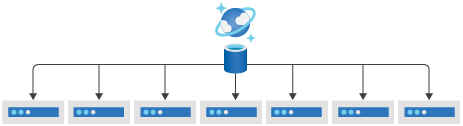
パーティション キーは必須のドキュメント プロパティであり、同じパーティション キー値を持つドキュメントは特定の物理パーティションにルーティングされて格納されます。 物理パーティションでは、固定の最大ストレージ量とスループット (RU/秒) がサポートされます。 Azure Cosmos DB により、使用可能な物理パーティションに論理パーティションが自動的に分散され、ここでもやはりパーティション キー値を使用して予測可能な方法で行われます。
このユニットでは、論理パーティションと、ホット パーティションを回避する方法について詳しく学習します。 この情報は、このシナリオで顧客データに適したパーティション キーを選択するのに役立ちます。
Azure Cosmos DB でストレージとスループットを向上させるには、データのアクセスと格納に使用される物理パーティションを追加します。 物理パーティションの最大ストレージ サイズは 50 GB、最大スループットは 10,000 RU/s です。
Azure Cosmos DB の論理パーティション
論理パーティションは、基になる物理パーティションの上の抽象化です。 複数の論理パーティションを 1 つの物理パーティション内に格納できます。 コンテナーには、無制限の数の論理パーティションを含めることができます。 個々の論理パーティションは、最適なストレージ使用率と拡大を確保するために、サイズが大きくなるにつれて新しい物理パーティションに移動されます。 論理パーティションを 1 つのユニットとして移動することで、その中のすべてのドキュメントが同じ物理パーティションに確実に存在するようになります。 論理パーティションの最大サイズは 20 GB です。 カーディナリティが高いパーティション キーを使用すると、データを多数の論理パーティションに分散することで、この 20 GB の制限を回避できます。 この制限を回避するために、階層的なパーティション キーを使用して、階層内のパーティション キーの値を整理することもできます。 これらは別のラーニング パスで説明します。
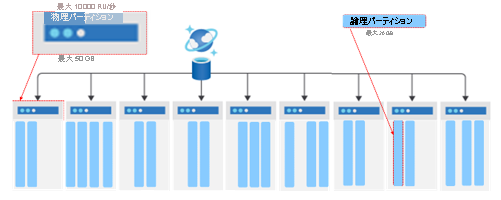
パーティション キーは、論理パーティションのデータをルーティングする方法を提供するものです。 これは、データをルーティングするコンテナー内のすべてのドキュメント内に存在するプロパティです。 コンテナーは別の抽象化であり、同じパーティション キーを使用したすべての格納データ用です。 パーティション キーは、コンテナーの作成時に定義されます。
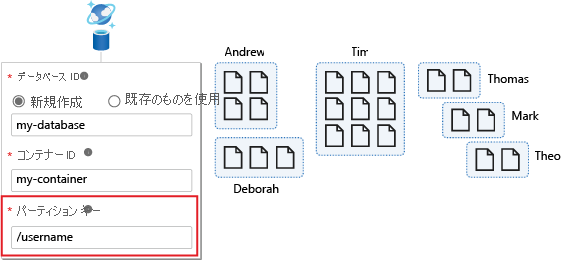
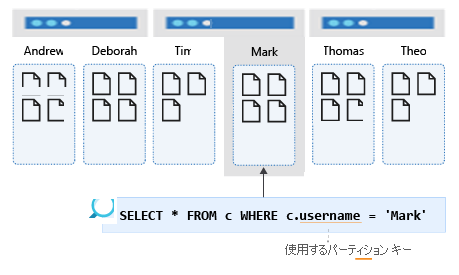
次の例では、コンテナーのパーティション キーは /username です。
ホット パーティションを回避する
Azure Cosmos DB のデータをモデル化する場合、選択したパーティション キーによって、コンテナー内の論理、さらには物理パーティションの両方にわたってデータと要求が均等に分散されることが非常に重要です。 これは、コンテナーが大きくなり、物理パーティションの数が増えたときに、特に当てはまります。
開発時に負荷をかけてデータベースの設計をテストしなかった場合、アプリケーションが運用環境に移行され、大量のデータが書き込まれるまで、パーティション キーの不適切な選択が明らかにならない可能性があります。
データが正しくパーティション分割されていない場合、"ホット パーティション" が発生する可能性があります。 ホット パーティションを使用すると、アプリケーションのワークロードのスケーリングが妨げられ、ストレージとスループットの両方で発生する可能性があります。
ストレージのホット パーティション
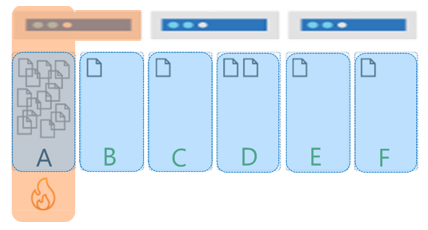
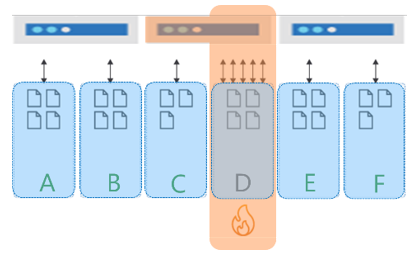
ストレージのホット パーティションは、パーティション キーによって非対称が高いストレージ パターンになった場合に発生します。 例として、TenantId をパーティション キーとして使用するマルチテナント アプリケーションを考えてみましょう。これには次の 6 つのテナントが含まれています: A から F。テナント B、C、E、F は非常に小さく、テナント D のデータは少し多くなっています。 一方、テナント A は大きく、パーティションの 20 GB という制限にすぐに到達します。 このシナリオでは、異なるパーティション キーを選んで、ストレージをより多くの論理パーティションに分散させる必要があります。
スループットのホット パーティション
ほとんどまたはすべての要求が同じ論理パーティションに送信される場合、スループットはホット パーティションの影響を受ける可能性があります。
アプリケーションのアクセス パターンを理解して、パーティション キー値全体に可能な限り均等に要求が分散されるようにすることが重要です。 Azure Cosmos DB のコンテナーにスループットがプロビジョニングされるときは、コンテナー内のすべての物理パーティションに均等に割り当てられます。
たとえば、30,000 RU/s のコンテナーがある場合、このワークロードは上記の同じ 6 つのテナントの 3 つの物理パーティションに分散されます。 そのため、各物理パーティションは 10,000 RU/s になります。 テナント D によって 10,000 RU/s がすべて消費された場合、他のパーティションに割り当てられたスループットは消費できないため、レートが制限されます。 この結果、テナント C と D のパフォーマンスは低下し、他の物理パーティションと残りのテナントのコンピューティング容量は使用されません。 最終的に、このパーティション キーによって作成されるデータベース設計では、アプリケーションのワークロードはスケーリングできません。
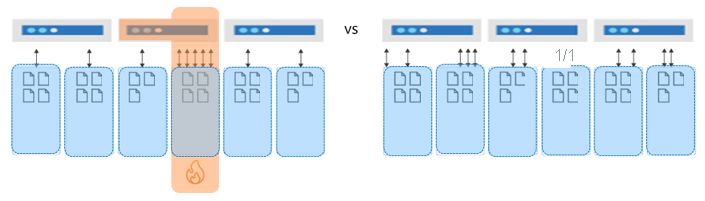
データと要求が均等に分散されている場合、データベースはストレージとスループットの両方を最大限に活用する方法で増大できます。 その結果、最高のパフォーマンスと最高の効率が得られます。 つまり、このデータベース設計はスケーリングします。
読み取りと書き込みを検討する
パーティション キーを選択する場合は、データの読み取りが多いか、書き込みが多いかも考慮する必要があります。 書き込みが多い要求は、カーディナリティの高いパーティション キーを使用して分散させるようにします。
読み取りが多いワークロードの場合は、パーティション キーに等値フィルターを指定した WHERE 句、またはパーティション キー値のサブセットに対する IN 演算子を、クエリに含めることによって、クエリが 1 つまたは限られた数のパーティションによって処理されるようにする必要があります。
アプリケーションのワークロードで書き込みと読み取りの両方が多いシナリオには、解決策があります。 それについては、次のモジュールで説明します。
次の図は、ユーザー名でパーティション分割されたコンテナーを示しています。 このクエリは 1 つの論理パーティションにしかヒットしないので、パフォーマンスは常に良好です。
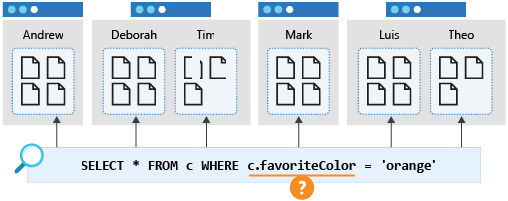
favoriteColor のような別のプロパティでフィルター処理したクエリを使用すると、コンテナー内のすべてのパーティションに "広がって" しまいます。 これは "クロスパーティション クエリ" とも呼ばれます。 このようなクエリは、コンテナーが小さく、1 つのパーティションのみを占めている場合は期待どおりに実行されます。 しかし、コンテナーが大きくなり、物理パーティションの数が増えてくると、結果を得るために、物理パーティションにクエリに関連するデータが含まれているかどうかをすべてのパーティションで確認する必要があるため、このクエリは遅くなり、コストも高くなります。
顧客に適したパーティション キーを選択する
Azure Cosmos DB のパーティション分割を理解したので、次は顧客データのパーティション キーを決定できます。 前に説明したように、顧客に対して実行する操作は、顧客の作成、顧客の更新、顧客の取得の 3 つです。 このケースでは、ID によって顧客を取得します。その操作が最も多く呼び出されるので、顧客の ID をコンテナーのパーティション キーにするのが理にかなっています。

ID をパーティション キーにした場合、顧客の数だけ論理パーティションが存在し、各論理パーティションに 1 つのドキュメントしか格納されていない状態になるのでは、と不安になるかもしれません。 何百万人もの顧客がいれば、何百万個もの論理パーティションができることになります。
ただし、これはまったく問題ありません。 論理パーティションは仮想的な概念であり、持てる論理パーティション数に制限はありません。 Azure Cosmos DB により、同じ物理パーティション上に複数の論理パーティションが併置されます。 論理パーティションの数またはサイズが大きくなると、Cosmos DB により、必要に応じて新しい物理パーティションに移動されます。