ハイブリッド ファイル アクセス要件
以前のユニットでは、ストレージ ソリューションで実行していることに大きく重点を置いていました。 このユニットでは、ご利用のデータが置かれる "場所" に焦点を当てます。 ハイブリッド ファイル アクセスに関する考慮事項とそれらに取り組む方法について説明します。
ハイブリッド ファイル アクセスの概要
現在データセンターで実行している HPC ワークロードを Azure で実行することにしました。 コンピューティング環境では、ワークロードに NFSv3 操作を提供している NAS 上のデータにアクセスします。 それは長年そこで実行されていましたが、おそらくこの NAS 環境はそのサイクルの終わりに達しつつあります。 それを置き換えるのではなく、クラウドへの長期的な移行を検討しています。
この決断をしてから HPC ワークロードの完全なクラウド デプロイまでに、Azure 戦略を決定し、ベースライン アカウントやサブスクリプションやセキュリティ セットアップを確立します。 では、難しい部分である HPC ワークロードの移行に進みましょう。
HPC クラスターとその管理プレーンの構築はこのモジュールの範囲外です。 クラスターで実行したい仮想マシンの種類と数量は決定済みであるものと見なします。
また、今のところ、目標はワークロードを現状のまま実行することとします。 つまり、現在オンプレミスでデプロイされているロジックまたはアクセス方法は変更しないものとします。 これは、コードで、クラスター メンバーのローカル ファイル システムのディレクトリ パスにデータがあると想定されていることを意味します。
最初の目標は、どんなデータが必要で、そのデータがどこから提供されているかを理解することです。 データが単一の NAS 環境の単一のディレクトリにある場合もあれば、さまざまな環境に分散される場合もあります。
次の目標は、ワークロードを実行するために必要なデータの量を特定することです。 ソース データは数ギガバイトですか、数百テラバイトですか。
最後に、Azure コンピューティングでデータがどのように提供されるかを決定する必要があります。 それは、各 HPC クラスター コンピューターにローカルで提供されますか、それともクラウドベースの NAS ソリューションによって共有されていますか?
リモート データ アクセスに関する考慮事項
Azure で実行したいゲノミクス ワークロードがあります。 データは、遺伝子シーケンサーによってオンプレミスで生成され、ローカルの NAS 環境に送信されます。 オンプレミスの研究者は、さまざまな用途でデータを使用します。 研究者は、Azure で実行しようとしている HPC ワークロードの結果を使用することも希望しています。 しかし彼らの一部は、それを実行するためにオンプレミスのワークロードを使用しています。 また、最新のゲノム データは定期的に生成されることが想定されます。 そのため、データを交換または更新することが必要になるまで、現在のワークロードを実行する期間が限られます。
課題は、コスト効率の高い、タイムリーな方法で Azure コンピューティングにデータを提供しながら、データへのオンプレミスのアクセスを保持することです。
ここでは、Azure で HPC ワークロードの実行を試みるときに行う必要がある主な質問をいくつか紹介します。
- オンプレミスでコピーを保持せずに、ソース データを Azure に移動できますか。
- オンプレミスでコピーを保持せずに、結果データを Azure Storage に保存できますか。
- オンプレミスのユーザーは、ソース データまたは結果データへの同時アクセスを必要としますか。
- そうであれば、Azure でデータを操作できますか、またはデータをオンプレミスに格納する必要がありますか。
データをオンプレミスに保持する必要がある場合、ワークロード用に Azure にコピーするデータの量はどのくらいですか。 データが処理されてから新しいデータ セットを処理する必要があるまでの時間はどれくらいですか。 この期間内にワークロードは実行されますか。
また、Azure へのネットワーク接続性を考慮する必要があります。 Azure へのインターネット アクセスしかありませんか。 その制限は、コピーまたは転送されるデータのサイズと更新間隔の時間によっては、問題がない可能性があります。 おそらく毎回大量のデータをコピーするでしょう。 Azure ExpressRoute を使用した、Azure へのワイドエリア ネットワーク (WAN) 接続が必要になる場合があります。これにより、データのコピーや転送のために大きな帯域幅が提供されます。
Azure への ExpressRoute が既に存在する場合、次の考慮事項があります。データ コピー操作に使用できる接続の量はどのくらいですか。 リンクが著しく飽和している場合は、データを転送する時間帯を考慮する必要がある可能性があります。 または、大規模なデータ転送に対応するために、より大規模な ExpressRoute 接続を構成することもできます。
データを Azure に移動する場合は、セキュリティで保護する方法を検討する必要があります。 たとえば、アクセス許可をユーザーに拡張するのに役立つディレクトリ サービスを使用するオンプレミスの NFS 環境があるとします。 このセキュリティを Azure にコピーする場合は、Azure 構築の一部としてディレクトリ サービスが必要かどうかを判断する必要があります。 しかし、ワークロードが HPC クラスターに限定され、結果がローカル環境に返送される場合は、これらの要件を省略できる可能性があります。
次に、データにアクセスする方法 (キャッシュ、コピー、同期) について考慮します。
キャッシュとコピーと同期
Azure にデータを追加するために使用できる一般的なアプローチについて説明します。 このデータ転送の議論の焦点となるのは、データのアーカイブやバックアップではなく、アクティブなデータです。
ここでの説明の中で、転送されるデータは、HPC ワークロードのワーキング セットであるとします。 ライフ サイエンス HPC 環境では、データには、生のゲノム データ、そのデータを処理するために使用されるバイナリ、または参照ゲノムのような補足データなどのソース データが含まれる可能性があります。 それは到着するとすぐに、またはその後まもなく処理される必要があります。 さらに、IOPS、待機時間、スループット、コストに関して、適切なパフォーマンス プロファイルを持つメディアにデータが格納される必要もあります。 これに対して、アーカイブ/バックアップ データは、ほとんどの場合に、可能な限り最もコストが低いストレージ ソリューションに転送されます。それは、ハイパフォーマンス アクセスを意図していません。
アクティブ データを転送する主な方法は、キャッシュ、コピー、および同期です。 各アプローチの長所と短所について説明しましょう。まずは、コピーの方法からです。
データのコピーは、データ移動の最も一般的なアプローチです。 使用するツールに応じて、さまざまな方法でデータがコピーされます。
次の点を考慮します。
- ファイルのサイズ。
- ファイルの数。
- データの転送に使用できるスループットの量。
- 転送を実行するのに必要な時間。
わずかな数の適度なサイズのファイルをリモートの送信先に送信する場合は、cp などの基本的なコピー ツールで十分です。 セキュリティで保護されていないネットワークを経由してデータを転送する場合、cp の代わりに scp を使用する必要がある可能性があります。scp では Secure Shell (SSH) 接続経由で暗号化が提供されます。
データをコピーする場所に応じて、コピー操作を最適化するためのさまざまなアプローチがあります。 各 HPC コンピューターにファイルを直接コピーする場合は、たとえば、各ノードで個々のコピー操作をスケジュールすることができます。
WAN リンク経由でデータをコピーする際の考慮事項の 1 つとして、コピー対象のファイルやフォルダーの数量があります。 小さなファイルを多数コピーする場合、コピーの使用と tar などのアーカイブを組み合わせて、WAN リンクからメタデータ オーバーヘッドを取り除く必要があります。 .tar ファイルを Azure にコピーし、次にそのデータをコンピューターにコピーします。
コピーに関するもう 1 つの問題には、中断のリスクがあります。 たとえば、大きなファイルをコピーしようとして、転送エラーが発生した場合、cp を使用しても、中断した場所からコピーを再開できないため、機能しません。
データのコピーに関する最後の懸念事項は、コピーが古くなる可能性があることです。 たとえば、データ セットを Azure にコピーするとします。 その間にオンプレミスのユーザーが 1 つ以上のソース ファイルを更新している場合があります。 正しいデータを使用していることを確認するためのプロセスを決定しておく必要があります。
データの同期はコピーの 1 つの形式ですが、より高度です。 rsync などのツールには、コピー元からデータをコピーすることに加えて、コピー元とコピー先の間でデータを同期できる機能が追加されています。 rsync では、ファイルのサイズと変更日に基づいて、ファイルが最新であることが確認されます。 同期によって、古いファイルが使用される可能性を最小限に抑えることができます。
rsync には回復機能があります。 たとえば、大きなファイルをコピーしていて、転送の問題が発生している場合、rsync では中断した場所から再開できます。
rsync は無料で、簡単に実装できます。 ここで説明するもの以外にも機能があります。 これにより、オンプレミスのデータに基づいて、Azure で同期ファイル システムを確立できます。
rsync にもここで説明する必要がある制限事項があります。 最初に、ツールはシングル スレッドです。 一度に実行できる操作は 1 つだけで、データアクセスを並列化することはできません。 コピー ユーティリティ cp も、シングル スレッドです。 そのため、これらのツールは、大量のデータと短い時間枠を伴う大規模なコピーや同期操作には最適ではありません。 また、同期させるためにツールを実行する必要もあります。 このツールを実行するときは、時間枠要件に従って実行されるようにする必要があるために、環境に複雑さが加わります。 たとえば、rsync を含むスクリプトをスケジュールしたいと考える場合があります。 このアプローチでは、問題が発生した場合に備えて、スクリプトのログ記録を追加する必要があります。 さらに、問題を監視する必要があることも意味します。 複雑さのレベルは急に拡大する可能性があります。
商用の NAS ソリューションを実行している場合は、より高度で、マルチスレッドのパフォーマンスを発揮するサーバーレベルの同期ツールを購入できます。 これらのツールを有効にして構成すると、常に動作していて、1 つまたは複数の同期元と同期先の間でデータが同期されます。
コピーと同期では、ソース データの完全なコピーが転送されます。 データセットやファイルサイズが小さい場合は、完全なファイル転送には問題ありません。 ソース データが多数の大きなファイルで構成されている場合に、著しい遅延が生じる可能性があります。 転送するデータが多いほど、転送にかかる時間が長くなります。 同期では、クラウドに新しいファイルのみが追加されます。 しかし、それらのファイルはやはり全体が転送される必要があります。 場合によっては、HPC ワークロードで特定のファイル セットの全体を必要としないことがあります。 ファイルの特定の領域へのアクセスのみが必要である場合があります。
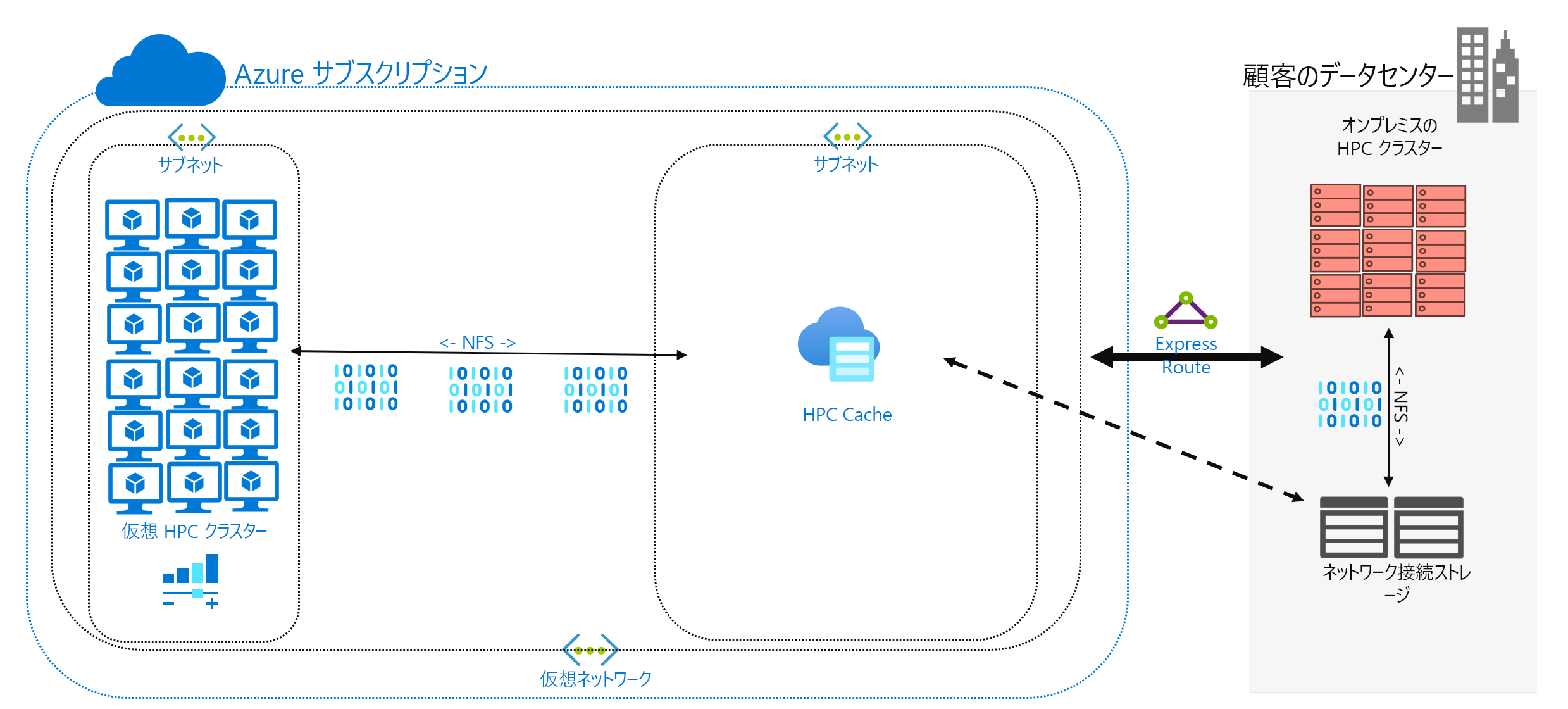
データのキャッシュは、Azure にデータを追加するための 3 つ目のアプローチです。 キャッシュとは、キャッシュを介したファイル データの取得と提供を指します。 キャッシュは、個々のローカル クライアントに配置することも、すべての HPC コンピューターにサービスを提供する分散キャッシュにすることもできます。 通常、キャッシュは待機時間を最小限に抑えるために使用されます。そのため、キャッシュを待機時間の境界に配置することは、データの提供に最適なアプローチです。 たとえば、WAN リンクを介してオンプレミスのストレージに接続されている分散キャッシュを Azure コンピューティングに配置することで、WAN 接続を介してデータ要求をキャッシュできます。
このモジュールでは、具体的にファイル キャッシュについて言及します。そこでは、キャッシュ自体で、コンピューターからの要求が処理されます。 バックエンド ストレージ環境 (NFS NAS 環境など) からデータが取得されて、そのデータがクライアントに提示されます。
キャッシュの機能には 2 つあります。 最初に、キャッシュでは、ファイル全体が取得されません。 キャッシュでは、ファイル全体ではなく、ファイルの要求されたサブセットまたはバイト範囲が取得されます。 取得は、これらのバイト範囲に対するクライアント要求に基づきます。 この取得のアプローチによって、ファイルの小さなセクションだけが必要な場合に、大きなファイル全体を取得する場合のパフォーマンスの低下を最小限に抑えます。
2 つ目に、キャッシュでは頻繁に要求されるデータの繰り返しのアクセスが最適化されます。 バイト範囲がキャッシュ内に入った後は、そのデータに対する以降の要求は高速になります。 取得が遅いのは、最初の取得だけです。 共通のファイル セットにアクセスしている多数の HPC クライアントまたはスレッドを実行している場合に、大きなメリットを認識できます。
キャッシュには、ハイブリッド シナリオでもう 1 つの利点があります。 データは Azure 内 (キャッシュ内) に一時的に格納されるだけです。 また、HPC ワークロードの操作中にのみ格納されます。 そのため、Azure へのより具体的なデータ移動に関連するロジスティック オーバーヘッドを減らすことができます。 データのプライバシーとセキュリティに関する懸念は、キャッシュと HPC コンピューター自体に切り離すことができます。
最後に、特定のキャッシュ ソリューションでは、いわゆる属性チェックが提供されます。 同期と同様に、キャッシュでは、ソースにあるファイルの属性が定期的にチェックされ、ソースでのファイルの変更が大きいバイト範囲が取得されます。 このアーキテクチャにより、HPC 環境は常に最新データを使用して動作するようになります。