Fabric のデータ ウェアハウスを理解する
Fabric の Lakehouse は、データ レイク上のデータベースのように機能するファイル、フォルダー、テーブル、ショートカットのコレクションです。 これは、Spark エンジンと SQL エンジンによってビッグ データ処理に使用され、オープンソースの Delta 形式のテーブルを使用する場合の ACID トランザクション用の機能を備えています。
Fabric のデータ ウェアハウス エクスペリエンスを使用すると、Lakehouse (Data Engineering と Apache Spark をサポートする) のレイク ビューから、従来のデータ ウェアハウスが提供する SQL エクスペリエンスに移行できます。 レイクハウスを使うと、テーブルを読み取って SQL 分析エンドポイントを使用できます。一方、データ ウェアハウスを使うと、データを操作できます。
データ ウェアハウス エクスペリエンスでは、テーブルとビューを使用してデータをモデル化し、T-SQL を実行してデータ ウェアハウスと Lakehouse 全体のデータに対してクエリを実行し、T-SQL を使用してデータ ウェアハウス内のデータに対して DML 操作を行い、Power BI などのレポート レイヤーを提供します。
リレーショナル データ ウェアハウス スキーマの基本的なアーキテクチャ原則を理解したので、次にデータ ウェアハウスを作成する方法について説明します。
Fabric のデータ ウェアハウスについて説明する
Fabric のデータ ウェアハウス エクスペリエンスでは、Lakehouse の物理データの上にリレーショナル レイヤーを構築し、分析およびレポート ツールに公開できます。 データ ウェアハウスは、作成ハブまたはワークスペース内から Fabric に直接作成できます。 空のウェアハウスを作成したら、そこにオブジェクトを追加できます。
ウェアハウスが作成されたら、T-SQL を使用してテーブルを Fabric インターフェイスで直接作成できます。
データ ウェアハウスにデータを取り込む
Fabric データ ウェアハウスにデータを取り込むには、"パイプライン"、"データフロー"、"データベース間クエリ"、COPY INTO コマンドなど、いくつかの方法があります。 データは取り込んだ後、複数のビジネス グループによる分析に使用できるようになり、データベース間クエリや共有などの機能を使用してアクセスすることができます。
テーブルの作成
データ ウェアハウスにテーブルを作成するには、SQL Server Management Studio (SSMS) または別の SQL クライアントを使用してデータ ウェアハウスに接続し、CREATE TABLE ステートメントを実行します。 Fabric UI でテーブルを直接作成することもできます。
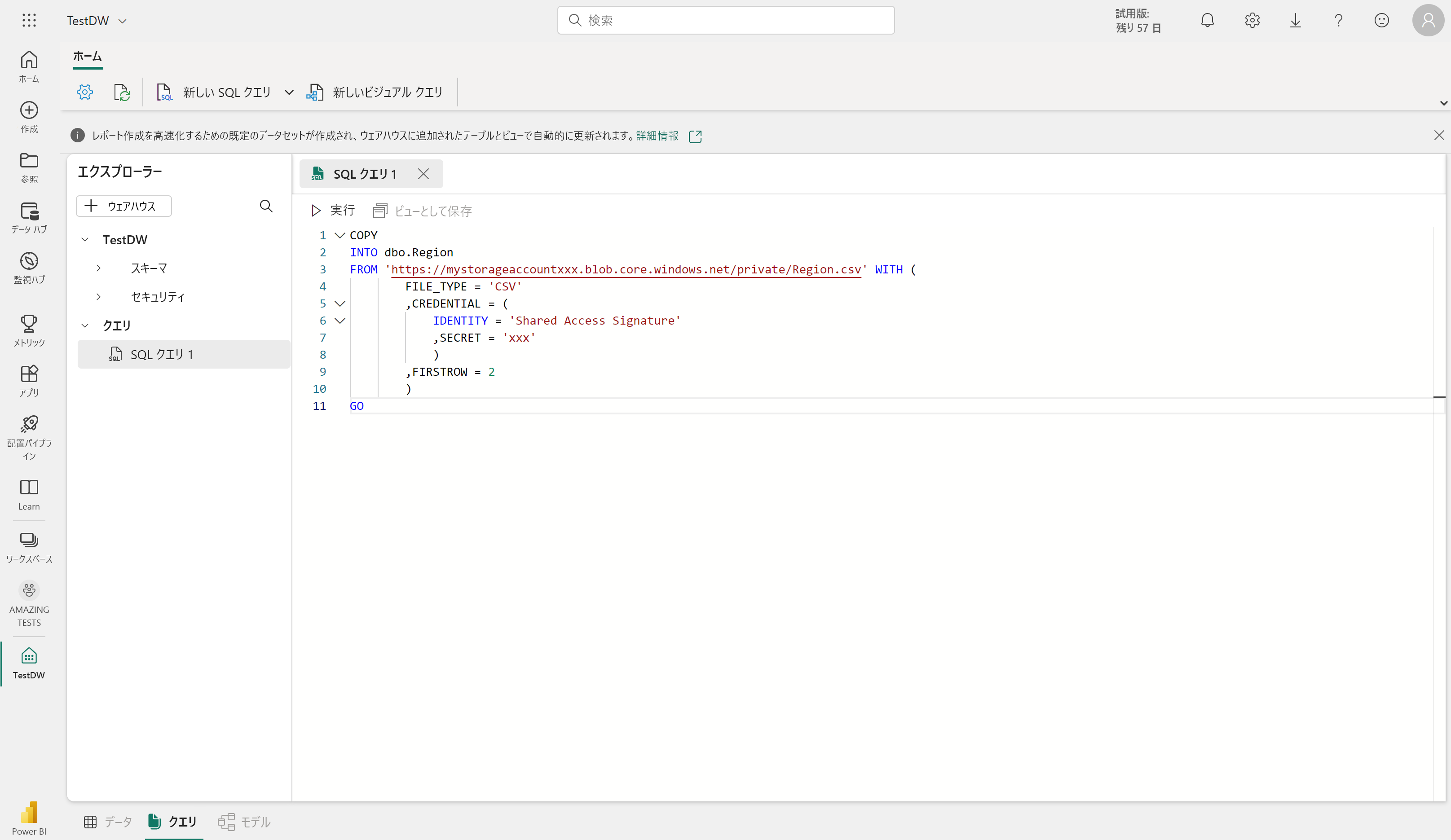
COPY INTO 構文を使用すると、外部の場所からデータ ウェアハウス内のテーブルにデータをコピーできます。 次に例を示します。
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
この SQL クエリは、Azure Blob Storage に格納されている CSV ファイルから、Fabric データ ウェアハウスの "Region" というテーブルにデータを読み込みます。
テーブルの複製
データ ウェアハウスで、ストレージ コストを最小限に抑えながらゼロコピー テーブルのクローンを作成できます。 これらのクローンは、基本的に、OneLake で同じデータ ファイルを参照しながらメタデータをコピーして作成されたテーブルのレプリカです。 つまり、Parquet ファイルとして格納された基礎データが重複していないため、ストレージ コストの削減に役立ちます。
テーブル クローンは、いくつかのシナリオで特に役立ちます。
- 開発とテスト:クローンを使用すると、開発者とテスト担当者は、より下位の環境でテーブルのコピーを作成でき、開発、デバッグ、テスト、検証のプロセスが容易になります。
- データの復旧:リリースの失敗やデータの破損が起こった場合、テーブルのクローンはデータの以前の状態を保持し、データ復旧を可能にします。
- 履歴レポート:特定の時点でのデータの状態を反映した履歴レポートを作成し、特定のビジネス マイルストーンでデータを保持するのに役立ちます。
CREATE TABLE AS CLONE OF T-SQL コマンドを使用して、テーブル クローンを作成できます。
テーブル クローンの詳細については、 チュートリアルを参照してください。Microsoft Fabric で T-SQL を使用してテーブルをクローンします。
テーブルに関する考慮事項
データ ウェアハウスにテーブルを作成した後、それらのテーブルにデータを読み込むプロセスを検討することが重要です。 "ステージング テーブル" を使用するのが一般的な方法です。 Fabric では、T-SQL コマンドを使用して、データ ウェアハウス内のステージング テーブルにファイルからデータを読み込むことができます。
ステージング テーブルは、データ クレンジング、データ変換、データ検証を行うために使用できる一時テーブルです。 ステージング テーブルを使用して、複数のソースのデータを 1 つの変換先テーブルに読み込むこともできます。
通常、データの読み込みは、データ ウェアハウスへの挿入と更新が一定の間隔 (毎日、毎週、毎月など) で行われるように調整されている定期的なバッチ プロセスとして実行されます。
一般的に、次の順序でタスクを実行するデータ ウェアハウスの読み込みプロセスを実装する必要があります。
- 読み込み対象の新しいデータをデータ レイクに取り込み、必要に応じて、読み込み前のクレンジングまたは変換を適用します。
- データをリレーショナル データ ウェアハウス内のファイルからステージング テーブルに読み込みます。
- ステージング テーブルのディメンション データからディメンション テーブルを読み込み、必要に応じて、既存の行を更新するか新しい行を挿入して、代理キー値を生成します。
- ステージング テーブルのファクト データからファクト テーブルを読み込み、関連するディメンションの適切な代理キーを参照します。
- インデックスとテーブル分散統計を更新して、読み込み後の最適化を実行します。
レイクハウスにテーブルがあり、Fabric データ ウェアハウスを使用して、ウェアハウス内でクエリを実行できるようにしたいが、変更は加えない場合は、レイクハウスからデータ ウェアハウスにデータをコピーする必要はありません。 データベース間クエリを使用して、レイクハウス内のデータにデータ ウェアハウスから直接クエリを実行できます。
重要
現在、Fabric データ ウェアハウスのテーブルの操作にはいくつかの制限があります。 詳細については、Microsoft Fabric のデータ ウェアハウスのテーブルに関するページを参照してください。