微調整された基盤モデルを評価、デプロイ、テストする
Azure Machine Learning のモデル カタログから基礎モデルを微調整すると、それを評価してデプロイし、モデルを簡単にテストして使用できます。
微調整モデルを評価する
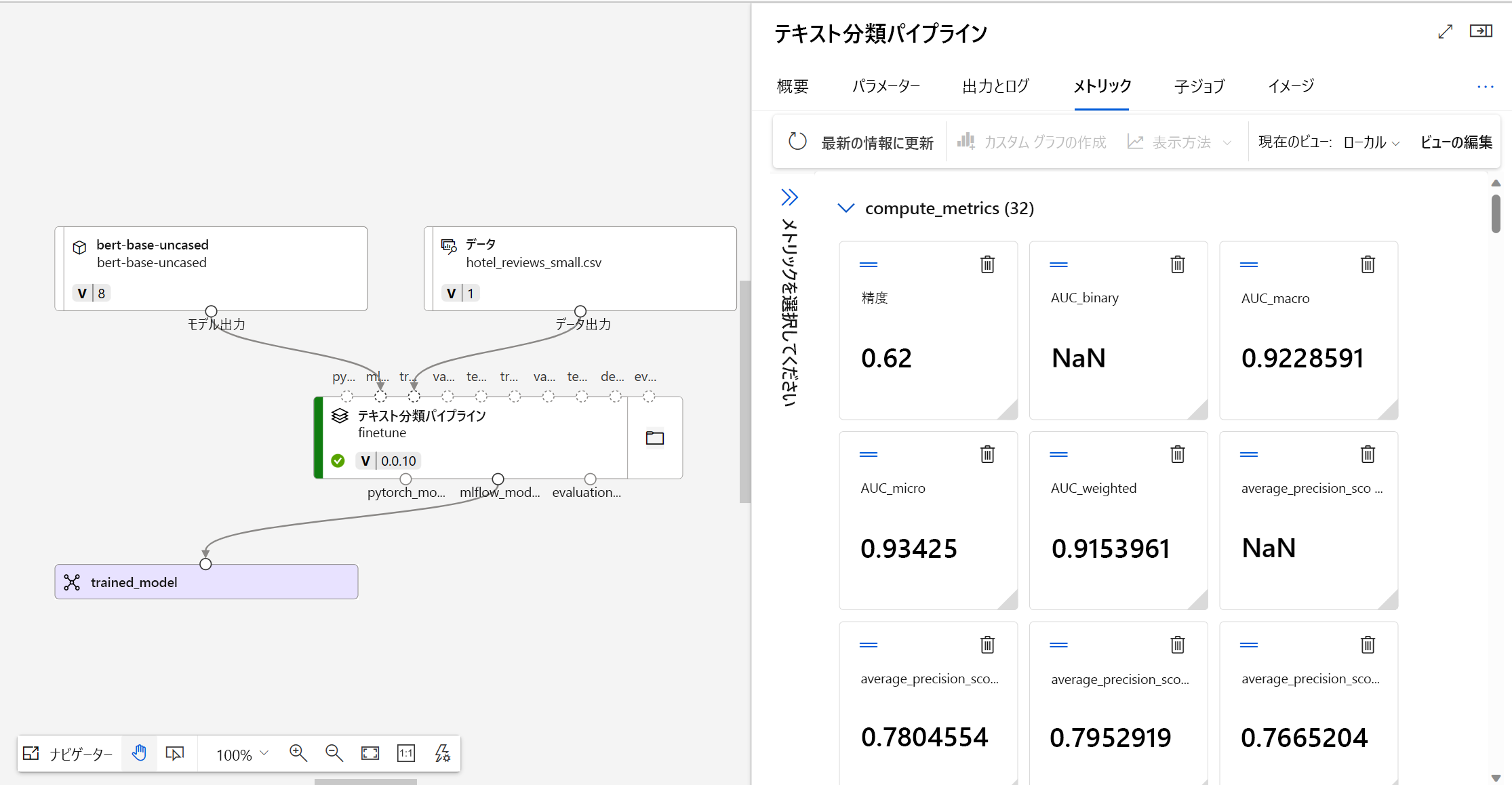
微調整モデルが想定どおりに動作するかどうかを判断するには、トレーニングと評価メトリックを確認できます。
微調整するモデルを送信すると、Azure Machine Learning により、実験内に新しいパイプライン ジョブが作成されます。 このパイプライン ジョブには、モデルの微調整を表すコンポーネントが含まれます。 完了したパイプラインを選択してジョブのログ、メトリック、出力を分析でき、特定の微調整コンポーネントを選択して詳細に調べることができます。
ヒント
Azure Machine Learning では、MLflow でモデルのメトリックを追跡します。 プログラムでメトリックにアクセスして確認する場合、Jupyter ノートブックで MLflow を使用できます。
微調整モデルをデプロイする
微調整モデルをテストして使用するには、モデルをエンドポイントにデプロイします。
Azure Machine Learning の エンドポイントは、トレーニングまたは微調整されたモデルを公開するアプリケーション プログラミング インターフェイス (API) です。これにより、ユーザーまたはアプリケーションは新しいデータに基づいて予測できます。
Azure Machine Learning には、次の 2 種類のエンドポイントがあります。
- リアルタイム エンドポイント: 即時またはオンザフライの予測を処理するように設計されています。
- バッチ エンドポイント: 大量のデータを一度に処理できるように最適化されています。
リアルタイム エンドポイントを使用すると予測を即座に取得できるため、このエンドポイントは、モデルによる予測のテストにも最適です。
Azure Machine Learning スタジオを使用してモデルを登録する
Azure Machine Learning スタジオを使用して微調整モデルをデプロイするには、微調整ジョブの出力を使用できます。
Azure Machine Learning では、MLflow を使用して、ジョブを追跡し、メトリックとモデル ファイルをログします。 MLflow は Azure Machine Learning スタジオに統合されているため、最小限の労力でジョブからモデルをデプロイできます。
まず、ジョブ出力からモデルを登録する必要があります。 ジョブの概要に移動し、[+ モデルの登録] オプションを見つけます。
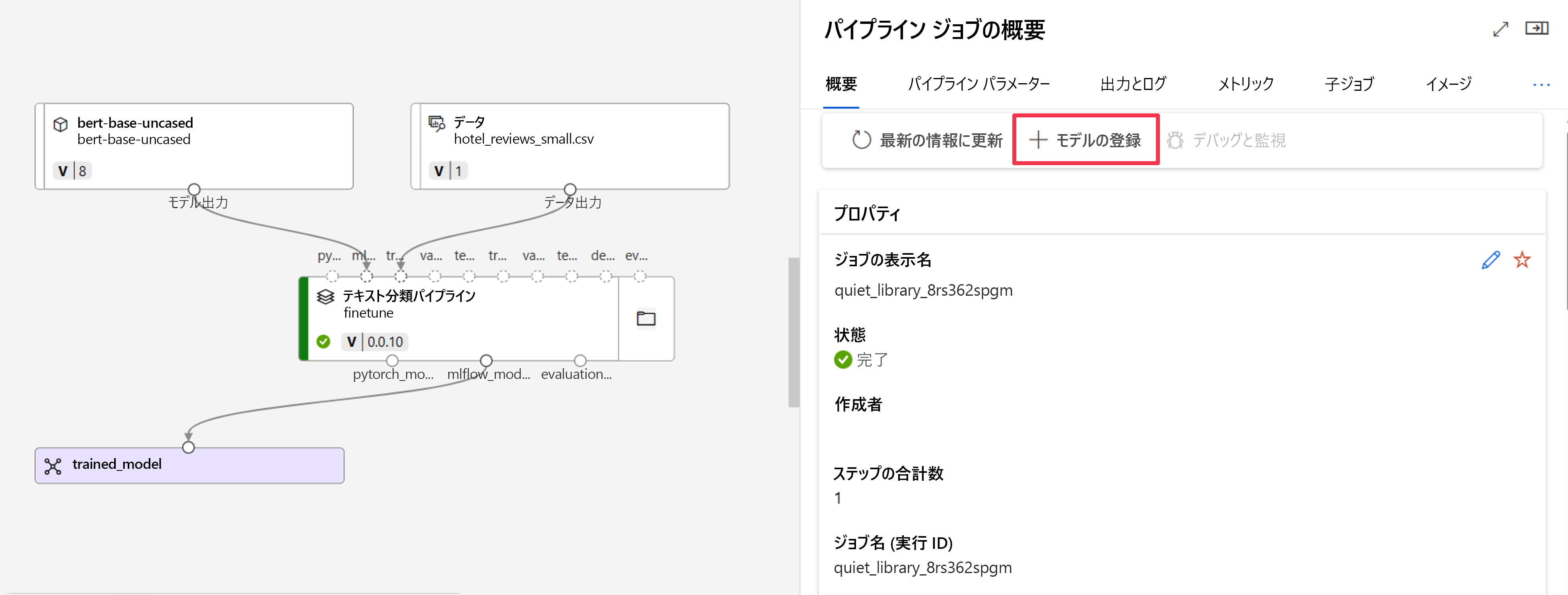
登録するモデルの種類は MLflow で、モデル ファイルを含むフォルダーは、Azure Machine Learning によって自動的に入力されます。 登録するモデルの名前を指定する必要があります。また、必要に応じてバージョンも指定します。
Azure Machine Learning スタジオを使用してモデルをデプロイする
モデルを Azure Machine Learning ワークスペースに登録したら、モデルの概要に移動し、モデルをリアルタイムまたはバッチ エンドポイントにデプロイできます。
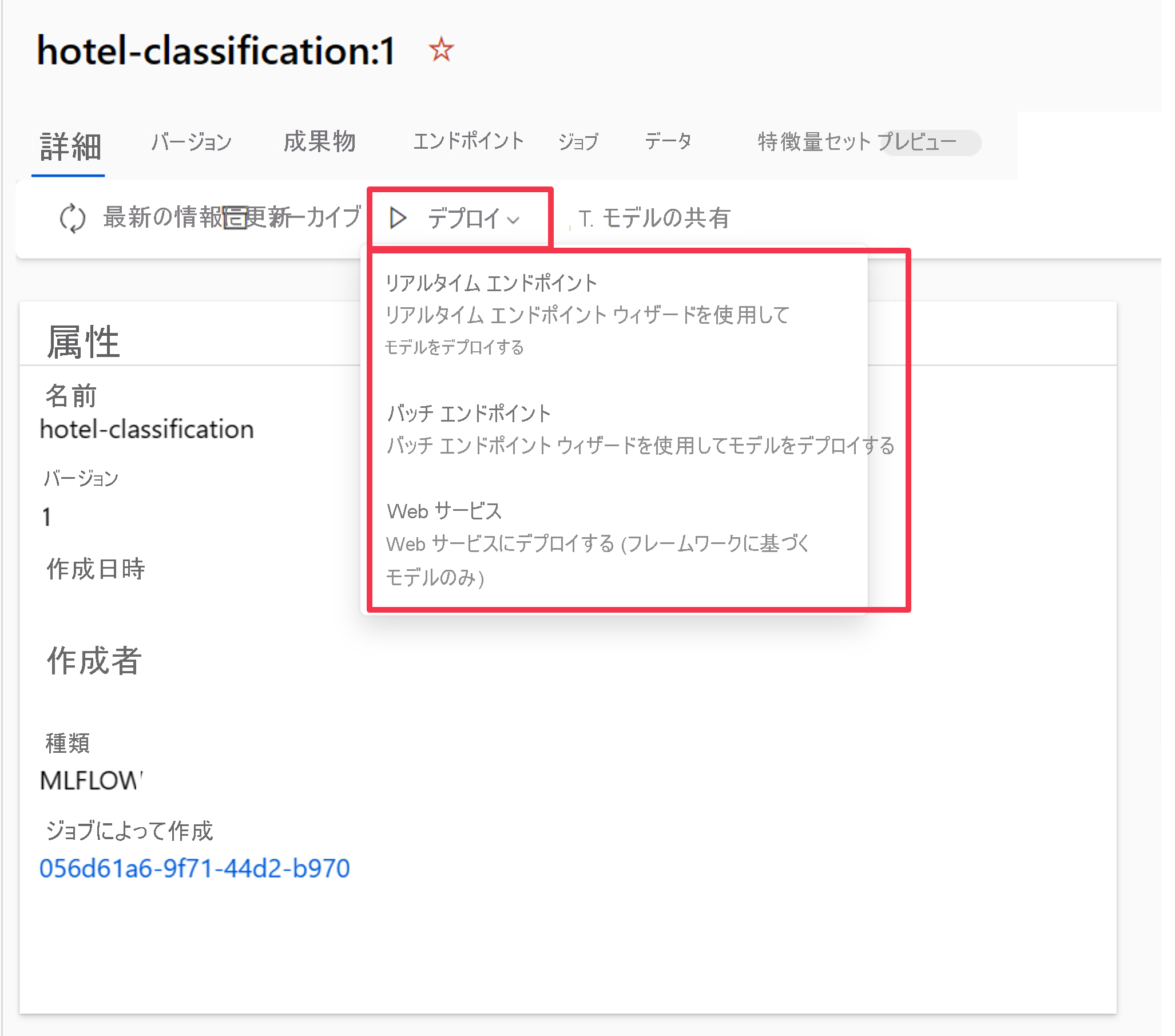
たとえば、次のように指定して、モデルをリアルタイム エンドポイントにデプロイできます。
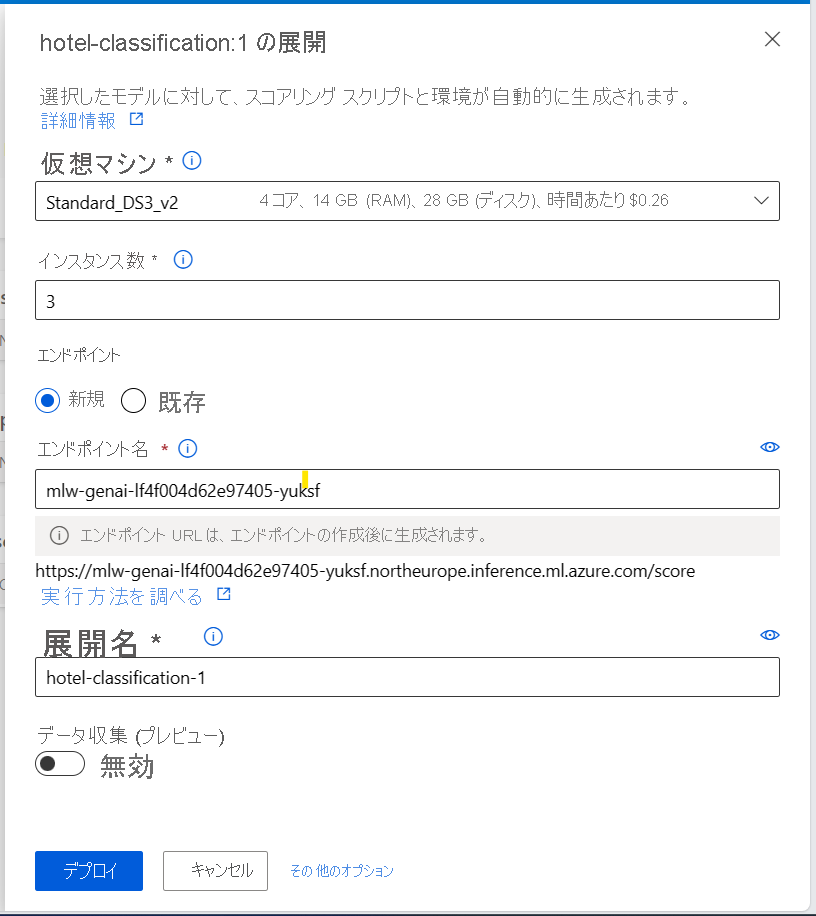
- "仮想マシン": エンドポイントによって使用されるコンピューティング。
- "インスタンス数": デプロイに使用するインスタンスの数。
- "エンドポイント": モデルを新しいまたは既存のエンドポイントにデプロイします。
- "エンドポイント名": エンドポイント URL の生成に使用されます。
- "デプロイ名": エンドポイントにデプロイされるモデルの名前。
Note
複数のモデルを同じエンドポイントにデプロイできます。 エンドポイントの作成と、エンドポイントへのモデルのデプロイには、しばらく時間がかかります。 エンドポイントとデプロイの両方の準備ができるまで待ってから、デプロイされたモデルをテストまたは使用してください。
Azure Machine Learning スタジオでモデルをテストする
モデルがリアルタイム エンドポイントにデプロイされたら、Azure Machine Learning スタジオでモデルをすばやくテストできます。
エンドポイントに移動し、[テスト] タブを調べます。
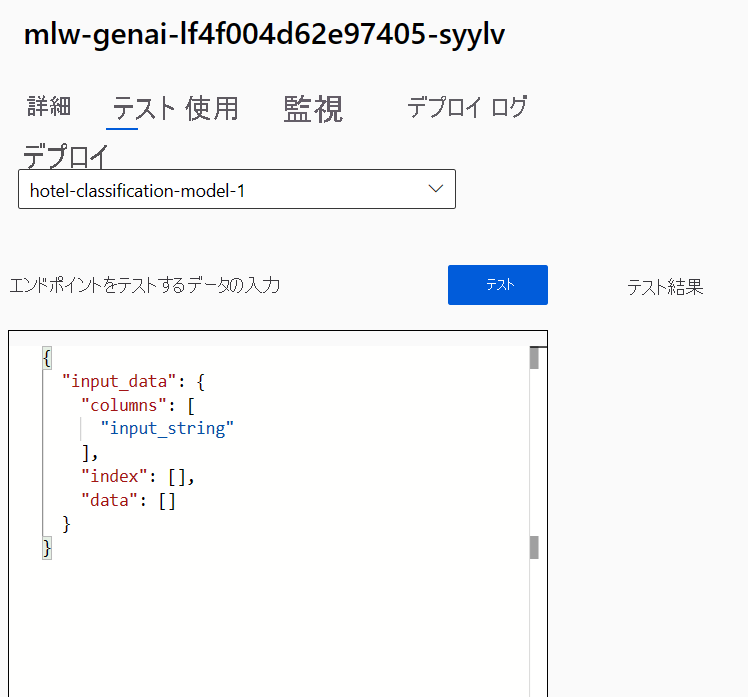
リアルタイム エンドポイントは API として機能するため、JSON 形式の入力データが想定されています。 想定される出力の例が、[テスト] タブに提示されます。
{
"input_data": {
"columns": [
"input_string"
],
"index": [],
"data": []
}
}
テスト データの形式は、ラベル列を除き、トレーニング データと同様である必要があります。 たとえば、テキスト分類用に微調整されたモデルをテストする場合、エンドポイントに 1 つの列 (分類される文) を提供する必要があります。
{
"input_data": {
"columns": [
"input_string"
],
"index": [0, 1],
"data": [["This would be the first sentence you want to classify."], ["This would be the second sentence you want to classify."]]
}
}
スタジオでテスト データを入力し、[テスト] を選択してデータをエンドポイントに送信できます。 結果はほとんど即座に [テスト結果] に表示されます。
ヒント
[テスト結果] の応答が想定どおりではない場合、最も可能性の高い原因として、入力データの形式が正しくないことが考えられます。 MLflow モデルをデプロイする場合、スコアリング スクリプトが自動生成されます。つまり、入力データの形式はトレーニング データ (ラベル列を除く) と同様である必要があります。